Entity를 조회하면서 연관된 Entity들 및 컬렉션을 함께 조회하는 방식 으로의 최적화를 다뤘던 [섹션4의 1,2,3,4 강] 복습에 이어
[5,6,7강]에서는 Entity가 아닌 DTO로 직접 조회하면서 연관된 Entity들 및 컬렉션들의 컬럼들도 함께 가져와서 DTO로 조회할 때의 최적화 부분을 다뤄본다.
그리고 [8강]에서는 이들을 아울러 연관된 Entity 및 컬렉션을 조회할 때 어떤 기준으로 조회하면 좋을지에 대해 정리하면서 이번 섹션을 마무리 한다.
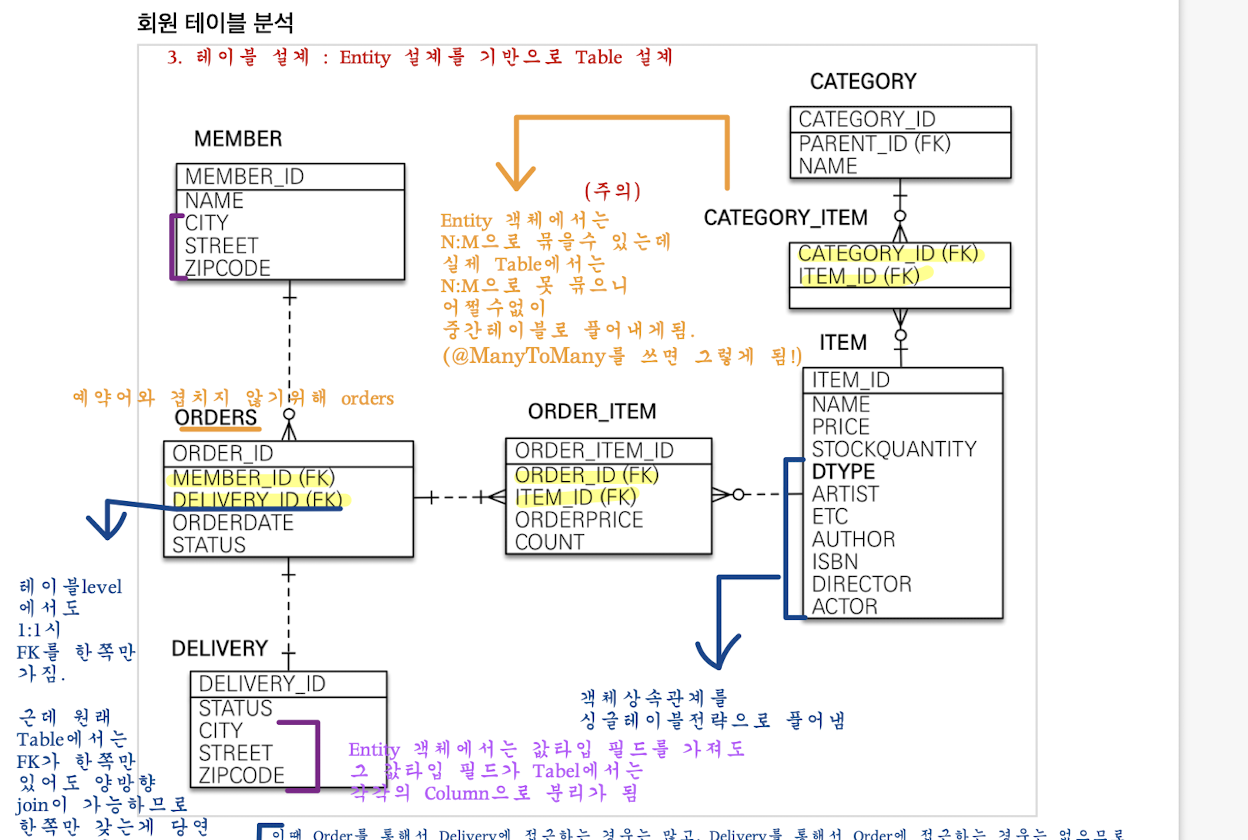
본격적으로 아래와 같은 ERD 관계 하에, Order 를 조회하면서 연관된 Member, Delivery 및 Order_Item들 및 Item들을 함께 접근하여 DTO로 직접 조회하는 과정을 살펴보자.
이때 버전을 높여가며 나가는 쿼리 숫자가 줄도록 성능 최적화를 시도할 것이다.
[버전4]
: DTO로 직접 조회할 때는 Order와 연관된 ToOne 관계의 Entity를 조회하는 과정과 / ToMany 관계의 컬렉션을 조회하는 과정을 분리해야 한다.0. DTO로 직접 조회하기 전에 먼저 수행해야 할 준비 작업
- DTO로 직접 조회하는 로직이 있는 별도의 Repository를 별도의 패키지에 생성하기
- 왜냐하면 DTO로 직접 조회하는 Repository로직은 여러 Service 및 Controller가 아니라 , 특정 API에서만 종속적으로 사용할 로직이기 때문에
-> 일반적인 Repository 패키지와는 별도로 분리하는 것이 좋다.- 따라서 우리의 경우는 repository 패키지 안에서 order.query 패키지를 새로 생성하여, 이 안에 정의하였다.
- 직접 조회할 DTO class를 기존 API DTO와 구분하여 , 별도의 패키지에 새로 정의하기
- 마찬가지로 이 DTO는 해당 API 에서만 종속적으로 사용할 것이므로, 기존의 DTO를 사용하지 말고 새로운 DTO를 정의하는 것이 좋다.
- 또한 이를 별도의 패키지로 구분하는 것이 좋다. (그 API에서만 쓸테니)
- 무엇보다도 기존 API에서 사용하는 DTO를 그냥 사용해버리면, Repository에서 -> Controller로 의존관계가 생겨버리고,
이에 따라 Controller의 DTO가 변하면 -> DTO로 직접 조회하는 Repository 로직도 변해야 하는 문제점이 발생할 수 있다.- 따라서 DTO로 직접 조회시 - 별도의 DTO를 별도의 패키지에 새로 정의하는 것이 좋다.
- 그리고 새로 정의한 DTO class에 JPQL로 조회가 가능하도록 하는 생성자를 정의하기
- DTO로 직접 조회하는 JPQL문은 new operation을 사용하게 되는데
- new 패키지경로.Dto(컬럼1, 컬럼2, 컬럼3) 형태 가 된다
- 이때 저 new operation에 대응가능한 생성자가 DTO 클래스에 정의되어 있어야 한다.
- 우리의 경우는 이러한 DTO 로써 repository.order.query 패키지 안에, OrderQueryDto , OrderItemQueryDto 클래스를 정의하였다.
(물론 대응되는 생성자도 함께 정의)
<이제 본격적으로 new 키워드를 사용한 DTO로 직접 조회>
: OrderQueryRepository 라는 별도의 Repository 안에 이 로직을 정의하였다.
- DTO로 직접 조회시 , Order와 연관된 Member, Delivery 의 컬럼이 필요한 경우 (페치 조인이 아닌) 그냥 join을 사용하여 해당 Entity들을 가져오고, 이들에게 별칭을 부여하여 - 그 별칭에 따른 특정 컬럼을 DTO에 넣는다
- 이에 따라 컬렉션을 제외한 연관된 Entity들을 함께 조회하면서 DTO로 직접 조회하는 루트 쿼리는 1번만 나가면 된다.
- 이후 조회한 DTO 값중 OrderId 값을 사용하여 ,
루프를 돌면서 각 OrderId와 연관된 OrderItem들을 역시 join으로 가져온 후, 이들에게 별칭을 부여하여 - 그 별칭에 따른 특정 컬럼을 DTO에 넣는다.
- 이때 OrderItem과 ToOne 관계로 연관된 Item을 함께 가져올 때도 그냥 join을 써서 가져오고 - 별칭을 부여하여 특정 컬럼을 DTO에 담으면 된다
(그렇게 해도 OrderItem에 대한 ToOne 관계라 추가적인 데이터 뻥튀기가 일어나지 않음 - 그냥 row 길이가 길어질 뿐 )
<정리하면 DTO로 직접 조회시에는>
1) 연관된 Entity들은 모두 한꺼번에 join으로 가져와 - 별칭을 부여하여 - 그 별칭에 따른 컬럼을 DTO에 넣고
2) 이후에 데이터 뻥튀기가 일어나는 컬렉션은 , ToOne 관계의 Entity와는 별개로 join으로 가져와서 - 별칭을 부여한 후 - 별칭에 따른 컬럼을 DTO에 넣어야 한다.즉 이렇게 DTO로 직접 조회시 연관된 Entity들과 연관된 컬렉션을 조회하는 로직을 반드시 분리하는 것이 중요하고 /
(Entity 조회때 처럼 distinct 로 Entity와 컬렉션을 한꺼번에 못가져옴.)
그에 따른 1+N 문제가 필연적으로 발생함을 기억해야 한다.
- 우리의 경우도 조회되는 Order는 2개이고 , 각 Order별로 2개씩 OrderItem과 연관되어 있는데
- Order를 조회하여 DTO에 담는 루트 쿼리는 1번 나가지만
- 각 OrderId 별로 연관된 OrderItem들을 조회해서 DTO로 담아서 조회하는 쿼리가 2번 더 나가니 ,
- 이게 곧 1+2 ==> 1+N 문제 이다!!
이러한 V4 관련 코드
[일단 DTO로 직접 조회하는 Repository 를 사용한 API]

[DTO로 직접 조회하는 것과 관련된 DTO 및 Repository를 별도의 패키지에 새로 정의]

[직접 조회할 DTO 클래스를 별도로 정의함]
이때 direct로 조회할 수 있도록 대응되는 생성자를 정의해놓음


[마지막으로 위 DTO로 직접 조회하는 Repository]
: 핵심은 결국 1번의 루트 쿼리와 N번의 컬렉션 조회 쿼리가 각각 나갈 수 밖에 없단 점
/**
* 1) 일단 컬렉션을 제외한 , Member와 Delivery만 join으로 함께 조회하여 DTO에 넣기
* 2) 이후 컬렉션들인 OrderItem들 그리고 이와 연관된 Item들을 join으로 조회하여 DTO에 넣기
* */
public List<OrderQueryDto> findOrderQueryDtos(){
List<OrderQueryDto> result = findOrders();
result.forEach(o -> {
List<OrderItemQueryDto> orderItems = findOrderItems(o.getOrderId());
o.setOrderItems(orderItems);
});
return result;
}
/** [1:N] 관계인 컬렉션을 제외한 , 나머지를 한꺼번에 가져오면서 DTO로 */
private List<OrderQueryDto> findOrders(){
return em.createQuery("select new jpabook.jpashop_review.repository.order.query.OrderQueryDto" +
"(o.id, m.name, o.orderDate, o.status, d.address) " +
"from Order o join o.member m join o.delivery d", OrderQueryDto.class)
.getResultList();
}
/** 그 외 [1:N] 관계인 orderItems를 한꺼번에 가져와서 DTO로 */
private List<OrderItemQueryDto> findOrderItems(Long orderId){
return em.createQuery("select new jpabook.jpashop_review.repository.order.query.OrderItemQueryDto" +
"(oi.order.id, i.name, oi.orderPrice, oi.count) from OrderItem oi join oi.item i "
+ " where oi.order.id = :orderId", OrderItemQueryDto.class)
.setParameter("orderId", orderId)
.getResultList();
}
[버전5]
: DTO로 직접 조회시 나가는 1번의 루트 쿼리와 + N번의 컬렉션 조회 쿼리 중, 컬렉션 조회 쿼리를 1번만 나가도록 최적화 시킨 버전
- 일단 ToOne 관계의 Entity를 join으로 함꼐 조회하여 - 이들에게 별칭을 부여하고 - 이를 통해 DTO로 직접 조회하는 로직에 따른 -> 루트쿼리는 그대로 1번만 나감
- 단 V4에서 루트쿼리로 조회한 각 OrderId와 연관된 OrderItem 컬렉션들을 일일이 루프를 돌면서 N번 쿼리를 날렸던 것 과 다르게
V5에서는 루트쿼리로 조회한 모든 OrderId들에 대해서 - 한번에 In 절을 사용하여 연관된 OrderItem 컬렉션들을 한꺼번에 조회 한다
(이때 in절 사용은 join이 아니라 where문이라는 내용은 -- SQL 내용이다..)
- In절로 연관된 OrderItem을 한꺼번에 join 해오는 과정에서 , 역시 별칭을 부여하여 Item까지 함께 join으로 가져오는것은 문제가 되지 x
(OrderItem과 Item은 ToOne 관계 이므로, 함께 가져와도 row수가 늘어나지는 않고, row 길이만 늘어나므로)- 그보다는 애초에 모든 OrderId들을 JPQL로 넘길 수 있다는 것에 주목해야 함
- orderId들을 List로 담아서 넘기고 , setParameter() 메서드를 통해 이 모든 orderId들을 한꺼번에 사용 할 수 있음
- 이렇게 In절을 사용한 where문으로 결국 컬렉션 조회쿼리가 1방만 나가도록 최적화 된다고 해도
-> 그 결과는 결국 getResultList()에 의해 하나의 리스트로 모두 담아져서 반환된다
-> 따라서 우리의 경우는 orderId별로 연관된 OrderItem 컬렉션 들을 MAP에 묶어서 반환해주었다.
<그래서 결과적으로>
1. 루트쿼리 1방과
2. 컬렉션 조회 쿼리 1방으로
필요한 데이터를 DTO 로 직접 조회해 올 수 있게 됨.
이러한 V5관련 코드
[API]

[Repository 로직]
/**
* 최적화
* Query : 루트 쿼리 1번 + 컬렉션 조회 쿼리 1번
* -> 이는 데이터를 한꺼번에 처리할 때 많이 사용되는 방식
* */
public List<OrderQueryDto> findAllByDto_optimization(){
//1) 일단 루트 조회 : ToOne 코드를 모두 한번에 조회
List<OrderQueryDto> result = findOrders();
//2) OrderItem 컬렉션을 MAP 한방에 조회 -> SQL 레벨에서 In절을 사용하므로 가능 (결국 배치사이즈 조절과 같은 원리)
Map<Long, List<OrderItemQueryDto>> orderItemMap = findOrderItemMap(toOrderIds(result));
//3) 이제 루프를 돌면서 조회한 OrderItemQueryDto를 -> 각 OrderQueryDto 안에 넣기 [포인트는 이때 쿼리가 안나간다는 점!]
result.forEach(o -> o.setOrderItems(orderItemMap.get(o.getOrderId())));
return result;
}
private List<Long> toOrderIds(List<OrderQueryDto> result){
return result.stream()
.map(o -> o.getOrderId())
.collect(Collectors.toList());
}
private Map<Long, List<OrderItemQueryDto>> findOrderItemMap(List<Long> orderIds){
List<OrderItemQueryDto> orderItems = em.createQuery("select new jpabook.jpashop_review.repository.order.query.OrderItemQueryDto(" +
"oi.order.id, i.name, oi.orderPrice, oi.count) " +
" from OrderItem oi join oi.item i where oi.order.id in :orderIds", OrderItemQueryDto.class)
.setParameter("orderIds", orderIds)
.getResultList();
return orderItems.stream()
.collect(Collectors.groupingBy(OrderItemQueryDto::getOrderId));
}
[버전6]
: v6는 연관된 Entity와 연관된 컬렉션들을 모두 join으로 조회햐여 , 필요한 컬럼을 DTO에 담아 - DTO로 바로 조회하는 방법이다
- 이렇게 하면 필연적으로 컬렉션과 join하는 과정에서 데이터 뻥튀기 문제가 발생 한다.
- 따라서 이를 개발자가 직접 파싱해서 해결해주는 후처리를 수행해줘야 한다.
- 솔직히 나는 이 예제에서 사용된 후처리 코드에 대한 이해가 부족하여,
일단 v6에 대해서는 이렇게 큰 흐름 위주로만 정리하고 , 그 코드를 첨부하겠다.
<이 방식의 장단점>
- 어쨌든 네트워크를 타는 쿼리가 1방만 나간다는 점은 장점이다
- 그러나 그 1방쿼리를 타고 넘어오는 데이터 양이 무척이나 방대할 수 밖에 없고, 이를 일일이 개발자가 중복을 제거하고 파싱해줘야 하므로 이는 단점이다.
(심지어 이 때문에 오히려 쿼리가 2방 나가는 V5보다 느릴 수 도 있다.)- 그리고 결정적으로 일단 조회해오는 당시 컬렉션에 의한 데이터 뻥튀기가 발생하기 때문에, 루트 Entity인 Order를 기준으로 페이징은 불가능 하게 된다.
-> 이점이 현업에서는 크리티컬한 한계점이 될 수 있다.
v6 관련 코드를 아래 첨부하겠다.
[API]
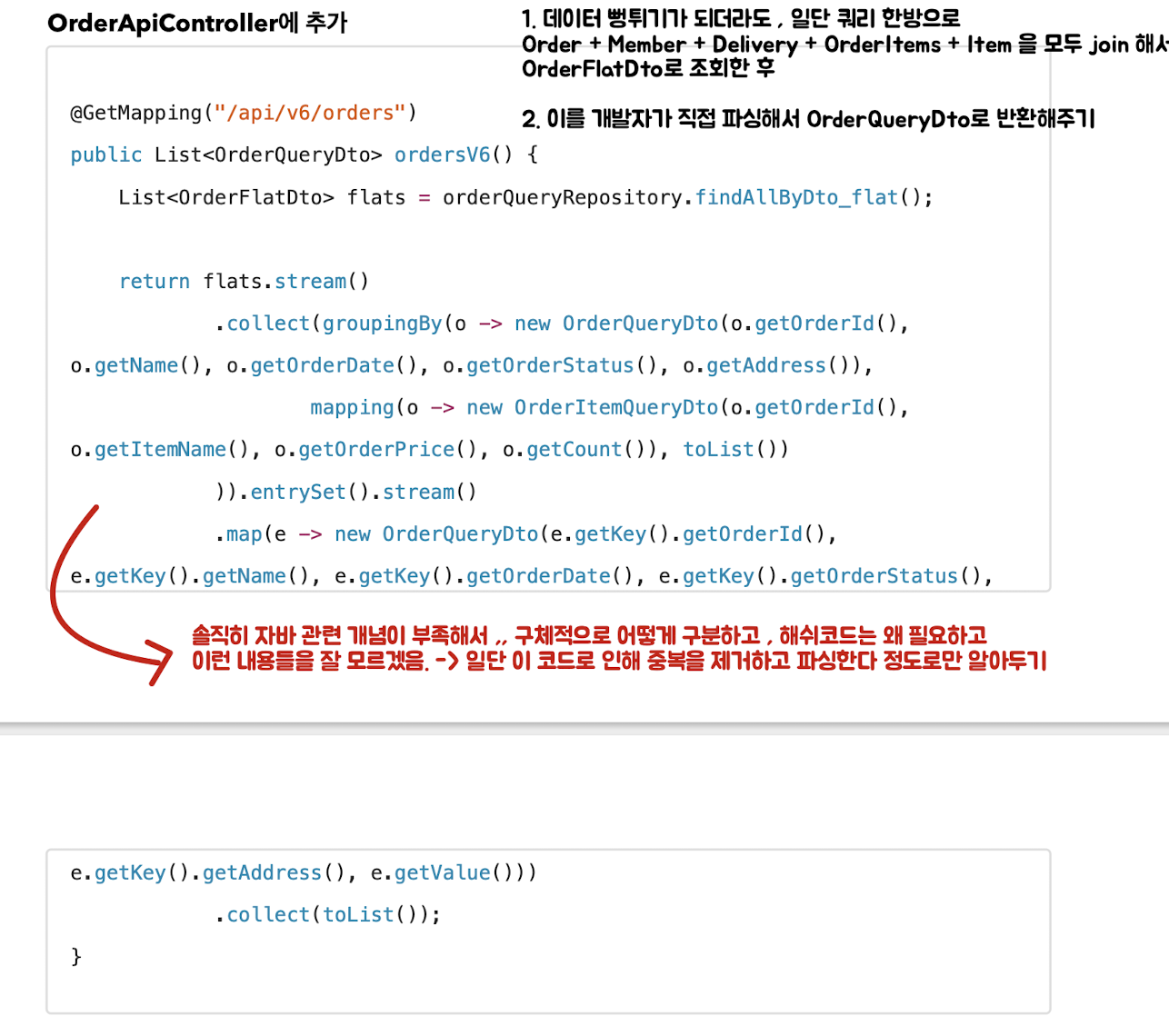
[한방에 조회해 오는 Repository 로직]

이제 마지막으로 Entity 조회와 DTO 직접 조회에 대한 결론을 정리해보자.
[어떻게 조회할 것인가]
1. 기본적으로 Entity로 조회하는 것이 코드가 더 간결하면서 JPA가 알아서 최적화도 해주기 때문에 더 좋다.(DTO조회 쿼리 보면 , 별도 DTO에 적절한 생성자도 정의해야 하고 , new 키워드 사용까지 코드가 복잡함을 알 수 O)
- 이때 페이징을 안해도 된다면 distinct를 사용하여 연관된 컬렉션과 , Entity들을 모두 함께 가져오는 페치조인을 사용하고
- 페이징을 해야한다면 ToOne 관계만 페치조인으로 한방에 가져오면서 - 페이징을 수행한 후 -> 컬렉션은 배치사이즈를 조절하여 LAZY로딩으로 1방 혹은 최소한으로 최적화 하여 가져오자
2. 그런데 Entity를 조회하는 방식이 성능이 부족하거나 or DTO로 직접 조회해야 하는 상황이라면
- 연관된 Entity들은 join을 써서 루트쿼리 한방으로 가져오고
- 이후 PK값들을 List로 한번에 넘겨서 - in절을 사용한 where 문으로 1방에 가져오자
(솔직히 V6의 1방에 다 가져오고 - 후처리로 중복을 제거하는 방법은 , 지금의 나는 못쓰겠다.. 복잡해서)그런데 솔직히 위 Entity 조회 최적화 방식으로 성능이 나오지 않는다면, DTO로 직접 조회하기 보다는 Redis등을 사용한 캐싱을 쓰는게 더 효율적일 것이다.
- 단 Entity는 영속성 컨텍스트에 의해 관리되므로 함부로 캐시에 올리면 문제가 될 수 있으므로
- 캐시에 올릴 때는 반드시 DTO를 올려야 한다
3. 어쨌거나 DTO 직접 조회로도 성능이 부족하면 NativeSQL or Spring Jdbc Template를 쓰는 방법도 있다!
