
☀️종결 처리

- 종결 처리를 통해 최종 결과물을 도출
- 종결 처리의 실행이 필요할 때 중간 처리들도 비로소 실행
(Lazy Evaluation)
1. Max / Min / Count
Optional<T> max(Comparator<? super T> comparator);
Optional<T> min(Comparator<? super T> comparator);
long count();// 가장 큰 숫자 추출
Optional<Integer> max = Stream.of(5, 3, 6, 2, 1)
.max(Integer::compareTo);
// 가장 빠른 순서인 이름
User firstUser = users.stream()
.min((u1, u2) -> u1.getName().compareTo(u2.getName()))
.get();
// 0 이상인 숫자 개수
long positiveIntegerCount = Stream.of(1, -4, 5, -3, 6)
.filter(x -> x > 0)
.count();
// 24시간 내에 생긴 user 중 유요하지 않은 user
long unverfiedUsersIn24Hrs = users.stream()
.filter(user -> user.getCreatedAt().isAfter(now.minusDays(1)))
.filter(user -> !user.isVerified())
.count();
// error인 order 중에서 가장 높은 amount 가진 order 추출
Order ex = orders.stream()
.filter(x->x.getStatus()==OrderStatus.ERROR)
.max((o1, o2) -> o1.getAmount().compareTo(o2.getAmount()))
.get();
// error 중 가장 큰 amount 값 추출
BigDecimal ex2 = orders.stream()
.filter(order -> order.getStatus() == OrderStatus.ERROR)
.map(Order::getAmount)
.max(BigDecimal::compareTo)
.orElse(BigDecimal.ZERO);- max – Stream 안의 데이터 중 최대값을 반환. Stream이 비어있다면 빈 Optional을 반환
- min – Stream 안의 데이터 중 최소값을 반환. Stream이 비어있다면 빈 Optional을 반환
- count – Stream 안의 데이터의 개수를 반환
2. All Match / Any Match
boolean allMatch(Predicate<? super T> predicate);
boolean anyMatch(Predicate<? super T> predicate);// 양수인지 음수인지 체크
List<Integer> numbers = Arrays.asList(3, -4, 2, 7, 9);
boolean allPostive = numbers.stream()
.allMatch(number -> number > 0);
System.out.println("Are all numbers positive: " + allPostive);
boolean anyNegative = numbers.stream()
.anyMatch(number -> number < 0);
System.out.println("Is any number negative: " + anyNegative);
// 유저가 모두 유효한지 체크
boolean areAllUserVerified = users.stream()
.allMatch(User::isVerified);- allMatch – Stream 안의 모든 데이터가 predicate을 만족하면 true
- anyMatch – Stream 안의 데이터 중 하나라도 predicate을 만족하면 true
3. Find First / Find Any
Optional<T> findFirst();
Optional<T> findAny();// 음수 중에서 아무거나
Optional<Integer> anyNegativeInteger = Stream.of(3, 2, -5, 6)
.filter(x -> x < 0)
.findAny();
System.out.println(anyNegativeInteger.get());
// 양수중에서 첫번째
Optional<Integer> firstPositiveInteger = Stream.of(-3, -2, -5, 6)
.filter(x -> x > 0)
.findFirst();
System.out.println(firstPositiveInteger.get());- findFirst – Stream 안의 첫번째 데이터를 반환. Stream이 비어있다면 비어있는 Optional을 반환.
- findAny – Stream 안의 아무 데이터나 리턴. 순서가 중요하지 않고 Parallel Stream을 사용할 때 최적화를 할 수 있다. 마찬가지로 Stream이 비어있다면 빈 Optional을 반환.
4. Reduce
Optional<T> reduce(BinaryOperator<T> accumulator);
T reduce(T identity, BinaryOperator<T> accumulator);
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);// 비교식 1개
List<Integer> numbers = Arrays.asList(1, 4, -2, -5, 3);
int sum = numbers.stream()
.reduce((x, y) -> x + y)
.get();
System.out.println(sum);
// 초기값 , 연산식
List<String> numberStrList = Arrays.asList("3", "2", "5", "-4");
int sumOfNumberStrList = numberStrList.stream()
.map(Integer::parseInt)
.reduce(0, (x, y) -> x + y);
// 초기값 하나, 타입 변환식, 연산식
int sumOfNumberStrList2 = numberStrList.stream()
.reduce(0, (number, str) -> number + Integer.parseInt(str), (num1, num2) -> num1 + num2);
// user들의 친구 수 출력
int sumOfNumberOfFriends = users.stream()
.map(User::getFriendUserIds)
.map(List::size)
.reduce(0, (x, y) -> x + y);
// amount 총 합 (flatmap 중요)
BigDecimal ex = orders.stream()
.map(Order::getOrderLines)
.flatMap(List::stream)
.map(OrderLine::getAmount)
.reduce(BigDecimal.ZERO, BigDecimal::add);- 주어진 함수를 반복 적용해 Stream 안의 데이터를 하나의 값으로 합치는 작업
- Max / Min / Count도 사실 reduce의 일종
- reduce 1 – 주어진 accumulator를 이용해 데이터를 합침. Stream이 비어있을 경우 빈 Optional을 반환
- reduce 2 – 주어진 초기값과 accumulator를 이용. 초기값이 있기 때문에 항상 반환값이 존재
- reduce 3 – 합치는 과정에서 타입이 바뀔 경우 사용. Map + reduce로 대체 가능
📒Collectors
<R, A> R collect(Collector<? super T, A, R> collector);
java.util.stream.Collectors
Collector<T, ?, List<T>> toList();
Collector<T, ?, Set<T>> toSet();List<Integer> numberList = Stream.of(3, 5, -3, 3, 4, 5)
.collect(Collectors.toList());
System.out.println(numberList);
Set<Integer> numberSet = Stream.of(3, 5, -3, 3, 4, 5)
.collect(Collectors.toSet());
System.out.println(numberSet);
// 이 아래는 map과 reduce로 변환 가능
List<Integer> numberList2 = Stream.of(3, 5, -3, 3, 4, 5)
.collect(Collectors.mapping(x -> Math.abs(x), Collectors.toList()));
System.out.println(numberList2);
Set<Integer> numberSet2 = Stream.of(3, 5, -3, 3, 4, 5)
.collect(Collectors.mapping(x -> Math.abs(x), Collectors.toSet()));
System.out.println(numberSet2);
int sum1 = Stream.of(3, 5, -3, 3, 4, 5)
.collect(Collectors.reducing(0, (x, y) -> x + y));
System.out.println(sum);- collect – 주어진 collector를 이용해 Stream안의 데이터를 합침. 일반적으로 특정 data structure로 데이터를 모을 때 사용
- Collectors – 자주 쓰일법한 유용한 collector들을 모아놓은 util class. java.util.stream 패키지에서 제공
- toList – Stream 안의 데이터를 List 형태로 반환해주는 collector
- toSet – Stream 안의 데이터를 Set 형태로 반환해주는 collector. Set이기 때문에 중복값은 사라지고 순서가 무의미해짐에 유의
- mapping – Map과 collect를 합쳐놓은 역할을 해주는 collector. 일반적으로는 map을 한 후 collect를 해도 되지만 groupingBy 등 필요할 때가 있다
- reducing – reduce를 해주는collector
- 이외에도 filtering, flatMapping, counting, minBy, maxBy 등도 있다
⭐1. toMap
public static <T, K, U> Collector<T, ?, Map<K,U>> toMap(
Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper)// x -> x 는 Function.identity()로 대신 사용 가능
// key를 만드는 식, value를 만드는 식 2개
Map<Integer, String> numberMap = Stream.of(3, 5, -4, 2, 6)
.collect(Collectors.toMap(Function.identity(), x -> "Number is " + x));
System.out.println(numberMap.get(3));
// userid와 user 객체를 각각 key, value
List<User> users = Arrays.asList(user1, user2, user3);
Map<Integer, User> userIdToUserMap = users.stream()
.collect(Collectors.toMap(User::getId, Function.identity()));
System.out.println(userIdToUserMap);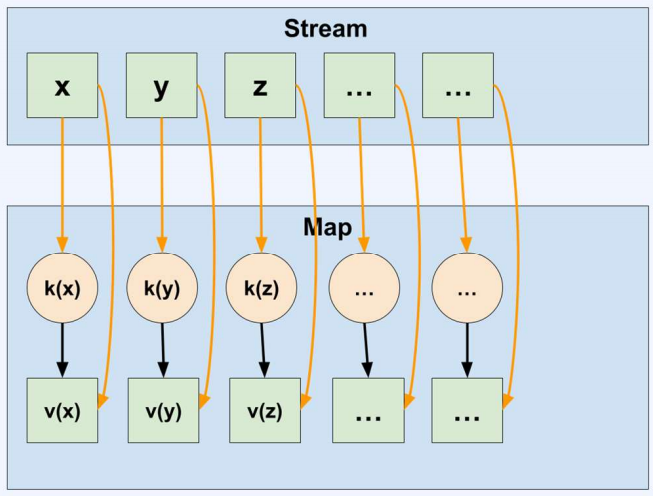
- x -> x 는 Function.identity()로 대신 사용 가능
- Stream 안의 데이터를 map의 형태로 반환해주는 collector
- keyMapper – 데이터를 map의 key로 변환하는 Function
- valueMapper – 데이터를 map의 value로 변환하는 Function
2. Grouping By
public static <T, K> Collector<T, ?, Map<K, List<T>>>
groupingBy(Function<? super T, ? extends K> classifier)
public static <T, K, A, D> Collector<T, ?, Map<K, D>> groupingBy(
Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream)List<Integer> numbers = Arrays.asList(13, 2, 101, 203, 304, 402, 305, 349, 2312, 203);
Map<Integer, List<Integer>> unitDigitMap = numbers.stream()
.collect(Collectors.groupingBy(number -> number % 10));
// set으로 추가 변환
Map<Integer, Set<Integer>> unitDigitSet = numbers.stream()
.collect(Collectors.groupingBy(number -> number % 10, Collectors.toSet()));
// key 함수, value 함수, 형태
Map<Integer, List<String>> unitDigitStrMap = numbers.stream()
.collect(Collectors.groupingBy(number -> number % 10,
Collectors.mapping(number -> "unit digit is " + number, Collectors.toList())));
// key : status, value : order amount 추출 후 총합
Map<OrderStatus, BigDecimal> orderStatusToSumOfAmountMap = orders.stream()
.collect(Collectors.groupingBy(Order::getStatus,
Collectors.mapping(Order::getAmount,
Collectors.reducing(BigDecimal.ZERO, BigDecimal::add))));- Stream 안의 데이터에 classifier를 적용했을 때 결과값이 같은 값끼리List로 모아서 Map의 형태로 반환해주는 collector. 이 때 key는 classifier의 결과값, value는 그 결과값을 갖는 데이터들.
- 예를 들어 stream에 {1, 2, 5, 7, 9, 12, 13}이 있을 때 classifier가 x -> x % 3이라면 반환되는 map은 {0 = [9, 12], 1 = [1, 7, 13], 2 = [2, 5]}.
- 두 번째 매개변수로 downstream collector를 넘기는 것도 가능
- 그 경우 List 대신 collector를 적용시킨 값으로 map의 value가 만들어짐
- 이 때 자주 쓰이는 것이 mapping / reducing 등의 collector
3. Partitioning By
public static <T>
Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(
Predicate<? super T> predicate)
public static <T, D, A>
Collector<T, ?, Map<Boolean, D>> partitioningBy(
Predicate<? super T> predicate,
Collector<? super T, A, D> downstream)List<User> users = Arrays.asList(user1, user2, user3);
// 친구 수가 5명 이상인지 미만인지 두 그룹으로 나눔
Map<Boolean, List<User>> userPartitions = users.stream()
.collect(Collectors.partitioningBy(user -> user.getFriendUserIds().size() > 5));
// 친구 수에 따라 다른 이메일 전송
EmailService emailService = new EmailService();
for (User user: userPartitions.get(true)) {
emailService.sendPlayWithFriendsEmail(user);
}
for (User user: userPartitions.get(false)) {
emailService.sendMakeMoreFriendsEmail(user);
}- GroupingBy와 유사하지만 Function 대신 Predicate을 받아 true와 false 두 key가 존재하는 map을 반환하는 collector
- 마찬가지로 downstream collector를 넘겨 List 이외의 형태로 map의 value를 만드는 것 역시 가능
📕For Each
void forEach(Consumer<? super T> action);// stream 중간처리를 하지 않는다면 stream은 빼도 된다
List<Integer> numbers = Arrays.asList(3, 5, 2, 1);
numbers.stream().forEach(number -> System.out.println("The number is " + number));
numbers.forEach(number -> System.out.println("The number is " + number));
List<User> users = Arrays.asList(user1, user2, user3);
// 필터링 한 user에게 각각 email 전송
EmailService emailService = new EmailService();
users.stream()
.filter(user -> !user.isVerified())
.forEach(emailService::sendVerifyYourEmailEmail);
// 기존의 for문의 아래처럼 변환 가능
for (int i = 0; i < users.size(); i++) {
User user = users.get(i);
System.out.println("Do an operation on user " + user.getName() + " at index " + i);
}
IntStream.range(0, users.size()).forEach(i -> {
User user = users.get(i);
System.out.println("Do an operation on user " + user.getName() + " at index " + i);
});- 제공된 action을 Stream의 각 데이터에 적용해주는 종결 처리 메서드
- Java의 iterable 인터페이스에도 forEach가 있기 때문에 Stream의 중간 처리가 필요없다면 iterable collection(Set, List 등)에서 바로 쓰는 것도 가능
📓Parallel Stream
List<Integer> numbers = Arrays.asList(1, 2, 3);
Stream<Integer> parallelStream = numbers.parallelStream();
Stream<Integer> parallelStream2 = numbers.stream().parallel();// 이메일 보내기와 같이 순서에 종속되지 않는 처리는 parallel 사용하자(속도 비약적 상승)
users.stream().parallel()
.filter(user -> !user.isVerified())
.forEach(emailService::sendVerifyYourEmailEmail);
// 이 예제를 실행시키면 순서 상관없이 무작위로 실행
// 따라서 순서가 중요한 작업의 경우 parallel 사용하지 말자
List<User> processedUsers = users.parallelStream()
.map(user -> {
System.out.println("Capitalize user name for user " + user.getId());
user.setName(user.getName().toUpperCase());
return user;
})
.map(user -> {
System.out.println("Set 'isVerified' to true for user " + user.getId());
user.setVerified(true);
return user;
})
.collect(Collectors.toList());
System.out.println(processedUsers);- Sequential vs. Parallel
- 여러개의 스레드를 이용하여 stream의 처리 과정을 병렬화 (parallelize)
- 중간 과정은 병렬 처리 되지만 순서가 있는 Stream의 경우 종결 처리 했을 때의 결과물이 기존의 순차적 처리와 일치하도록 종결 처리과정에서 조정된다. 즉 List로 collect한다면 순서가 항상 올바르게 나온다는 것.
장점
- 굉장히 간단하게 병렬 처리를 사용할 수 있게 해준다
- 속도가 비약적으로 빨라질 수 있다
단점
- 항상 속도가 빨라지는 것은 아니다
- 공통으로 사용하는 리소스가 있을 경우 잘못된 결과가 나오거나 아예 오류가 날 수도 있다 (deadlock)
- 이를 막기 위해 mutex, semaphore등 병렬 처리 기술을 이용하면 순차 처리보다 느려질 수도 있다

꾸준히 빠르게