

목차
1. 성능 개선하게 된 배경
지금 식구하자 프로젝트 SNS 마이크로서비스 기능 중 생성 유저 기준 SNS 게시글 조회 API 에서 있던 쿼리는 다른 쿼리들에 비해 유난히 오래 걸렸습니다.
기본적으로 존재하는 클러스터링 인덱스와 FK 인덱스로는 해당 쿼리가 인덱스를 타지 않아, 다른 기본 조회 쿼리에 비해 이에 따라 해당 쿼리의 성능을 최대한 끌어올려보고자 최적의 인덱스를 찾아보기로 하였습니다.
2. 테스트 데이터
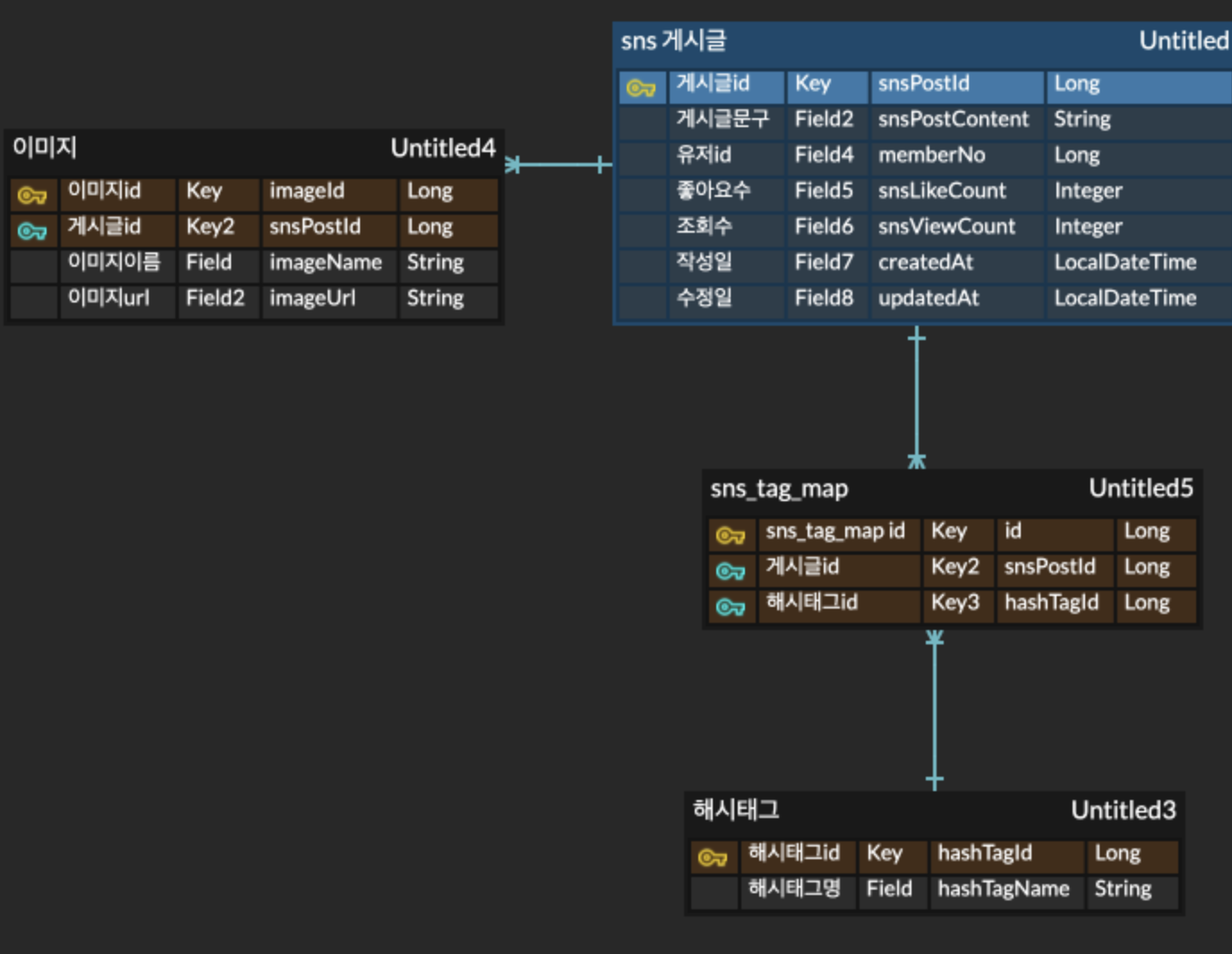
먼저 쿼리를 개선하기 위해서, 대상 테이블에 프로시저를 활용해서 각각 아래와 같은 5만개의 더미 데이터를 삽입 해보도록 하겠습니다.
📚 더미 데이터 예시
DELIMITER //
CREATE PROCEDURE InsertDummyData()
BEGIN
DECLARE counter INT DEFAULT 0;
WHILE counter < 50000 DO
INSERT INTO sns_post (
sns_views_count,
sns_post_title,
sns_post_content,
sns_likes_count,
memebr_no,
created_by,
created_at
)
VALUES (
FLOOR(RAND() * 1000), -- sns_views_count: 0에서 999 사이의 임의의 값
CONCAT('Post Title ', counter + 1), -- sns_post_title: 'Post Title ' + 번호
CONCAT('This is the content for post number ', counter + 1), -- sns_post_content: 'This is the content for post number ' + 번호
FLOOR(RAND() * 100), -- sns_likes_count: 0에서 99 사이의 임의의 값
FLOOR(RAND() * 1000), -- memebr_no: 0에서 999 사이의 임의의 값
CONCAT('User', FLOOR(RAND() * 100)), -- created_by: 'User' + 0에서 99 사이의 임의의 값
DATE_ADD(NOW(), INTERVAL -FLOOR(RAND() * 365) DAY) -- created_at: 현재 시간으로부터 최대 1년 전까지의 임의의 날짜
);
SET counter = counter + 1;
END WHILE;
END //
DELIMITER ;
DELIMITER //
CREATE PROCEDURE InsertDummyHashTags()
BEGIN
DECLARE counter INT DEFAULT 0;
WHILE counter < 50000 DO
INSERT INTO hash_tag (hash_tag_name)
VALUES (
CONCAT('#tag', LPAD(counter + 1, 6, '0')) -- #tag000001부터 #tag050000까지
);
SET counter = counter + 1;
END WHILE;
END //
DELIMITER ;3. 문제점 파악
개선하기 전의 쿼리
SELECT
sp.sns_post_id,
sp.memebr_no,
sp.sns_post_title,
sp.sns_post_content,
sp.created_by,
sp.created_at,
sp.sns_likes_count,
sp.sns_views_count,
ht.hash_tag_name,
i.image_url
FROM
sns_hash_tag_map shtm
INNER JOIN
sns_post sp ON shtm.sns_post_id = sp.sns_post_id
INNER JOIN
hash_tag ht ON shtm.hash_tag_id = ht.hash_tag_id
INNER JOIN
image i ON sp.sns_post_id = i.sns_post_id
WHERE
sp.created_by = "User1"
ORDER BY sp.created_at desc;
sns_post(sns_게시글), sns_hash_tag_map(게시글 <-> 해시태그 매핑), hash_tag(해시태그), image(이미지) 4개의 테이블을 조인하고 조건절에는 User1이라는 유저가 작성한 게시글을 Order By절에서 최신순으로 정렬중인 쿼리입니다.
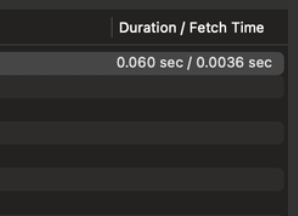
위 쿼리의 실행 속도는 더미데이터 5만건을 기준으로 약 0.060초가 소요되었습니다.
더미데이터를 삽입을 하고 아래와 같은 실행계획을 확인해보도록 하겠습니다.
📌 여기서 잠깐!
실행 계획(explain)이란?
실행 계획(explain)은 클라이언트가 MySQL 서버에 요청한 SQL문을 어떻게 데이터를 불러올 것인지에 관한 계획, 경로를 의미한다.
실행 계획 정보를 활용하여 SQL 튜닝을 할 수 있다. 단, 실제 수행 순서가 아닌 MySQL의 통계 정보를 기반으로 계산한 예측값이다. 실제값으로 실행 결과를 보려면 옵션을 추가해야한다.
↪️ 실행계획
EXPLAIN
SELECT
sp.sns_post_id,
sp.memebr_no,
sp.sns_post_title,
sp.sns_post_content,
sp.created_by,
sp.created_at,
sp.sns_likes_count,
sp.sns_views_count,
ht.hash_tag_name,
i.image_url
FROM
sns_hash_tag_map shtm
INNER JOIN
sns_post sp ON shtm.sns_post_id = sp.sns_post_id
INNER JOIN
hash_tag ht ON shtm.hash_tag_id = ht.hash_tag_id
INNER JOIN
image i ON sp.sns_post_id = i.sns_post_id
ORDER BY
sp.created_at DESC;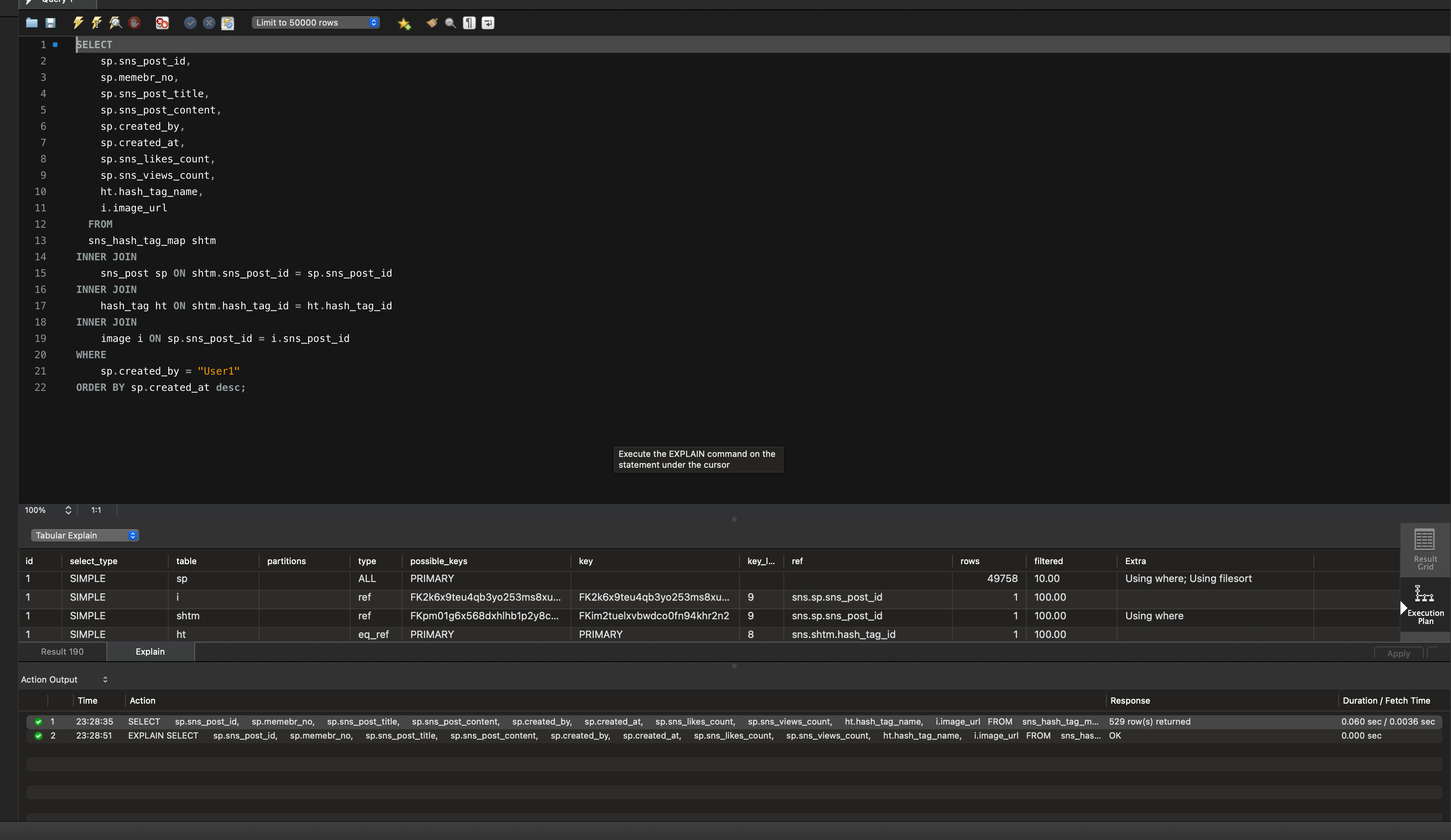
현재 실행계획에서 눈여겨봐야 할 부분이 있는데 type과 Extra 입니다.
sns_post의 type=all, Extra부분을 보면 Using FileSort를 확인할 수 있습니다.
1️⃣ type - ALL
테이블 풀 스캔. 활용할 인덱스가 없거나 인덱스 사용이 비효율적이라고 옵티마이저의 판단 시 사용됩니다.성능 면에서 굉장히 좋지 않습니다.
2️⃣ - Using filesort
인덱스로 정렬되어 있지 않은 레코드를 정렬합니다.

실행계획으로 판단했을 땐, 조건절과 정렬하는 컬럼에 해당하는 인덱스가 존재하지 않아 테이블 풀 스캔이 되고 있는 것 같습니다,,,
🔎 인덱스 조사
SHOW INDEX FROM sns_post;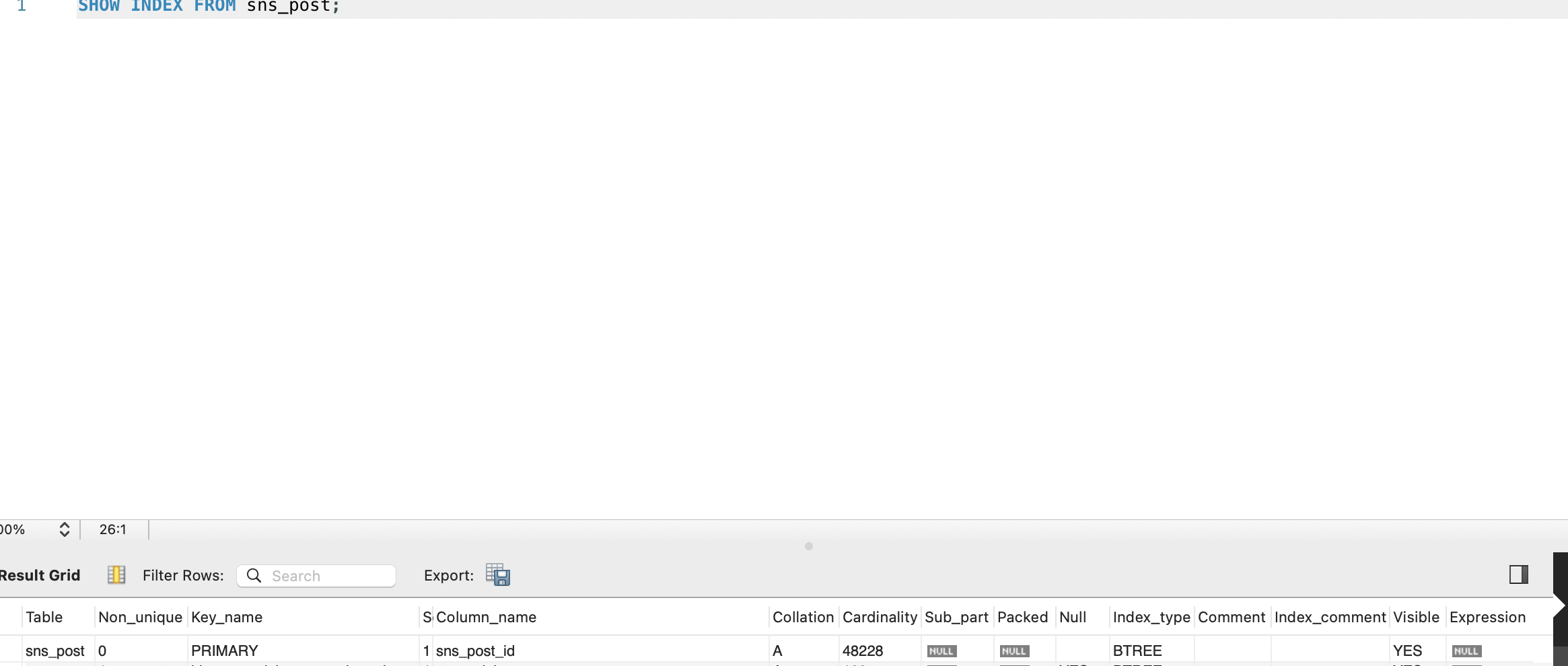
현재 생성되어 있는 인덱스는 위의 1개입니다. PRIMARY sns_post_id 는 테이블이 생성될 때 자동으로 생성되는 인덱스입니다. 테이블이 생성될 때, Inno DB 는 기본키와 외래키에 대해 자동으로 인덱스를 생성합니다
4. 개선: 인덱스 생성
현재 쿼리의 성능을 개선하기 위해 created_by와 created_at 컬럼에 대한 인덱스를 생성해보도록 하겠습니다!
🤔 고민 사항: 단일 인덱스 vs 복합 인덱스 vs 커버링 인덱스
단일 인덱스를 여러 개 생성할지, 복합 인덱스를 생성할지, 또는 커버링 인덱스를 사용할지에 대한 고민이 필요합니다.
🧑🏫 결정: 복합 인덱스 (created_by, created_at)
복합 인덱스를 생성하기로 결정했습니다! 그 이유는
- 쿼리 최적화:
WHERE절과ORDER BY에 동시에 사용되는 컬럼들을 하나의 인덱스로 커버할 수 있습니다. - 인덱스 효율: 복합 인덱스는 여러 컬럼을 동시에 고려하므로, 단일 인덱스보다 더 효율적일 수 있습니다.
- 저장 공간 효율: 여러 개의 단일 인덱스보다 하나의 복합 인덱스가 저장 공간을 덜 사용합니다.
커버링 인덱스의 경우, SELECT 절의 모든 컬럼에 인덱스를 적용하면 당장의 조회 성능은 향상될 수 있습니다. 하지만 이는 추후 데이터 수정이나 삭제 시 발생할 수 있는 오버헤드를 고려하면 실용적이지 않다고 판단하였습니다. 현재의 복합 인덱스만으로도 상당한 성능 개선을 이루었으며, 향후 데이터 관리의 효율성도 고려하여 복합 인덱스를 사용하는 것이 가장 적절한 선택이라고 결정하였습니다.
인덱스 생성 SQL
CREATE INDEX idx_created_by_created_at ON sns_post (created_by, created_at);그리고 다시 실행해보면!
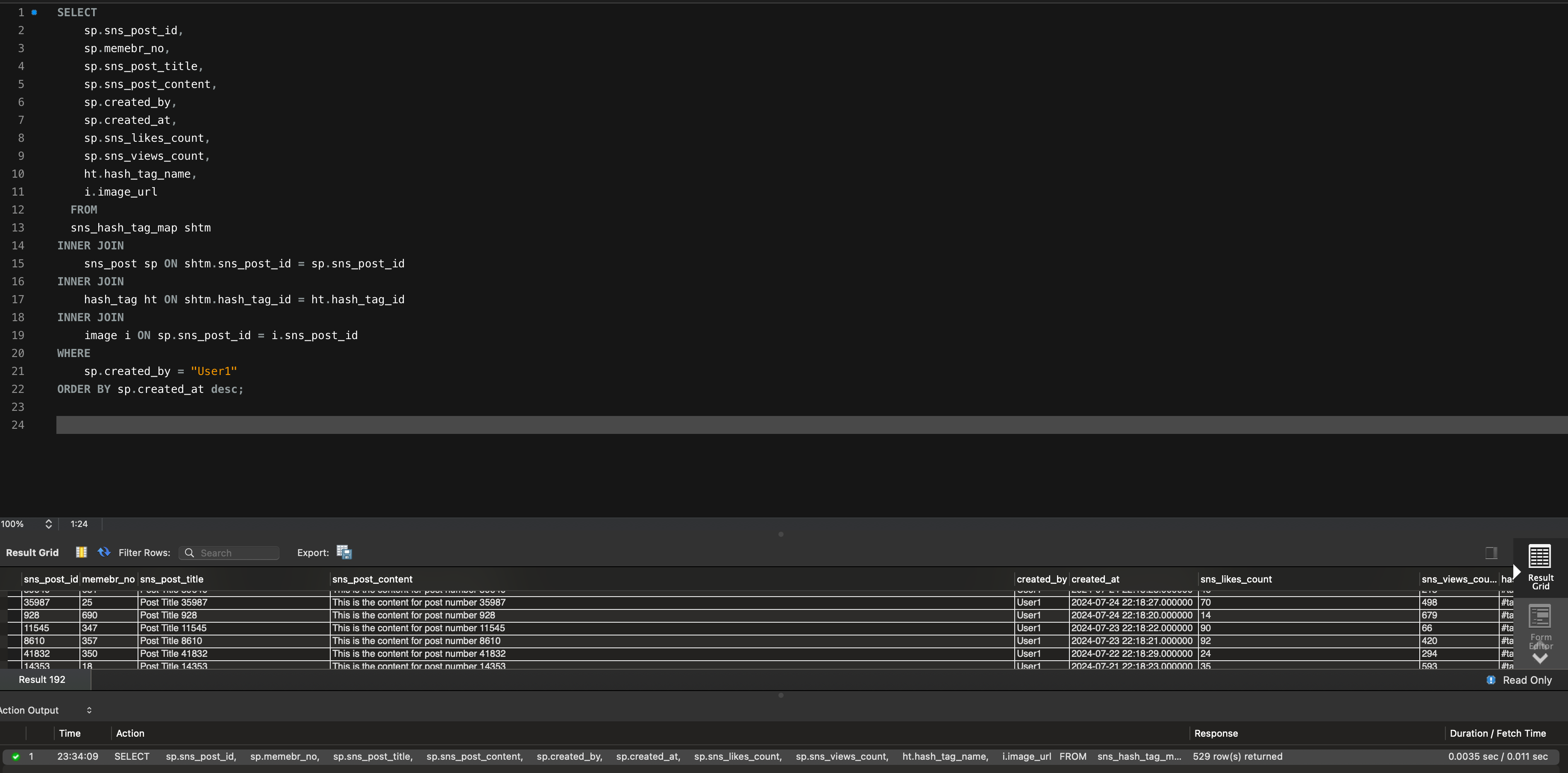
실행속도가 기존 쿼리 0.060sec 에서 0.0035sec로 거의 17배 빨라졌습니다!
실행 계획도 확인해보면!

type이 all에서 ref로 바뀌었고 key 컬럼에 방금 생성한 (created_by, created_at) 의 복합 인덱스가 인덱스로 사용된 것을 확인할 수 있습니다. 그리고 Using filesort 도 떼어낼 수 있었습니다!!
추가 문제 상황 : Backward index scan
Backward index scan 이라는 새로운 작은 혹이 새로 발생하였습니다. 요구 사항 정책 상, 날짜를 최신순으로 정렬하여 응답하기때문에 내림차순 정렬을 이용하였고, 이로 인해 인덱스를 뒤에서 부터 읽는 Backward index scan 이 발생하였습니다.
역순 인덱스 설정
MySQL에서는 인덱스 역순 정렬 기능을 지원합니다. 이 기능의 지원 내역은 다음과 같습니다:
- MySQL 8.0 이전: 문법상으로만 지원 (실제로는 미지원)
- MySQL 8.0 이후: 역순 인덱스 실제 적용 가능
역순 인덱스에 대한 자세한 내용은 MySQL Ascending index vs Descending index에서 확인할 수 있습니다.
인덱스 스캔 방향에 따른 성능 차이
인덱스 페이지 구조가 double linked list임에도 불구하고 forward scan과 backward scan 사이에 성능 차이가 발생하는 이유는 다음과 같습니다:
- 페이지 잠금 구조: forward index scan에 더 적합한 구조로 설계되어 있습니다.
- 인덱스 페이지 내부 구조: 인덱스 레코드가 단방향으로만 연결되어 있습니다.
성능 차이가 두드러지는 상황
forward index scan과 backward index scan의 성능 차이가 특히 두드러지는 경우는 다음과 같습니다:
- 쿼리가 하나의 인덱스 페이지에 집중되는 상황
- 이 경우, 페이지 잠금을 획득하기 위한 쓰레드 간 경합이 빈번하게 발생하여 처리 시간이 길어질 수 있습니다.
예시
select tid from t1
where tid<=@random_tid order by tid DESC limit 50;
select title, rental_datetime from rentals
where language = 'Italian'
order by rental_datetime desc;두 쿼리 모두 조건절에서 필터링되어 하나의 인덱스 페이지에 집중되는 상황입니다. 현재 인덱스를 적용하려는 저의 쿼리와 많이 유사합니다. 현재의 쿼리도 created_by 로 조건절 필터링을 하기때문에 필터링된 created_by 를 가진 인덱스 페이지에 집중되는 상황입니다. 이에 따라 역순 인덱스를 적용할 필요가 있다고 판단하였습니다.
역순 인덱스 관련 자세한 아래 내용에서 참고 부탁드리겠습니다 :)
https://tech.kakao.com/2018/06/19/mysql-ascending-index-vs-descending-index/
😄 해결 : 역순 인덱스 적용
CREATE INDEX idx_created_by_created_at_desc ON sns_post(created_by, created_at desc);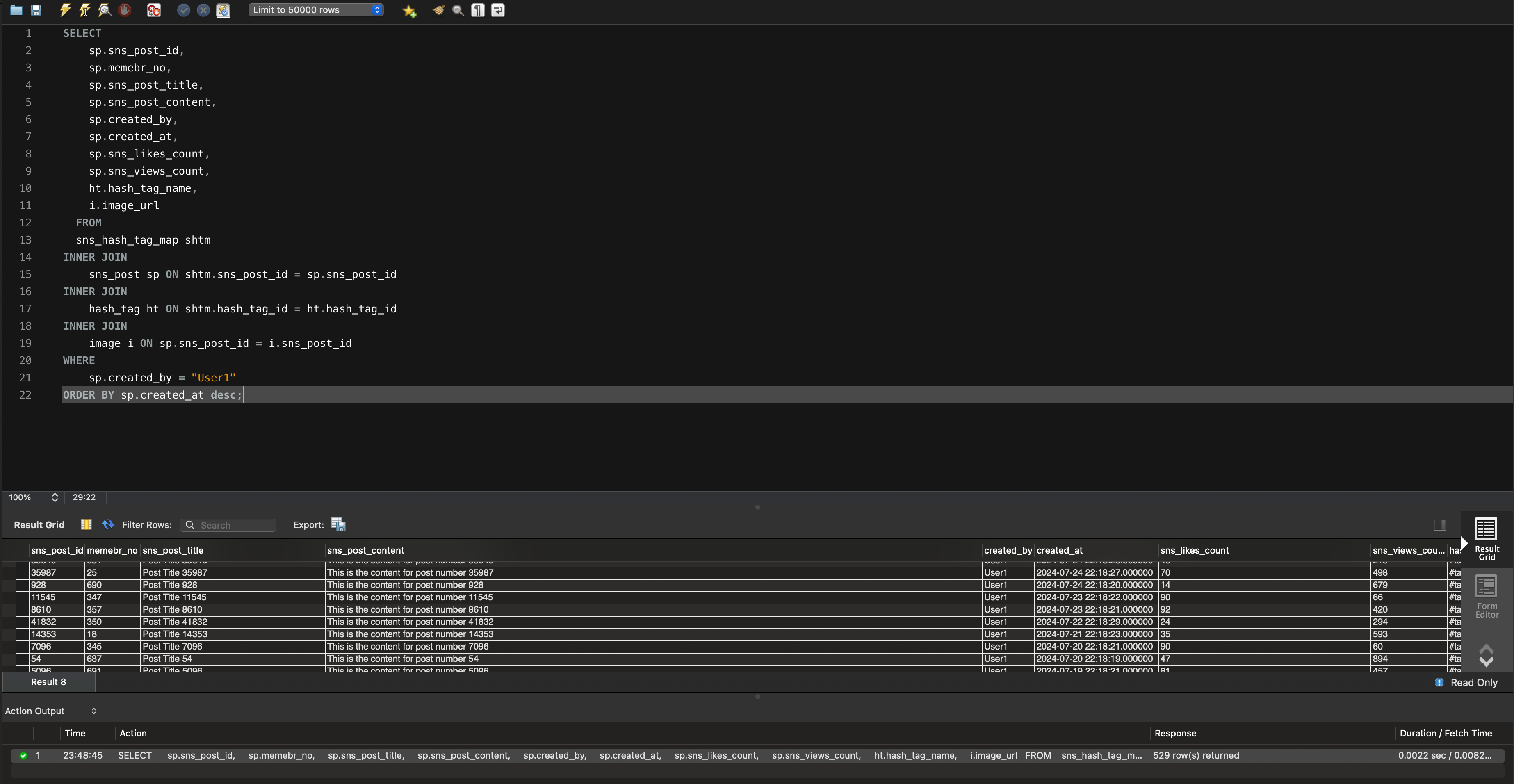
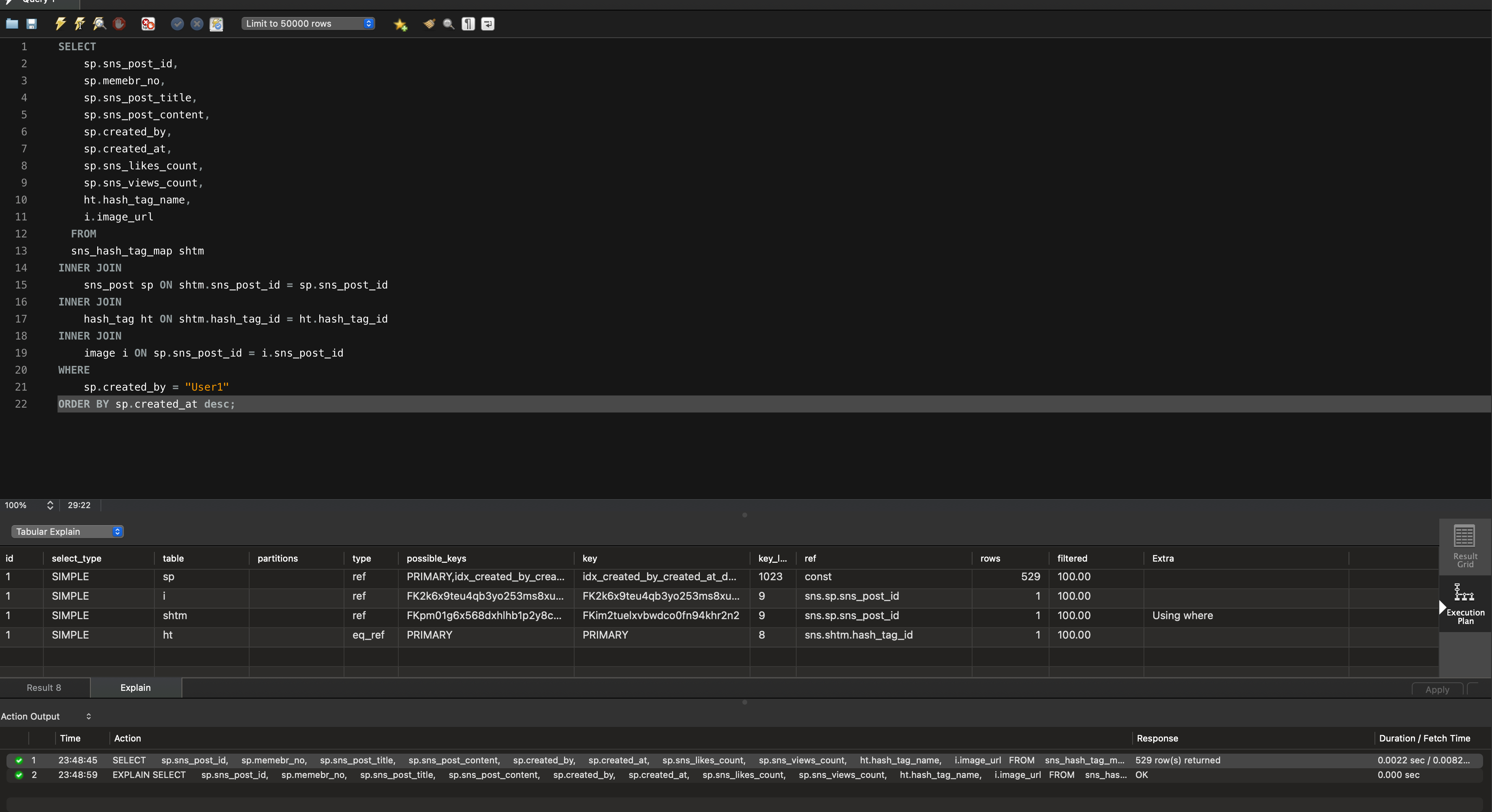
Backward index scan 없이 깔끔하게 복합 인덱스를 적용할 수 있었습니다. 또한 속도도 0.0035sec → 0.0022sec 로 약 37% 개선할 수 있었습니다.
마무리
실행 계획을 토대로 WHERE절, ORDER BY절, 그리고 조인이 포함된 복잡한 쿼리의 속도를 크게 개선할 수 있었습니다. 단순히 실행 계획을 참고하고 적절한 인덱스를 적용하는 것만으로도 약 17배의 성능 향상을 이뤄낼 수 있었습니다🙏🙏
- 쿼리를 작성할 때 기본적으로 클러스터링 인덱스를 고려해보자!
- 복잡한 쿼리의 경우, 실행 계획을 반드시 확인하고 분석하자
앞으로 쿼리 최적화 작업을 할 때는 이러한 점들을 항상 염두에 두고, 더 효율적인 데이터베이스 운영을 위해 노력해야겠습니다. 성능 개선은 단순히 속도를 높이는 것뿐만 아니라, 시스템 자원을 효율적으로 사용하고 사용자 경험을 향상시키는 중요한 과정임을 다시 한번 깨달았습니다.
오늘도 읽어주셔서 감사합니다!🙏🙏
참고
https://velog.io/@ddongh1122/MySQL-%EC%8B%A4%ED%96%89%EA%B3%84%ED%9A%8D2-EXPLAIN
https://tech.kakao.com/2018/06/19/mysql-ascending-index-vs-descending-index/
https://kukim.tistory.com/128
