SQLD 6회차 2과목 오답
14 날짜 함수
TO_DATE(문자열, 형식) 함수
TO_DATE는 문자열을 날짜형으로 바줌
형식에서 입력되지 않은 부분(빠진 정보) 은 기본값으로 채워짐
예: MM만 주면, 일은 01, 연도는 오늘 날짜의 연도로 채움
- 다음 날짜 함수 결과로 적절하지 않은 것은?
단, 오늘 날짜는 2024년 11월 17이다.
형식이 'YYYY/MM'처럼 앞부분까지 꽉 차 있으면, 뒷부분(일)은 01로 채운다.
① TO_DATE('12','MM') : '2024/12/01'
② TO_DATE('2024/12','YYYY/MM') : '2024/12/01'
③ TO_DATE('2024','YYYY') : '2024/01/01'
현재 날짜 반영해야함. 2024-11-17
④ TO_DATE('12','DD') : '2024/11/12'
15 COALESCE, ISNULL, IFNULL
-
COALESCE(COL1, COL2)
왼쪽부터 차례로 확인해서 NULL이 아닌 값을 반환 -
ISNULL(COL1, 20)
COL1이 NULL이면 20 반환 -
IFNULL(NULL, '대체')
표현식이 NULL이면 대체값, 아니면 표현식 자체 반환
17 문자열 제거
-
RPAD(문자열, 길이, 채울 문자)
→ 오른쪽으로 길이를 맞추면서 채울 문자로 채운다 (Right Pad)
Oracle에서 첫 번째 인자가 NULL이면, 결과도 무조건 NULL. 즉, RPAD(NULL, 4, '*') → NULL
Oracle에서는 ''(빈 문자열)을 NULL로 처리 -
RTRIM(문자열, 잘라낼 문자)
Right Trim
오른쪽에서 잘라내다 (자르다) -
TRIM(문자 from 문자열)
TRIM([[LEADING | TRAILING | BOTH] 제거할문자 FROM 문자열])
양쪽 공백 제거
-
REPLACE(원본문자열, 바꿀문자열, 대체문자열)
대체문자열 생략시 대체 -> 제거로 역할 바뀜
20 count
count는 null빼고 센다
group by는 null을 같이 출력함.
21 group by
GROUP BY를 쓰면, SELECT 절에는 다음만 올 수 있다:
- GROUP BY에 있는 컬럼
- 집계함수(Aggregate Function) — 예: SUM, AVG, COUNT 등
27 join
② FULL OUTER JOIN은 두 집합의 UNION과 같다
③ USING절에는 괄호를 생략할 수 없다.
using(동일컬럼명)
④ ORACLE에서는 FROM절의 테이블 순서에 따라 JOIN 결과가 달라지지 않는다.
당연함 (+) 사용함.
29 NOT EXISTS와 NULL의 비교 처리 방식
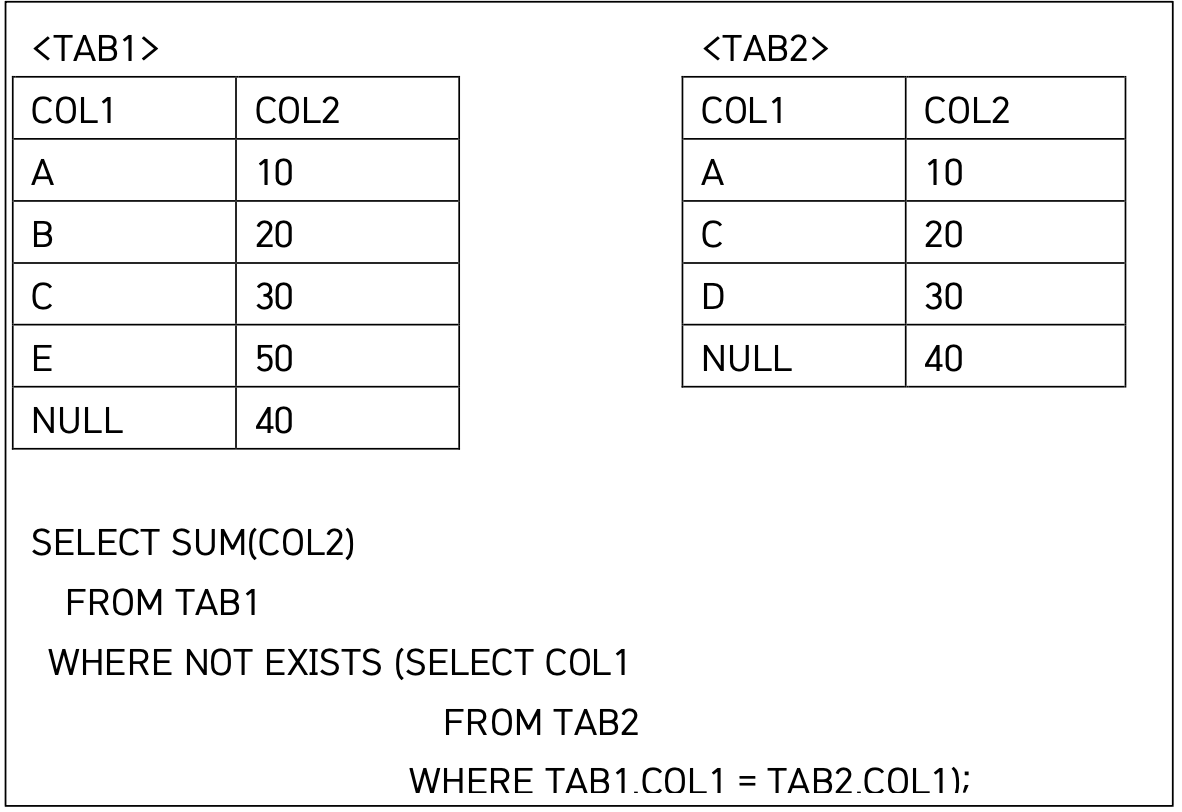
✅ 핵심 포인트: NULL은 = NULL 비교 시 무조건 FALSE (또는 UNKNOWN) 처리됨!
NULL = NULL은 FALSE가 아니라 UNKNOWN이기 때문에
NOT EXISTS 조건에서는 NULL도 "없다고" 간주돼서 포함된다!
not in
NOT IN은 내부 서브쿼리 결과에 NULL이 하나라도 포함되면,모든 비교 결과가 UNKNOWN
→ 최종 결과는 아무 것도 안 나옴!
| 조건문 예시 | TAB2에 NULL 있음 | TAB1.COL1이 NULL일 때 결과 포함? | 설명 |
|---|---|---|---|
COL1 IN (SELECT COL1 FROM TAB2) | ✅ | ❌ | NULL = NULL은 비교 안 됨 → 포함 안 됨 |
COL1 NOT IN (SELECT COL1 FROM TAB2) | ✅ | ❌ | 내부 NULL → 전체 조건 UNKNOWN → 아무 행도 안 나옴 |
EXISTS (SELECT 1 FROM TAB2 WHERE TAB1.COL1 = TAB2.COL1) | ✅ | ❌ | COL1 = NULL은 비교 안 돼서 FALSE 처리 |
NOT EXISTS (SELECT 1 FROM TAB2 WHERE TAB1.COL1 = TAB2.COL1) | ✅ | ✅ | = NULL이 실패(UNKNOWN) → 존재 안 한다고 간주 → 포함됨 |
31 오류
SELECT T1.COL1, T2.AVGSAL
FROM TAB1 T1
WHERE COL1 < (
SELECT AVG(COL1) AS AVGVAL -- 오류
FROM TAB1 T2
WHERE COL2 = T1.COL2
);
T2.AVGSAL 컬럼이 없음.(from에서 select해와야하니까!)
34 ANY
✅ COL2 < ANY (서브쿼리) 의미
👉 "서브쿼리에서 나오는 값 중 하나라도 보다 작으면 통과!"
🔁 다시 말해:
COL2 < ANY(리스트) = COL2 < MAX(리스트)
| TAB1.COL1 | TAB1.COL2 | TAB2에서 비교 대상 | 조건 (COL2 < ANY) | 포함 여부 |
|---|---|---|---|---|
| A | 25 | 30, 20 | 25 < 30 ✅ | 포함 |
| B | 20 | 20, 10 | 20 < 20 ❌, 20 < 10 ❌ | 제외 |
| C | 40 | 30, 40 | 40 < 30 ❌, 40 < 40 ❌ | 제외 |
| D | 10 | 10, 20 | 10 < 20 ✅ | 포함 |
다중행 비교 연산자
| 연산자 | 의미 | 실제 비교 방식 | 예시 |
|---|---|---|---|
IN | 여러 값 중 하나와 같으면 TRUE | = ANY | x IN (1, 2, 3) → x = 1 OR x = 2 OR x = 3 |
NOT IN | 여러 값 중 어느 것도 같지 않으면 TRUE | != ALL | x NOT IN (1, 2, 3) → x ≠ 1 AND x ≠ 2 AND x ≠ 3 |
ANY 또는 SOME | 비교 조건을 하나라도 만족하면 TRUE | x < ANY(...) = x < MAX(...) | x < ANY(3, 7, 10) → x < 10 |
ALL | 모든 값과 비교 조건을 만족해야 TRUE | x < ALL(...) = x < MIN(...) | x < ALL(3, 7, 10) → x < 3 |
35 UNION, ORDER BY
SELECT COL1, COL2
FROM TAB1
ORDER BY COL1
UNION ALL
SELECT COL1, COL2
FROM TAB2
ORDER BY COL1;집합연산자(union all)사용시 각 쿼리에 정렬 수행 x
마지막에 사용된 order by만 가능
36 GROUP BY의 확장 기능 (다차원 집계)
| 구분 | CUBE(A, B) | ROLLUP(A, B) | GROUPING SETS((A, B), (A), (B), ()) |
|---|---|---|---|
| 기능 요약 | A와 B의 모든 조합 + 총합까지 자동 생성 | A를 기준으로 단계적 누적 합계 생성 | 원하는 집계 조합만 직접 지정 가능 |
| 자동 생성 그룹 | (A, B), (A), (B), () | (A, B), (A), () | (A, B), (A), (B), () (직접 지정한 경우에만) |
39 윈도우 함수 범위 지정
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
현재 행과 바로 이전 행”만을 대상으로 누적합 계산하라
전체누적을 계산하고 싶다면
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 사용
| 키워드 | 의미 | 예시 설명 |
|---|---|---|
UNBOUNDED PRECEDING | 가장 첫 행부터 | 처음부터 현재까지 포함 |
1 PRECEDING | 바로 이전 행 포함 | 현재 기준으로 위쪽 한 행 |
CURRENT ROW | 현재 행만 | 지금 이 행만 계산 |
1 FOLLOWING | 바로 다음 행 포함 | 아래쪽 한 행 |
UNBOUNDED FOLLOWING | 마지막 행까지 포함 | 현재부터 끝까지 |
41 계층형 탐색
START WITH부터 시작!!
- 인문대학까지 포함하는 경우
START WITH PART IS NULL
CONNECT BY PRIOR DEPTNO = PART
45 정규표현식
SELECT COUNT(ID)
FROM TAB1
WHERE REGEXP_LIKE(ID, '^A|B.+A$');
패턴: ^A|B.+A$
^A→ A로 시작B.+A$→ B로 시작해서 중간에 뭐든 있고 A로 끝남
a or b가 아니다 가 아님!!!
. : 임의의 한 문자
+ : 하나 이상
A : 문자 A
$ : 문자열 끝
.+A$ : "하나 이상의 아무 문자 다음에 A가 오고, A가 문자열의 끝이어야 한다"
46 Oracle에서의 UPDATE
①
UPDATE EMP
SET SAL = 5000, COMM = 300
WHERE ENAME = 'SMITH';
②
UPDATE EMP
SET (SAL, COMM) = (5000, 300)
WHERE ENAME = 'SMITH';
③
UPDATE EMP
SET (SAL, COMM) = (SELECT MAX(SAL), MAX(COMM)
FROM EMP)
WHERE ENAME = 'SMITH';
④
UPDATE EMP E1
SET SAL = (SELECT MAX(SAL)
FROM EMP
WHERE DEPTNO = E1.DEPTNO)
WHERE ENAME = 'SMITH';2번 ) Oracle에서는 상수 리스트를 직접 튜플처럼 대입하는 문법이 허용되지 않음
즉, SET (COL1, COL2) = (값1, 값2) ← ❌ 문법 오류
💥 튜플 대입은 반드시 서브쿼리로만 가능
47 TCL

ROLLBACK해서 INSERT C가 없어짐!!!!!
48 제약조건
INSERT INTO TAB1 VALUES(4, 'D', NULL);
-- COL3에 명시적으로 NULL 지정했기때문에 기본값 100이 안들어감.
49 외래키
① 외래키를 생성하기 위해서는 반드시 참조키에 기본키 또는 고유키가 먼저 생성되어야 한다.
② 외래키 설정 후에는 참조키에 생성된 제약조건을 삭제할 수 없다.
③ 외래키 설정 후 부모 테이블 삭제 시 CASCADE 옵션을 사용하면 자식 테이블의 외래키 제약조건도 제거할 수 있다.
테이블 제거는 아님.
④ 외래키를 ON DELETE CASCADE 옵션과 함께 생성하면 부모 데이터 삭제 시 부모키를 참조하고 있는 자식 데이터도 함께 삭제할 수 있다.
cascade
연결된 객체나 데이터에 영향을 줄 때, 그 영향을 “연쇄적으로” 전파하겠다는 뜻
| CASCADE 종류 | 설명 |
|---|---|
CASCADE CONSTRAINTS | DROP 시 연결된 제약조건(자식)도 같이 제거 |
ON DELETE CASCADE | 부모 레코드 삭제 시 자식 레코드도 같이 삭제 |
ON UPDATE CASCADE | 부모 키가 바뀌면 자식도 바꿈 (Oracle 미지원) |
50 사용자 권한
① 자신이 소유한 테이블에 대해서는 조회 권한을 다른 사용자에게 언제나 부여할 수 있다.
② SYSTEM 계정에서 테이블을 생성하는 경우 항상 SYSTEM 소유로 생성된다.
소유자는 따로 지정 가능하다
-- SYSTEM 계정이 다른 사용자의 스키마에 테이블 생성 가능
CREATE TABLE SCOTT.TEST (ID NUMBER);소유자 scott
③ 동시에 여러 테이블에 대한 조회 권한을 부여할 수 없다.
GRANT SELECT ON 테이블1 TO 사용자명;
GRANT SELECT ON 테이블2 TO 사용자명;
--오류
GRANT SELECT ON 테이블1, 테이블2 TO 사용자명;
이렇게 여러 줄로도 되지만,
하나의 GRANT 구문으로는 한 번에 하나의 테이블만 지정.
④ 권한을 동시에 여러 사용자에게 부여할 수 있다.**
GRANT SELECT ON 테이블명 TO SCOTT, JANE, TOM;
