이분 탐색 / 이진 탐색 (Binary Search)
-
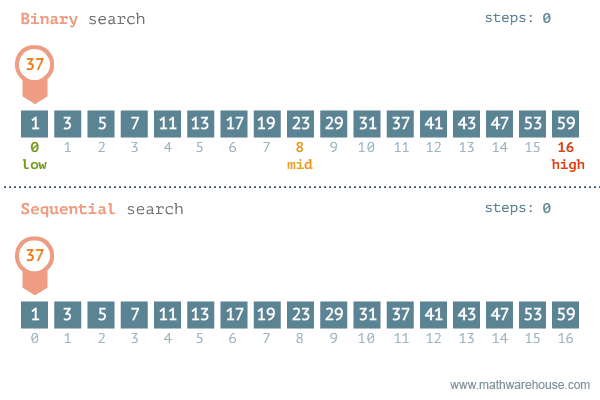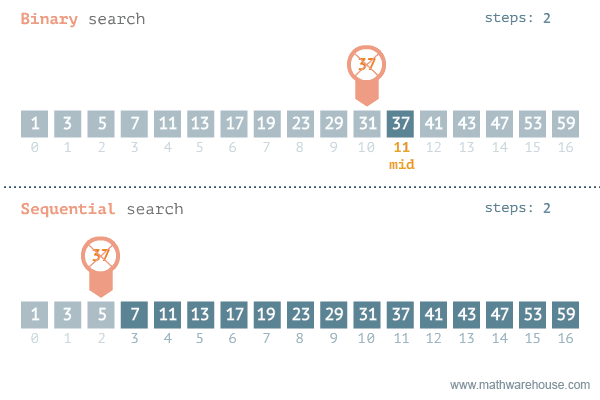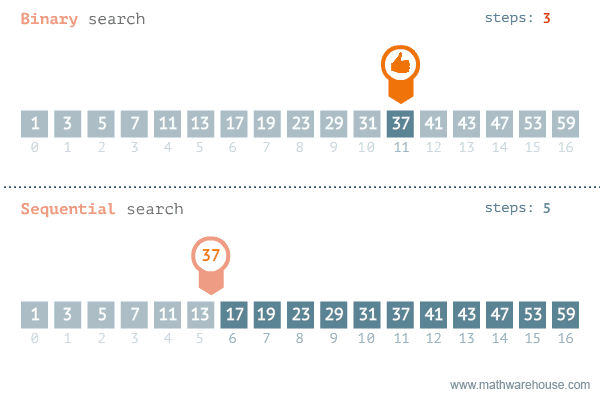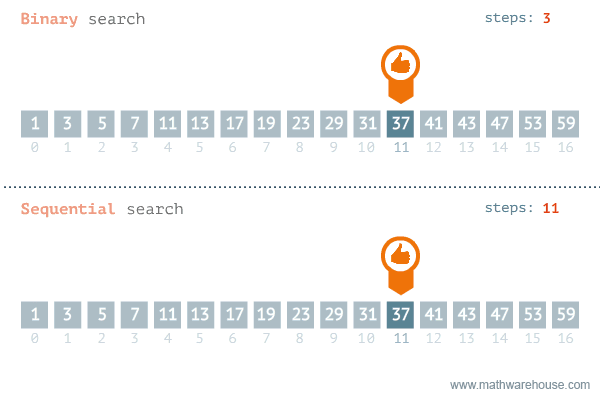
이진 탐색(이분 탐색)알고리즘은 정렬되어 있는 리스트에서 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하는 방법이다. (정렬이 돼있어야 가능) -
이진 탐색은 배열 내부의 데이터가 정렬되어 있어야만 사용할 수 있는 알고리즘이다.
-
변수 3개(start, end, mid)를 사용하여 탐색한다. 찾으려는 데이터와 중간점 위치에 있는 데이터를 반복적으로 비교해서 원하는 데이터를 찾는 것이 이진 탐색의 과정이다.
이진 탐색 / 이분 탐색 알고리즘 코드 (Python)
# 반복문으로 구현한 이진 탐색
def binary_search(array, target, start, end):
while start <= end:
mid = (start + end) // 2
# 원하는 값 찾은 경우 인덱스 반환
if array[mid] == target:
return mid
# 원하는 값이 중간점의 값보다 작은 경우 왼쪽 부분(절반의 왼쪽 부분) 확인
elif array[mid] > target:
end = mid - 1
# 원하는 값이 중간점의 값보다 큰 경우 오른쪽 부분(절반의 오른쪽 부분) 확인
else:
start = mid + 1
return None
n, target = list(map(int, input().split()))
array = list(map(int, input().split()))
result = binary_search(array, target, 0, n - 1)
if result is None:
print('원소가 존재 X')
else:
print(result + 1)
>>> 4
# sample input
# 10 7
# 1 3 5 7 9 11 13 15 17 19- 시간 복잡도는
O(logN)이다. - 단계마다 탐색 범위를 반으로(÷2) 나누는 것과 동일하므로 위 시간 복잡도를 가지게 된다.
- 예를 들어 처음 데이터의 개수가 32개라면, 이론적으로 1단계를 거치면 약 16개의 데이터가 남고, 2단계에서 약 8개, 3단계에서 약 4개의 데이터만 남게 된다.
- 즉, 이진 탐색(이분 탐색)은 탐색 범위를 절반씩 줄이고, O(logN)의 시간 복잡도를 보장한다.
Python 이진 탐색 라이브러리
Python에서는 bisect라는 이진 탐색 라이브러리(모듈)을 지원한다! 예제를 통해 알아보도록 하자.
-
bisect_left(a, x)--> 정렬된 순서를 유지하면서 리스트 a에 데이터 x를 삽입할 가장 왼쪽 인덱스를 찾는 메소드 -
bisect_right(a, x)--> 정렬된 순서를 유지하도록 리스트 a에 데이터 x를 삽입할 가장 오른쪽 인덱스를 찾는 메소드
from bisect import bisect_left, bisect_right
a = [1, 2, 4, 4, 8]
x = 4
print(bisect_left(a, x))
>>> 2
# 리스트 a에 4를 삽입할 가장 왼쪽 인덱스는 2이다.
print(bisect_right(a, x))
>>> 4
# 리스트 a에 4를 삽입할 가장 오른쪽 인덱스는 4이다.참고
투 포인터 알고리즘이란?
포인터가 C언어에서의 포인터가 아니다. 정말 말그대로 가리키는 두 개의 포인터라고 생각하면 된다.
이름처럼양 끝을 각각 포인터로 설정한 다음, 포인터의 위치를 안쪽으로 옮기며 주어진 연산을 반복해 최적값을 찾아내는 방식이다.
투포인터 알고리즘의 장점은 리스트를 한 번만 순환하기 때문에 빠르다. 시간복잡도가 O(n), 최악의 경우 O(nlogn)이다.
이중 for문의 시간복잡도 O(n^2) 보다는 빠르지만 이진 탐색에 비하면 느리다
ex)예를 들어 N개의 자연수로 이루어진 수열이 주어졌을 때, 이 수열에서 연속되는 부분 수열 중 합이 S가 되는 부분 수열의 개수를 구할때 사용(부분의 합이 구하고자 하는 s보다 작을 때 end 증가, 크거나 같다면 start 증가)
이진 탐색과 투 포인터 알고리즘의 차이점
이진 탐색은 mid = (start + end)//2를 target 값과 비교해 start 혹은 end를 mid 전후로 위치를 변경시켜가며 target이 위치할 수 있는 인덱스를 반환하는 형태의 탐색이다.
start, end가 움직이는 범위는 mid의 크기에 따라 최대 N//2 + 1만큼 움직이다. 한 번 연산할 때마다 데이터 양이 최대 절반씩 줄어들기 때문에 시간 복잡도는 O(logN)이다.
반면, 투포인터에서는 start와 end를 양 끝으로 설정하는 것까지는 같으나
start와 end가 움직이는 범위는 한 번의 연산 당 +1/-1만큼이다. 한 칸씩 계속해서 start 혹은 end 범위를 가운데로 좁혀가며 start와 end 사이 연산값을 저장해놓은 뒤, 그보다 최소 혹은 최대의 start+end값을 만나면 그 값으로 바꾸는 식으로 최대 혹은 최소를 찾는 방식이다. 최악의 경우 모든 원소를 다 스캔해야하며 일반적으로 O(N)이다.
핵심
1. mid만큼 이동하냐(이진탐색) VS 양 끝단에 한 칸씩 이동하냐(투포인터)
2. 이진탐색 => 리스트 정렬되어있음을 가정하고 시작 VS 투포인터 => 모든 원소를 다 스캔하면서 최적의 값이 나타나면 해당 값을 저장하는 방식이기에 정렬되어있지 않아도 됨 (But, 더 빠른 연산을 위해 정렬할 수 있음)
| 이진 탐색 | 투 포인터 | |
|---|---|---|
| 시간복잡도 | O(logN) | O(N) |
| 가정 | 데이터가 정렬되어있어야 함 | it's okay |
| 방식 | mid를 활용, 매 연산마다 탐색하는 범위를 절반으로 좁혀 나감 | 양 끝단에서 한 칸씩 이동하면서 알맞은 값을 찾음 |
참고 코드(투 포인터)
import sys
n = int(sys.stdin.readline().rstrip())
seq = sorted(list(map(int, sys.stdin.readline().split())))
x = int(sys.stdin.readline().rstrip())
def solution(target, n, x):
start = 0
end = n-1
count = 0
while start < end:
value = target[start] + target[end]
# 정렬되어있기 때문에 end쪽 값이 더 크니 줄여줌으로써 value 값이 더 작아지도록
if value > x:
end -= 1
# 정렬되어있기 때문에 start쪽 값이 더 작으니 늘려줌으로써 value 값이 더 커지도록
elif value < x:
start += 1
# 만약 value == x 이면 쌍의 개수를 카운트하고, 투 포인터를 안쪽으로 옮겨주면 된다.
else:
count += 1
start += 1
end -= 1
return count
참고 블로그
https://bo5mi.tistory.com/140
https://github.com/gyoogle/tech-interview-for-developer/blob/master/Algorithm/Binary%20Search.md
