
10/21 1, 2, 3, 4, 5세션
A. 비지도 학습이란
- 정답 (Label) 이 없는 데이터
- 스스로 비슷한 데이터끼리 묶음
- 학습 시 x만 사용. x의 패턴 인식 문제임
- 후속 작업이 필요함 (차원 축소, 클러스터링, 이상 탐지)
- 비지도 학습은 결과가 아니라 과정임.
B. 차원 축소 (PCA)
고차원 데이터를 축소하여 새로운 feature 생성, 시각화 및 지도 학습과 연계
B-1. 변수가 많을 수록 모델 성능이 향상되는가?
- 차원 : 차원의 수 == 변수의 수(칼럼의 수)
- 꼭 필요한 데이터가 아닌데 넣으면 불필요하게 복잡한 모델이 된다.
- 차원이 커지면 데이터가 희박해진다
차원의 저주
- 변수가 많아지면 데이터가 희박해져서 학습이 적절하게 되지 않을 가능성이 높다
차원의 저주 풀기
- 행 늘리기 (데이터 늘리기)
- 열 줄이기 (차원 축소)
B-2. 차원 축소
- 기존 특성을 최대한 유지하면서 고차원 feature를 저차원 feature 로 축소
- PCA (주성분 분석), T-SNE 로 차원을 줄인다.
- 차원축소를 하면 다중공선성 문제도 해결된다.
B-3. PCA (주성분 분석)
- 변수의 수보다 적은 저차원의 평면으로 투영 (정사영, Projection)
- 학습 데이터셋에서
분산이 최대인 첫번째 축을 찾음 - 첫번째 축과 직교하면서 분산이 최대인 두번째 축을 찾음
- 첫번째 축과 두번째 축에 직교하고, 분산이 최대인 세번째 축을 찾음
- 1~3 과 같은 방법으로 데이터셋의 차원만큼 축을 찾음
PCA 함수
- MinMax 스케일링 수행
- 차원 축소
- 넘파이인 결과를 데이터프레임으로 변환
B-4. 적정 주성분 개수 찾기
- 주성분은 1개를 하든, 30개를 하든 1번 열의 결과는 동일하다
- 데이터가 동일하기 때문에, 축 마다 분산이 가장 큰 선도 동일하기 때문.
pca.explained_variance_ratio_로 주성분 별 오차율 확인
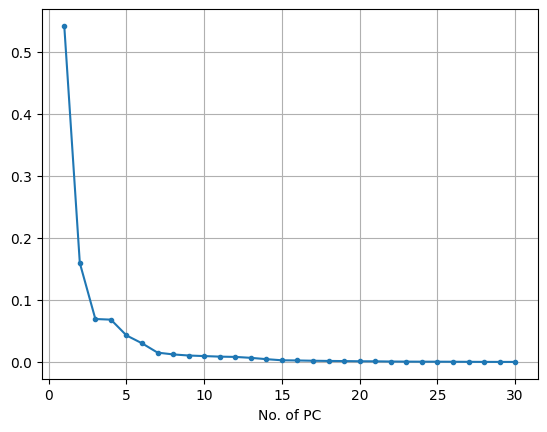
- Elbow Method (팔꿈치 방법) : 휴리스틱 법 중에 하나. 팔꿈치 지점 근방에서 적절한 값을 찾는 것이 좋다.
- 주성분과 차원은 트레이드 오프 관계
C. PCA - 지도학습 연계
# n으로 치환
ac_result = [] # 정확도 리스트
for n in range(1, 31):
# 데이터 준비
cols = column_names[:n]
x_train_pc_n = x_train_pc.loc[:, cols]
x_val_pc_n = x_val_pc.loc[:, cols]
# 모델링
model = KNeighborsClassifier()
model.fit(x_train_pc_n, y_train)
# 예측
pred = model.predict(x_val_pc_n)
# 평가
ac_result.append(accuracy_score(y_val, pred))# 시각화
plt.plot(range(1, 31), ac_result, marker='o')
plt.axhline(accuracy_score(y_val, pred0), color='r')
plt.grid()
plt.show()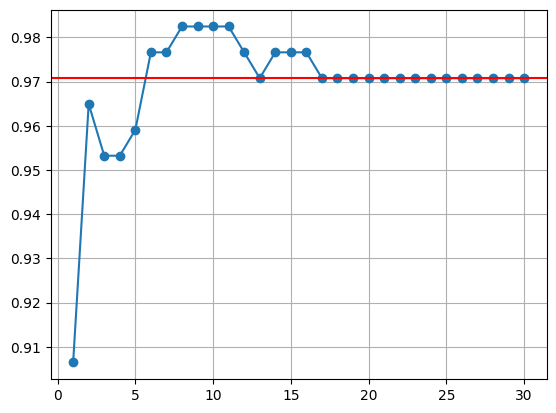
D. T-SNE
- 고차원의 특징(유사도) 를 최대한 유지
- 비선형 방식
- 2~3개로 축소함
