1. 요구사항 분석
- 각 사용자는 채팅방에 입장 시 이전 채팅 로그를 읽을 수있다.
- 이전에 전송된 채팅 로그를 다시 읽을 수있다는 요구사항을 구현해내기 위해 사용자가 언제 채팅방에 입장했던지 상관없이 이전에 전송된 모든 채팅 로그를 서버에 요청하고 읽을 수있도록 만들기로 결정되었다.
- version 0.1 에서는 RDBMS를 사용했지만 모든 채팅 로그를 다 확인해야 하는 경우가 생길 수있고, 최악의 경우 O(N)의 복잡도가 소요된다는 것을 알 수있다. → 모든 채팅 로그가 하나의 테이블에 저장되기 때문에 매우 비효율적이다.
1.1 RDBMS의 한계
많은 데이터량과 데이터 처리량이 계속적으로 증가한다면
- 스키마 문제 : 빅데이터를 RDB의 스키마에 맞춰 변경해서 넣으려면 매우 긴 시간의 down time이 발생한다.
- Scale up(서버 자체의 성능을 증가)의 한계 : RDBMS는 애초에 스케일 아웃을 염두에 두고 설계하지 않았다. 관계형 모델과 트랜잭션의 연산, 일관성, 속성을 유지하면서 분산환경(Scale Out)에서 RDBMS를 조작하는것은 어렵다.
- RDBMS에 채팅 내용을 담기에 I/O 비용이 크다. ( I/O : 데이터를 넣고 빼는 리소스(cpu, disk, memory) 사용량이 크다
| SQL | NoSQL |
|---|---|
| 규격이 정해져 있다. | 정해진 규격이 없다. |
| Join이 가능하다. | Join이라는 개념 자체가 없다. |
| 트랜잭션을 사용한다. | 트랜잭션이 없다. → MongoDB 어느정도 가능 |
| 분산처리가 어렵다. | 분산처리가 쉽다. |
| ACID를 구현한다. | ACID를 완벽히 구현하지 않고 "Eventual consistency" 개념이 도입되었다. |
1.2 결론
- 테이블 형식의 데이터 저장이 필요 없다.
- Join, where 과 같은 sql 연산이 필요 없다.
- 빠른 읽기/쓰기 지연, 데이터를 자주 변경하지 않는다.
- 캐시 데이터 저장 가능
- 수직, 수평적 확장 가능 → 분산처리 용이
2. NoSQL이란?
💡 Not Only SQL의 약자로 기존 RDBM 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미한다.
- 기존의 정형화된 데이터뿐만 아니라 메신저 텍스트, 음성 등 반정형화, 비정형화된 데이터도 저장하고 다뤄야 하는 수요가 생겼다.
- 빅데이터를 다룰 때, RDBMS로만 트래픽을 감당하기 어려워졌고, 이를 해결하기위해 NoSQL이 등장했다. NoSQL은 분산 환경을 빠르게 처리하기 위해서 개발되었다.
- NoSQL의 핵심은 Horizontal Scalability(수평확장)과 High Availability(고가용성)이다.
- RDBMS 가 클라이언트/서버 환경에 맞는 데이터 저장기술이라면, NoSQL은 클라우드 환경에 맞는 저장 기술이다.
3. CAP
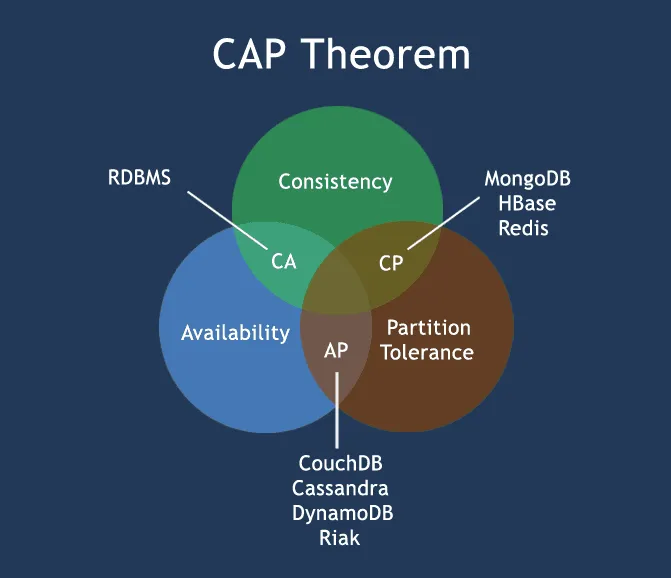
분산 데이터베이스는 방대한 데이터를 다루기에 유용한 시스템이다. 분산 데이터베이스는 수평 확장할 수 있기 때문에 트래픽이 증가하더라도 낮은 지연 시간을 유지할 수 있고, 일부 노드 장애에 적절히 대응할 수 있다. NoSQL 데이터베이스는 대표적인 분산 데이터베이스이며, 유연하게 데이터를 다룰 수 있다는 장점이 있다.
분산형 구조는 일관성(Consistency), 가용성(Availability), 분산 허용(Partitioning Tolerance)의 3가지 특징을 가지고 있다. CAP이론은 이 중 2가지만 만족할 수 있다는 이론인데, NoSQL은 대부분 이 CAP이론을 따른다.
3.1 일관성(Consistency)
- 데이터는 항상 일관성 있는 상태를 유지해야 하고 데이터의 조작 후에도 무결성을 해치지 말아야 한다는 속성이다.
- 쓰기 동작이 완료된 후 발생하는 읽기 동작은 마지막으로 쓰여진 데이터를 리턴해야 한다
- 일관성은 동시성 또는 동일성이라고도 하며 다중 클라이언트에서 같은 시간에 조회하는 데이터는 항상 동일한 데이터임을 보증하는 것을 의미한다.
- 이것은 관계형 데이터베이스가 지원하는 가장 기본적인 기능이지만 일관성을 지원하지 않는 NoSQL을 사용한다면 데이터의 일관성이 느슨하게 처리되어 동일한 데이터가 나타나지 않을 수 있다.
- 느슨하게 처리된다는 것은 데이터의 변경을 시간의 흐름에 따라 여러 노드에 전파하는 것을 말한다.
- 이러한 방법을 최종적으로 일관성이 유지된다고 하여 최종 일관성 또는 궁극적 일관성을 지원한다고 한다.
- 각 NoSQL들은 분산 노드 간의 데이터 동기화를 위해서 두 가지 방법을 사용한다.
- 첫번째로 데이터의 저장 결과를 클라이언트로 응답하기 전에 모든 노드에 데이터를 저장하는 동기식 방법이 있다. 그만큼 느린 응답시간을 보이지만 데이터의 정합성을 보장한다.
- 두번째로 메모리나 임시 파일에 기록하고 클라이언트에 먼저 응답한 다음 특정 이벤트 또는 프로세스를 사용하여 노드로 데이터를 동기화하는 비동기식 방법이 있다. 빠른 응답시간을 보인다는 장점이 있지만, 쓰기 노드에 장애가 발생하였을 경우 데이터가 손실될 수 있다.
- 분산 시스템에서 일관성을 유지하기 위해서는 희생이 따른다.
- 가용성과 분할 허용성을 지원하는 카산드라(Cassandra DB)는 최종 일관성을 지원한다.
- 또한 설정값을 조절하여 강한 일관성을 지원할 수 있다.
- 많은 NoSQL 솔루션은 읽기와 쓰기의 성능 향상을 위해 데이터를 메모리에 임시로 기록한 다음 클라이언트에 응답하고 백그라운드 쓰레드(혹은 프로세스)로 해당 데이터를 디스크에 기록한다.
- 방금 전에 언급했듯이 이 경우에는 데이터 손실의 위험이 존재하게 되는데 카산드라와 HBase에서는 이러한 손실을 방지하기 위해 메모리에 저장하기 전에 커밋로그 및 WAL파일에 먼저 정보를 기록하는 방법을 사용하고 있다. Redis에도 AOF(Append Only File)라는 기능이 존재한다.
3.2 가용성(Availability)
- 특정 노드가 장애가 나도 서비스가 가능해야 한다라는 의미를 가진다.
- 데이터 저장소에 대한 모든 동작(read, write 등)은 항상 성공적으로 리턴되어야 한다.
- 명확해 보이는 단어이기는 하지만 분산 시스템에서의 특징을 말하는 것이기 때문에 서비스가 가능하다와 성공적으로 리턴이라는 표현이 애매하다.
- 얼마동안 기다리는 것 까지를 성공적이라고 할 수 있느냐에 대한 문제가 남아있다.
- 20시간정도 기다렸더니 리턴이 왔어! Availability가 있는 시스템이야! 라고 할 수 없기 때문이다.
- 다시한번 성공적으로 리턴 에 대해서 보면 모든 동작에 대해서 시스템이 Fail 이라는 리턴을 성공적으로 보내준다면 그것을 Availability가 있다고 해야 하느냐에 대해서도 애매하다.
- CAP를 설명하는 문서들 중 Fail 이라고 리턴을 하는 경우도 성공적인 리턴 이라고 설명하는 것을 보았다.
- NoSQL은 클러스터 내에서 몇 개의 노드가 망가지더라도 정상적인 서비스가 가능하다.
- 몇몇 NoSQL은 가용성을 보장하기 위해 데이터 복제(Replication)을 사용한다.
- 동일한 데이터를 다중 노드에 중복 저장하여 그 중 몇 대의 노드가 고장나도 데이터가 유실되지 않도록 하는 방법이다.
- 데이터 중복 저장 방법에는 동일한 데이터를 가진 저장소를 하나 더 생성하는 Master-Slave 복제 방법과 데이터 단위로 중복 저장하는 Peer-to-Peer 복제 방법이 있다.
3.3 분산 허용(Partitioning Tolerance)
- 분할 허용성이란 지역적으로 분할된 네트워크 환경에서 동작하는 시스템에서 두 지역 간의 네트워크가 단절되거나 네트워크 데이터의 유실이 일어나더라도 각 지역 내의 시스템은 정상적으로 동작해야 함을 의미한다.
- Availablity와의 차이점은 Availability는 특정 노드가 장애가 발생한 상황에 대한 것이고
- Tolerance to network Partitions는 노드의 상태는 정상이지만 네트워크 등의 문제로 서로 간의 연결이 끊어진 상황에 대한 것이다.
4. PACELC 이론
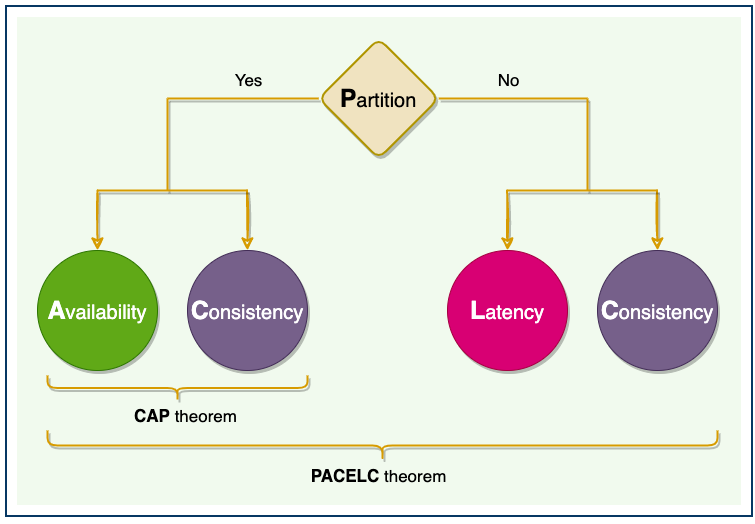
- PACELC 이론은 CAP 이론으로 부족한 부분을 보완하기위해 네트워크 장애 상황과 정상 상황으로 나누어서 설명하는 이론이다.
- P(네트워크 파티션)상황에서 A(가용성)과 C(일관성)의 상충 관계와 E(else, 정상)상황에서 L(지연 시간)과 C(일관성)의 상충 관계를 설명한다.
- PACELC 이론에서는 장애 상황, 정상 상황에서 어떻게 동작하는지에 따라 시스템을 PC/EC, PC/EL, PA/EC, PA/EL로 나눌 수 있다.
| 장애상황 | 정상상황 | 유형 특성 | 구현 시스템 |
|---|---|---|---|
| P+A | E+L | • 장애 상황 시 가용 노드만 반영, 복구 시 전체 반영 • 정상 상황 시 Latency 우선 고려 • PA 가능한 노드에만 데이터 반영, 복구 시 Eventual Consistency 적용 • EL Latency 위해 모든 노드에 데이터를 반영 안함 | Cassndra, DynamoDB |
| P+A | E+C | • 장애 상황 시 가용 노드만 반영, 복구 시 전체 반영 • 정상 상황 시 모든 노드 동일 메시지 보장 • PA 장애 상황일때 C를 포기 가능한 노드에만 데이터 반영 • EC 모든 노드에서 같은 메시지를 볼 수 있도록 쓰기연산 수행 | MongoDB, Hazelcast IMDG |
| P+C | E+L | • 장애 상황 시 Timeline Consistency 수준 보장 • 정상 상황 시 Latency 우선 고려 • PC 평소만큼의 C를 보장하기 위해 A를 희생 • EL 평소에도 L을 위해 C를 희생(Timeline Consistency) | PNUTS |
| P+C | E+C | • 장애 상황 시 일관성 우선 보장 • 정상 상황 시 모든 노드 동일 메시지 보장 • PC 장애 상황일 때 C를 위해 A를 희생 • EC 그렇지 않은 경우에도 C를 위해 L을 희생 | VoltDB, HBase |
5. NoSQL 종류와 특징
5.1 Key-Value
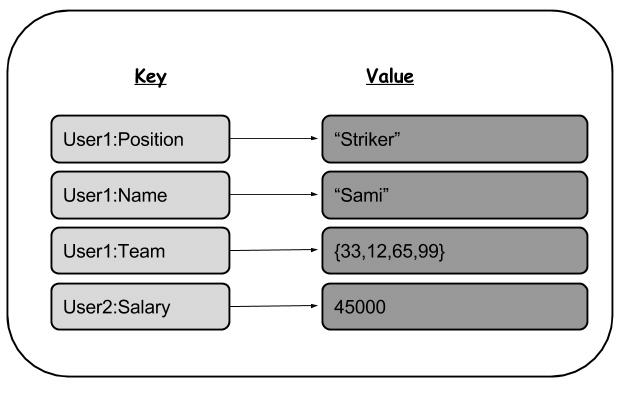
- Key-Value의 쌍으로 데이터가 저장되는 유형이다.
- 키는 값에 접근하기 위한 용도로 사용되며, 값은 어떠한 형태의 데이터라도 담을 수 있다.
- 이미지나 비디오도 가능하다.
- 또한 간단한 API를 제공하는 만큼 질의의 속도가 굉장히 빠른 편이다.
- 단순한 저장구조로 인하여 복잡한 조회 연산을 지원하지 않는다.
- 고속 읽기와 쓰기에 최적화된 경우가 많다.
- 하나의 서비스 요청에 다수의 데이터 조회 및 수정 연산이 발생하면 트랜잭션 처리가 불가능하여 데이터 정합성을 보장할 수 없다.
- Dynamo DB, Redis, Riak, Memcache … 등이 있다.
5.2 Column-Based
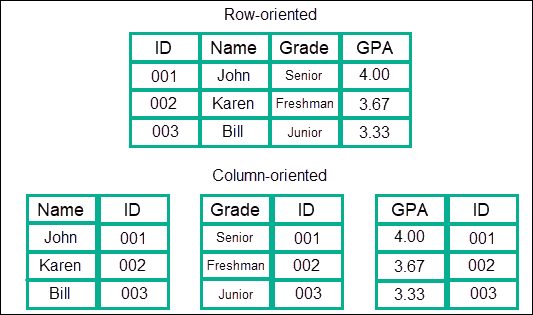
- Column 별로 연속적으로 저장하는 유형이다.
- 하나의 키에 여러 개의 컬럼 이름과 컬럼 값의 쌍으로 이루어진 데이터를 저장하고 조회한다.
- 모든 컬럼은 항상 타임 스탬프 값과 함께 저장된다.
- 저장의 기본 단위는 컬럼으로 컬럼은 컬럼 이름과 컬럼 값, 타임스탬프로 구성된다.
- 컬럼형 NoSQL은 구글의 Big Table 영향을 받았다. → Big Table DB라고도 함
- 이러한 컬럼들의 집합이 Row(Row)이며, Row키(Row key)는 각 Row를 유일하게 식별하는 값이다.
- 대부분의 컬럼 모델 NoSQL은 쓰기와 읽기 중에 쓰기에 더 특화되어 있다.
- 그렇기 때문에 읽기 연산 대비 쓰기 연산이 많은 서비스나 빠른 시간 안에 대량의 데이터를 입력하고 조회하는 서비스를 구현할 때 가장 좋은 성능을 보인다.
- 채팅 내용 저장, 실시간 분석을 위한 데이터 저장소 등의 서비스 구현에 적합하다.
- 또한 값들은 일련의 바이너리 데이터로 존재하기 때문에 어떤 형태의 데이터라도 저장될 수 있다.
- 다만 위의 두 모델들과는 다르게 Blob 단위의 쿼리가 불가능하며 로우와 컬럼의 초기 디자인이 중요하다.
- Schema Less이긴 하지만 새로운 필드를 만드는 데 드는 비용이 크기 때문에 사실상 결정된 스키마를 변경하는 것이 어렵다.
- Cassandra DB, HBase, ScyllaDB 등이 있다.
5.3 Document-Oriented
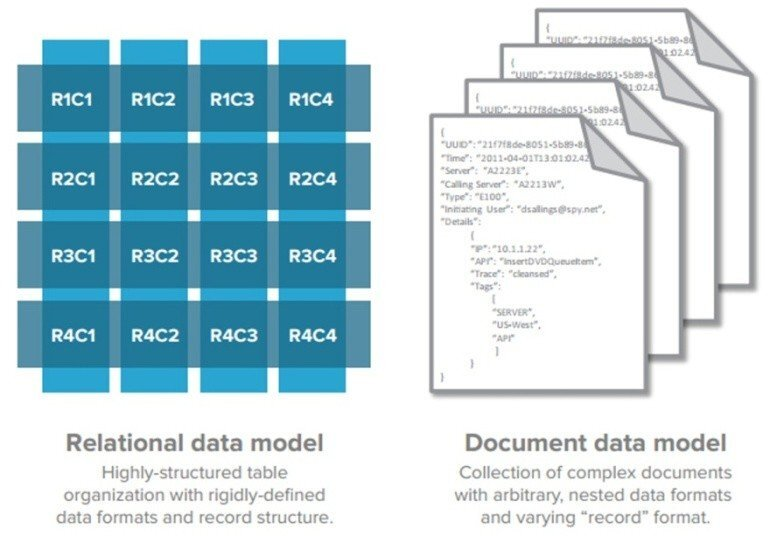
- JSON, XML과 같은 Collection 데이터 모델 구조이다.
- 데이터가 key와 document 형태로 저장되는 데이터베이스이다.
- key는 문서에 대한 ID 로 표현된다.
- key-value 모델과 달리 value는 계층적인 형태의 document로 저장된다. 이를 통해 하나의 객체를 여러 개의 테이블에 나눠 저장할 필요가 없어지게 된다.
- 객체를 document의 형태로 바로 저장할 수 있기 때문에 객체-관계 매핑을 할 필요가 없다.
- key-value 모델과 동일하게 검색에 최적화되어 있다.
- 문서 ID 에 대한 인덱스를 사용하여 O(1) 시간 안에 문서를 조회할 수 있다.
- 대부분의 문서 모델 NoSQL 은 B 트리 인덱스를 사용하여 2 차 인덱스를 생성한다.
- B 트리는 크기가 커지면 커질수록 새로운 데이터를 입력하거나 삭제할 때 성능이 떨어지게 된다.
- 읽기와 쓰기의 비율이 7:3 정도일 때 가장 좋은 성능을 보인다
- 중앙 집중식 로그 저장, 타임라인 저장, 통계 정보 저장 등에 사용된다.
- Document 데이터베이스의 질의 결과가 JSON, xml 형태로 출력된다.
- Mongo DB, Cough DB 등이 있다.
5.4 Graph

- Nodes, Relationship, Key-Value 데이터 모델을 채용하고 있다.
- 데이터 간의 관계를 그래프로 형성하고 통합 검색을 빠르게 할 수있다.
- 개체와 관계를 그래프 형태로 표현한 것이므로 관계형 모델이라고 할 수 있다.
- 페이스북이나 트위터 같은 소셜 네트워크, 연관된 데이터를 추천해주는 추천 엔진이나 패턴 인식 등의 데이터베이스로 적합하다.
- Neo4J, OreientDB 등이 있다.
6. 우리 프로젝트에 맞는 DBMS 선택
6.1 가장 많이 사용되는 NoSQL은?
- NoSQL 종류
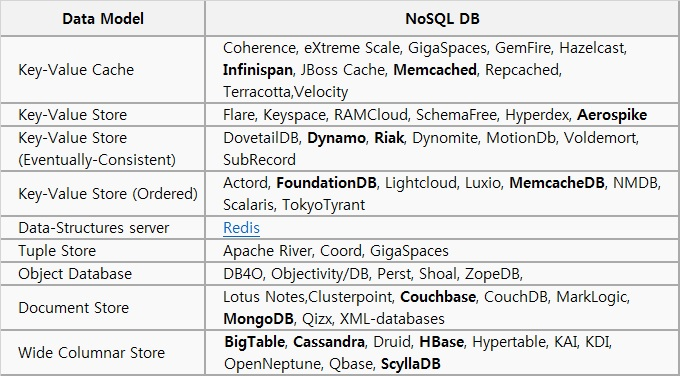
- DB별 특성
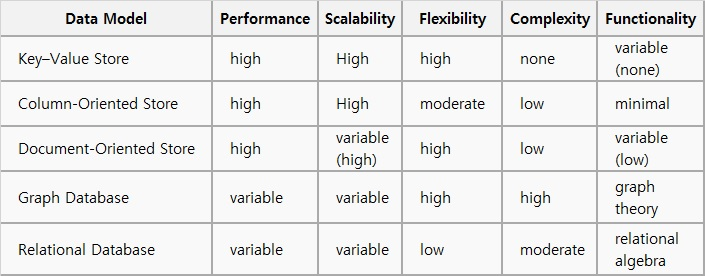
Key-Value 제품을 포함하여 전체 NoSQL제품들 중 현재 시장에서 가장 많이 인기가 있는 제품들은
- MongoDB(Document),
- HBase(Wide Columnar Store),
- Cassandra(Wide Columnar Store)
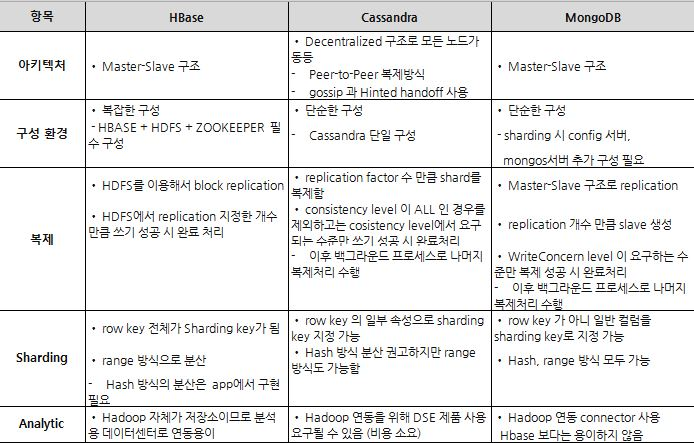
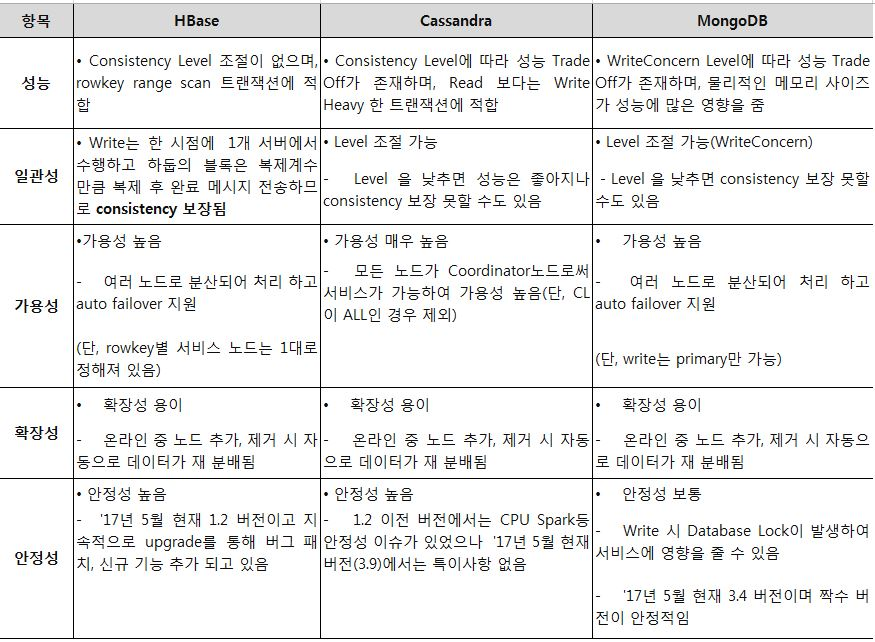
[ Cassandra & HBase ]
- 카산드라 클러스터 설정 및 구성이 HBase 클러스터 구성보다 훨씬 쉽다.
- 카산드라가 일반적으로 write시 5배 이상의 더 나은 성능, read시 4배 이상의 성능을 보인다.
[ Cassandra & MongoDB ]
- Cassandra 노드가 추가될수록 MonogoDB 보다 훨씬 나은 선형적인 성능 향상을 보인다.다중 Index가 필요한 구조라면 MongoDB를 선택하고, 데이터 항목 변경이 많고 unique access가 많은 경우라면 Cassandra가 적합
6.2 Discord의 DB
현 프로젝트는 Discord와 같은 채팅 서비스를 생각하고 진행 중이라서 가장 먼저 Discord의 데이터베이스 모델을 찾아봤다.
- 2017 Cassandra → 2023 ScyllaDB
- ScyllaDB이란?
- spring webflux + scylla + kafka
- ScyllaDB를 사용하면 좋겠지만 관련자료 찾기 힘듬
6.3 우리 프로젝트에 맞는 NoSQL은 ?
MongoDB vs Cassandra
- CP(MongoDB) or AP(Cassandra) → MongoDB > Cassandra
- MongoDB같은 경우 PA+EC
- Cassandra의 경우 PA+EL
- CAP 및 PACELC 이론을 근거로 MongoDB는 가용성보다는 일관성을 보장하는 분산 시스템이고 Cassandra는 가용성을 추구하는 시스템으로 분류된다. 하지만 이 분류는 단지 두 시스템 모두의 기본 동작만을 설명할 뿐이다. MongoDB는 primary 멤버에 읽기와 쓰기를 모두 할 때에만 강한 일관성을 제공한다. primary 멤버에만 읽기가 제한되더라도 read/write concern에 따라 일관성을 낮출 수 있다. Cassandra 역시 가용성과 지연 시간을 합리적으로 조절하여 강한 일관성을 만들 수 있다.
- 데이터 모델 → Cassandra > MongoDB
- MongoDB: MongoDB는 유연하고 JSON과 같은 문서에 데이터를 저장하는 문서 데이터베이스입니다. 복잡한 데이터 구조, 중첩 필드 및 유연한 스키마를 허용하므로 진화하는 데이터 요구 사항이나 풍부한 데이터 쿼리가 필요한 애플리케이션에 적합합니다.
- Cassandra: 카산드라는 컬럼 패밀리로 그룹화된 컬럼으로 데이터를 구성하는 컬럼 패밀리 데이터베이스입니다. 높은 쓰기 처리량을 위해 설계되었으며 많은 양의 데이터를 처리할 수 있습니다. Cassandra의 데이터 모델은 쓰기 작업이 많은 워크로드 및 시계열 데이터에 매우 적합합니다.
- 관련 자료를 쉽게 얻을 수 있는 것 → Cassandra < MongoDB
- 페이지네이션 → MongoDB > Cassandra
- 모니터링 & Cloud → MongoDB > Cassandra
7. 결론
Database의 특성을 고려했을 때 MongoDB, Cassandra로 좁혀졌다.
instagram과 같은 수천 수만명이 동시에 접속하는 시스템이라면 가용성이 높은 Cassandra를 선택했겠지만 현재 프로젝트 목표로 하나의 채팅방에 최대 100명의 접속자를 제한하기 때문에 일관성을 보장하는 MongoDB를 선택하게 되었다. 데이터 모델로 간단한 채팅 메세지만을 사용할 데이터 구조로 사용하기 때문에 Cassandra가 MongoDB보다 적합하다고 생각했지만 MongoDB관련된 자료나, 페이지네이션, 모니터링과 Cloud(Atlas)를 제공한다는 장점이 확실하기 때문에 최종 Nosql 데이터베이스로 MongoDB를 선택하게 되었다.
추후 검색기능을 추가한다면 ElasticSerach와 함께 사용해볼 수 있을 것 같다.
reference
How Discord Stores Billions of Messages
How Discord Stores Trillions of Messages
NoSQL에 대하여 (feat. 등장배경, CAP이론, 종류 등)
NoSQL 이란? - NoSQL 특징, NoSQL 데이터 모델, RDBM 비교
채팅을 위한 Message Queue 선택과 DB 선택
[Django] 카카오톡 같은 채팅 시스템 데이터베이스 설계, 구현, 테스트 코드 만들어보기 - 구영민의 개발 블로그
RDBMS의 한계와 NoSQL을 사용하는 이유 (2) RDBMS의 한계, 트랜잭션
The CAP Theorem With Apache Cassandra® and MongoDB
Apache Cassandra :Is a a key-value or a column-oriented (or tabular) database management system?
