
오늘 포스팅에서는 이전 포스팅에서 말씀드린대로 시스템의 가용성을 높이기 위해 카프카 클러스터를 구축해보도록 하겠습니다!
👉👉 이전 포스팅 보러가기
🤔 카프카 클러스터 왜 구축해야할까..?
이해하기 쉽게 간단한 비유로 설명해보겠습니다.
우리 동네에 우체국이 딱 하나만 있다고 생각해봅시다. 이 우체국에 무슨 일이 생기면 어떻게 될까요? 화재나 정전으로 문을 닫게 되면 모든 메시지 전달이 중단됩니다. 또한 우편물이 폭주할 때는 직원들이 과부하에 시달리겠죠.
이런 문제를 해결하기 위해 우리는 여러 개의 우체국을 만듭니다. 이것이 바로 카프카 클러스터와 같은 개념입니다.
- 한 우체국에 문제가 생겨도 다른 우체국들이 계속 운영됩니다. (고가용성)
- 우편물이 많아지면 새로운 우체국을 추가로 열 수 있습니다. (확장성)
- 중요한 편지는 여러 우체국에 복사본을 보관합니다. (데이터 내구성)
- 여러 우체국이 업무를 나눠 처리하므로 한 곳에 일이 몰리지 않습니다. (부하 분산)
이처럼 카프카 클러스터는 우리의 중요한 데이터를 안전하고 효율적으로 관리할 수 있게 해줍니다.
실습을 해보기 앞서 Kafka Replication, Leader & Follower, ISR이 뭔지 간단하게 알아보도록 하겠습니다.
🤔 Kafka Replication이란..?
Kafka에서는 높은 가용성을 위하여 Replication이란 기능을 제공합니다.
Replication은 각 Topic의 Partition들을 Kafka Cluster내의 다른 Broker들로 복제하는 것을 말하며 Topic생성 시 Replication의 수를 지정할 수 있습니다.
생성된 Replication은 Leader와 Follower로 나뉘어 ISR(In Sync Replica)이라는 일종의 Replication Group을 형성하여 관리됩니다.
🧑🏫 Leader & Follower
Kafka의 Topic은 1개 이상의 Partition으로 구성되고, 각 Partition은 1개의 leader replica와 0개 이상의 follower replica로 구성됩니다.
리더는 일종의 반장같은 역할을 합니다
예를 들어 Replication factor가 1이라면 Partition은 1개의 leader replica와 0개의 follower replica로 이루어집니다.
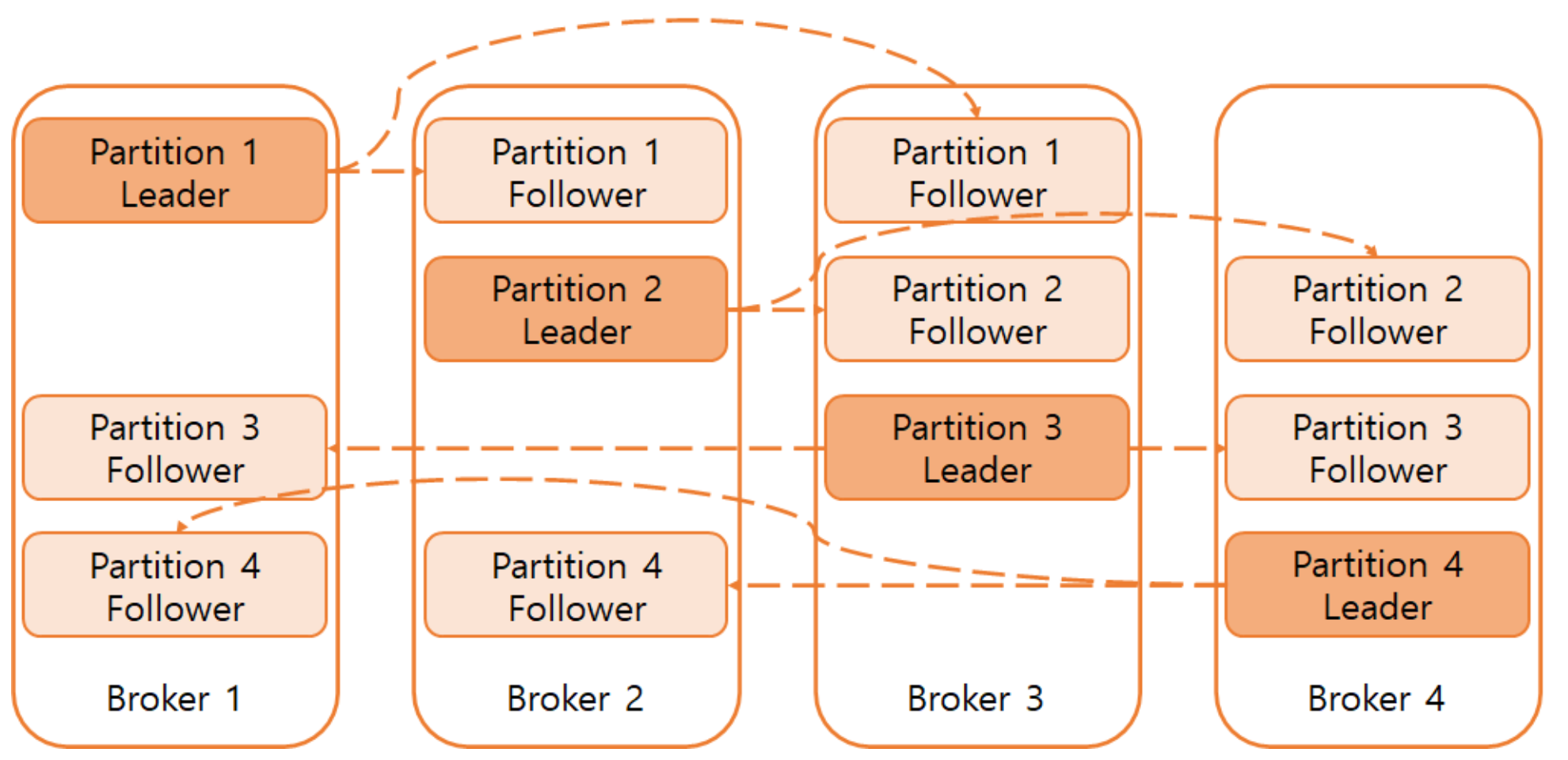
위에 사진은 Partition 4, Replication factor가 3으로 설정된 Topic입니다!
Leader replica는 일관성을 보장하기 위해 모든 Producer와 Consumer의 요청을 처리하며 데이터를 저장합니다.
Follower replica는 Leader replica의 데이터를 복제하여 동일하게 유지하다가 Leader replica가 중단되는 경우 Follower replica 중 하나가 해당 Partition의 새로운 Leader replica로 선출됩니다.
만약 기존 Leader replica에 예상치 못한 문제가 생겨 새로운 Leader replica가 선출되어야 하는 상황이 발생했을 때 제대로 데이터를 복제해 오지 못한 Follower replica가 존재한다면, 해당 개체를 제외한 나머지 Follower replica 중에서 Leader replica를 선출해야 할 것입니다. 이를 위해서 Kafka에서는 ISR(In Sync Replica)이라는 개념을 도입했습니다.
ISR(In Sync Replica)
ISR(In Sync Replica)이란 일종의 Replication group이라 생각하시면 됩니다.
ISR : 같은 반, 리더 : 반장
이 Group은 Leader replica와 제대로 동기화가 이루어진 Follower replica들로 구성됩니다.
- 여기서 ISR의 핵심은 동기화가 이루어진 Follower replica로 구성된다는게 핵심입니다!
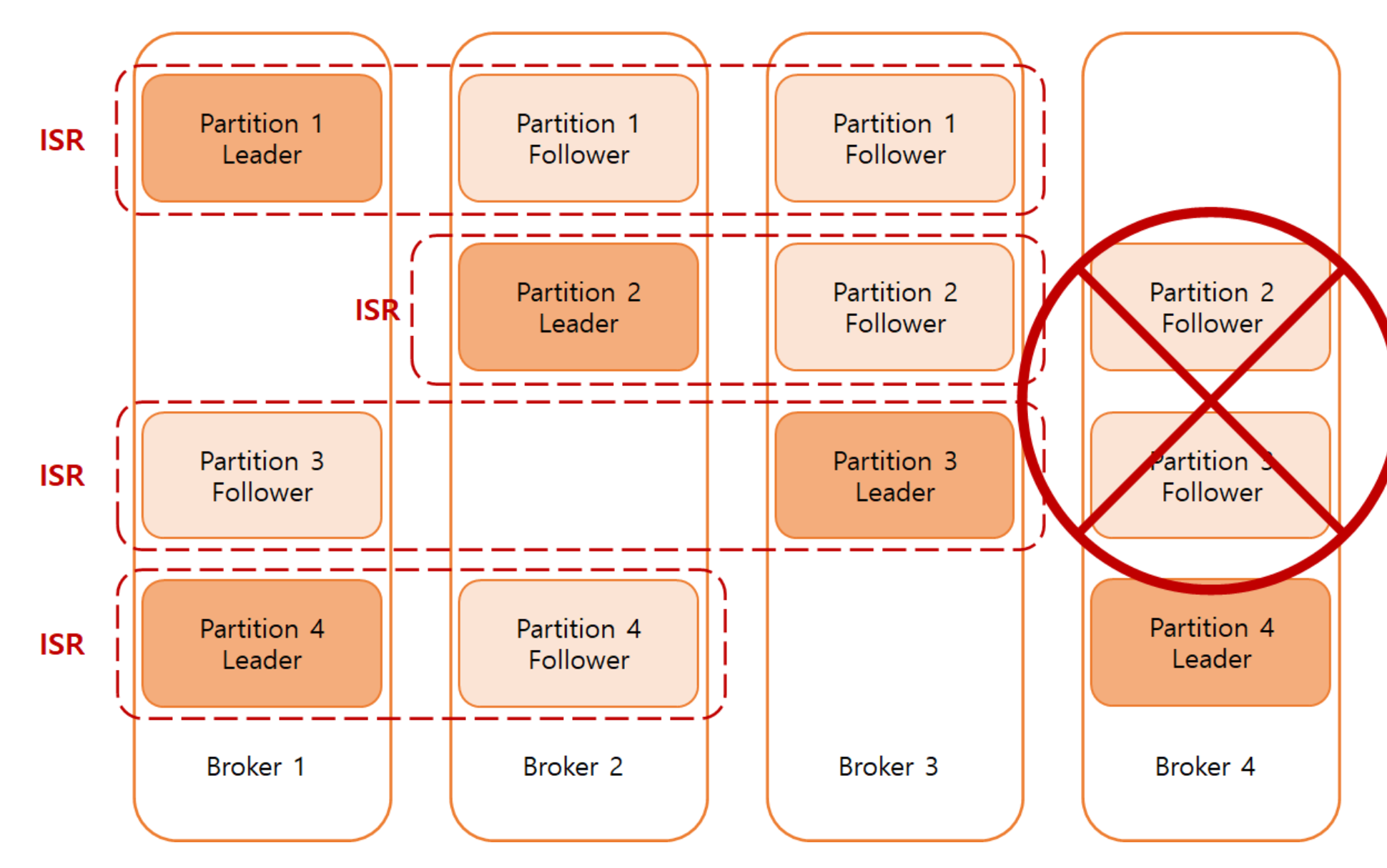
Leader가 중단되는 경우에 대비해서 ISR에 속해있는 Follower 중 하나가 Leader로 선출됩니다.
Follower가 일정 시간 이상 Fetch 요청을 하지 않거나, 요청은 했지만 시간 안에 Leader의 마지막 Offset의 메시지를 복제하지 못한다면 동기화에 실패한 것으로 간주하여 Leader는 해당 Follower를 ISR에서 제거합니다.
📌 카프카 클러스터 구축 실습!(+멱등성 프로듀서 설정)
🎤 1. 구축 환경
- EC2 인스턴스 서버 3대
- Docker
- Kafka 브로커 3개
- Zookeeper 인스턴스 3개
🔎 2. 사전 준비
2.1 Docker 설치
각 EC2 인스턴스에 Docker를 설치합니다. (생략)
2.2 Docker Compose 설치
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose설치 확인
docker-compose --version📜 3. docker-compose.yml 파일 작성
각 EC2 인스턴스에 다음과 같은 docker-compose.yml 파일을 브로커의 갯수만큼 생성합니다.
❌ 단, 각 인스턴스마다 ZOO_MY_ID와 KAFKA_BROKER_ID를 다르게 설정해야 합니다!!!
version: '3'
networks:
[docker network 이름]:
external: true
name: [docker network 이름]
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
networks:
- [docker network 이름]
environment:
ZOO_MY_ID: 1 # 각 서버마다 1, 2, 3으로 변경
ZOO_SERVERS: server.1=[주키퍼1_IP]:2888:3888 server.2=[주키퍼2_IP]:2888:3888 server.3=[주키퍼3_IP]:2888:3888
kafka:
image: wurstmeister/kafka
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://[카프카1_IP]:9092
KAFKA_LISTENERS: PLAINTEXT://:9092
KAFKA_ZOOKEEPER_CONNECT: [주키퍼1_IP]:2181,[주키퍼2_IP]:2181,[주키퍼3_IP]:2181
KAFKA_BROKER_ID: 1 # 각 서버마다 1, 2, 3으로 변경
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3
KAFKA_DEFAULT_REPLICATION_FACTOR: 3
KAFKA_MIN_INSYNC_REPLICAS: 2
volumes:
- /var/run/docker.sock:/var/run/docker.sock
depends_on:
- zookeeper
networks:
- [docker network 이름]1️⃣ 3-1. 멱등성 프로듀서 설정
우선 저는 데이터를 여러 번 전송하더라도 해당 데이터가 카프카 클러스터에 단 한 번만 저장되도록 보장하기 위해 멱등성 프로듀서를 설정했었습니다.
.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true)이 설정(enable.idempotence=true)은 자동으로 몇 가지 프로듀서 옵션을 조정합니다:
retries: 기본값인 Integer.MAX_VALUE로 설정됩니다.acks: 'all'로 설정됩니다.
acks=all 설정의 의미
acks=all은 프로듀서가 메시지를 보낼 때, 리더와 모든 ISR(In-Sync Replicas) 팔로워들이 메시지를 받았는지 확인합니다. 이는 메시지 전달에 시간이 더 걸릴 수 있지만, 최고 수준의 안정성을 제공합니다.
2️⃣ 3-2. acks=all 일 때 min.insync.replicas=2로 설정해야 하는 이유는 무엇일까?
min.insync.replicas는 메시지가 성공적으로 전송되었다고 간주하기 위해 필요한 최소 동기화 복제본 수를 지정합니다.
min.insync.replicas=2로 설정해야 하는 주요 이유:
- 데이터 안정성 보장: 최소 2개의 복제본이 동기화되어야 메시지가 성공적으로 처리된 것으로 간주됩니다. 이는 데이터 손실 위험을 크게 줄입니다.
- 시스템 가용성 유지: 3개의 브로커 중 1개가 실패해도 시스템이 계속 작동할 수 있습니다. 이는 고가용성을 보장합니다.
- 과도한 제약 방지:
min.insync.replicas=3으로 설정하면 1개의 브로커 실패만으로도 전체 시스템이 중단될 수 있어, 오히려 안정성이 떨어질 수 있습니다. - 성능과 안정성의 균형: 이 설정은 높은 처리량을 유지하면서도 충분한 데이터 안정성을 제공합니다.
이러한 이유들 때문에 아파치 카프카 문서에서는 손실 없는 메세지 전송을 위한 조건으로 프로듀서는 acks=all, 브로커의 min.insync.replicas=2, Topic의 Replication Factor는 3으로 권장하고 있습니다.
📌 4. 토픽 replication 테스트
카프카 클러스터를 구축한 후에 ISR 그룹내에서 토픽이 잘 복제되는지 확인해보도록 하겠습니다
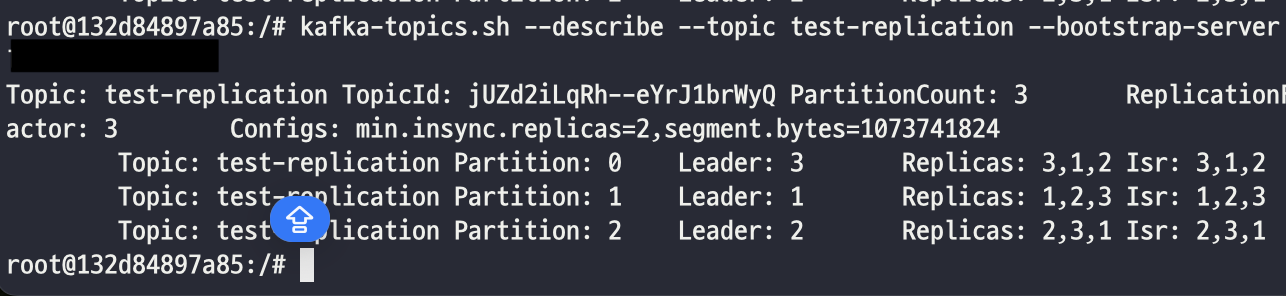
kafka-topics.sh --create --topic test-replication --partitions 3 --replication-factor 3 --bootstrap-server [kafka ip 주소]'test-replication'이라는 이름의 토픽을 3개의 파티션과 3의 복제 팩터로 생성합니다.
kafka-topics.sh --describe --topic test-replication --bootstrap-server
[kafka ip 주소]
# 토픽 정보 상세 보기위에 커맨드를 입력해서 특정 topic의 partition과 replica에 대한 상세 정보를 확인해보면
성공적으로 카프카 클러스터에 토픽이 복제된것을 확인할 수 있습니다!
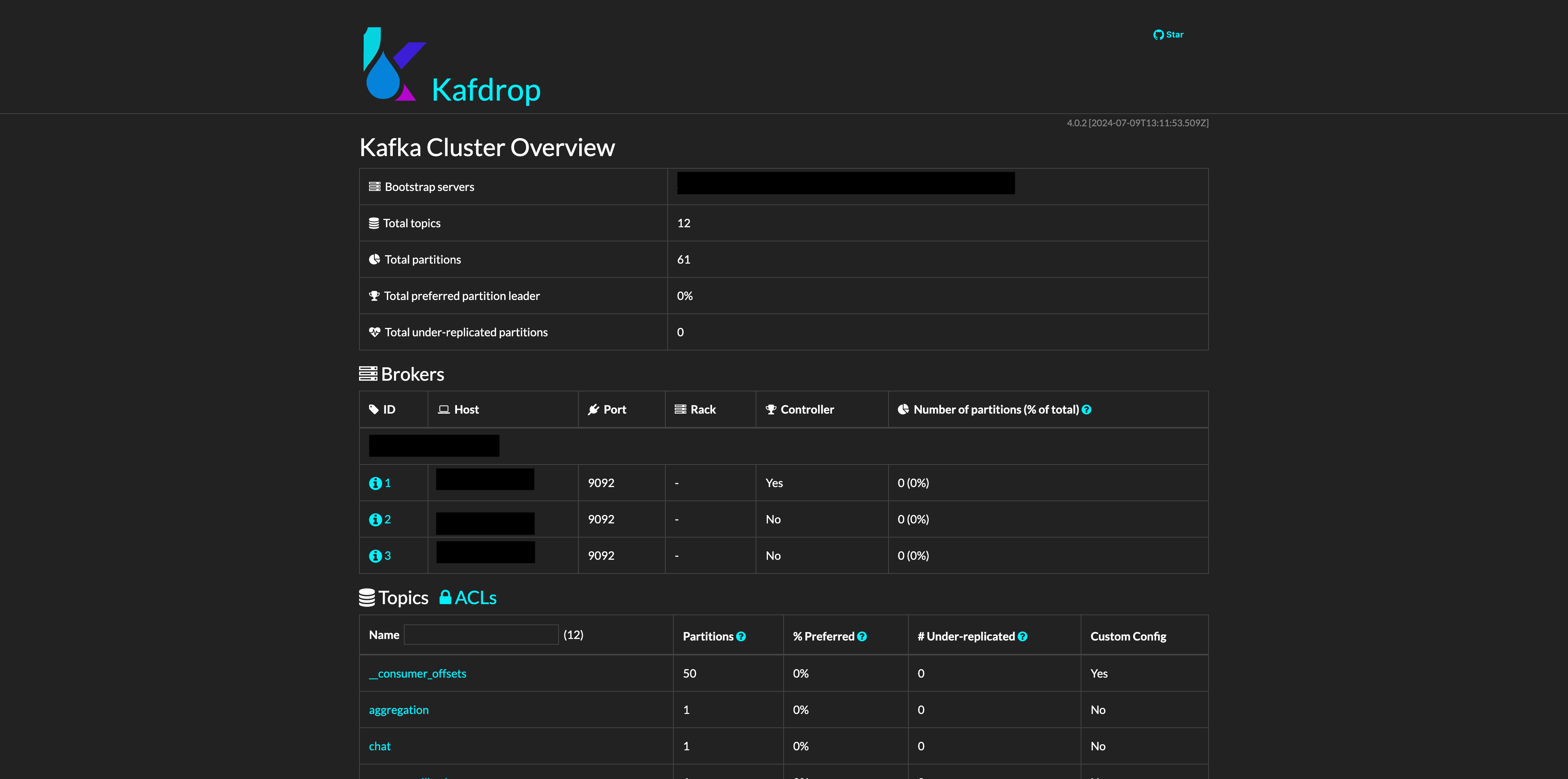
💻 5. 클러스터 구축 후 kafdrop UI 확인
👉 다음으로
시스템의 신뢰성과 가용성을 높이기 위해 kafka cluster를 구축하는 과정에 대해 정리해봤습니다.
하지만 여전히 MSA환경에서의 데이터 일관성 문제가 남아있습니다. 다음 포스팅에서는 이 문제를 해결하기 위한 방법으로 Kafka connect의 소스 커넥터를 활용한 CDC와 Transactional Outbox Pattern을 적용한 사례를 다뤄보도록 하겠습니다.
참고
https://devlog-wjdrbs96.tistory.com/436
https://velog.io/@bbkyoo/Apache-Kafka-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-%EA%B5%AC%EC%B6%95%ED%95%98%EA%B8%B0
https://damdam-kim.tistory.com/17
