엘라스틱 서치의 기본 개념에 대해 기재하려고 한다.
공식 문서를 보면서 다시 개념을 짚어가는 중이다. 오늘도 한번 깨닫지만, 입문하게 되는 기술의 경우에는 공식 문서를 보는게 가장 정확하다.
블로그를 보면 용어도 많이 틀리고, 잘못된 내용도 정말 많다. 옛날에는 몰랐지만, 지금은 보인다... 신기하군!!!
** 이 글은 https://esbook.kimjmin.net 가이드 내용을 참조하여 작성한 글입니다.
ElasticSearch
오픈소스 검색엔진 이며,
아파치 루씬(Apache Lucene) 이 가진 한계를 보완하기 위해 개발됨
Logstash, Kibana와 함께 사용 되면서 한동안 ELK Stack (Elasticsearch, Logstash, Kibana) 이라고 보통 사용됨
지금은 ELK stack 이 아닌, ElasticStack으로 바뀌어서 불리게됨
(검색하면 루씬 기반의 분산 검색 엔진이라고 나오는데, 정확히는 루씬의 한계점을 극복하기 위해
개발된 오픈소스 검색 엔진이 맞는듯 하다.)
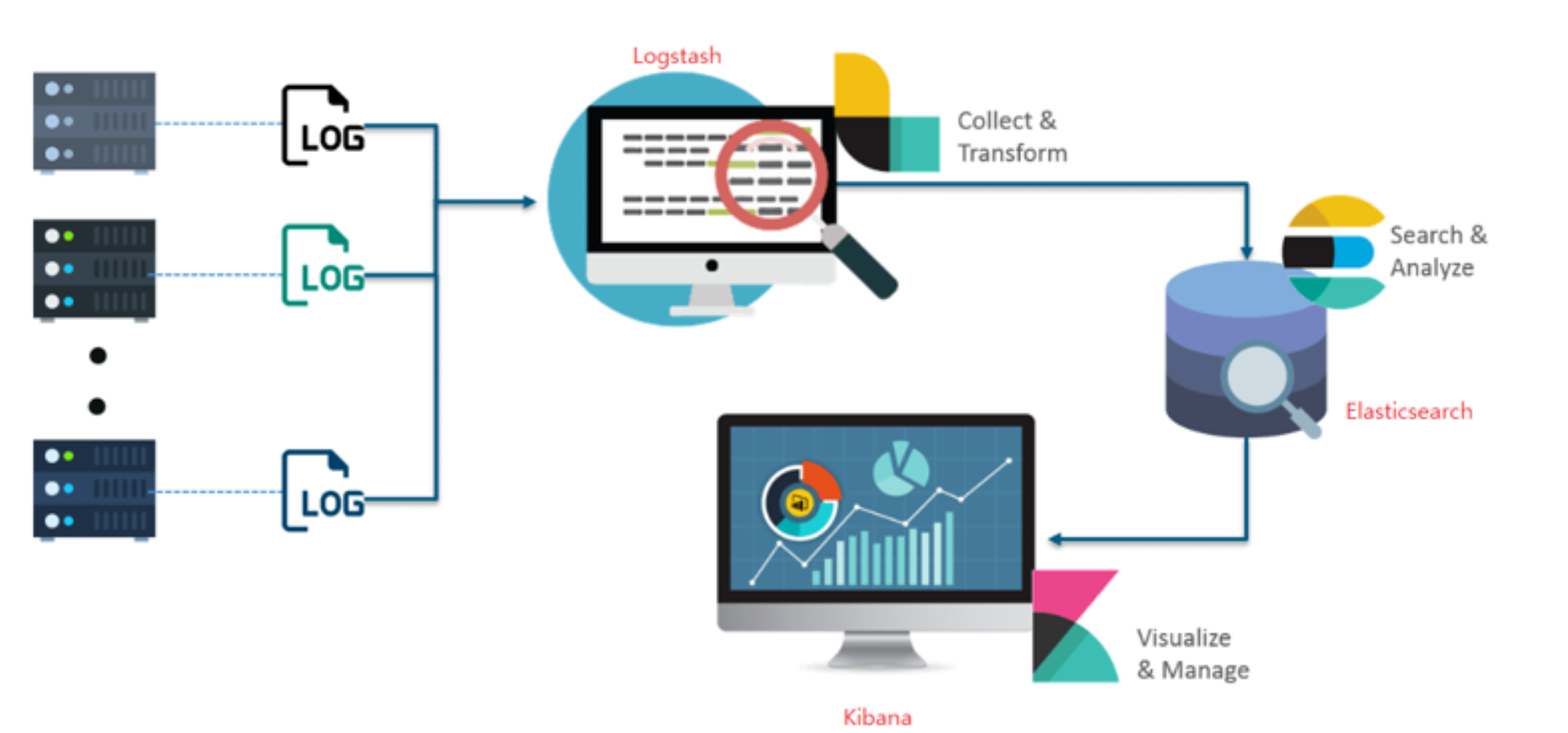
출처 : https://www.edureka.co/blog/elk-stack-tutorial/
ElasticSearch 노드, 샤드
- 전체 구성도
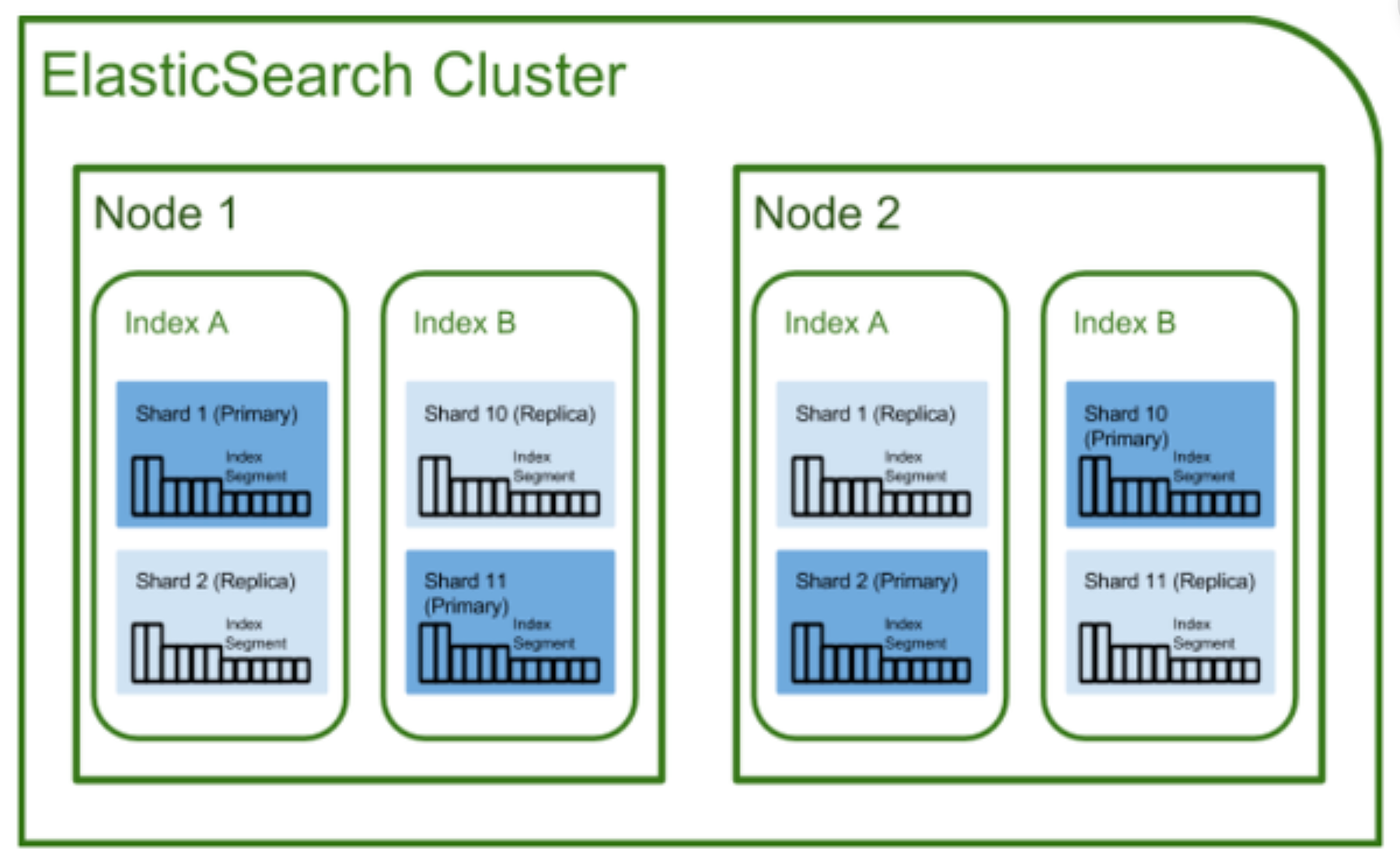
출처 : https://github.com/exo-archives/exo-es-search
1. 노드 (노드에 대해 알아야 할게 이렇게 많을 줄이야 ^^;)
- 여러개의 노드에 하나의 클러스터로 실행된다. 여기서 노드는 하나의 서버를 의미한다.
- 노드는 여러개의 종류가 있다. 목적에 따라 알맞은 노드로 설정해줘야 한다.
- node.master: true ## 마스터 후보(master eligible) 노드
- node.data: true ## 노드가 데이터를 저장가능하도록 함
- node.ingest: true ## 데이터 색인시 전처리 작업인 ingest pipleline 작업의 수행을 할 수 있는지 여부를 지정
- node.ml: true ## 머신러닝 수행 가능 노드- 마스터 노드
- Elasticsearch 클러스터는 하나 이상의 노드로 이뤄지고, 이 중 하나의 노드는 인덱스의 메타 데이터, 샤드의 위치와 같은 클러스터 상태(Cluster Status) 정보를 관리하는 마스터 노드의 역할을 수행(반드시 필요!!)- 클러스터가 1개의 노드로 이뤄지면, 1개의 노드가 마스터 노드가 됨
- 기존 마스터 노드가 다운되면, 다른 마스터 후보 노드 중 하나가 마스터 노드로 선출이 되어 마스터 노드의 역할을 대신 수행
- 마스터 후보 노드(master eligible)들은 처음부터 마스터 노드의 정보들을 공유하고 있기 때문에 즉시 마스터 역할의 수행이 가능
- 노드와 샤드의 개수가 많으면, 일부 노드만 마스터 노드 옵션을 true로 하고 나머지는 false로 두어 부하를 줄이도록 하는게 좋음
- 데이터 노드
- 데이터 노드는 실제로 색인된 데이터를 저장하는 노드- 마스터 후보 노드들은 node.data: false 로 설정하여 마스터 노드 역할만 하고 데이터는 저장하지 않도록 할 수 있음
- (이렇게 설정 안하면, 마스터 노드는 마스터 노드 + 데이터 노드의 역할이 가능하다는 뜻 !!)
- split Brain
- 마스터 노드의 개수는 홀수개로 유지, 네트워크 문제가 생길 경우 복구가 어렵다!- 만약에 2개이면, 하나가 문제가 생겼을때 남은 1개와 분리되면서 서로 다른 클러스터로 동작하게됨
- 나중에 복구 후 다시 하나의 클러스터로 합쳐졌을 때 데이터 무결성, 정합성에 문제가 생긴다.
2. 인덱스
- ElasticSearch에서 하나의 데이터 (RDBMS로 따지면, 하나의 row)는 도큐먼트라고 불리운다.
- 이러한 도큐먼트의 집합을 인덱스(용어가 여러면으로 해석될 수 있어서 인디시즈라고도 불리움)라고 한다.
3. 샤드
-
인덱스 -> 샤드(shard)라는 단위로 구성
-
설정해주지 않으면, 디폴트로 1개 인덱스 per 1개 샤드
-
프라이머리 샤드와 레플리카 샤드
- 처음 생성된 샤드를 프라이머리 샤드(Primary Shard), 복제본은 리플리카(Replica)
- 한 인덱스가 5개의 샤드로 구성어 있고, 클러스터가 4개의 노드로 구성되어 있다고 가정하면 각각 5개의 프라이머리 샤드와 복제본, 총 10개의 샤드들이 전체 노드에 골고루 분배되어 저장
-
중간에 서버의 네트워크, 혹은 다른 문제로 노드사용이 어려워질때 레플리카 샤드를 이용해 데이터의 유실을 방지할 수 있다.
-
샤드의 개수는 처음에 인덱스를 생성할때에 설정해줄 수 있다.
$ curl -XPUT "http://localhost:9200/test" -H 'Content-Type: application/json' -d'
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}'4. 로컬 환경 설정 내용 분석
elasticsearch 운영을 하기 위해 필수적으로 설정해줘야 하는 파일이 있는데, 앞전 게시글에서는 간략하게 뛰어넘었다.
앞부분의 엘라스틱 클러스터의 구성과 역할에 대해서 알고, 해당 내용을 보면 더욱 더 이해가 쉽다!
기본적으로 설정하는 항목은 다음과 같다.
- 경로, 명칭 설정
cluster.name: my-application -> 클러스터 이름 / 여러개의 노드를 하나의 클러스터에서 운영할 때에는 이름을 동일하게 해줘야 한다.
node.name: node-1 -> 노드의 이름/ 디폴트로 node -1,2 ... 이렇게 설정되는 것 같다.
path.data: /path/to/data -> 데이터가 저장되는 디렉토리
path.logs: /path/to/logs -> 노드, 클러스터에서 생성되는 로그를 저장하는 경로
bootstrap.memory_lock: true -> ES가 선점한 메모리를 다른 JAVA 프로그램이 선점하지 못하도록 설정함- 네트워크 관련 항목
network.host: 192.168.0.1 -> 지정한 IP만 접근
network.host: [192.168.0.1, 192.168.0.2, ... ] -> 지정한 IP만 접근
network.host: 0.0.0.0 -> 모든 IP허용
http.port: 9200 -> 클라이언트와 통신할 port
transport.port: 9300 -> 엘라스틱 노드들끼리 통신할 포트 (디폴트가 9300)
discovery.seed_hosts:[192.168.0.1, 192.168.0.2 ... ]
cluster.initial_master_nodes: ["node-1", "node-2"]-
elasticsearch.yml 파일에 노드명에 대한 설정을 확인할 수 있다. 내가 환경설정에서 진행했던 노드명이 보인다.
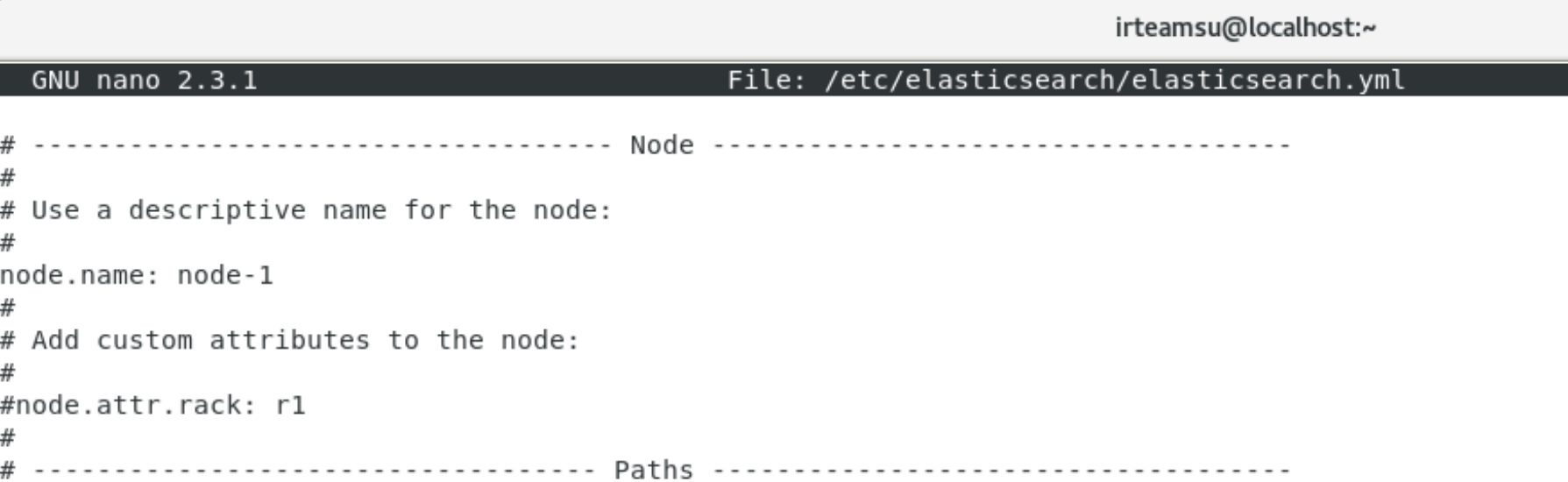
-
내가 설정할 내용은 다음과 같다.
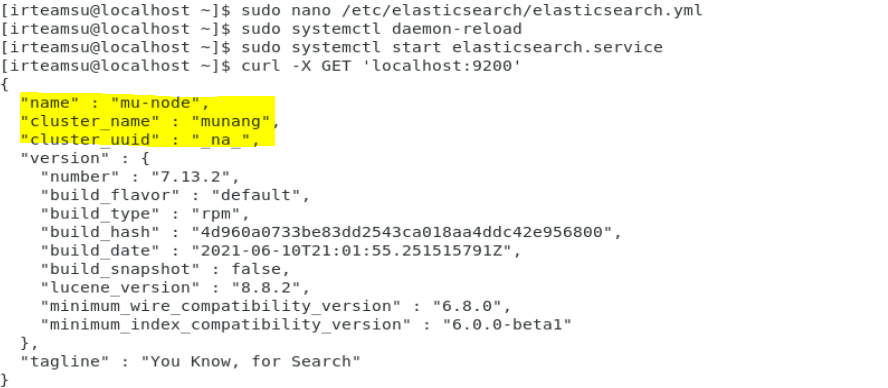
클러스터 네임 : munang
노드 네임 : mu-node
메모리 락 : true
네트워크 호스트 : 로컬 호스트만 접근 가능 -> 나는 가상 머신이라서, 가상머신 내의 ipconfig 명령어를 이용해 주소를 확인했다. 그리고, 바뀐 모습이다.

다시 서비스를 시작해보면 !! 정상적으로 확인됐다.