목차
Binary Search Tree
이진탐색트리의 목적은?
> 이진탐색 + 연결리스트이진탐색 : 탐색에 소요되는 시간복잡도는 O(logN), but 삽입,삭제가 불가능
연결리스트 : 삽입, 삭제의 시간복잡도는 O(1), but 탐색하는 시간복잡도가 O(N)
이 두가지를 합하여 장점을 모두 얻는 것이 '이진탐색트리'
즉, 효율적인 탐색 능력을 가지고, 자료의 삽입 삭제도 가능하게 만들자
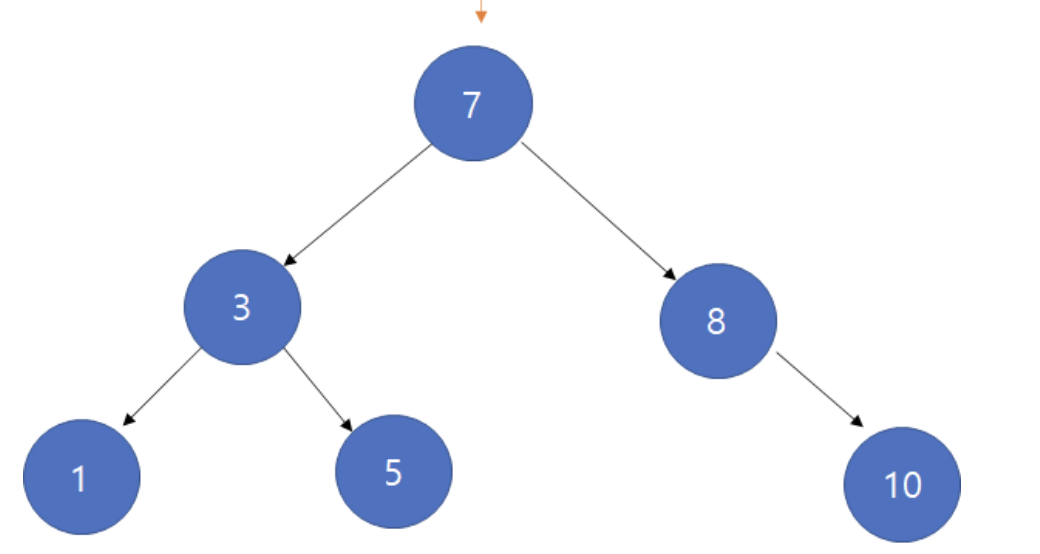
특징
- 각 노드의 자식이
2개 이하(1개도 상관없음) - 각 노드의 왼쪽 자식은 부모보다 작고, 오른쪽 자식은 부모보다 큼
- 중복된 노드가 없어야 함
📕 중복이 없어야 하는 이유는 뭘까?
검색 목적 자료구조인데, 굳이 중복이 많은 경우에 트리를 사용하여 검색 속도를 느리게 할 필요가 없음. (트리에 삽입하는 것보다, 노드에 count 값을 가지게 하여 처리하는 것이 훨씬 효율적
이진 탐색트리 검색
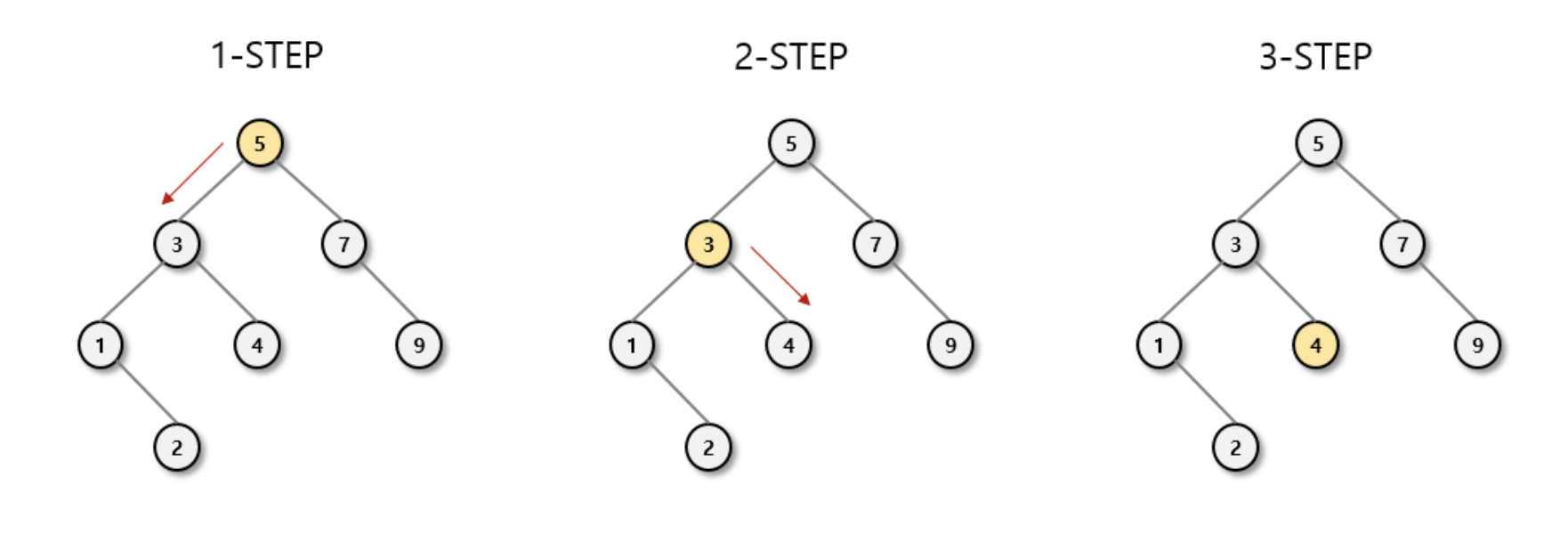
예시의 이진 탐색트리 에서 4 노드를 검색한다고 가정해봅시다.
- 첫번째로 만나는 노드는
5입니다. 검색노드가5보다 작으므로, 왼쪽으로 이동합니다. - 두번째로 만나는 노드는
3입니다. 검색노드가3보다 크므로, 오른쪽으로 이동합니다. - 세번째로 만나는 노드는
4입니다. 검색노드와 일치 하므로 해당 노드를 리턴 합니다.
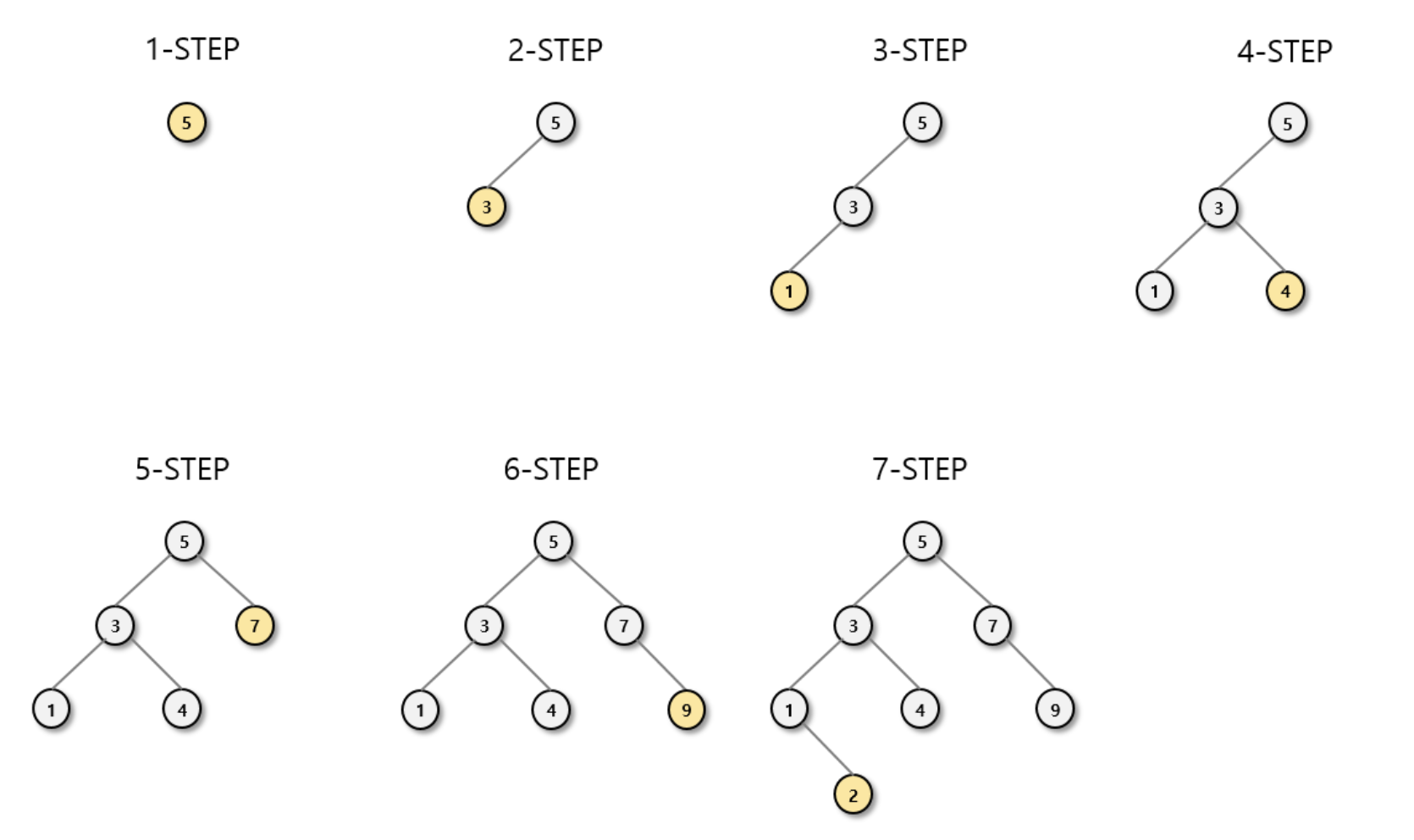
이진 탐색트리 삽입
이진 탐색트리에 노드를 넣는 순서는 다음과 같다고 가정합니다.
5, 3, 1, 4, 7, 9, 2
위에서 설명한 규칙대로 삽입과정을 거칩니다. 검색과 마찬가지로 이동하며, 자리를 찾아 노드를 저장합니다.
이진 탐색트리 삭제
이진 탐색트리의 검색/삽입 연산과 달리 삭제는 조금 복잡합니다.
고려해야 할 케이스를 3개로 나눌 수 있습니다.
- 삭제할 노드가 말단 노드인 경우(자식노드가 없는 경우)
- 삭제할 노드의 자식 노드가 1개인 경우
- 삭제할 노드의 자식 노드가 2개인 경우
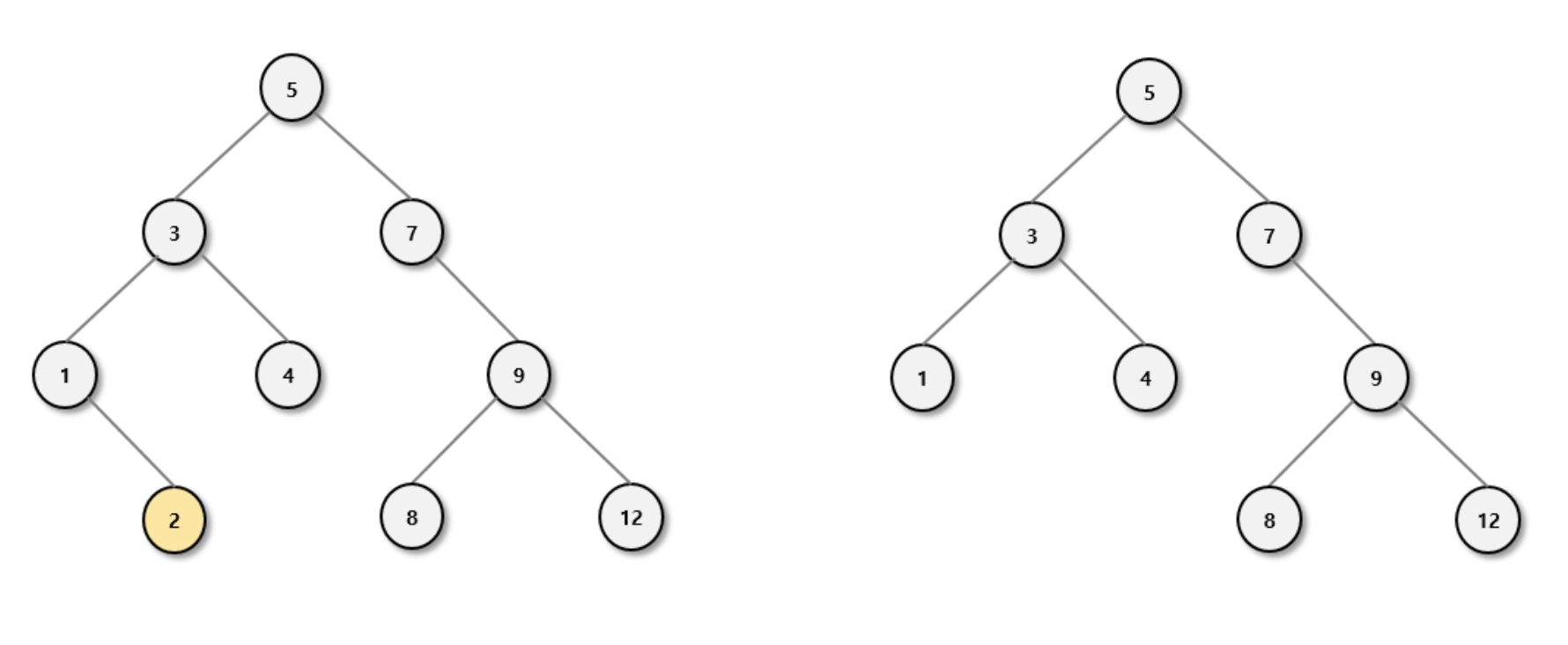
삭제할 노드가 말단 노드인 경우
해당 경우는 간단합니다. 삭제할 노드만 삭제해주면 됩니다.아래의 예시는 2 노드를 지웁니다.
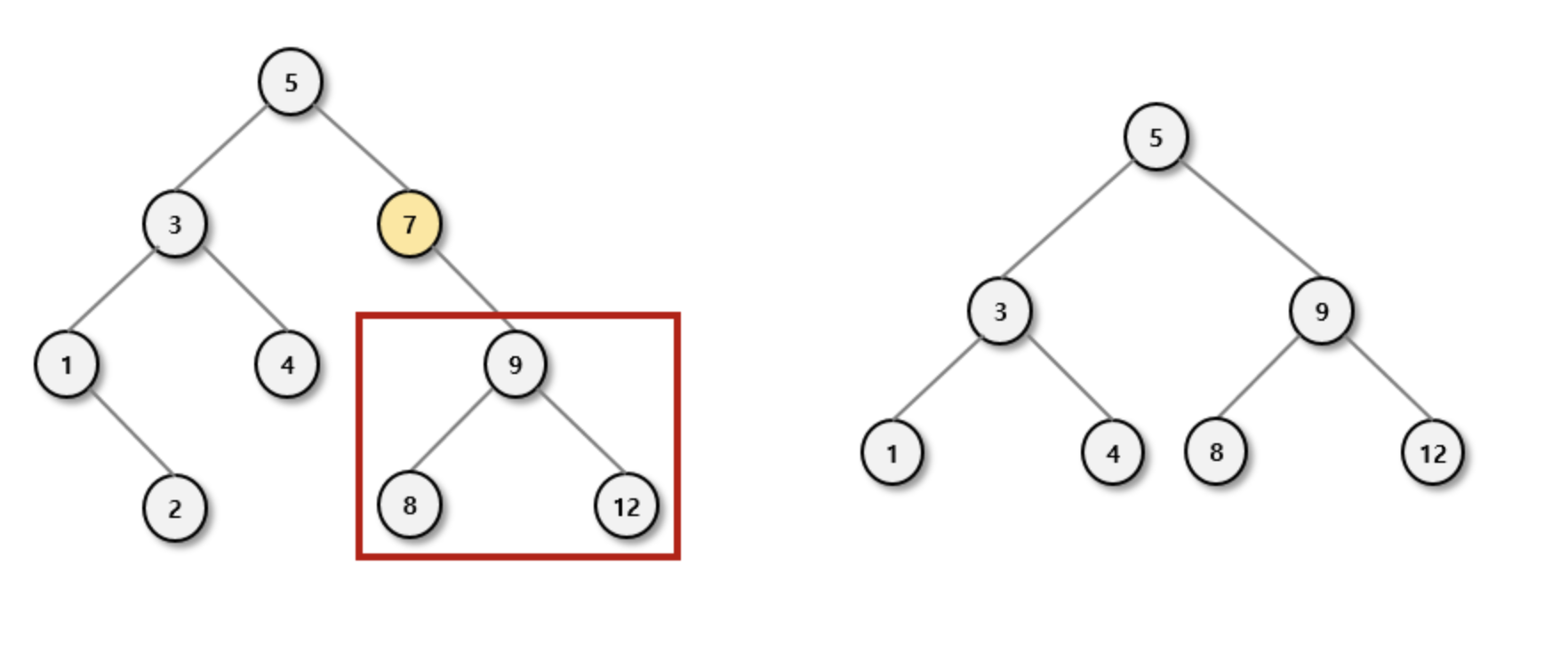
삭제할 노드의 자식 노드 1개인 경우
이 경우도 어렵지 않습니다. 삭제할 노드의 자식들의 트리 구조 규칙은
삭제할 노드의 조상으로 부모를 바꾸더라도 규칙이 깨지지 않기 때문입니다.
아래의 예시는 7 노드를 지웁니다.
삭제할 노드의 자식 노드가 2개인 경우
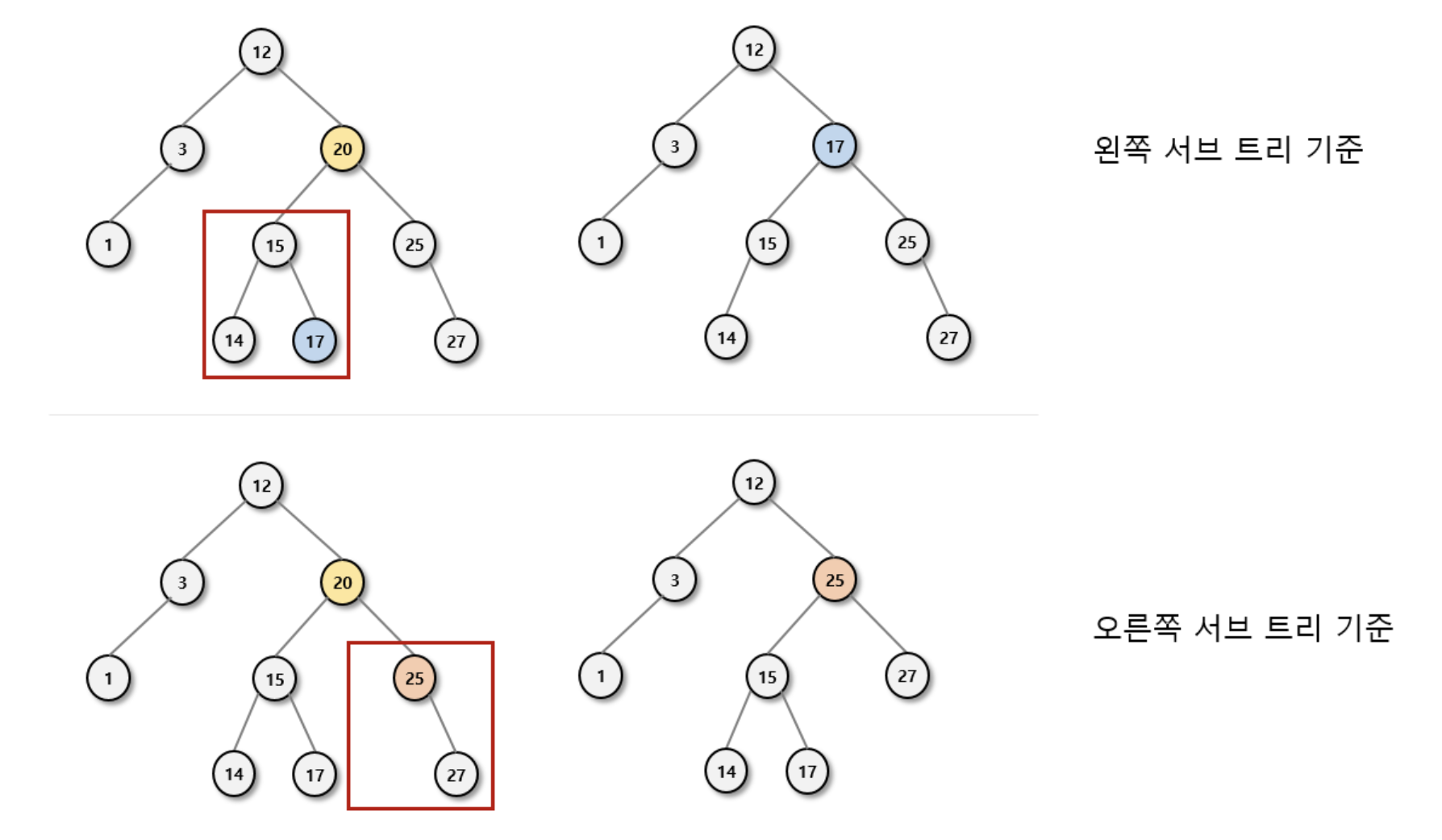
이 경우가 살짝 복잡합니다. 삭제할 노드의 자리에 대신 채울 노드를 찾아야 하는 과정이 필요합니다.
대신 채울 노드를 찾는 방법은 2가지 존재합니다.
- 삭제할 노드의
왼쪽 서브 트리에서최대 값 노드 - 삭제할 노드의
오른쪽 서브 트리에서최소 값 노드
아래의 예시는 20 노드를 삭제할 때, 서브 트리에서 위 방법으로, 노드를 찾아 대체합니다.
이진 탐색트리 시간 복잡도
균등 트리 : 노드 개수가 N개일 때 O(logN)
편향 트리 : 노드 개수가 N개일 때 O(N)
삽입, 검색, 삭제 시간복잡도는 트리의 Depth에 비례
Hash
Hash란?
-
데이터를 효율적으로 관리하기 위해, 임의의 길이 데이터를 고정된 길이의 데이터로 매핑하는 것
-
해시 함수를 구현하여 데이터 값을 해시 값으로 매핑한다.
(Key, Value)로 데이터를 저장하는 자료구조 중 하나로 빠르게 데이터를 검색할 수 있는 자료구조이다. 해시 테이블이 빠른 검색속도를 제공하는 이유는 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문이다.각 Key값은 해시함수에 의해 고유한 index를 가지게 되어 바로 접근할 수 있으므로 평균 O(1)의 시간 복잡도로 데이터를 조회합니다.
해시 테이블은 각각의 Key값에 해시함수를 적용해 배열의 고유한 index를 생성하고, 이 index를 활용해 값을 저장하거나 검색하게 된다. 여기서 실제 값이 저장되는 장소를버킷또는슬롯이라고 한다.
Lee → 해싱함수 → 5
Kim → 해싱함수 → 3
Park → 해싱함수 → 2
Chun → 해싱함수 → 5 // Lee와 해싱값 충돌결국 데이터가 많아지면, 다른 데이터가 같은 해시 값으로 충돌나는 현상이 발생함 'collision'(충돌) 현상
그래도 해시 테이블을 쓰는 이유는?
- 적은 자원으로 많은 데이터를 효율적으로 관리하기 위해
- 하드디스크나, 클라우드에 존재하는 무한한 데이터들을 유한한 개수의 해시값으로 매핑하면 작은 메모리로도 프로세스 관리가 가능해짐!
-
언제나 동일한 해시값 리턴,
index를 알면빠른 데이터검색이 가능해짐 -
해시테이블의 시간복잡도 O(1) - (이진탐색트리는 O(logN))
충돌 문제 해결
💡 체이닝 : 연결리스트로 노드를 계속 추가해나가는 방식 (제한 없이 계속 연결 가능, but 메모리 문제)
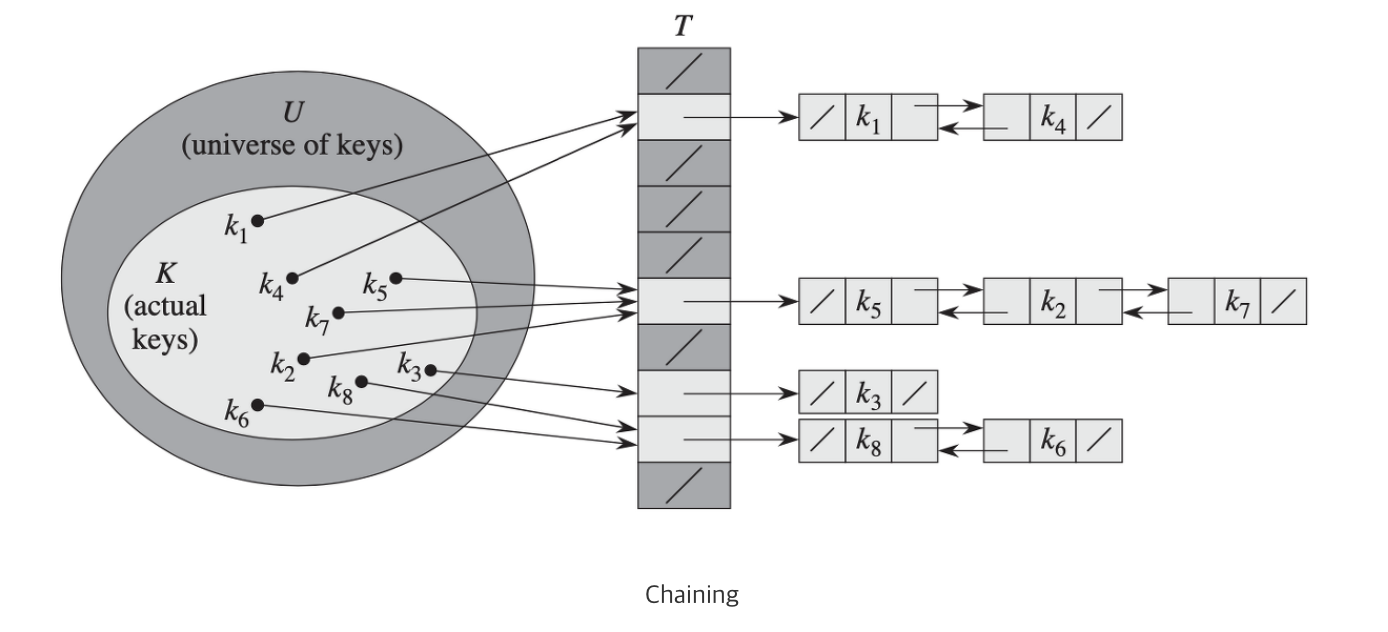
중복된 해시 값이 있는 경우, 해당 슬롯을 연결 리스트로 저장한다. 이 방법은 연결 리스트로 인해 최악의 경우 수행 시간이 O(n)이 된다. 해시를 사용하는 이유는 O(1)이라는 장점으로 사용하는 것인데 O(n)이 된다면 문제가 된다. 이런 문제로 트리로 구성하여 더 시간 복잡도를 줄일 수도 있다.
💡 Open Addressing : 충돌 발생 시 해시함수로 얻은 주소가 아닌 다른 주소 공간에 데이터를 저장한다.
오픈 어드레싱은 충돌을 피하기 위한 다른 방법으로 key를 해시 테이블에 직접 저장한다. 오픈 어드레싱의 장점은 포인터를 사용하지 않아도 되어 구현이 간편하며, 검색도 미세하게 빨라진다.
오픈 어드레싱은 총 3가지 종류가 있다. 각 종류의 특징을 알아보도록 하자
1. 선형 프로빙(Linear probing) : 정해진 고정 폭으로 옮겨 해시값의 중복을 피함
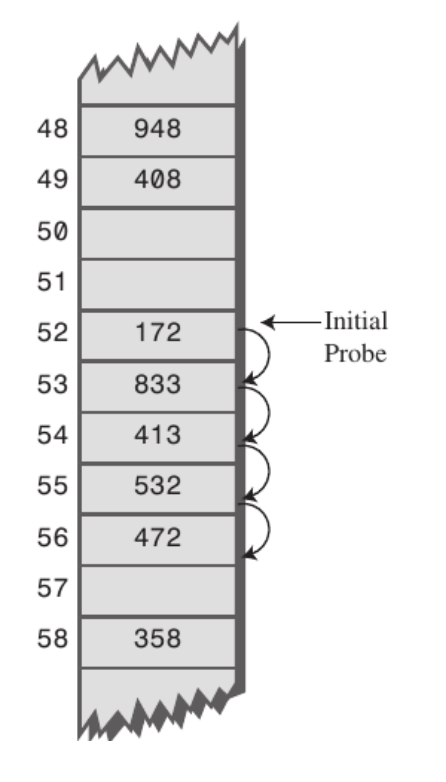
선형 프로빙은 충돌이 발생할 경우 빈 slot이 나올 때까지 탐색 후, 빈 slot이 나오면 위치가 결정된다. 선형 프로빙은 아래와 같은 해시 함수가 사용된다. 여기서 k는 키, i는 충돌 횟수, h()는 해시 함수, m은 해시 테이블 크기를 의미한다.
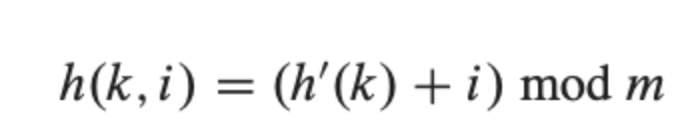
📌 장단점
선형 프로빙의 장점은 구현은 매우 쉬우나 primary clustering 문제가 있다. primary clustering는 한 번 충돌이 나면 집중적으로 충돌이 발생하는 것을 의미한다. 이로 인하여 평균 검색 시간이 증가한다
2. 이차식 프로빙,제곱 탐사(Quadratic probing) : 정해진 고정 폭을 제곱수로 옮겨 해시값의 중복을 피함
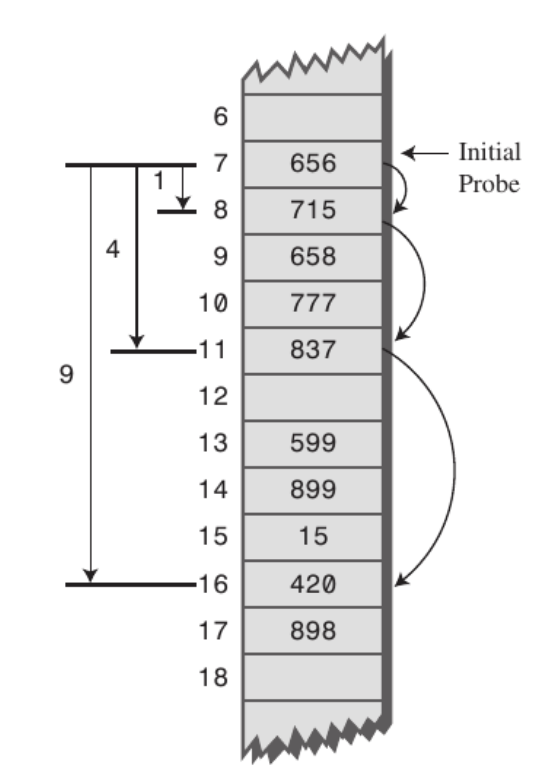
임의의 키값에 해당하는 데이터에 액세스할 때 충돌이 일어나면 칸을 옮깁니다. 여기에서도 충돌이 일어나면 이번엔 칸, 그 다음엔 칸 옮기는 식입니다.
이차식 프로빙은 아래와 같은 해시 함수를 사용한다. i에 대한 2차 함수 꼴로 slot를 이동하면서 빈 slot를 찾는다.
h: 보조 해시 함수
c1, c2: 0이 아닌 상수
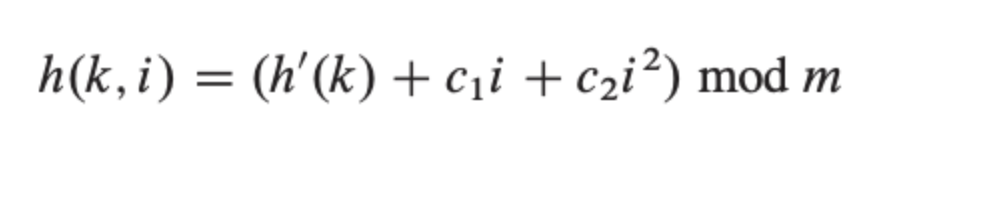
📌 장단점
이차식 프로빙은 선형 프로빙에 비해 충돌이 적지만 secondary clustering이 발생한다. secondary clustering은 처음 충돌한 위치가 같다면 다음 충돌할 위치도 반복적으로 계속 충돌이 나게 된다는 의미이다.
제곱탐사는 여러 개의 서로 다른 키들이 동일한 초기 해시값(아래에서 initial probe)을 갖는 secondary clustering에 취약하다고 합니다. 초기 해시값이 같으면 다음 탐사 위치 또한 동일하기 때문에 효율성이 떨어집니다. 예컨대 아래 그림에서 초기 해시값이 7인 데이터를 삽입해야 할 경우 선형 탐사 기법보다 성큼성큼 이동하더라도 탐사를 네 번 수행하고 나서야 비로소 데이터를 저장할 수 있습니다.
3. 이중 해시(Double hasing)
탐사할 해시값의 규칙성을 없애버려서 clustering을 방지하는 기법입니다. 2개의 해시함수를 준비해서 하나는 최초의 해시값을 얻을 때, 또 다른 하나는 해시충돌이 일어났을 때 탐사 이동폭을 얻기 위해 사용합니다. 이렇게 되면 최초 해시값이 같더라도 탐사 이동폭이 달라지고, 탐사 이동폭이 같더라도 최초 해시값이 달라져 primary, secondary clustering 을 모두 완화할 수 있습니다.
이중 해시는 다음과 같은 형태의 해시 함수를 사용한다. 충돌이 없을 때는 h1으로 위치를 탐색하고, 충돌이 있으면 h2 mod m 만큼 이동하면서 탐색한다.
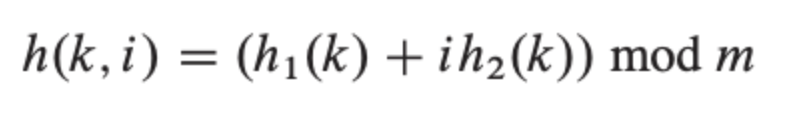
해시 버킷 동적 확장
해시 버킷의 크기가 충분히 크다면 해시 충돌 빈도를 낮출 수 있다.
하지만 메모리는 한정된 자원이기 때문에 무작정 큰 공간을 할당해 줄 수 없다
때문에 load factor가 일정 수준 이상 이라면 (보편적으로는 0.7 ~ 0.8) 해시 버킷의 크기를 확장하는 동적 확장 방식을 사용한다.
load factor : 할당된 키의 개수 / 해시 버킷의 크기
해시 버킷이 동적 확장 될 때 리해싱 과정을 거치게 된다
리해싱(Rehashing) : 기존 저장되어 있는 값들을 다시 해싱하여 새로운 키를 부여하는 것을 말한다
참고
https://ryu-e.tistory.com/87
https://ratsgo.github.io/data%20structure&algorithm/2017/10/25/hash/
