
크롤링 시점 기준 알림에서 → 이슈 시작 시점 기준 알림으로
왜 바꿔야 했나?
기존 가는길 지금 알림 시스템에는 구조적인 문제가 하나 있었습니다.
교통 이슈 데이터를 크롤링해오는 순간, 현재 시간이 이슈 시작 시간보다 이후이고 종료 시간보다 이전이면 곧바로 알림을 발송하는 방식이었습니다. 언뜻 보면 합리적인 것 같지만, 실제로는 알림이 이슈 시작 시점이 아니라 크롤링 시점에 종속되는 문제가 있었습니다.
쉽게 말해, 크롤링해온 시점에 아직 시작되지 않은 미래 이슈는 "현재 시간 > 이슈 시작 시간" 조건을 만족하지 못하기 때문에 알림 자체가 발송되지 않습니다. 저희 앱의 핵심 서비스가 이슈 알림인데, 예정된 공사나 행사처럼 미리 등록된 교통 이슈에 대해서는 알림이 아예 나가지 않는 상황이었습니다.
AS-IS: 기존 구조의 문제점
기존 흐름은 이랬다.
크롤러 실행
→ 현재 시간이 [이슈 시작 ~ 이슈 종료] 범위 내이면
→ 사용자 알림 조건 확인
→ Kafka 전송 → FCM 발송Redis에는 이슈의 시작 시간, 종료 시간을 단순 Hash로 저장하고 있었다.
핵심 문제: 알림 발송 타이밍이 "크롤링 주기"에 묶여 있었다. 이슈 시작 시각에 정확히 맞춰 알림을 보내는 것이 불가능하고 이슈 알림이 누락될 가능성이 있었습니다.
TO-BE: 새로운 설계
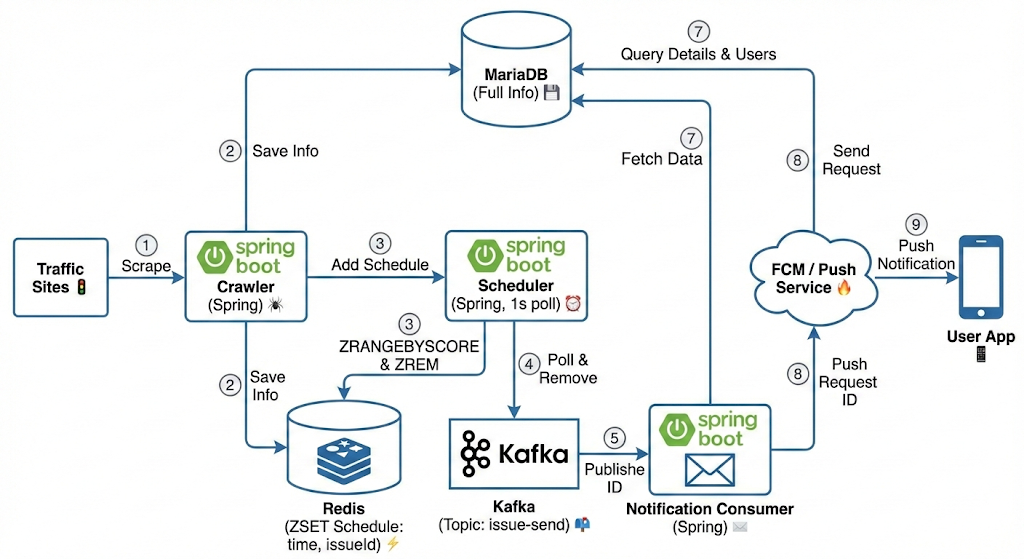
전체 흐름
크롤러
-> Redis Sorted Set에 이슈 ID와 시작 시각(score) 저장
→ 스케줄러(매 초/분 단위)가 Redis를 폴링
→ Kafka (traffic-issue-events) 토픽으로 이벤트 발행
→ Consumer가 소비
→ 알림을 보낼 이슈만 Kafka Sender 호출
→ FCM 발송핵심 변화 두 가지
- Redis를 Hash → Sorted Set으로 전환
- 알림 발송 트리거를 크롤링에서 스케줄러로 분리
왜 Redis Sorted Set인가?
구조
Key: pending_notifications
Score: 알림 발송 예정 시각 (Unix Timestamp)
Value: 이슈 ID (JSON 또는 숫자)핵심 쿼리 하나로 해결
ZRANGEBYSCORE pending_notifications 0 <현재_Unix_Timestamp> @Override
public Set<String> getDueIssueIds(String key, long currentTimestamp) {
// 0부터 현재 시간(currentTimestamp)까지의 모든 Issue ID 조회
return redisTemplate.opsForZSet().rangeByScore(key, 0, currentTimestamp);
}MariaDB에서 WHERE send_at <= NOW()로 매번 풀스캔하는 것과 비교하면 성능 차이가 압도적입니다. Sorted Set은 score 기반으로 정렬되어 있으므로 원하는 범위의 데이터를 O(log N + M) 으로 가져올 수 있고 이미 프로젝트에서 redis를 사용하고 있었습니다.
"알림 데이터" 말고 "이슈 ID"를 저장하는 이유
처음에는 Redis에 사용자별 알림 메시지를 미리 만들어 넣으면 어떨까 생각했다. 하지만 그건 1:N(일대다) 문제를 가장 비효율적인 시점에 처리하는 방식입이다.
"강남역 사고"라는 이슈는 하나지만, 알림을 받아야 할 사람은 수백 명에서 더 많아지면 수만명이다. 수만 명 분의 메시지를 미리 만들어 Redis에 넣어두는 순간 어떤 문제가 생기는지 비교해보면 명확하다.
| 비교 항목 | 알림 데이터 저장 ❌ | 이슈 ID 저장 ✅ |
|---|---|---|
| 메모리 사용량 | 사용자 수 × 이슈 수만큼 폭발적 증가 | 이슈 수만큼만 (거의 없음) |
| 내용 수정 시 | 만들어진 수만 개 메시지를 전부 수정해야 함 | DB 원본 1개만 수정하면 끝 |
| 알림 취소 시 | Redis 키를 수만 개 검색해서 삭제 | ZREM으로 ID 하나만 삭제 |
| 실시간성 | 저장 시점의 사용자 정보를 사용 | 발송 시점의 최신 정보로 발송 가능 |
결론: Redis에는 "언제, 무엇(ID)을 실행할지" 넣어두고, 실제 전파(확산)는 Consumer가 DB를 보고 수행하는 것이 맞다.
왜 Kafka를 쓰는가?

이미 인프라에 Kafka가 있었기 때문에 "쓸래 말래"가 아니라 "어떻게 잘 쓸까"의 문제였다. Kafka를 사용하면 다음 세 가지를 얻을 수 있다.
① 스케줄러의 정확한 역할 및 책임 분리 (Non-blocking)
Kafka 없이 스케줄러가 직접 DB 조회, 알림 생성, FCM 전송까지 다 하면 1초 간격 스케줄이 밀릴 수 있다.
Kafka를 쓰면 스케줄러는 "야, 이거 보내!" 하고 Kafka에 던지기만 한다. 스케줄러는 시간 체크 본연의 역할에만 집중할 수 있다.
② 트래픽 폭주 시 댐 역할 (Backpressure)
갑자기 1분에 이슈가 1,000개 터지면? Kafka 없이는 DB 조회 1,000번, FCM 요청 1,000번이 동시에 터져서 서버가 다운될 수 있다.
Kafka가 있으면 일단 큐에 1,000개가 차곡차곡 쌓이고, Consumer는 자기가 처리할 수 있는 속도로 하나씩 꺼낸다. 서버가 죽지 않는다.
③ 장애 격리 (Fault Tolerance)
FCM 서버가 터지거나 Consumer에 버그가 생겼을 때, Kafka 없이는 데이터가 유실된다.
Kafka에는 데이터가 그대로 남아있으므로 서버를 고치고 재시작하면 그 시점부터 이어서 발송할 수 있다. 그리고 이미 프로젝트에서는, 재시도를 반복해도 끝내 처리에 실패한 메시지는 DLT(Dead Letter Topic) 로 이동시키고 있다. 정상 처리 흐름을 막지 않으면서도 실패한 알림을 유실 없이 별도로 보관해두기 때문에, 원인을 파악한 뒤 재처리하거나 모니터링하는 것이 가능하다.
@KafkaListener(topics = "notification.dlt", groupId = "gazi", containerFactory = "notificationListenerContainerFactory") // DLT 토픽 리스너
public void handleDltMessage(NotificationCreate notificationCreate) {
try {
log.error("DLT로 이동된 메시지: {}", notificationCreate);
// Slack 알림 전송
sendSlackNotification(notificationCreate);
} catch (Exception e) {
log.error("DLT 메시지 처리 중 오류 발생: {}", e.getMessage(), e);
}
}
private void sendSlackNotification(NotificationCreate notificationCreate) {
try {
// NotificationCreate 객체를 JSON 문자열로 변환
String notificationJson = objectMapper.writeValueAsString(notificationCreate);
// Slack 메시지 내용 생성
String slackMessage = String.format(
"⚠️ DLT Message Detected ⚠️\n" +
"Details: ```%s```\n" +
"Please check the issue."
, notificationJson);
// Slack Webhook으로 메시지 전송
String payload = objectMapper.writeValueAsString(new SlackPayload(slackMessage));
restTemplate.postForObject(SLACK_WEBHOOK_URL, payload, String.class);
log.info("Slack 알림 전송 완료: {}", slackMessage);
} catch (JsonProcessingException e) {
log.error("Slack 메시지 생성 중 JSON 처리 오류: {}", e.getMessage(), e);
} catch (Exception e) {
log.error("Slack 알림 전송 실패: {}", e.getMessage(), e);
}
}MariaDB의 역할
Redis와 Kafka가 실시간 처리를 담당한다면, MariaDB는 영속성과 이력 관리를 담당한다.
- 교통 이슈 원본 데이터 전체 저장
- 알림 발송 이력 저장
- 사용자의 "지난 알림 보기" 기능
Redis는 빠르고 휘발적이고, MariaDB는 느리지만 영구적이다. 두 스토리지가 역할을 분명히 나눠 갖는 구조다.
한 줄 정리
- Redis Sorted Set: 수만 명분 데이터를 미리 만들지 말고, 언제(Time) 무엇(ID)을 실행할지 스케줄표만 관리해서 메모리를 아끼자.
- Kafka: 이슈가 폭주해도 서버가 죽지 않도록 중간에서 완충재(Buffer) 역할을 하고, 스케줄러와 발송 로직을 완벽히 분리하자.
