
0. 개요
싸피에서 3주 동안 진행된 알고리즘 커리큘럼의 마지막 시간,,, 문자열 패턴 매칭 알고리즘에 대해 배웠다. 라빈-카프 알고리즘, 보이어-무어 알고리즘, KMP 알고리즘으로 총 3개를 배웠는데 그 중 KMP 알고리즘이 가장 어려웠고 이해가 잘 되지 않는 부분이 있어서 글로써 한 번 정리해보고자 한다!!
1. Knuth-Morris-Pratt Algorithm
- 우리는 불일치가 발생한 문자열의 앞 부분에 어떤 문자가 있는지를 미리 알고 있다. 그래서 검색하고자 하는 패턴을 전처리하여 부분일치 테이블 배열 pi[k]을 구해서 잘못된 시작을 최소화하고자 하는 것이 목적이다
- 부분 일치 테이블은 접두사이면서 접미사인 최대 문자열의 길이가 얼마나 되는지 패턴의 길이마다 저장해놓은 테이블이다.
2. 부분 일치 테이블
pi[] : 부분 일치 테이블
pattern[] : 문자열 패턴
patternLength : pattern의 길이
header: 접두사 포인터 (초기값 1)
footer: 접미사 포인터 (초기값 0)
for header from 1 to patternLength
while footer > 0 && pattern[header] != pattern[footer]
footer = pi[footer - 1]
end while
if (pattern[header] == pattern[footer])
pi[header] = ++footer;
else
pi[header] = 0;
end if
end for여기서 나는 while 부분을 이해하는데 정말 오랜 시간이 걸렸다. 이거를 이해해보려고 그림을 몇 번 그렸는지 모르겠다,,, 우선 while문의 조건이 들어있는 부분을 해석해보자.
footer > 0
header의 초기값은 0이다. 이러한 header가 0보다 큰 시점이 언제일까? 밑에 조건문을 보면 header가 가리키는 문자와 footer가 가리키는 문자가 같을 때 footer는 비로소 1 증가하게 된다.
결국 이 조건의 뜻은 현재 header와 footer가 바라보고 있는 지점의 직전에는 점두사와 접미사가 같은 부분이 있었다는 뜻이 된다.
pattern[header] != pattern[footer]
이 조건은 말 그대로 현재 header와 footer가 바라보고 있는 지점의 문자가 서로 다르다는 뜻이다. 결국 이때의 접두사와 접미사는 다르므로 header를 처리해줘야 하는데 그 방법은 바로
header = pi[header - 1]
이거다. 그런데 이 부분은 내가 느끼기로는 뭔가 이상하다. 분명 배울 때는 header는 패턴에서 접두사를 가리키는 포인터고 pi[]는 접두사와 접미사가 일치하는 문자열의 최대 길이인데 왜 포인터에다가 길이에 관한 정보를 대입하는 걸까?? 원리가 당최 이해가 가지 않았다.
우선 그 의미를 해석하기 전에 이 코드가 도대체 어떤 기능을 해주는지 한번 확인해보자.

여기 문자열 패턴과 각각의 인덱스에 해당하는 부분 일치 테이블이 있다. 이때 header는 5번 인덱스를, footer는 11번 인덱스를 가리키는 시점을 한번 보자.
이 시점에는 while문에 들어가는 두 가지 조건을 다 만족하므로 header = pi[header - 1] 을 실행하게 된다.
그럼 현재 pi[4]는 1이므로 header가 1번 인덱스로 옮겨가게 된다.

그런데 이 때 header와 footer를 다시 비교해보니 둘 다 ‘a’로 문자가 같다. 그래서 pi[11]은 header에 1을 더한 값인 2가 된다.
이렇게 보니 왜 이 코드가 필요한 지에 대해서는 알게 되었다. header와 footer가 가리키는 문자가 다르더라도 실제 세계에서는 접두사와 접미사의 길이만 줄어들고 일치하는 경우가 있을 수 있기 때문이었다.
그렇다면 다시 돌아와서 왜 header에 pi[]라는 의미가 다른 값을 대입하는 걸까?
사실 pi는 header와 완전히 의미가 다른 값은 아니다. 의미적으로는 접두사, 접미사의 길이지만 또한 접두사의 다음 포인터 위치라는 정보도 가지고 있다.
자 그러면 새로운 사진과 함께 다시 pi[header - 1]에 대해서 생각해보자.

이 사진을 보면 0 ~ header의 substring(babcbc)과 header + 1 ~ footer의 substring(babcba)은 다르지만 그 직전 포인터까지의 substring(babcb)은 같다는 것을 알 수 있다.
그러면 header - 1(babcb)이 접미사를 가지고 있다면 그 시점에서의 접두사 또한 존재했다는 뜻이고, footer 또한 그 접두사를 가질 수 있다.
말로 설명하기 어려우니 그림으로 표현해보겠다.
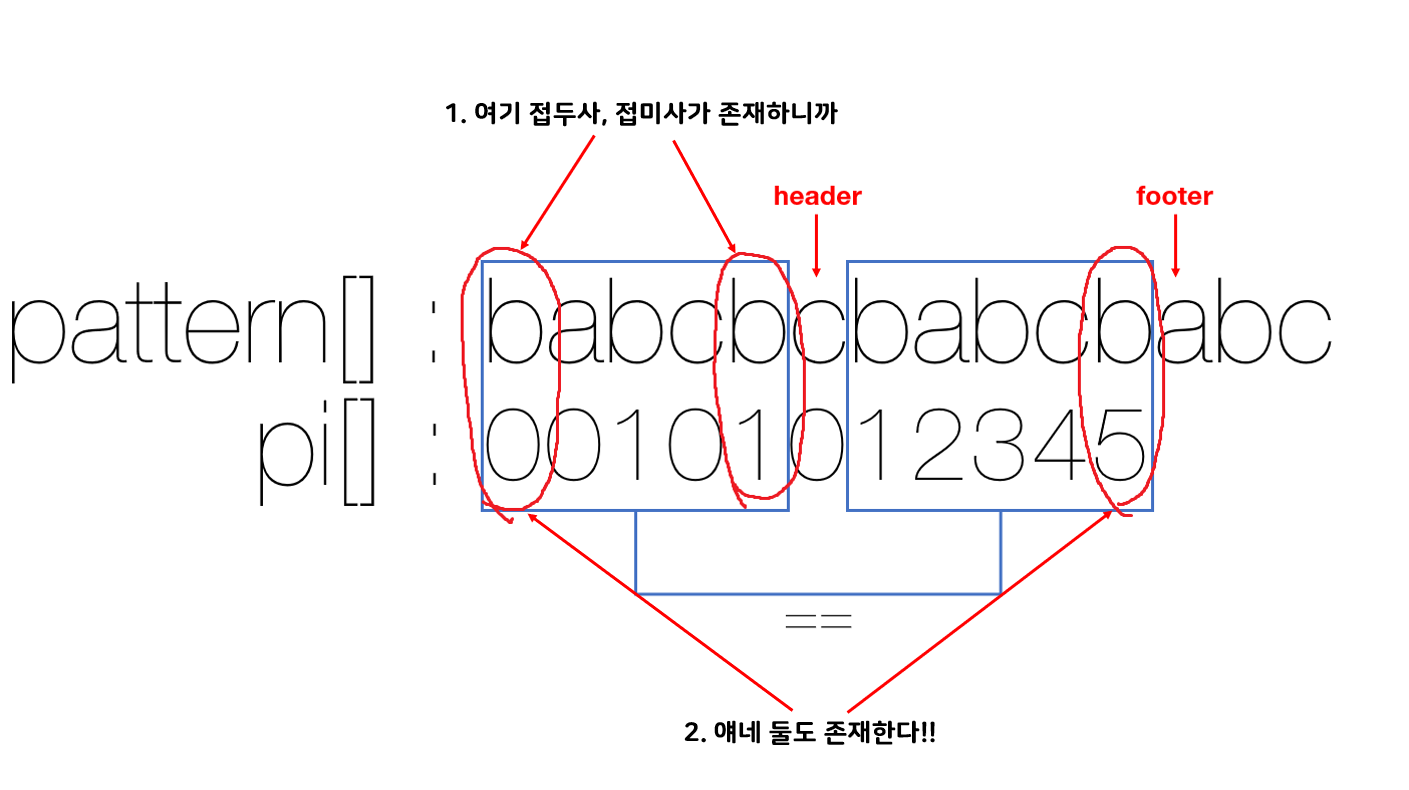
그리고 pi[header - 1]이 곧 babcb일 때 다음 header의 위치이므로 그 위치에 header를 옮겨 준 후 다시 header와 footer를 비교하는 것이다.
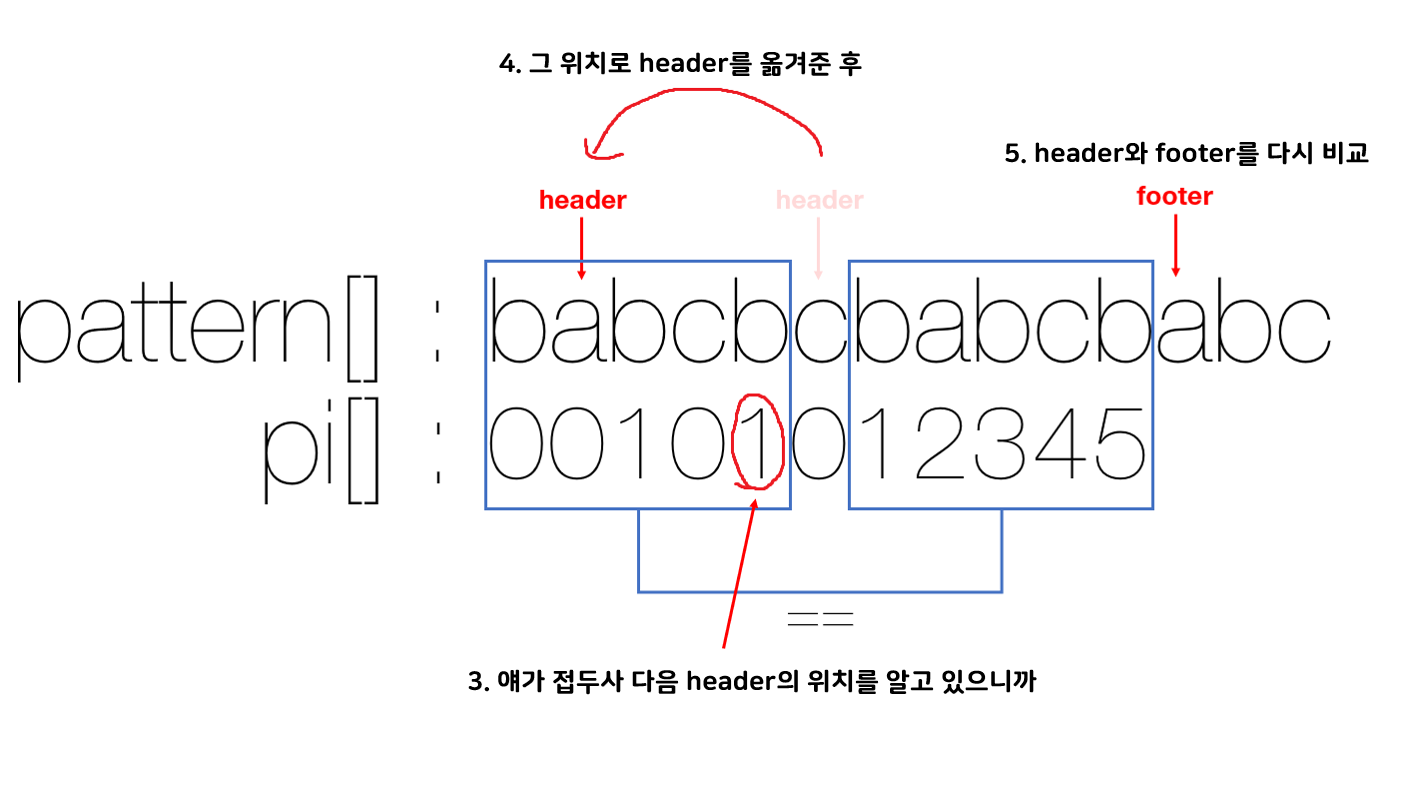
이걸 위해 그 while문을 사용하는 것이다.
그 이후 텍스트 문자열과 패턴을 비교하는 코드는 다른 블로그에도 많으니 따로 적지는 않겠다. 원래 내가 모르는 부분만 정리하려고 했기 때문에...
3. 고찰
블로그에 정리해보면서 KMP에 대해서 조금 더 깊은 이해를 할 수 있게 된 것 같다. 다만 글쓰는 능력이 부족해서 나중에 친구들에게 설명을 하라고 했을 때 블로그를 보여줘서 이해시키기는 어려울 것 같다.. 블로그도 자주 쓰면서 글 쓰는 연습을 자주 하고, 내 생각을 깔끔하게 정리하는 법도 연습을 많이 해야겠다.
