Chapter 1
실시간 검색어 확인하기
우리는 실시간 검색어를 가져오는 코드(실시간 검색어 크롤링 프로그램)를 작성할 것이다.
하지만, 현재는 실시간 검색어가 없어졌기 때문에 직접 결과를 받아올 순 없고 예전 교육 자료에 나와있는 결과를 사용할 것이다.
크롤러 알아보기
크롤링(Crawling)이란?
- 크롤링을 알기 전 크롤러(Crawler)라는 단어를 살펴보자.
크롤러(Crawler)란?
- 사전에는 다음과 같은 뜻이 나오게 된다.
- 기는 것
- 파충류
=> 우리는 웹 사이트를 기어다니면서 데이터를 모을 것이다. 사실 우리가 직접 기어다니는 건 아니고 우리가 사용할 크롤러가 대신 데이터를 모아줄 것이다.
-> 우리가 원하는 정보를 얻고 싶을 때 보통 구글링을 하는데 '웹 크롤링'을 통해서도 가능하다.
Web Crawler
: 웹 페이지의 데이터를 모아주는 소프트웨어
Web Crawling
: 크롤러를 사용해 웹 페이지의 데이터를 추출해 내는 행위
??우리의 프로그램은 어떻게 실시간 검색어를 가져온다는 걸까요??
-> python의 크롤러를 이용!
블록 조립 키트
터미널에 아래와 같이 입력하면,
pip install requestspip라는 도구가 requests라는 모듈을 찾아서 우리 컴퓨터에 설치해준다.
-> 외부모듈을 설치하게 되면 설치가 다 됐다는 문구와 함께 사용할 수 있게 된다.
만약, 이미 존재하는 모듈의 설치를 입력했다면 아래와 같이 이미 존재 한다는 문구가 뜨게 된다.

코드
- print문으로 requests모듈을 출력해보자.
import requests
print(requests)결과
- 모듈이 이러한 경로에 저장되어 있어 하는 의미의 결과다.

위 내용 이해를 위해서는 파이썬의 함수와 모듈에 대한 이해가 필요하다.
파이썬의 함수란, 자주 사용하는 코드들을 묶어놓고 사용할 수 있게 해주는 것을 의미한다. 반복적인 작업을 줄일 수 있게끔 도와주는 파이썬의 문법이다.
모듈은, 자주 쓰는 함수들을 모아놓은 것이라고 생각하면 된다.
우리는 남들이 만들어놓은 requests라는 모듈을 가져다가 사용법만 익혀 사용하면 된다!
블록 조립 키트 사용법
우리가 requests라는 모듈에서 원하는 값을 얻기 위해서는
1. requests라는 모듈에서
2. get함수를 꺼내
3. 요청을 보내줘
get 함수 -> 자! 여기 응답값~
get 함수 -> 자! 여기 응답값~
이걸 파이썬스럽게 바꾼다면
get 함수 -> return 응답값~-> 우리가 응답값을 요청하니 get함수가 응답값을 만들어 우리에게 return 해주는 것이다.
요청하고 응답받기 1
import 모듈-> 이렇게 사용할 모듈에 대해 명시해 두지 않으면 파이썬은 우리가 이 모듈을 쓰고 싶어하는 것을 알 수가 없다.
// 모듈에 있는 함수를 사용할 때 형식이다.
모듈명.함수이름()코드
- requests.get를 출력해보자.
import requests
print(requests.get)결과
- get이라는 함수라는 뜻.

요청을 보내는 기능
PUT
GET
POST
DELETE-> 이 중 우리는 get요청을 보내는 기능인 get 함수에 대해 알아볼 것이다.
그렇지만, 그 이전에 요청이 무엇인지 알아보자.
요청과 응답이란?
client(손님), server(요리사)라고 예를 들어보자.
- 요청: client -> server: 손님이 요리사에게 음식 주문하는 것과 비슷
- 응답: server -> client: 요리사가 손님에게 만든 음식을 주는 것과 비슷
-> client는 요청을 하는 존재, server는 응답을 하는 존재!
요청하고 응답받기 2
get함수는 다음과 같이 사용이 가능하다.
아래 내용은 requests 모듈 공식 홈페이지에서 가져온 것이다.

- 여기서 우리가 살펴봐야 할 정보는 딱 세가지이다.
- requests.get(url,params=None,**kwars)
- Parameters
- Returns
requests.get(url)
-> return(응답값): requests.response- url: 우리가 요청을 보낸 서버의 주소이다.
요청하고 응답받기 3
서버에 요청을 보내고 응답을 출력해보는 코드를 작성해보자.
import requests
requests.get(url)-> url이 정의되어 있지 않아 오류가 발생한다.
코드
url을 정의해서 결과를 보자.
import requests
url = "http://www.daum.net"
print(requests.get(url))결과
<Response [200]>-> Response문구와 함께 200이라는 숫자가 함께 왔다. 200이라는 숫자는 코딩에서 성공을 의미한다. 우리의 요청이 성공적으로 갔고 응답을 잘 받아왔다는 뜻이다.
그러나 '<Response [200]>'은 우리가 원하는 응답값이 아니다!
import requests
url = "http://www.daum.net"
response = requests.get(url)
print(response.text) // 응답 텍스트 출력 결과
<!DOCTYPE html><html lang="ko"> <head> <meta charset="utf-8" /> <title>Daum</title> <meta http-equiv="x-ua-compatible" content="IE=edge" /> <meta property="og:url" content="//www.daum.net/" /> <meta property="og:type" content="website" /> <meta property="og:title" content="Daum" /> <meta http-equiv="Pragma" content="no-cache" /> <meta http-equiv="Expires" content="-1" /> <meta name="referrer" content="origin" /> <meta property="og:image" content="https://i1.daumcdn.net/svc/image/U03/common_icon/5587C4E4012FCD0001" /> <meta property="og:description" content="ëì ê´ì¬ ì½í
ì¸ ë¥¼ ê°ì¥ ì¦ê²ê² ë³¼ ì ìë Daum" /> <meta name="msapplication-task" content="name=Daum;actio/;icon-uri=/favicon.ico" /> <meta name="msapplication-task" content="name=미ëì´ë¤ì;action-uri=//news.daum.net/;icon-uri=/media_favicon.ico" /> <meta name="msapplicatsk" content="name=ë©ì¼;action-uri=//mail.daum.net;icon-uri=/mail_favicon.ico" /> <link href="https://t1.daumcdn.net/top/favicon.ico" rel="shortcut icon" /> <meta name="rerrer" content="origin" /> <link rel="search" type="application/opensearchdescription+xml" href="https://search.daum.net/OpenSearch.xml" title="ë¤ì" /> <link rel="stylesh" href="https://t1.daumcdn.net/top/tiller-pc/20220218_100902/css/common.css" /> <script src="https://t1.daumcdn.net/kas/static/na.min.js"></script> </head> <body> <noscript> ì´ ì¬ì´í¸ì 기ë¥ì 모ë íì©í기 ìí´ìë ìë°ì¤í¬ë¦½í¸ë¥¼ íì±í ìí¬ íìê° ììµëë¤. <a href="https://www.enable-javascript.com/ko/"ì°¸ê³ íì¸ì. </noscript> <script src="https://t1.daumcdn.net/tiara/js/v1/tiara.min.js" type="text/javascript"></script> <script src="https://t1.daumcdn.net/top/tiller-b/1636937121956/polyfill.min.js" type="text/javascript" ></script> <script src="https://t1.daumcdn.net/top/tiller-pc/20220218_100902/js/app.js" type="text/javascript"></script> <script src="https://t1.daumcdn.net/kas/static/ba.min.js" type="text/javascript" defer></script> <script src="https://t1.daumcdn.net/top/tiller-pc/1632900517149/tiller-pc-suggest.js" type="text/javascript" defer ></script> </body></html>-> 대략 이런 html 코드가 온다.
아래 내용은 text뿐 아니라 가져올 수 있는 다양한 응답값이다.
#print(response.text)
#print(response.url)
#print(response.content)
#print(response.encoding)
#print(response.headers)
#print(response.json)
#print(response.links)
#print(response.ok)
#print(response.status_code)하나만 실행해보자.
import requests
url = "http://www.daum.net"
response = requests.get(url)
print(response.encoding)결과
ISO-8859-1Beautiful Soup 1
Beautiful Soup이라는 새로운 기능을 배워보자.
Beautiful Soup는 모듈이 아니라 어떤 모듈의 기능이다.
// 모듈에서 특정 기능만 가져와서 사용할 때 형식
from 모듈명 import 기능
// bs4모듈의 BeautifulSoup 기능을 사용할 것이다. 라는 의미
from bs4 import BeautifulSoup 예시 코드
response.text 출력부분을 주석처리하고, beautiful soup를 이용해서 결과를 출력해보자.
import requests
from bs4 import BeautifulSoup
url = "http://www.daum.net/"
response = requests.get(url)
# print(response.text)
print(BeautifulSoup(response.text, 'html.parser'))결과
<!DOCTYPE html><html lang="ko"> <head> <meta charset="utf-8" /> <title>Daum</title> <meta http-equiv="x-ua-compatible" content="IE=edge" /> <meta property="og:url" content="//www.daum.net/" /> <meta property="og:type" content="website" /> <meta property="og:title" content="Daum" /> <meta http-equiv="Pragma" content="no-cache" /> <meta http-equiv="Expires" content="-1" /> <meta name="referrer" content="origin" /> <meta property="og:image" content="https://i1.daumcdn.net/svc/image/U03/common_icon/5587C4E4012FCD0001" /> <meta property="og:description" content="ëì ê´ì¬ ì½í
ì¸ ë¥¼ ê°ì¥ ì¦ê²ê² ë³¼ ì ìë Daum" /> <meta name="msapplication-task" content="name=Daum;actio/;icon-uri=/favicon.ico" /> <meta name="msapplication-task" content="name=미ëì´ë¤ì;action-uri=//news.daum.net/;icon-uri=/media_favicon.ico" /> <meta name="msapplicatsk" content="name=ë©ì¼;action-uri=//mail.daum.net;icon-uri=/mail_favicon.ico" /> <link href="https://t1.daumcdn.net/top/favicon.ico" rel="shortcut icon" /> <meta name="rerrer" content="origin" /> <link rel="search" type="application/opensearchdescription+xml" href="https://search.daum.net/OpenSearch.xml" title="ë¤ì" /> <link rel="stylesh" href="https://t1.daumcdn.net/top/tiller-pc/20220218_100902/css/common.css" /> <script src="https://t1.daumcdn.net/kas/static/na.min.js"></script> </head> <body> <noscript> ì´ ì¬ì´í¸ì 기ë¥ì 모ë íì©í기 ìí´ìë ìë°ì¤í¬ë¦½í¸ë¥¼ íì±í ìí¬ íìê° ììµëë¤. <a href="https://www.enable-javascript.com/ko/"ì°¸ê³ íì¸ì. </noscript> <script src="https://t1.daumcdn.net/tiara/js/v1/tiara.min.js" type="text/javascript"></script> <script src="https://t1.daumcdn.net/top/tiller-b/1636937121956/polyfill.min.js" type="text/javascript" ></script> <script src="https://t1.daumcdn.net/top/tiller-pc/20220218_100902/js/app.js" type="text/javascript"></script> <script src="https://t1.daumcdn.net/kas/static/ba.min.js" type="text/javascript" defer></script> <script src="https://t1.daumcdn.net/top/tiller-pc/1632900517149/tiller-pc-suggest.js" type="text/javascript" defer ></script> </body></html>-> 결과는 아까 그냥 response.text를 출력한 것과 같다.
그렇지만, 둘은 다른 데이터다.
Beautiful Soup 2
두개의 데이터가 어떻게 다른지 알아보기 위해 각각 type()을 씌워서 확인해보자.
코드
import requests
from bs4 import BeautifulSoup
url = "http://www.daum.net/"
response = requests.get(url)
print(type(response.text))
print(type(BeautifulSoup(response.text, 'html.parser')))결과
<class 'str'>
<class 'bs4.BeautifulSoup'>-> 위 결과를 보면 str타입이었던 response.text를 bs4.BeautifulSoup로 형변환 했다는 것을 알 수 있다.
BeautifulSoup 기능은?
- 어떤 통에다가 정보를 담아주는 기능이다.
Beautiful Soup 3
Beautiful Soup로 무얼 할 수 있을까?
형식
BeautifulSoup(데이터, 파싱방법)- 데이터에는 xml, html이 올 수 있다.
- 그래서 우리는 response.text(html)를 데이터 자리에 넣을 수 있는 것이다. - 파싱은 쉽게 말해서 우리의 문서, 우리의 데이터를 의미있게 변경하는 작업이라고 생각하면 된다.
- 즉, 어떤 문장, 어떤 문자열을 분석해서 의미 있는 것으로 변경한다.
- 이러한 파싱을 해주는 것을 parser라 한다. 우리는 기본 내장되어있는 html파서(html.parser)를 사용할 것이다.
(BeautifulSoup(response.text, 'html.parser')코드
- 우리가 만든 BeautifulSoup도 한 변수에 저장해서 사용해보자.
import requests
from bs4 import BeautifulSoup
url = "http://www.daum.net/"
response = requests.get(url)
# print(type(response.text))
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.title) // beautifulsoup로 나온 결과의 title 출력결과
<title>Daum</title>-> title 태그와 그 내용이 나온 것을 알 수 있다.
Beautiful Soup 4
코드
import requests
from bs4 import BeautifulSoup
url = "http://www.daum.net/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.title)
print(soup.title.string) //변경된 코드결과
<title>Daum</title>
Daum-> string을 출력하니 태그 안 내용값만 출력이 된다.
코드
import requests
from bs4 import BeautifulSoup
url = "http://www.daum.net/"
response = requests.get(url)
print(response.text)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.title)
print(soup.title.string)
//추가코드 2줄
print(soup.span) //span태그를 출력해라.
print(soup.findAll('span')) //모든 span태그를 출력해라.결과
- span태그가 너무 많아 결과창을 올리기에 너무 길어지니 설명만 적겠다.
print(soup.span)의 경우는 1개의 span태그만 출력이 되고,
print(soup.findAll('span'))는 html 코드에 있는 모든 span태그가 나오게 된다.reference
beautifulsoup 문서
Beautiful Soup 5
많은 데이터 중 우리가 원하는 실시간 검색어만 가져와보자.
코드
- 가져온 데이터를 html문서에 저장해보자.
from bs4 import BeautifulSoup
import requests
url = "http://www.daum.net/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
//추가된 코드 - 파일 생성 및 작성 코드
file = open("daum.html","w") // daum.html이라는 파일을 생성하자.
file.write(response.text) // response.text내용을 파일에 작성하자.
file.close() // 다 작성했으니 닫자.
//
print(soup.title)
print(soup.title.string)
print(soup.span)
print(soup.findAll('span'))-> 파일 작성하는 것은 나중에 자세히 배우자.
결과
- html 문서가 생성됨을 알 수 있다.
(내용이 너무 길어 문서 내용을 올릴 수가 없음.)
Beautiful Soup 6
받은 html 코드에서 실시간 검색어만이 가진 공통점을 찾아 그것만 뽑아와보자.
from bs4 import BeautifulSoup
import requests
url = "http://www.daum.net/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# html 문서에서 모든 a태그를 가져오는 코드
print(soup.findAll("a"))-> 그런데 a태그안에 묶인 태그들까지 같이 출력된다.
하지만 우리는 모든 a태그만이 아니라 실시간 검색어만 필요하다.
아래와 같이 작성해서 원하는 것만 가져오자.
// 모든 a태그 중 class가 link_favorsch인 것을 다 가져오라는 뜻.
print(soup.findAll("a","link_favorsch"))예쁘게 출력하기
코드
from bs4 import BeautifulSoup
import requests
url = "http://www.daum.net/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.findAll('a','link_favorsch')
print(results)결과
리스트에 담겨서 [실시간검색어1, 실시간검색어2, ...] 이렇게 실시간 검색어가 콤마로 구분되어 출력된다.
(너무 길어 내용 생략.)
-> 그래서 우리는 반복문을 사용해 하나씩 출력해 볼 것이다.
코드
from bs4 import BeautifulSoup
import requests
url = "http://www.daum.net/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.findAll('a','link_favorsch')
for result in results:
print(result,"\n")결과
리스트의 요소로 이루어졌던 결과들이 하나씩 출력되는 것을 볼 수 있다.
하지만, 우리는 실시간검색어를 보고 싶은 것이지 그 태그 전체를 보고싶은 것이 아니다.
코드
from bs4 import BeautifulSoup
import requests
url = "http://www.daum.net/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.findAll('a','link_favorsch')
for result in results:
print(result.get_text(),"\n")결과

이런식으로 검색어만 나온다.
순위도 함께 출력해보자.
코드
from bs4 import BeautifulSoup
import requests
url = "http://www.daum.net/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
rank = 1
results = soup.findAll('a','link_favorsch')
for result in results:
print(rank,"위 : ",result.get_text(),"\n")
rank += 1결과

이번엔 몇 월 며칠의 실시간 검색어인지 뽑아 볼 것이다.
실시간 검색어는 말 그대로 실시간이기에 당일 날짜를 출력하면 된다.
코드
print(datetime.today())결과
- 오늘 날짜를 출력하게 된다.
2022-02-25 05:07:57.537312하지만 우리는 위와 같이 번거롭게 시간까지는 필요가 없다.
다음과 같이 깔끔하게 변경해주자.
print(datetime.today().strftime("%Y년 %m월 %d일의 실시간 검색어 순위입니다."))결과
2022년 02월 25일의 실시간 검색어 순위입니다.파일로 출력하기
- 파일을 새로 만들거나, 읽어서 가져오거나 파일의 내용을 수정하고 싶으면 python의 open()내장함수를 사용해야 한다.
- python이 기본으로 가지고 있는 기능이기 때문에 우리는 사용법만 익히면 바로 사용할 수 있다.
open(파일, 모드)- 이 함수를 사용하기 위해서는 파일, 모드가 필요하다.
- 파일은 원하는 파일명과 확장자를 정해 사용하면 된다.
open("파일명.파일확장자",모드)- 모드는 우리가 읽거나 쓸 대상이 되는 파일의 상태를 의미한다.
- open 함수에서 정해져 있는 키워드들이 있다.- 'r' -> read: 읽기 전용 모드로 파일을 연다.
- 'w' -> write: 새로 쓰거나 수정할 수 있다. 기존 내용이 있어도 새로운 내용으로 덮어씌워지게 된다.
- 'a' -> append: 기존파일을 보존하고 거기에 내용을 덧붙여 작성할 수 있다.
코드
from bs4 import BeautifulSoup
import requests
from datetime import datetime
url = "http://www.daum.net/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
rank = 1
results = soup.findAll('a','link_favorsch')
//rankresult.txt라는 파일을 쓰기 모드로 연다는 뜻이다.
search_rank_file = open("rankresult.txt","w")
print(datetime.today().strftime("%Y년 %m월 %d일의 실시간 검색어 순위입니다.\n"))
for result in results:
//파일 작성 내용
search_rank_file.write(str(rank)+"위:"+result.get_text()+"\n")
print(rank,"위 : ",result.get_text(),"\n")
rank += 1결과
-> 텍스트 파일이 생성된 것을 볼 수 있다.
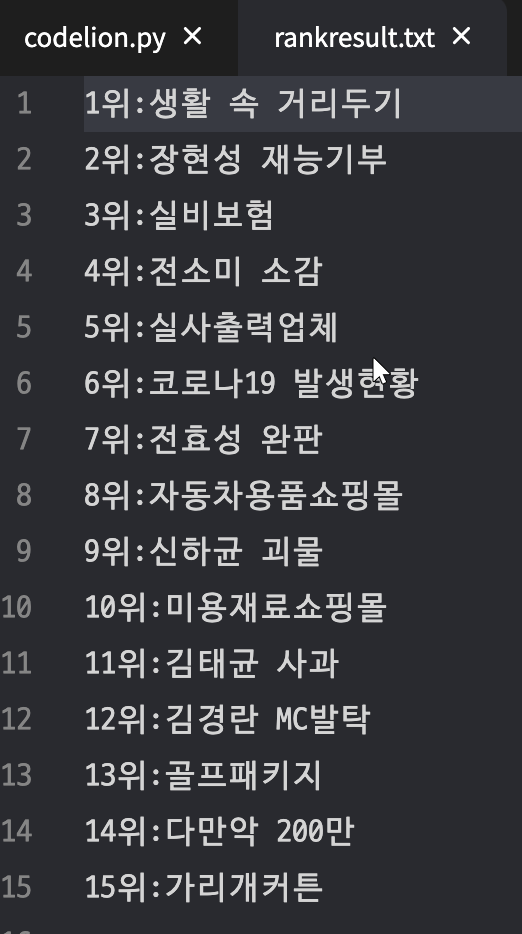
-> 텍스트 파일 안에 우리가 작성한 내용이 쓰여 있는 것을 알 수 있다.
원래 코드에서 한글자만 수정해서 파일에 내용을 덧붙이는 코드로 변경해보자.
코드
...
search_rank_file = open("rankresult.txt","a") // "w"를 "a"로 변경
...-> 이렇게 open함수의 모드를 a로 변경하면 내용을 덮어 버리는 것이 아닌 뒤에 덧붙여지게 된다.
응용 해보기
네이버 급상승 검색어를 가져와보자.
그렇지만, 내용을 가져오려는 경우 존재하지 않는 웹사이트라는 말이 뜬다.
이것은 코드가 잘못된 것이 아니다.
- 네이버와 같은 특정 웹사이트의 경우 불법으로 페이지의 정보를 크롤링 해가거나 정보를 수집하기 위한 행위를 하는 로봇들을 차단시켜 놓았기 때문이다.
- 크롤링 로봇들이 와서 네이버에 있는 모든 정보들을 가져가거나 숨어있는 정보들을 빼내간다면 문제가 되기 때문이다.
하지만, 우리는 로봇이 아니다. 그래서 이와 같이 로봇을 방지하기 위해 접근을 막은 사이트의 경우 다른 방법을 사용해 주어야 한다.
- 난 로봇이 아니고 잠깐 크롤링을 하는 한 사용자일 뿐이야라고 말해주는 구문이 필요하다. 그 구문은 바로 아래와 같다.
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}-> 우리의 정보를 담아서 보낸다.
-> 우리는 로봇이 아니고 이러한 환경에서 코딩을 하고 있는 유저야라고 설명해주는 것이다.
-> 이렇게 만들어진 header를 request.get요청을 보낼때 같이 보내줘야 한다.
- 다음과 같이 수정하면 된다.
response = requests.get(url,headers=headers)그럼 이제 값을 가져올 수 있게 된다.
전체 코드
from bs4 import BeautifulSoup
import requests
from datetime import datetime
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url = "https://datalab.naver.com/keyword/realtimeList.naver?age=20s"
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
rank = 1
# span - item_title
results = soup.findAll('span','item_title')
print(response.text)
search_rank_file = open("rankresult.txt","a")
print(datetime.today().strftime("%Y년 %m월 %d일의 실시간 검색어 순위입니다.\n"))
for result in results:
search_rank_file.write(str(rank)+"위:"+result.get_text()+"\n")
print(rank,"위 : ",result.get_text(),"\n")
rank += 1Chapter 2
날씨 정보 받아오기
API key 발급받기
https://home.openweathermap.org/
위 사이트에 접속해 회원가입 후 이메일 인증 하면 API key를 발급받을 수 있다.
API 알아보기
- 목표: API를 사용하여 날씨 정보를 출력하는 프로그램
API(Application Programming Interface)
: client와 server를 연결해준다. - client와 server간 데이터 이동을 도와준다.
"API를 만든다"라는 것은, 사용자가 필요로 하는 기능을 만들고 서버에 올려놓은 뒤에 특정한 규약에 따라 사용할 수 있게 하는 프로그램을 만드는 것이다.
"API를 사용한다"라는 것은, 누군가가 만든 기능을 특정한 규약에 맞춰 사용한다는 것이다. 즉, 사용자가 만드는 프로그램과 기존에 있는 프로그램을 연결해주는 다리가 API다.
따로 비용을 지불하지 않아도 사용이 가능한 API = openAPI라고 부른다.
API key 알아보기
"내가 만든 API를 누가 사용하고 있는걸까?"라는 궁금증이 생겨서 다음부터 API를 만들 때 'API를 사용하려면 누가 사용했는지 기재하고 사용해주세요' 하고 조건을 넣은 것이다.
다음과 같이 말이다.

-> 여기서는 '철수', '영희'가 API key이다.
- API를 사용할 때 본인이 누구인지 나타내는 것을 API key라고 한다.
- 위와 같이 '철수', '영희'와 같이 흔한 이름으로 API key를 지정하는 것이 아니라 식별할 수 있는 고유의 문자열로 이루어져 있다.
API 링크 만들기
- openweathermapAPI를 사용하기 위해서 사이트에 들어가 API doc을 눌러 API 사용 설명을 읽자.
- API doc에 들어가게 되면 아래와 같이 API를 호출할 수 있는 주소가 나와있다.
api = "http://api.openweathermap.org/data/2.5/weather?q={city name}&appid={your api key}"-> 위 주소 중 중괄호로 감싸 있는 city name, your api key 같은 경우는 우리가 직접 채워주어야 하는 부분이다. 이 부분을 parameter라고 한다.
우리는 파이썬의 기능인 "f-string"을 이용해 저 주소문자열에 city name과 api key를 넣어 줄 것이다.
f-string이란
- 아래와 같이 문자열의 맨 앞에 'f'를 붙여 f-string을 사용하면 우리가 사용하는 변수명을 중괄호 안에 적어주면 된다.
- 변수를 넣어 사용하고 싶을 땐 항상 중괄호를 해주어야 한다.
코드 - api key는 암호화
city = "Seoul"
apikey = "################################"
api = f"http://api.openweathermap.org/data/2.5/weather?q={city}&appid={apikey}"
print(api)결과
http://api.openweathermap.org/data/2.5/weather?q=Seoul&appid=################################날씨 받아오기
api = f"http://api.openweathermap.org/data/2.5/weather?q={city}&appid={apikey}"-> ?를 기준으로 왼쪽은 공통 api 주소이고 뒷쪽은 파라미터이다.
- requests모듈로 요청을 보내보자.
코드
import requests
city = "Seoul"
apikey = "################################"
api = f"http://api.openweathermap.org/data/2.5/weather?q={city}&appid={apikey}"
result = requests.get(api)
print(result)결과
<Response [200]>코드
- result의 text를 출력해보자.
import requests
city = "Seoul"
apikey = "################################"
api = f"http://api.openweathermap.org/data/2.5/weather?q={city}&appid={apikey}"
result = requests.get(api)
print(result.text)결과
{"coord":{"lon":126.9778,"lat":37.5683},"weather":[{"id":721,"main":"Haze","description":"haze","icon":"50d"}],"base":"stations","main":{"temp":279.45,"feels_like":276.54,"temp_min":277.84,"temp_max":280.81,"pressure":1024,"humidity":75},"visibility":3800,"wind":{"speed":4.12,"deg":240},"clouds":{"all":75},"dt":1645780695,"sys":{"type":1,"id":8105,"country":"KR","sunrise":1645740593,"sunset":1645780856},"timezone":32400,"id":1835848,"name":"Seoul","cod":200}-> 지금 보내준 정보는 너무 많으니 원하는 정보만 뽑아주자.
예쁘게 출력하기 1
우리가 받아온 응답이 사실은 json타입이다.
json이란, javascript object notation의 줄임말이다.
- 여기서는 데이터를 주고 받을 때 사용하는 포맷이라고 생각하면 된다.
- 파이썬의 dictionary와 모양이 같다.
- 문자열을 json 으로 변경하기 위해서는 아래와 같이 사용하면 된다.
json.loads(str)코드
import requests
import json
city = "Seoul"
apikey = "################################"
api = f"http://api.openweathermap.org/data/2.5/weather?q={city}&appid={apikey}"
result = requests.get(api)
data = json.loads(result.text)
print(type(result.text))
print(type(data))결과
<class 'str'>
<class 'dict'>-> type이 str에서 dict로 바뀐 것을 확인 할 수 있다.
예쁘게 출력하기 2
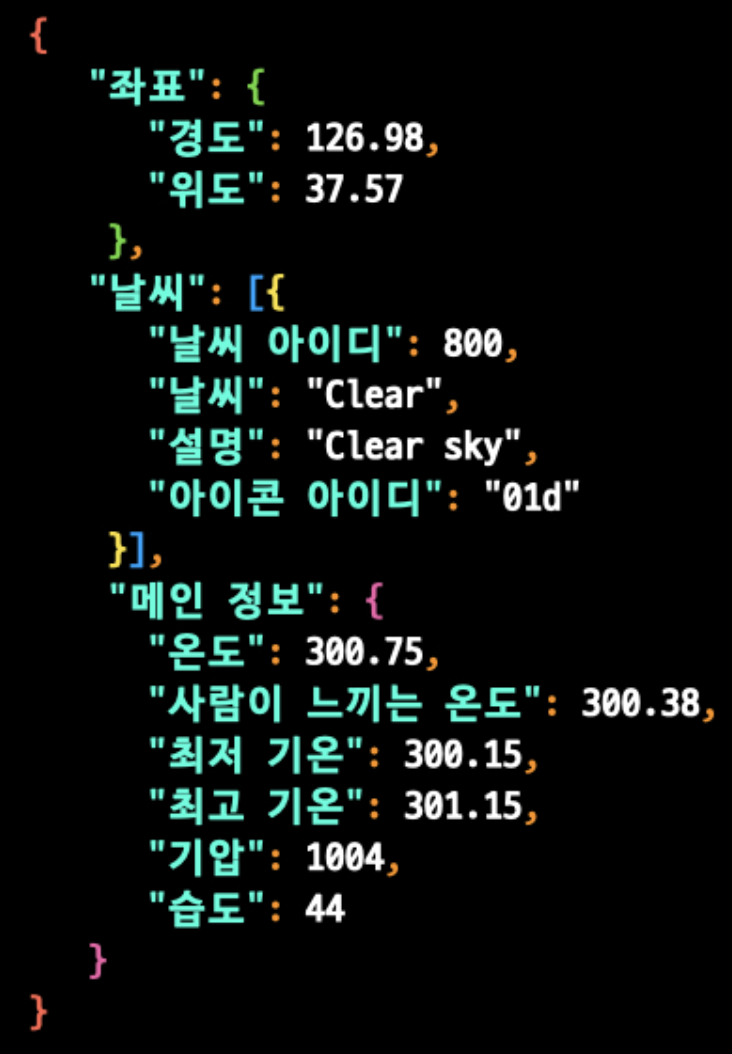
코드
- 원하는 날씨 정보를 뽑아 출력해보자.
import requests
import json
city = "Seoul"
apikey = "################################"
api = f"http://api.openweathermap.org/data/2.5/weather?q={city}&appid={apikey}"
result = requests.get(api)
data = json.loads(result.text)
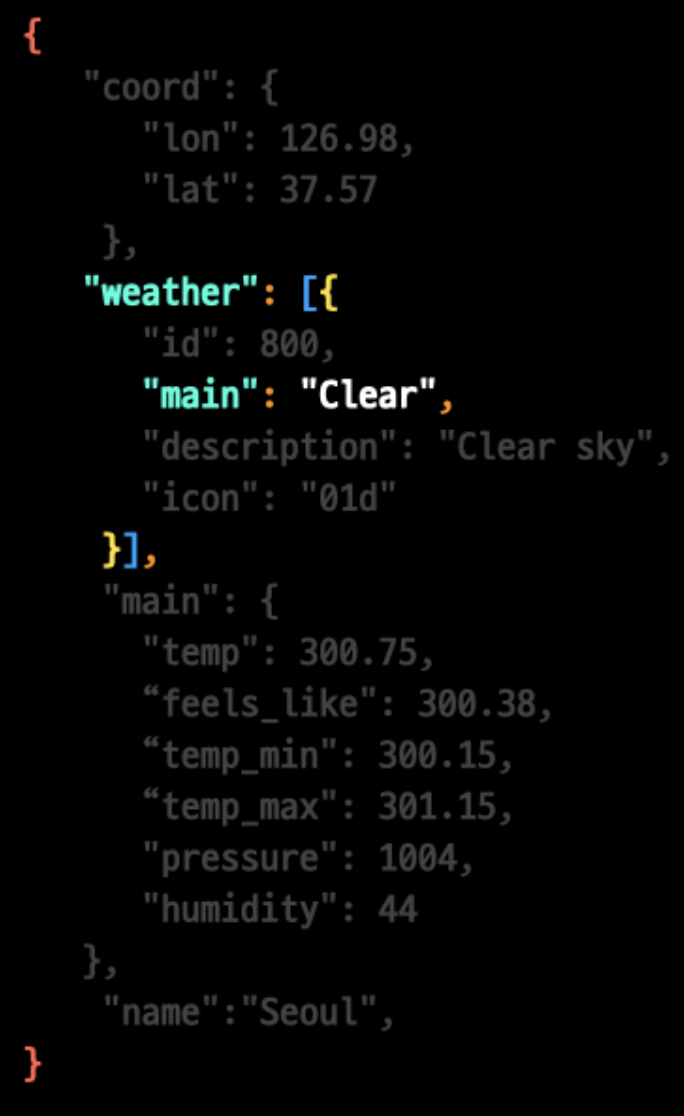
print(data["name"],"의 날씨입니다.")
print("날씨는 ",data["weather"][0]["main"],"입니다.")
print("현재 온도는 ",data["main"]["temp"],"입니다.")
print("하지만 체감 온도는 ",data["main"]["feels_like"],"입니다.")
print("최저 기온은", data["main"]["temp_min"], "입니다.")
print("최고 기온은", data["main"]["temp_max"], "입니다.")
print("습도는", data["main"]["humidity"], "입니다.")
print("기압은", data["main"]["pressure"], "입니다.")
print("풍향은", data["wind"]["deg"], "입니다.")
print("풍속은", data["wind"]["speed"], "입니다.")결과
Seoul 의 날씨입니다.
날씨는 Haze 입니다.
현재 온도는 279.57 입니다.
하지만 체감 온도는 276.69 입니다.
최저 기온은 277.84 입니다.
최고 기온은 280.81 입니다.
습도는 68 입니다.
기압은 1024 입니다.
풍향은 240 입니다.
풍속은 4.12 입니다.-> 온도는 화씨로 나오니 섭씨로 바꿔주자.
언어 및 단위 변경하기
import requests
import json
city = "Seoul"
apikey = "################################"
lang = "kr" // 한국어
# lang, units라는 파라미터를 추가해서 한국어로 변경하고, 화씨를 섭씨 온도로 변경 했다.
api = f"""http://api.openweathermap.org/data/2.5/\
weather?q={city}&appid={apikey}&lang={lang}&units=metric"""
result = requests.get(api)
# print(result.text)
data = json.loads(result.text)
# 지역 : name
print(data["name"],"의 날씨입니다.")
# 자세한 날씨 : weather - description
print("날씨는 ",data["weather"][0]["description"],"입니다.")
# 현재 온도 : main - temp
print("현재 온도는 ",data["main"]["temp"],"입니다.")
# 체감 온도 : main - feels_like
print("하지만 체감 온도는 ",data["main"]["feels_like"],"입니다.")
# 최저 기온 : main - temp_min
print("최저 기온은 ",data["main"]["temp_min"],"입니다.")
# 최고 기온 : main - temp_max
print("최고 기온은 ",data["main"]["temp_max"],"입니다.")
# 습도 : main - humidity
print("습도는 ",data["main"]["humidity"],"입니다.")
# 기압 : main - pressure
print("기압은 ",data["main"]["pressure"],"입니다.")
# 풍향 : wind - deg
print("풍향은 ",data["wind"]["deg"],"입니다.")
# 풍속 : wind - speed
print("풍속은 ",data["wind"]["speed"],"입니다.")결과
Seoul 의 날씨입니다.
날씨는 맑음 입니다.
현재 온도는 7.04 입니다.
하지만 체감 온도는 5.48 입니다.
최저 기온은 2.42 입니다.
최고 기온은 7.66 입니다.
습도는 85 입니다.
기압은 1025 입니다.
풍향은 224 입니다.
풍속은 2.3 입니다.Chapter 3
번역하기
미리보기

googletrans 알아보기
googletrans란?
: 언어 감지 및 번역 기능을 가진 모듈. 즉, 라이브러리이다.
- 우리가 앞에서 배웠던 모듈을 큰 기능 단위로 묶어둔 것을 라이브러리라고 부르는데 그런 의미에서 googletrans는 큰 기능을 가진 모듈의 집합
- 언어 감지 및 번역을 도와주는 라이브러리라고 볼 수 있다.
언어 감지란?
: "안녕하세요는 한국어고, hello는 영어다"라고 감지해주는 것이다.
우리는 translator라는 기능만 사용할 것이다.
코드
from googletrans import translator
print(translator)결과
<class 'googletrans.client.Translator'>언어 감지하기
언어를 감지 하기 위해서는 다음과 같은 순서가 필요하다.
1. 번역기를 만든다.
2. 언어 감지를 원하는 문장을 설정한다.
3. 언어를 감지한다.
1.번역기를 만든다.
Translator()이 기능을 사용해 번역기를 만들자.
2. 언어 감지를 원하는 문장을 설정한다.
translator.detect(언어감지를 원하는 문장)코드
from googletrans import Translator
translator = Translator()
sentence = "안녕하세요 코드라이언입니다."
detected = translator.detect(sentence)
print(detected)결과
Detected(lang=ko, confidence=1)-> lang=ko라는 결과는 한국어라는 뜻이다.
-> confidence는 언어 감지 신뢰도이다. 1이면 높은 것.
3. 언어를 감지한다.
detected만으로 lang값만 가져오고 싶을 때?
detected.lang코드
from googletrans import Translator
translator = Translator()
sentence = "안녕하세요 코드라이언입니다."
detected = translator.detect(sentence)
print(detected.lang)결과
ko직접 언어를 입력받아서 감지해보자.
코드
from googletrans import Translator
translator = Translator()
sentence = input("언어를 감지할 문장을 입력해주세요 : ")
detected = translator.detect(sentence)
print(detected.lang)번역하기 1
- 번역기를 만든다.
- 번역을 원하는 문장을 만든다.
- 번역을 원하는 언어를 설정한다.
- 번역을 한다.
번역기는 이전에 만들어둔 것이 있기에 그것을 사용하자.
2. 번역을 원하는 문장을 만든다.
3. 번역을 원하는 언어를 설정한다.
//dest: destination의 줄임말, src(source text)
translate(text, dest, src)
translate(번역을 원하는 문장 , 어떤 언어로 번역을 할지, 소스(생략가능))-> src가 생략 가능한 이유는 translator()에서 언어 감지를 잘 해주기 때문에
코드
from googletrans import Translator
translator = Translator()
sentence = "안녕하세요 코드라이언입니다."
result = translator.translate(sentence,'en')
print(result)결과
Translated(src=ko, dest=en, text=Hello, I'm Coderian., pronunciation=None, extra_data="{'translat...")->translate라는 함수를 사용하면 위와 같은 정보들을 translated라는 통에 담아서 돌려주게 된다.
-> pronunciation=None은 영어로 번역할 경우 발음을 표시 해 줄 필요가 없기에 None이라고 뜬다.
-> extra_data는 text와 pronunciationi을 제외한 부수적인 것이 번역된 부분이라고 보면 된다.
번역하기 2
4. 번역을 한다.
코드
from googletrans import Translator
translator = Translator()
sentence = "안녕하세요 코드라이언입니다."
result = translator.translate(sentence,'en')
detected = translator.detect(sentence)
print("===========출 력 결 과===========")
print(detected.lang,":",sentence)
print(result.dest,":",result.text)
print("=================================")결과
===========출 력 결 과===========
ko : 안녕하세요 코드라이언입니다.
en : Hello, I'm Coderian.
=================================여러가지 언어의 lang값
프랑스어: fr
아랍어: ar
베트남어: vi
독일어: de
스페인어: es
몽골어: mn
중국어: zh-CN
힌디어: hi코드
- 사용자가 원하는 문장과 언어로 번역하도록 입력을 받아보자.
from googletrans import Translator
translator = Translator()
sentence = input("번역을 원하는 문장을 입력해주세요 : ")
dest = input("어떤 언어로 번역을 원하시나요?")
result = translator.translate(sentence,dest)
detected = translator.detect(sentence)
print("===========출 력 결 과===========")
print(detected.lang,":",sentence)
print(result.dest,":",result.text)
print("=================================")결과
번역을 원하는 문장을 입력해주세요 : 안녕
어떤 언어로 번역을 원하시나요?fr
===========출 력 결 과===========
ko : 안녕
fr : salut
=================================Chapter 4
메일 보내기
- 파이썬으로 메일을 보내보자!(gmail 사용예정)
사전 준비
Google 보안 수준 변경하기
- 메일 계정의 외부 접속에 대한 보안 설정
- Google 메인 페이지에 접속 합니다.
- 프로필 이미지 클릭, 'Google 계정 관리' 버튼을 클릭 합니다.
- 좌측 '보안' 탭을 클릭 합니다.
- 액세스 사용 설정 페이지로 진입 합니다.
- (4-1) '보안 수준이 낮은 앱의 액세스' 섹션을 찾습니다. (보안 탭의 하단에 위치하고 있습니다.)
- (4-2) '액세스 사용 설정(권장하지 않음)' 텍스트를 클릭 합니다.
- '보안 수준이 낮은 앱'의 액세스 권한을 허용 합니다.
- 이제 Python 프로그램이 우리 메일 서버에 접근할 수 있어요.
Google IMAP 설정하기
IMAP이란?
: 다양한 기기에서 이메일에 접근하고 클라이언트 서버에 이메일과 첨부파일을 저장하기 위함이다.
- 이걸 사용으로 해두지 않으면 python 코드에서 동작하지 않는다.
- python 학습이 모두 끝나면 다시 사용안함으로 변경해도 상관없다.
- Google 계정을 준비합니다.
- Gmail 메인 페이지에 접속합니다.
- 상단 톱니를( ⚙️) 클릭 합니다.
- '모든 설정 보기' 버튼을 클릭 합니다.
- 전달 및 POP/IMAP 탭을 클릭 합니다.
- IMAP 액세스 / 상태 값을 'IMAP 사용'으로 변경합니다.
SMTP 1
SMTP란?
: Simple Mail Transfer Protocol의 약자이다. 한국말로 간단히 표현하자면 '간단하게 메일을 보내는 약속'이다.
-
우리의 python code(email client)에서 이메일을 생성해서 SMTP를 이용해 gmail server(email server)로 전송한다.
-
email server끼리 메일을 주고 받을 때도 SMTP를 사용한다.
-
email server가 우리 즉, client에 메일을 전달해 줘야 하는 경우도 있다. 이 경우에 사용하는 것이 IMAP이다.
-
따라서 IMAP 설정을 해주어야 client로 이메일을 가져올 수 있게 되는 것이다.
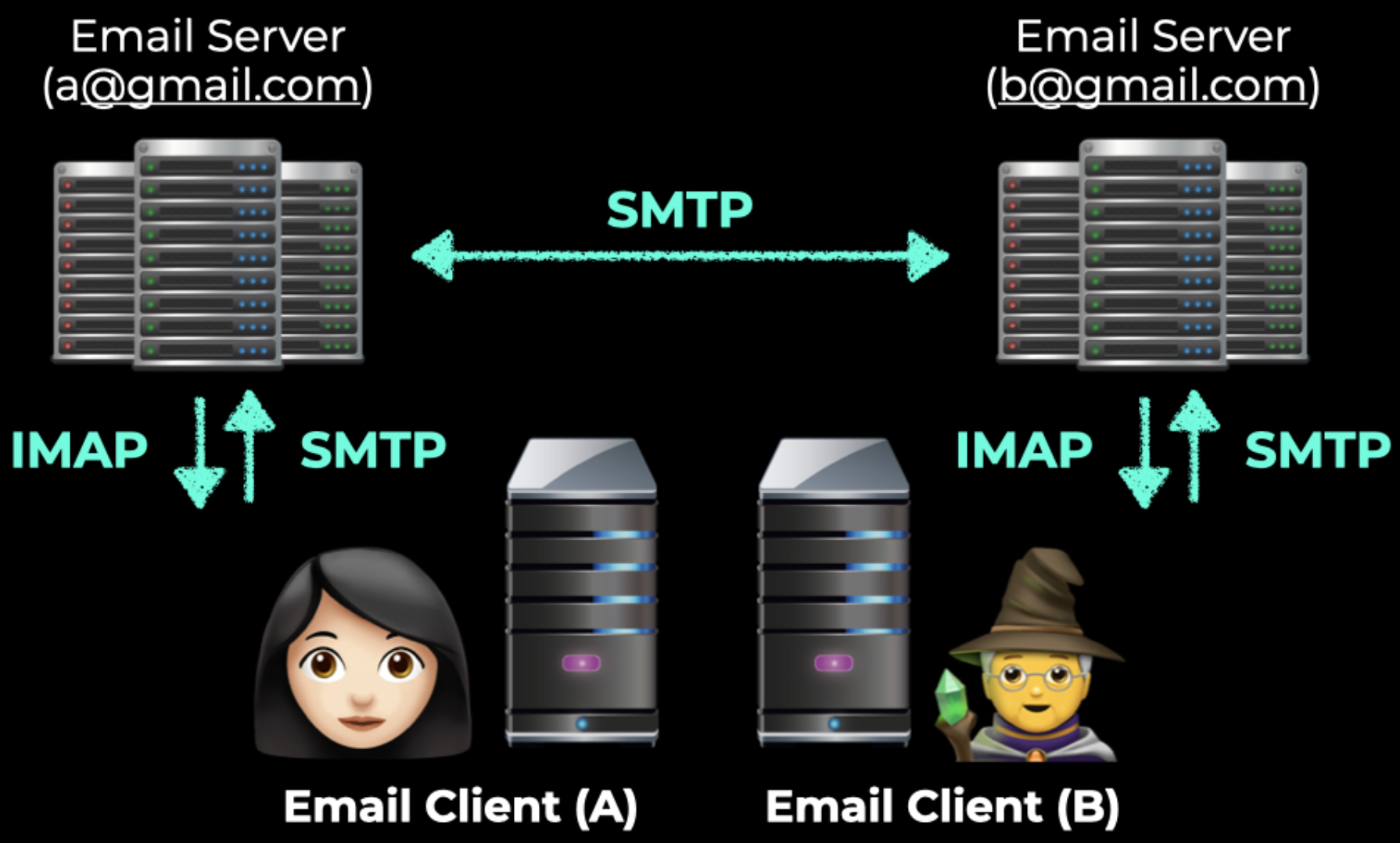
- 우리는 평소 email server에 직접 들어가 SMTP만을 이용해 이메일을 보내기때문에 client입장에서 메일 보내는 것이 생소할 수 있다.
=> SMTP 서버(email server)를 이용해서 우리가 원하는 곳으로 메일을 보낼 수 있다.
SMTP 2
우리가 SMTP 서버에 접속할 때는 대략 smtp.gmail.com라는 주소의 465번 포트를 이용한다고 생각하면 된다.
그리고 SMTP를 좀 더 쉽게 사용할 수 있는 smtplib라이브러리가 있다.
SMTP 3
- SMTP 메일 서버를 연결한다.
- SMTP 메일 서버에 로그인한다.
- SMTP 메일 서버로 메일을 보낸다.
1. SMTP 메일 서버를 연결한다.
smtplib라이브러리는 따로 설치가 필요없다.
import smtplib
smtplib.SMTP(서버주소, 포트번호)코드
import smtplib
SMTP_SERVER = "smtp.gmail.com"
SMTP_PORT = 465 // gmail에서 지정한 포트번호라 변경 불가.
smtp = smtplib.SMTP(SMTP_SERVER,SMTP_PORT)
print(smtp)결과
-> 연결할 수 없다는 메시지가 뜬다.
이것은 바로 보안문제 때문이다.
우리가 사용하는 gmail의 smtp서버는 ssl이라는 것을 필수적으로 요구한다.
이 ssl이란, 아무나 우리 메일 서버에 접근하지 못하도록 하는 막아주는 암호화 방식을 말한다.
우리는 이 암호화 방식을 포함하고 있는 함수를 사용해야 한다.
smtp = smtplib.SMTP_SSL(SMTP_SERVER,SMTP_PORT)코드
import smtplib
SMTP_SERVER = "smtp.gmail.com"
SMTP_PORT = 465
smtp = smtplib.SMTP_SSL(SMTP_SERVER,SMTP_PORT) // 함수가 수정되었다.
print(smtp)결과
<smtplib.SMTP_SSL object at 0x7f3c9a139460>-> 아까의 오류가 뜨지 않는다.
이렇게 되면 우리는 접속이 잘 된 것이다.
SMTP 4
2. SMTP 메일 서버에 로그인한다.
smtp.login(이메일계정, 비밀번호)-> 계정정보로 로그인 할 수 있다.

-> 이렇게 깔끔하게 나오면 로그인이 잘 된 것이다.
3. SMTP 메일 서버로 메일을 보낸다.
smtp.send_message() // 메일을 보내는 함수
smtp.quit() // smtp서버와의 연결 끊기Email Message - MIME
MIME란?
: 메일을 보낼 때 이런형태로 보낼거야~ 하는 약속같은 것이다.
SMTP는 그냥 문서의 말을 못알아듣는다.
그래서 MIME형태로 내용을 변경해서 SMTP한테 보내줘야 하는 것이다.
그 중 우리는 python에 내장되어있는 모듈인 email.message를 이용할 것이다.
email.message 모듈
.EmailMessage 기능MIME형태로 만드는 과정
1. 이메일을 담을 통을 만든다.
2. 이메일에 내용을 담는다.
3. 이메일 제목,발신자, 수신자를 설정한다.
1. 이메일을 담을 통을 만든다.
EmailMessage()-> 이메일을 MIME형태로 만들어주는 하나의 통을 만든 것이다.
2. 이메일에 내용을 담는다.
코드
import smtplib
from email.message import EmailMessage
SMTP_SERVER = "smtp.gmail.com"
SMTP_PORT = 465
message = EmailMessage() // MIME 로 변환하는 통
message.set_content("코드라이언 수업중입니다.") // 메일의 본문을 쓴 것.
smtp = smtplib.SMTP_SSL(SMTP_SERVER,SMTP_PORT)
smtp.login("###@gmail.com","######")
smtp.send_message()
smtp.quit()-> 메일의 제목과 나머지 내용도 적어주자.
Email Message - Header
MIME에는 header 라는 것이 있다.
- 이 header에는 subject, from, to가 있다.
3. 이메일 제목, 발신자, 수신자를 설정한다.
import smtplib
from email.message import EmailMessage
SMTP_SERVER = "smtp.gmail.com"
SMTP_PORT = 465
message = EmailMessage()
message.set_content("코드라이언 수업중입니다.")
message["Subject"] = "이것은 제목입니다."
message["From"] = "###@gmail.com"
message["To"] = "###@gmail.com"
smtp = smtplib.SMTP_SSL(SMTP_SERVER,SMTP_PORT)
smtp.login("###@gmail.com","######")
smtp.send_message()
smtp.quit()메일 전송하기
전체 코드
import smtplib
from email.message import EmailMessage
SMTP_SERVER = "smtp.gmail.com"
SMTP_PORT = 465
# 메일을 담을 내용
message = EmailMessage()
# 메일 본문
message.set_content("코드라이언 수업중입니다.")
# 메일 제목, 발신자, 수신자
message["Subject"] = "이것은 제목입니다."
message["From"] = "###@gmail.com"
message["To"] = "###@gmail.com"
# smtp서버와 ssl연결
smtp = smtplib.SMTP_SSL(SMTP_SERVER,SMTP_PORT)
# 계정 로그인
smtp.login("###@gmail.com","######")
# 메일 전송
smtp.send_message(message)
# smtp 서버와의 연결 끊기
smtp.quit()메일에 사진 첨부하기 1
이미지 파일 읽어오기
이미지를 컴퓨터가 읽을 수 있도록 표현한 것이 binary이다.
이런 binary파일은 jpg, png, exe, mp4, mov 같은 것들이 포함된다.
open()함수 사용
rb -> read binary
wb -> write binary
ab -> append binary코드
image = open("codelion.png","rb")
print(image.read())결과
출력하게 되면 읽을 수 없는 문자들이 막 나온다.(binary파일)
메일에 사진 첨부하기 2
multipart/mixed타입의 메일
: 글만 있는 것이 아니라 다른 요소가 포함된 메일
add_attachment(...)-> 이 add_attachment()를 사용하려면 세가지가 필요하다.
1. image
2. maintype(우리가 첨부할 내용의 종류 like 비디오, 사진등)
3. subtype(확장자)
이미지의 확장자가 바뀌더라도 전송하는데 문제가 없도록 코드를 작성해보자.
import imghdr
image_type = imghdr.what('codelion',image_file)-> 위 모듈은 이미지파일의 확장자를 알 수 있게 해준다.
전체 코드
import smtplib
from email.message import EmailMessage
import imghdr
SMTP_SERVER = "smtp.gmail.com"
SMTP_PORT = 465
message = EmailMessage()
message.set_content("코드라이언 수업중입니다.")
message["Subject"] = "이것은 제목입니다."
message["From"] = "###@gmail.com"
message["To"] = "###@gmail.com"
with open("codelion.png","rb") as image:
image_file = image.read()
image_type = imghdr.what('codelion',image_file)
message.add_attachment(image_file,maintype='image',subtype=image_type) // 이렇게 확장자를 고정하지 않고 사용할 이미지의 확장자에 따라 유연하게 바뀌도록!
smtp = smtplib.SMTP_SSL(SMTP_SERVER,SMTP_PORT)
smtp.login("###@gmail.com","######")
smtp.send_message(message)
smtp.quit()유효성 검사하기 1
이메일 주소의 유효성을 검사한다는 것은 그 이메일 주소가 정말 존재하는 이메일 주소인지 확인하는 것이다.
어떻게 확인하면 좋을까?
-> 이럴때 사용하는 것이 정규표현식이다.
정규표현식이란?
: 쉽게 말해 문자열에서 나타나는 특정 패턴을 알아내서 대응시키기 위해 사용되는 표현식이다.
- 이메일 정규표현식
: 이메일에 나타나는 특정한 패턴을 조건으로 주고 이 문자열이 적합한지 아닌지 확인하는 것이다.
정규표현식


-> 정규표현식에서 대괄호 안에 어떤 문자들이 있다면 이 대괄호는 대괄호 안에 포함된 문자 하나를 가리킨다.
-> 대괄호 뒤 '+'는 앞에 내용이 1회 이상 반복된다는 뜻이다.
-> 이 조건식에 부합하는 문자는 무엇이 있을까요?
ex) codelion.example - 부합한다.
문자는 a-z사이에 있고 .(점)도 포함이어서 부합하는 것이다.



-> 정규표현식으로써의 (.)점이아니라 실제 문자로써의 점이길 바래서 앞에 역슬래쉬()를 넣어준 것이다.

-> 중괄호 안 숫자는{최소값, 최대값}이다.
유효성 검사하기 2
정규표현식을 사용하기 위해서는 re(regular expression의 줄임말) 모듈을 import 해주어야 한다.
re.match(정규표현식, 매칭할 내용)코드
import re
reg = "^[a-zA-Z0-9.+_-]+@[a-zA-Z0-9]+\.[a-zA-Z]{2,3}$" // 정규표현식
print(re.match(reg,"codelion.example@gmail.com")) // 매칭결과 출력결과

매칭이 안됐을 때 결과

유효성 검사하기 3
이메일 주소의 유효성을 검사하고 유효하다면 메일을 보내고 유효하지 않으면 메일을 보내지 않는 함수를 만들어 보자.
함수
def sendEmail(addr):
reg = "^[a-zA-Z0-9.+_-]+@[a-zA-Z0-9]+\.[a-zA-Z]{2,3}$"
if bool(re.match(reg,addr)):
smtp.send_message(message)
print("정상적으로 메일이 발송되었습니다.")
else:
print("유효한 이메일 주소가 아닙니다.")전체 코드
import smtplib
from email.message import EmailMessage
import imghdr
import re
SMTP_SERVER = "smtp.gmail.com"
SMTP_PORT = 465
def sendEmail(addr):
reg = "^[a-zA-Z0-9.+_-]+@[a-zA-Z0-9]+\.[a-zA-Z]{2,3}$"
if bool(re.match(reg,addr)):
smtp.send_message(message)
print("정상적으로 메일이 발송되었습니다.")
else:
print("유효한 이메일 주소가 아닙니다.")
message = EmailMessage()
message.set_content("코드라이언 수업중입니다.")
message["Subject"] = "이것은 제목입니다."
message["From"] = "###@gmail.com"
message["To"] = "###@gmail.com"
with open("codelion.png","rb") as image:
image_file = image.read()
image_type = imghdr.what('codelion',image_file)
message.add_attachment(image_file,maintype='image',subtype=image_type)
smtp = smtplib.SMTP_SSL(SMTP_SERVER,SMTP_PORT)
smtp.login("###@gmail.com","######")
# 메일을 보내는 sendEmail 함수를 호출
sendEmail("###gmailcom")
smtp.quit()결과
정상적으로 메일이 발송되었습니다.