1. 개요
이번에 싸피에서 DB 커리큘럼을 진행하였다. 커리큘럼 대부분의 시간을 SQL 문법을 배우는데 시간을 할애했는데 이 SQL 문법을 실행했을 때 내부적으로 어떻게 동작하는지에 대해서 호기심이 생겼다. 이 내용을 CS 스터디원들과 공유하여 함께 공부하였고, 그 중 내가 정리한 부분에 대해서 이야기해보고자 한다.
2. MySQL 엔진 아키텍처
MySQL 서버는 사람의 머리 역할을 담당하는 MySQL 엔진과 손발 역할을 담당하는 스토리지 엔진으로 구분할 수 있으며, 손과 발 역할을 담당하는 스토리지 엔진은 핸들러 API를 만족하면 누구든지 스토리지 엔진을 구현하여 사용할 수 있다.
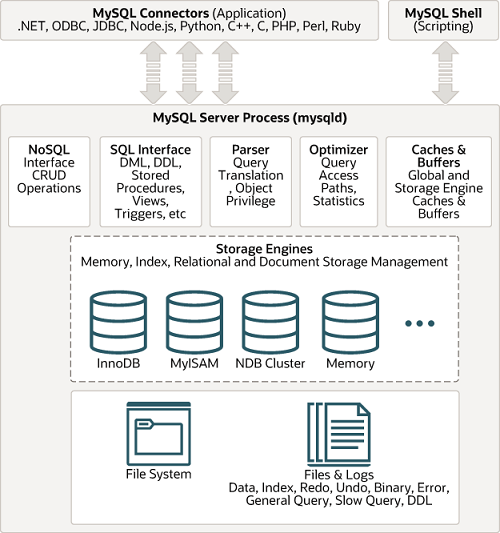
2.1 MySQL Connectors
기본적으로 C를 제외한 웬만한 응용 프로그램 언어에서는 DB 접근 기술에 관련된 인터페이스가 존재한다. 자바의 경우에는 JDBC를 예로 들 수 있다. 하지만 알다시피 자바는 인터페이스뿐만 아니라 구현체가 있어야 클라이언트가 사용할 수 있고, 그러한 구현체는 각각의 DBMS를 제공하는 회사들이 직접 배포한다. MySQL의 Connectors가 그러한 구현체이다.
2.2 MySQL Engine
MySQL 서버의 머리에 해당되는 부분이다.
클라이언트의 요청을 받아 SQL의 질의어가 서버로 들어오게 되면 파서가 질의어를 파싱하여 트리 형태로 구성하게 한다. 트리 형태로 구성된 질의어를 전처리기가 문법상 오류가 없는 지 검증 절차를 가지고, 그 후에 옵티마이저에게 넘겨준다. 옵티마이저는 받은 질의어로 최적화된 실행 계획을 짠다. 이러한 실행 계획을 짜는 방식은 두 가지로 나뉜다.
- 규칙 기반 옵티마이저(Rule Based Optimizer)
- 말 그대로 규칙을 가지고 실행 계획을 생성
- 통계 정보를 조사하지 않고 실행계획이 수립되기 떄문에 거의 항상 같은 실행 방법이 만들어진다.
- 비용 기반 옵티마이저(Cost Based Optimizer)
- 단위 작업의 비용과 대상 테이블의 통계 정보를 이용해 실행 계획별 비용을 산출해서 최소 비용인 실행 방법을 만든다.
최적화 및 실행 계획이 끝나면 이제 스토리지 엔진에 요청해 필요한 데이터를 물리적 장치에서 가지고 온다.
2.3 Storage Engine
스토리지 엔진은 현재 InnoDB가 가장 많이 쓰이므로 InnoDB 위주로 설명한다.
InnoDB의 가장 큰 특징으로는 트랜잭션을 지원한다는 점이다. DB에서는 쪼갤 수 없는 작업의 단위를 트랜잭션이라고 한다.
InnoDB는 In-Memory 구조와 On-Disk 구조로 이루어져 있다.
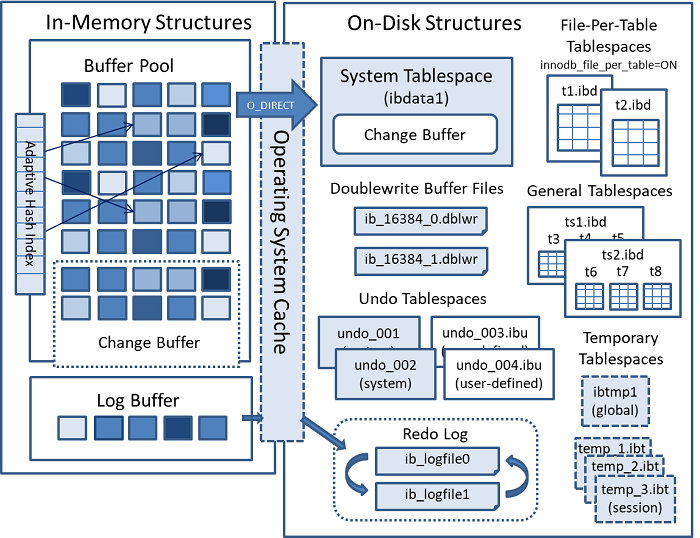
데이터베이스 시스템의 성능 최적화를 위해 목표로 잡은 것은 IO를 줄이는 것이다. 즉 디스크 영역에 접근하는 횟수를 줄이기 위해 메모리 영역에서 처리하는 것을 우선으로 한다.
2.3.1 Buffer Pool
- InnoDB 스토리지 엔진에서 가장 핵심적인 부분
- 테이블이나 인덱스의 데이터를 캐싱하는 메인 메모리 영역. 디스크까지 접근하지 않으므로 처리 속도가 향상된다.
- 변경된 데이터를 버퍼풀에 모았다가 한 번에 디스크에 기록. → I/O를 줄이기 위해서
- But, 버퍼 풀은 메모리 공간이기 때문에 장애 발생 시 버퍼 풀에 있는 내용은 사라지게 된다. 이 말은 곧 ACID 성질을 보장할 수 없게 된다는 말이고 장애가 복구되더라도 데이터는 복구될 수 없다는 것을 말한다.
- SELECT문 동작방식
1. 스토리지 엔진으로부터 실행 계획을 받는다.- 버퍼 풀에서 데이터를 찾는다.
2-1) 데이터 블록이 버퍼 풀에 있으면 클라이언트에게 바로 반환한다. (캐싱)
2-2) 버퍼 풀에 없으면 테이블 스페이스에서 찾는다. 그리고 읽어온 내용을 버퍼 풀에 올려준다.
- 버퍼 풀에서 데이터를 찾는다.
- UPDATE문 동작방식
1. 스토리지 엔진으로부터 실행 게획을 받는다.- 버퍼 풀에서 데이터를 찾는다.
2-1) 데이터 블록이 있으면, 메모리 영역에서 데이터를 변경하고 클라이언트에 반환한다.
2-2) 없으면, 변경 된 기록을 로그 버퍼를 통해 Redo Log에 기록한다. 그리고 변경된 기록은 더티 페이지로써 기록한다. 후에 이벤트가 발생하면 쓰레드가 더티 페이지들을 테이블 스페이스에 저장한다.
- 버퍼 풀에서 데이터를 찾는다.
- 버퍼풀의 LRU 알고리즘
- 새로운 데이터를 버퍼 풀에 추가하기 위해 공간이 필요한 경우 가장 오랫동안 사용되지 않은 페이지를 버퍼풀에서 제공한다.
- 버퍼 풀은 new sublist와 old sublist로 나뉜다. 비율은 5:3 정도로 메모리를 차지하고 있으며 old sublist에 저장된 데이터는 이후에 eviction될 수 있다.
- dirty page
- 변경 사항이 아직 flush되지 않은 메모리에서 업데이트된 버퍼 풀의 데이터(참고로 페이지는 flush할 때 전송되는 데이터의 양을 나타내는 단위임)
- 디스크에의 I/O를 최소화하기 위해 커밋이 될 때마다 저장하는게 아니라 모아났다가 한번에 처리한다.
2.3.2 Undo Log
- 트랜잭션의 롤백 대비 및 트랜잭션의 격리 수준을 유지하면서 높은 동시성을 제공하는데 사용된다.
- Update나 Delete로 데이터를 변경할 때 변경 되기 전의 데이터를 보관하는 부분이다.
- 트랜잭션의 격리 수준에 따라서 커밋 이전 다른 트랜잭션이 조회할 때 Buffer Pool의 정보를 조회하거나(dirty read) Undo Log의 정보를 조회한다(consitent read).
- Read uncommited의 경우 Buffer Pool을 조회
- 나머지 Read Commited, Repeatable read, serialazable의 경우 undo log를 조회
아래의 사진 두 개는 개인적으로 트랜잭션의 격리 수준이 어떤건지 확실하게 보기 위해서 해본 실험이다. MySQL 워크벤치에서 하는 작업을 1번 트랜잭션, MySQL CLI에서 하는 작업을 2번 트랜잭션이라고 가정하고 진행한다.
우선 1번 트랜잭션에서 user 필드 하나를 테이블에 저장한 후 커밋한다. 그럼 이 데이터 블록은 버퍼 풀에 담겨있을 것이다.
그리고 1번 트랜잭션에서 다시 이 필드의 이름을 'asd'로 수정하고자 한다. 수정 쿼리문을 처리하고 1번 트랜잭션에서 이 필드를 조회했을 때 수정된 값으로 조회할 수 있다.
하지만 2번 트랜잭션에서는 이 필드를 조회했을 때 마지막 커밋 직전의 값을 보게 된다. 이게 바로 트랜잭션 격리 수준 때문이다. 1번 트랜잭션이 커밋을 하지 않는 이상 다른 트랜잭션에서는 저 변경된 값을 Read uncommited를 제외한 다른 옵션에서는 절대 확인할 수 없다.
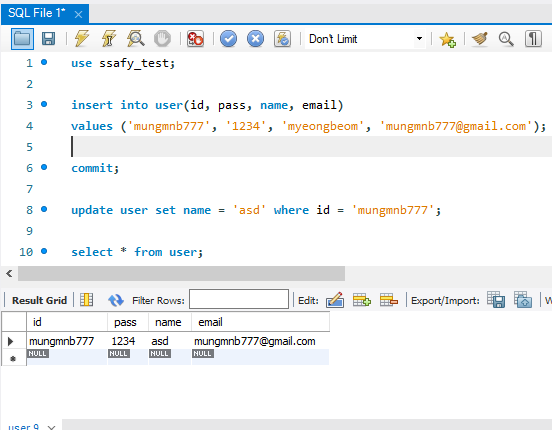
위 사진은 1번 트랜잭션으로 본인의 트랜잭션이 변경한 내용은 커밋되지 않아도 확인할 수 있다.(name = asd)
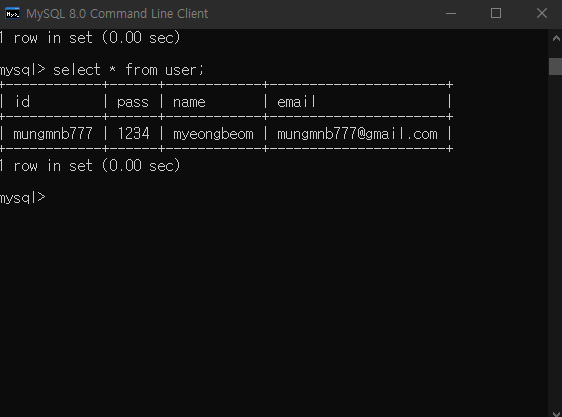
위 사진은 2번 트랜잭션으로 다른 트랜잭션의 조작 결과를 커밋 이전에는 확인할 수 없다. 이러한 결과가 나오는 이유는 트랜잭션이 커밋이 되기 이전에는 undo log에서 테이블의 정보를 조회하기 때문이다.
2.3.3 테이블 스페이스
- 하나 이상의 테이블 및 관련 인덱스에 대한 데이터를 보유할 수 있는 데이터 파일
- 시스템 테이블 스페이스는 모든 데이터 테이블을 보유하고 있으며 MySQL 5.6 이전까지는 기본 설정이었음
- MySQL 5.6 이상부터 테이블 당 하나의 파일을 가지는 테이블 스페이스가 기본 옵션이 되었다. file_per_table의 특징으로는 off-page column(엄청~~ 긴 가변 길이 데이터가 포함된 열)의 효율적인 저장, 테이블 압축 등이 있음.
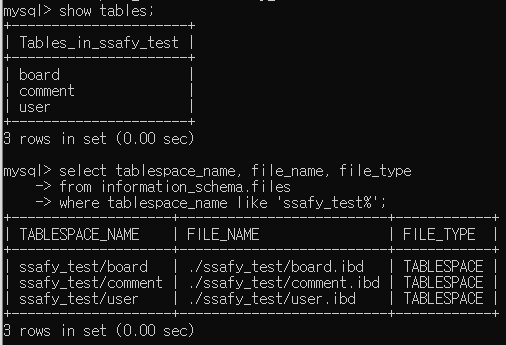
위 사진의 쿼리문 결과를 보면 확인할 수 있듯이, 테이블 당 테이블스페이스 파일이 ibd파일로써 각각 관리되고 있음을 확인할 수 있다.
3. 고찰
MySQL은 빠른 성능과 영속성 유지를 위해서 DBMS의 아키텍처를 정밀하고 효율적으로 개발했다는 것이 느껴졌다. 아키텍처 내부에서 열심히 알아보았는데도 이해 못한 부분들이 많았다. 특히 doublewrite buffer와 redo log에서 구분되는 부분이 무엇인지와, 더티 페이지가 flush가 될 때 doublewrite buffer와 테이블 스페이스에 총 두 번 쓰여지는데 두 배의 오버헤드나 I/O 작업은 필요하지 않다는 점도 구글링을 해보아도 도저히 이해가 되지 않았다.
그래도 이번 포스팅을 통해 우리가 쿼리문을 보낼 때 그 쿼리문들이 어떠한 방식으로 컴퓨터가 이해가능한 코드로 바뀌고 어떤 흐름을 통해서 디스크에 저장이 되는지 알 수 있었다. 조금 더 백엔드 개발자에 가까워진 기분이다!!!!!
참고자료
