10/15 2, 3세션
A. 분류 모델 성능 평가
- 1과 0을 정확히 예측한 비율 :
정확도 (Accuracy) - 1이라고 예측한 것 중에서 정말 1인 비율 :
정밀도 (Precision) - 실제 1인 것을 1이라고 예측한 비율 :
재현율 (Recall)
A-1. 혼동 행렬
오분류표
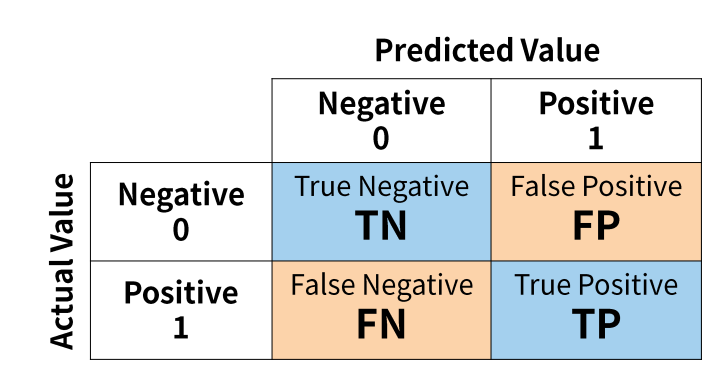
TN: 음성을 음성이라고 잘 예측FP: 음성을 양성이라고 잘 못 예측FN: 양성을 음성이라고 잘 못 예측TP: 양성을 양성이라고 잘 예측
A-2. Accuracy (정확도)
- 정분류율
- 전체 중에서 양성과 음성을 잘 예측 (TN + TP) 의 비율
A-3. Precision (정밀도)
- 양성으로 예측한 것 중에서 실제 양성인 비율
- ex) 비가 내릴 것으로 예측한 날 중에서 실제 비가 내린 날의 비율
- ex) 암이라고 예측한 환자 중에서 실제 암인 환자 비율
정밀도가 낮다면?
- 비가 오지 않았는데 비가 온다고 했으니 불필요하게 우산을 챙김
- 암이 아닌데 암이라고 했으니 불필요한 치료 발생
A-4. Recall (재현율, 민감도)
- 실제 양성 중에서 양성으로 예측한 비율
- 적극적인 예측 시 재현율이 높아짐
- 민감도 98% : 양성인데 음성이라고 예측한 비율이 2% 임. 만약 양성이라고 예측했다면 무조건 양성임.
- ex) 실제 비가 내린 날 중에서 비가 내릴 것으로 예측한 날의 비율
- ex) 실제 암인 환자 중에서 암이라고 예측한 환자의 비율
- 재현율이 낮으면 아주 심각한 결과가 초래됨
재현율이 낮다면?
- 비가 내리는 날에 내리지 않을 것이라고 예측했으므로 비를 맞음
- 암인 사람에게 암이 아니라고 예측했으므로 심각해짐
정밀도와 재현율은
상충 관계 (Trade Off)관계이다
A-5. Specificity (특이도)
- 실제 음성 중에서 음성이라고 예측한 비율
- 특이도 100% : 음성을 음성이라고 100% 예측함.
- 실제 비가 내리지 않은 날 중에서 비가 내리지 않을 것으로 예측한 날의 비율
- 실제 암이 아닌 환자 중에서 암이 아니라고 예측한 환자의 비율
특이도가 낮다면?
- 비가 오지 않는데 비가 온다고 했으니 불필요하게 우산을 챙김
- 암이 아닌데 암이라고 했으니 불필요한 치료 발생
B. F1-Score
B-1. 가중치 평균
수가 많은 쪽으로 가중치가 갈 수 있도록 함
ex) 키 150cm 인 사람 4명과, 200cm 인 사람 90명 이면,
B-2. 조화 평균
- 정밀도와 재현율의 조화 평균
C. 분류 모델 평가 함수
from sklearn.metrics라이브러리에 있음
import confusion_matrix
import accuracy_score
import precision_score
import recall_score
import f1_score
import classification_report
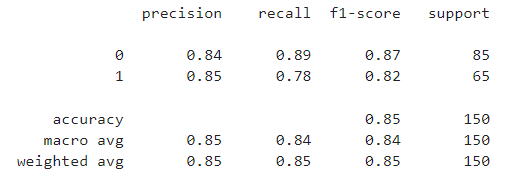
print('Recall :', recall_score(y_test, y_pred, average=None))
print(classification_report(y_test, y_pred))average 파라미터
- binary : default 값. 1을 기준으로 보여줌
- None : 0, 1 모두 보여줌
- macro : 산술평균
- weighted : 가중치평균