SQLD 정리 - 1과목 + 2과목 (1 - 6)
1과목
4. 관계
관계의 페어링
✅ 핵심 개념 요약
인스턴스: 엔터티 안의 하나하나의 데이터(행, row)
예: 고객 엔터티에 있는 "홍길동"이라는 한 명의 고객 정보 → 인스턴스 하나!
관계(Relationship): 두 엔터티의 인스턴스끼리 연결되어 있는 상태
예: 고객 "홍길동"이 주문 "1001번"을 했다 → 이게 관계 하나야.
페어링(Pairing): 인스턴스끼리 짝을 짓는 것!
→ 관계는 결국 이런 "인스턴스 간의 짝"들의 모음
예시
엔터티 2개:
- 고객 엔터티 (Customer)
- 주문 엔터티 (Order)
데이터 인스턴스:
-
고객 인스턴스:
C1: 홍길동
C2: 김영희 -
주문 인스턴스:
O1: 주문번호 1001
O2: 주문번호 1002
O3: 주문번호 1003
고객 C1(홍길동)이 O1, O3을 주문했고
고객 C2(김영희)가 O2를 주문했다면,
페어링은
- (C1, O1)
- (C1, O3)
- (C2, O2)
이 각각이 관계 인스턴스 (페어링),
이 전체를 모아서 말하면 → 고객과 주문 간의 관계(Relationship)
관계의 표기법
| 요소 | 예시 |
|---|---|
| 관계명 | 주문한다 (고객 ― 주문한다 ― 주문) |
| 관계차수 | 1\:N (고객 1명은 주문 여러 개 가능) |
| 선택성 | 고객은 주문이 없어도 된다 → 선택 관계 (○) |
IE표기법
고객 ○──────< 주문
주문 입장에선 → 고객이 필수 (직선)
고객 입장에선 → 주문은 선택 (○ 있음)
차수는 1:N (고객 1명 : 주문 여러 개)
2단원
1. 관계형 데이터베이스 개요
데이터베이스와 DBMS(Database Management System)
- DBMS : 데이터를 효과적으로 관리하기 위한 시스템
개인이 파일을 여러 개 묶어서 폴더에 보관하면 데이터를 찾고 관리하는데 많은 비용이 발생 -> 이를 보다 시스템적으로 작동하게 만든 시스템 = DBMS
(ORACLE, MYSQL 등)
관계형 데이터베이스 구성 요소
- 계정 : 데이터의 접근 제한을 위한 여러 업무별/시스템별 계정이 존재
- 테이블 : DBMS 의 DB 안에서 데이터가 저장되는 형식
- 스키마 : 테이블이 어떠한 구성으로 되어있는지, 어떠한 정보를 가지고 있는지에 대한 기본적인 구조를
정의 (데이터베이스에 어떤 데이터가 어떻게 들어있는지를 설명한 설계도)
객체
| 객체 이름 | 설명 |
|---|---|
| 테이블 | 데이터를 저장하는 구조 (행/열) |
| 뷰(View) | SELECT 결과를 저장해둔 가상 테이블 |
| 인덱스 | 검색 속도 빠르게 도와주는 구조 |
| 시퀀스 | 자동 번호 증가하는 번호표 |
| 트리거 | 어떤 일이 벌어졌을 때 자동으로 실행되는 코드 |
| 프로시저/함수 | 저장된 SQL 코드 조각들 |
SQL(Structured Query Language)
- 관계형 데이터베이스에서 데이터 조회 및 조작, DBMS 시스템 관리 기능을 명령하는 언어
- 데이터 정의(DDL), 데이터 조작(DML), 데이터 제어 언어(DCL) 등으로 구분
- SQL 문법은 대소문자를 구분하지 X
관계형 데이터베이스 특징
- 기존의 작성된 스키마를 수정하기 어려움
- 데이터베이스의 부하(DB에 걸리는 업무량, load)를 분석하는 것이 어려움
여러 테이블이 복잡하게 엮여 있고 (JOIN 많이 함)
사용자 수가 많고
트랜잭션도 많고
로그나 쿼리 실행 계획을 잘 봐야 어디가 병목(한 지점에서 처리 속도가 느려져서 전체 시스템이 느려지는 상황)인지 알 수 있어서
어디서 부하가 많이 생기는지, 즉 어떤 쿼리, 어떤 테이블이 병목인지 파악하기 어렵다는 뜻
데이터 무결성 종류
- 개체무결성
- 참조 무결성
- 도메인 무결성
- NULL 무결성
- 고유 무결성
- 키 무결성
SQL종류
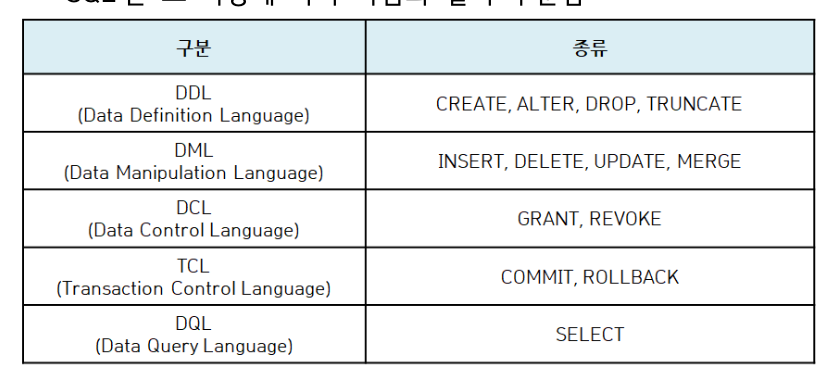
┌────────────┬─────────────────────────────────────┬────────────────────────────────────────┐
│ 구분 │ 설명 │ 종류 │
├────────────┼─────────────────────────────────────┼────────────────────────────────────────┤
│ DDL │ Data Definition Language │ CREATE, ALTER, DROP, TRUNCATE │
│ │ (데이터 정의어) │ │
├────────────┼─────────────────────────────────────┼────────────────────────────────────────┤
│ DML │ Data Manipulation Language │ INSERT, DELETE, UPDATE, MERGE │
│ │ (데이터 조작어) │ │
├────────────┼─────────────────────────────────────┼────────────────────────────────────────┤
│ DCL │ Data Control Language │ GRANT, REVOKE │
│ │ (데이터 제어어) │ │
├────────────┼─────────────────────────────────────┼────────────────────────────────────────┤
│ TCL │ Transaction Control Language │ COMMIT, ROLLBACK │
│ │ (트랜잭션 제어어) │ │
├────────────┼─────────────────────────────────────┼────────────────────────────────────────┤
│ DQL │ Data Query Language │ SELECT │
│ │ (데이터 질의어) │ │
└────────────┴─────────────────────────────────────┴────────────────────────────────────────┘
select문 구조
FROM > WHERE > GROUP BY > HAVING > SELECT > ORDER BY 순서대로
그래서 as(alisas)의 경우 SELECT 문보다 늦게 수행되는 ORDER BY 절에서만 컬럼 별칭 사용 가능(그 외 절에서 사용시 에러 발생)
from 절
-
테이블 여러 개 전달 가능(컴마로 구분) -> 조인 조건 없이 테이블명만 나열 시 카티시안 곱 발생 주의!
-
테이블 별칭 선언 가능(ORACLE 은 AS 사용 불가, SQL Server 는 사용/생략가능)
※ 테이블 별칭 선언 시 컬럼 구분자는 테이블 별칭으로만 전달(테이블명으로 사용 시 에러 발생)
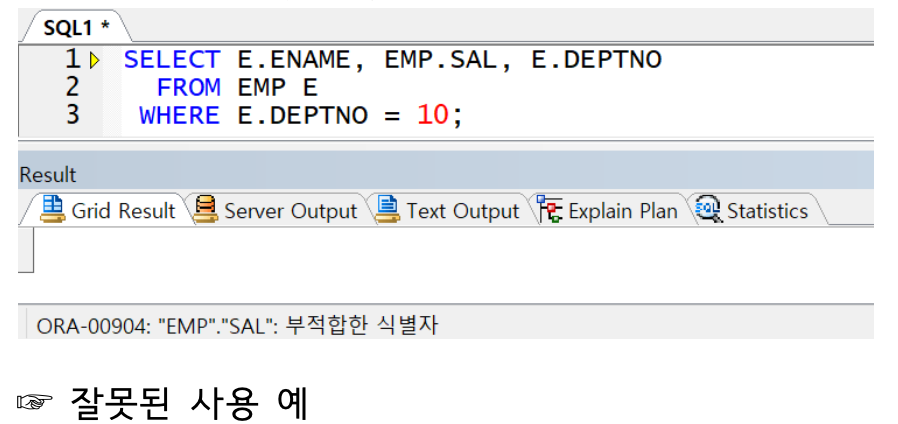
select에 emp.으로 하면 오류
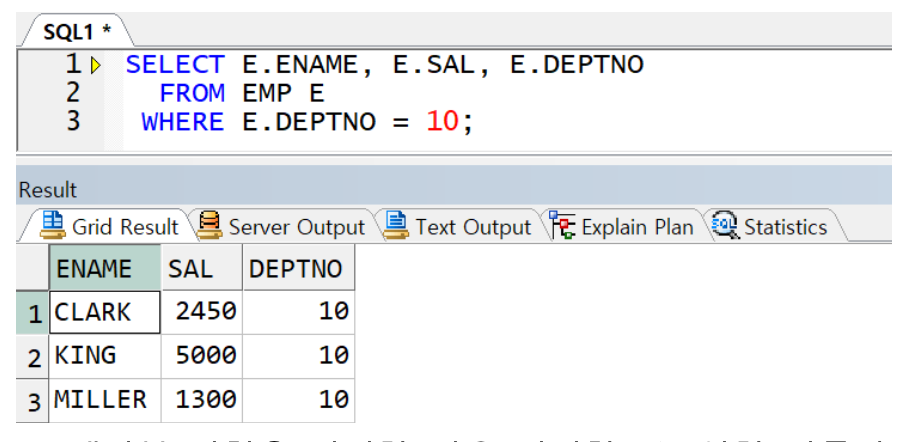 별칭 e로 사용해야 가능
별칭 e로 사용해야 가능 -
ORACLE 에서는 FROM 절 생략 불가(의미상 필요 없는 경우 DUAL 테이블 선언)
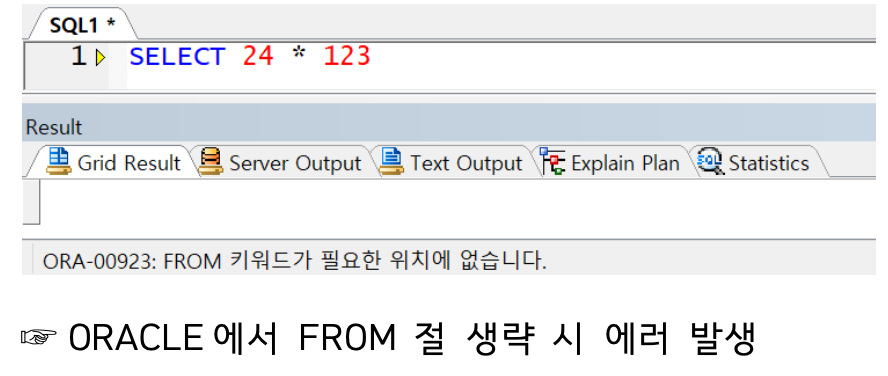
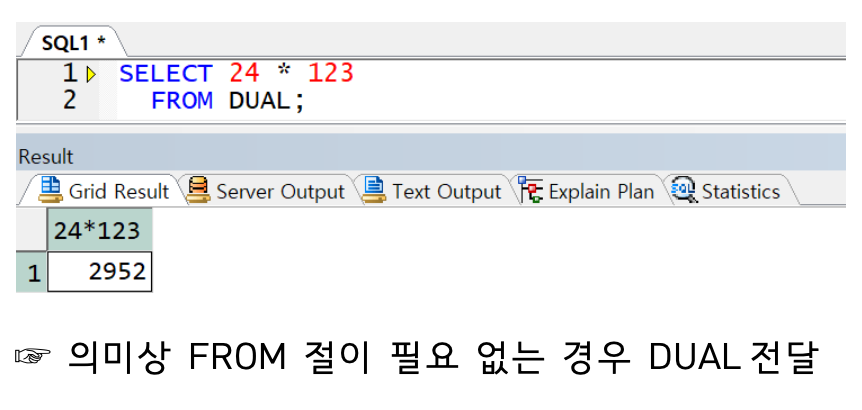
※ ORACLE 23c 버전부터는 생략 가능
SQL Server 에서는 FROM 절 필요 없을 경우 생략 가능(오늘 날짜 조회 시)
3. 함수
입/출력 값의 타입에 따른 함수 분류
문자형 함수
단일행 함수 형태로 output은 대부분 문자값
| 함수명 | 함수기능 | 사용예시 | 출력 | 기타설명 |
|---|---|---|---|---|
LOWER(대상) | 문자열을 소문자로 | LOWER('ABC') | abc | |
UPPER(대상) | 문자열을 대문자로 | UPPER('abc') | ABC | |
SUBSTR(대상, m, n) | 문자열 중 m위치에서 n개의 문자 추출 | SUBSTR('ABCDE',2,3) | BCD | n 생략 시 끝까지 추출 |
SUBSTR('ABCDE',2) | BCDE | |||
SUBSTR('ABCDE',-4,3) | BCD | 뒤에서 4번째(B)부터 오른쪽으로 스캔하여 3개 추출 | ||
INSTR(대상, 찾을문자열, m, n) | 대상에서 찾을문자열 위치 반환 | INSTR('A#B#C#', '#') | 2 | m과 n 생략 시 1로 해석 |
INSTR('A#B#C#', '#', 3, 2) | 6 | 3번째부터 두번째 발견된 # 위치 | ||
INSTR('A#B#C#', '#', -3, 2) | 2 | 뒤에서 3번째 #부터 왼쪽으로 스캔하여 두 번째 발견된 # 위치 | ||
LTRIM(대상, 삭제문자열) | 왼쪽에서 특정 문자 삭제 | LTRIM('AABABAA','A') | BABAA | |
RTRIM(대상, 삭제문자열) | 오른쪽에서 특정 문자 삭제 | RTRIM('AABABAA','A') | AABAB | |
TRIM(대상) | 양쪽의 공백 제거 | TRIM(' ABCDE ') | ABCDE | Oracle에서는 공백만 삭제 가능 |
LPAD(대상, n, 문자열) | 왼쪽에 문자 추가하여 총 n길이 반환 | LPAD('ABC',5,'*') | **ABC | |
RPAD(대상, n, 문자열) | 오른쪽에 문자 추가하여 총 n길이 반환 | RPAD('ABC',5,'*') | ABC** | |
CONCAT(대상1, 대상2) | 문자열 결합 | CONCAT('A','B') | AB | 두 개의 인수만 전달 가능 |
LENGTH(대상) | 문자열 길이 | LENGTH('ABCDE') | 5 | |
REPLACE(대상, 찾을문자열, 바꿀문자열) | 문자열 치환 및 삭제 | REPLACE('ABBA','AB','ab') | abBA | 세 번째 인수를 생략하거나 빈문자열 전달 시 찾을문자열 삭제 가능 |
TRANSLATE(대상, 찾을문자열, 바꿀문자열) | 글자를 1대1로 치환 | TRANSLATE('ABBA','AB','ab') | abba | A는 a로, B는 b로 각각 치환, 바꿀문자열 생략 불가. 빈문자열 전달시 NULL 리턴 |
SQL Server경우
SUBSTR -> SUBSTRING
LENGTH -> LEN
INSTR -> CHARINDEX
숫자형 함수
| 함수명 | 함수기능 | 사용예시 | 출력 | 기타설명 |
|---|---|---|---|---|
| ABS(숫자) | 절대값 반환 | ABS(-1.5) | 1.5 | |
| ROUND(숫자, 자리수) | 소수점 특정 자리에서 반올림 | ROUND(123.456, 2) | 123.46 | 소수점 둘째자리로 반올림 |
| ROUND(123.456, -2) | 100 | 자리수가 음수이면 정수자리에서 반올림 (십의 자리에서 반올림 진행) | ||
| TRUNC(숫자, 자리수) | 소수점 특정 자리에서 버림 | TRUNC(123.456, 2) | 123.45 | |
| SIGN(숫자) | 숫자가 양수면 1, 음수면 -1, 0이면 0 반환 | SIGN(100) | 1 | |
| FLOOR(숫자) | 작거나 같은 최대 정수 리턴 | FLOOR(3.5) | 3 | |
| CEIL(숫자) | 크거나 같은 최소 정수 리턴 | CEIL(3.5) | 4 | |
| MOD(숫자1, 숫자2) | 숫자1을 숫자2로 나누어 나머지 반환 | MOD(7, 2) | 1 | |
| POWER(m, n) | m의 n 거듭제곱 | POWER(2, 4) | 16 | |
| SQRT(숫자) | 루트값 리턴 | SQRT(16) | 4 |
날짜형 함수
ORACLE 과 SQL Server 함수 거의 달라 주의
| 함수명 | 함수기능 | 사용예시 | 출력 | 기타설명 |
|---|---|---|---|---|
| SYSDATE | 현재 날짜와 시간 리턴 | SYSDATE | 2024/02/14 18:44:34 | 날짜출력형식에 따라 다르게 출력됨 (날짜만 출력될 수 있음) |
| CURRENT_DATE | 현재 날짜 리턴 | CURRENT_DATE | 2024/02/14 | 날짜출력형식에 따라 다르게 출력됨 (시간이 출력될 수 있음) |
| CURRENT_TIMESTAMP | 현재 타임스탬프 리턴 | CURRENT_TIMESTAMP | 2024/02/14 18:45:29 +09:00 | |
| ADD_MONTHS(날짜, n) | 날짜에서 n개월 후 날짜 리턴 | ADD_MONTHS(SYSDATE, 3) | 2024/05/14 18:44:34 | n이 음수인 경우 n개월 이전 날짜 리턴 |
| MONTHS_BETWEEN(날짜1, 날짜2) | 날짜1과 날짜2의 개월 수 리턴 | MONTHS_BETWEEN(SYSDATE, HIREDATE) | 3.7234 | 날짜1 < 날짜2 로 전달 시 음수 리턴 |
| LAST_DAY(날짜) | 주어진 월의 마지막 날짜 리턴 | LAST_DAY(SYSDATE) | 2024/02/29 18:44:34 | |
| NEXT_DAY(날짜, n) | 주어진 날짜 이후 지정된 요일의 첫 번째 날짜 리턴 | NEXT_DAY(SYSDATE, 1) | 2024/02/18 18:51:35 | 1:일요일, 2:월요일, ..., 7:토요일 |
| ROUND(날짜, 자리수) | 날짜 반올림 | ROUND(SYSDATE, 'MONTH') | 2024-02-01 00:00 | 월 이전자리에서 반올림 |
| TRUNC(날짜, 자리수) | 날짜 버림 | TRUNC(SYSDATE, 'MONTH') | 2024-02-01 00:00 | 월 이전자리에서 버림 |
SQL Server에서는..
SYSDATE -> GETDATE
ADD_MONTHS -> DATEADD(월 뿐만 아니라 모든 단위 날짜 연산 가능)
MONTHS_BETWEEN -> DATEDIFF(두 날짜 사이의 년, 월, 일 추출)
변환함수
| 함수명 | 함수기능 | 사용예시 | 출력 | 기타설명 |
|---|---|---|---|---|
| TO_NUMBER(문자) | 숫자 타입으로 변경하여 리턴 | TO_NUMBER('100') | 100 | 문자 '100'을 숫자 100으로 리턴 |
| TO_CHAR(대상, 포맷) | 1) 날짜의 포맷 변경 | TO_CHAR(SYSDATE, 'MM/DD/YYYY') | 02/14/2024 | 날짜 형식 변경 (리턴은 문자타입) |
| 2) 숫자의 포맷 변경 | TO_CHAR(9000, '9,999') | 9,000 | 천단위 구분기호 생성 (리턴은 문자타입) | |
| TO_CHAR(9000, '09999') | 09000 | 총 5자리로 리턴 (앞 자리를 0으로 채움) | ||
| TO_DATE(문자, 포맷) | 주어진 문자열을 포맷 형식에 맞게 읽어 날짜로 리턴 | TO_DATE('2024/01/01', 'YYYY/MM/DD') | 2024/01/01 00:00:00 | 날짜로 리턴됨 |
| FORMAT(날짜, 포맷) | 날짜의 포맷 변경 | FORMAT(GETDATE(), 'YYYY') | 2024 | SQL SERVER 함수 |
| CAST(대상 AS 데이터타입) | 대상을 주어진 데이터타입으로 변환 | CAST('100' AS int) | 100 | 문자 '100'을 숫자 100으로 리턴 |
SQL Server에서는..
TO_NUMBER, TO_DATE, TO_CHAR -> CONVERT(포맷 전달 시)
단순 변환일 경우 주로 CAST 사용
일반함수
기타함수(NULL 치환함수 등)
| 함수명 | 함수기능 | 사용예시 | 출력 | 기타설명 |
|---|---|---|---|---|
| DECODE(대상, 값1, 리턴1, 값2, 리턴2, ..., 그외리턴) | 대상이 값1이면 리턴1, 값2와 같으면 리턴2, … 그 외에는 그외리턴 반환 | DECODE(DEPTNO, 10, A, B) | A 또는 B | 대소비교에 따른 치환 불가, 그외리턴 생략 시 NULL 반환 |
| NVL(대상, 치환값) | 대상이 널이면 치환값으로 치환하여 리턴 | NVL(COMM, 0) | COMM값 또는 0 | |
| NVL2(대상, 치환값1, 치환값2) | 대상이 널이면 치환값2로, 널이 아니면 치환값1로 리턴 | NVL2(COMM, COMM*1.1, 0) | COMM*1.1 또는 0 | COMM이 널이면 0, 아니면 COMM*1.1 반환 |
| COALESCE(대상1, 대상2, ..., 그외리턴) | 대상들 중 널이 아닌 첫 번째 값 리턴, 모두 널이면 NULL 반환 | COALESCE(NULL, 100) | 100 | 그외리턴 생략 시 NULL 반환 |
| ISNULL(대상, 치환값) | 대상이 널이면 치환값 리턴 | ISNULL(NULL, 100) | 100 | SQL Server 함수 |
| NULLIF(대상1, 대상2) | 두 값이 같으면 NULL, 다르면 대상1 리턴 | NULLIF(10, 20) | 10 | |
| CASE문 | 조건별 치환 및 연산 수행 | (아래에 별도 정리 가능) | (아래에 별도 정리) | 다양한 조건 분기 처리 가능. 복잡한 로직 구현 가능 |
-
decode 예시
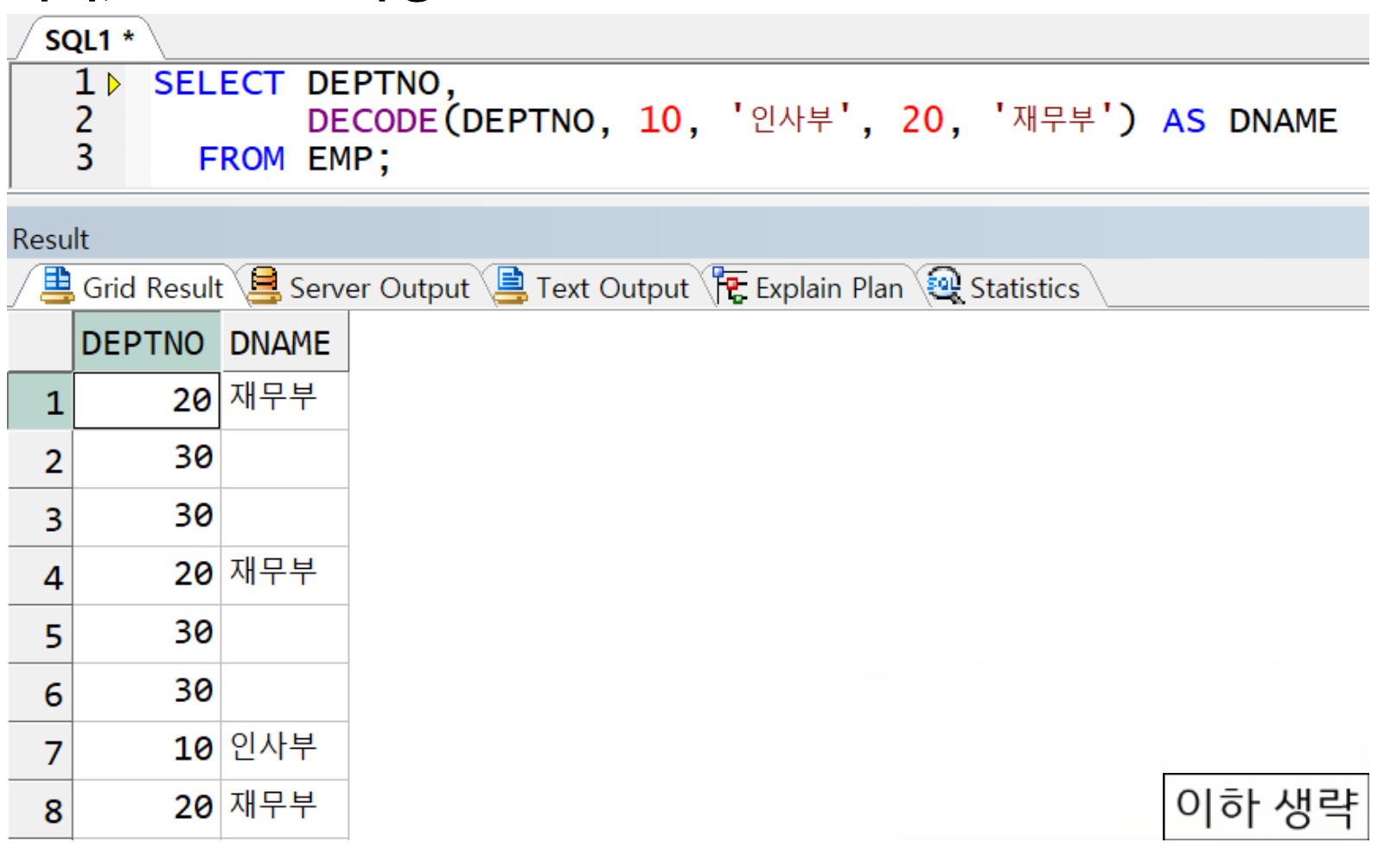
부서번호 10이면 인사부, 20번이면 재무부, 나머지는 널값 리턴
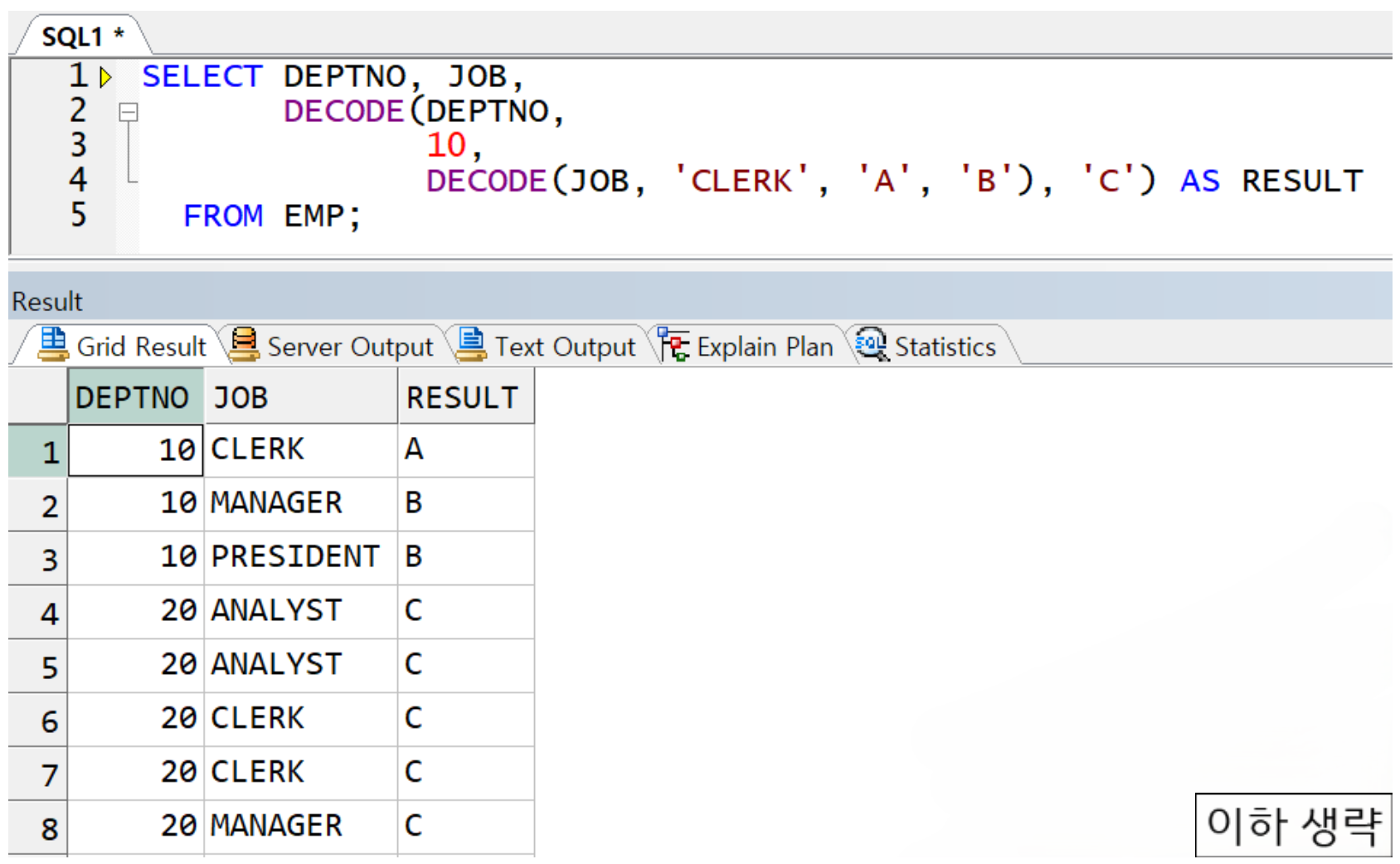
DEPTNO가 10이면서 JOB이 CLERK이면 A,
DEPTNO가 10이면서 CLERK가 아니면 B,
DEPTNO가 10이 아니면 C -
NVL, NVL2 예시
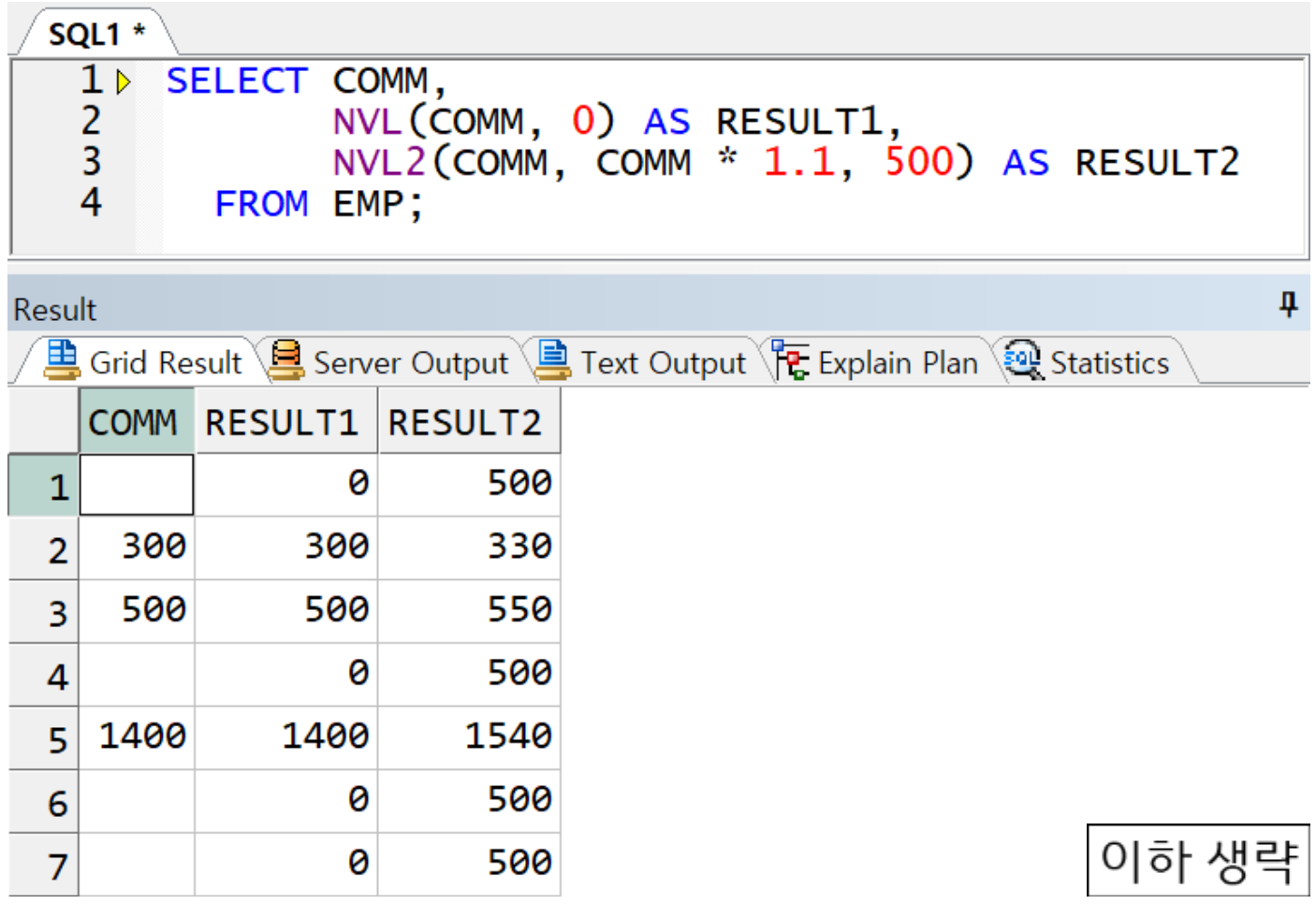
☞ NVL2의 경우 NVL이랑 다르게 COMM의 값이 널이 아닐 때도 치환값 정의 가능.
COMM이 널이 아니면 10% 인상값, 널이면 500 리턴 -
casewhen 예시
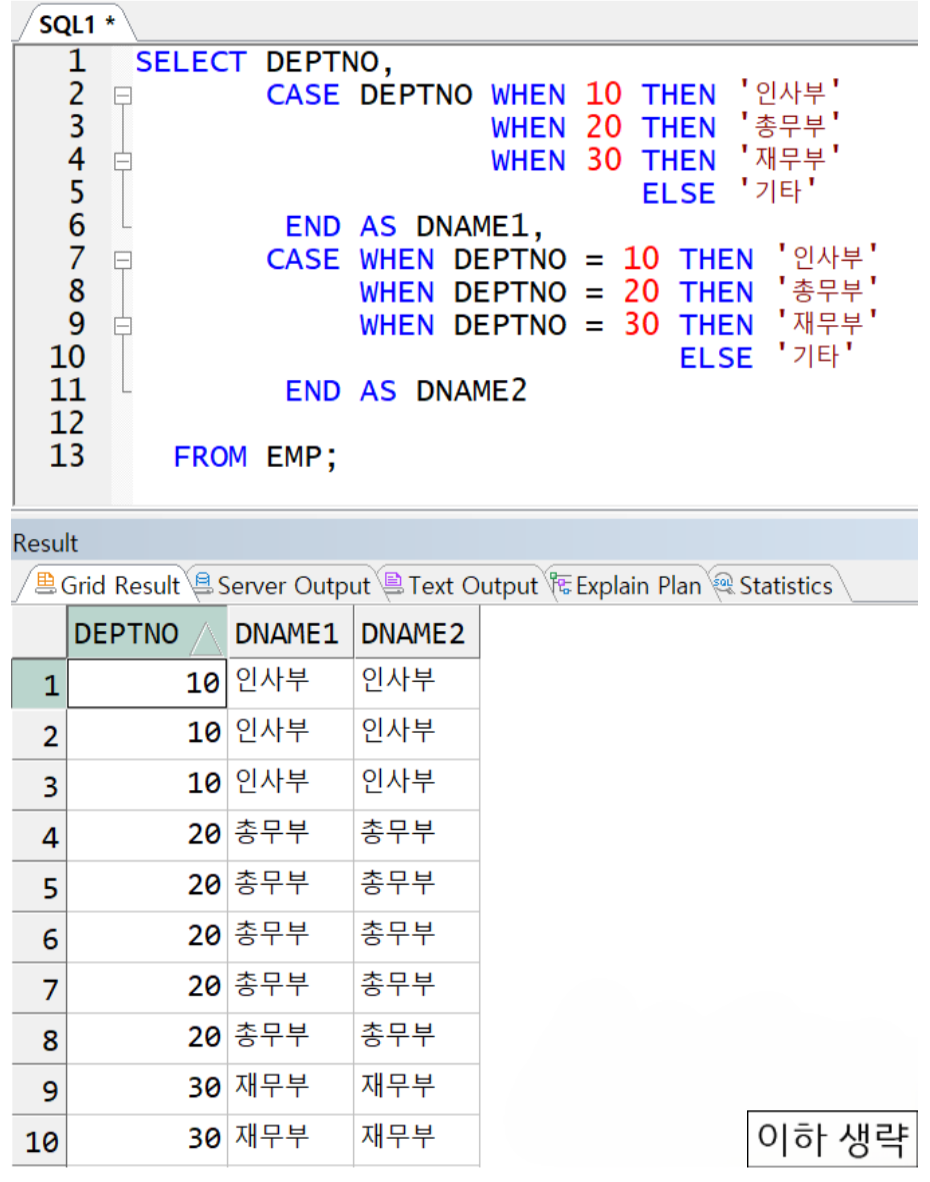
동등비교 시 위처럼 비교대상(DEPTNO)를 CASE와 WHEN 사이에 배치하면서 WHEN절 마다 반복하지 않아
도 됨 (이 때 DEPTNO 데이터 타입과 WHEN절의 명시된 비교대상의 데이터타입 반드시 일치해야 함) -
nullif 예시
null값 치환하기 위한 목적이 아닌,
특정 값과 일치하는 대상을 NULL 로 치환하기 위해 사용
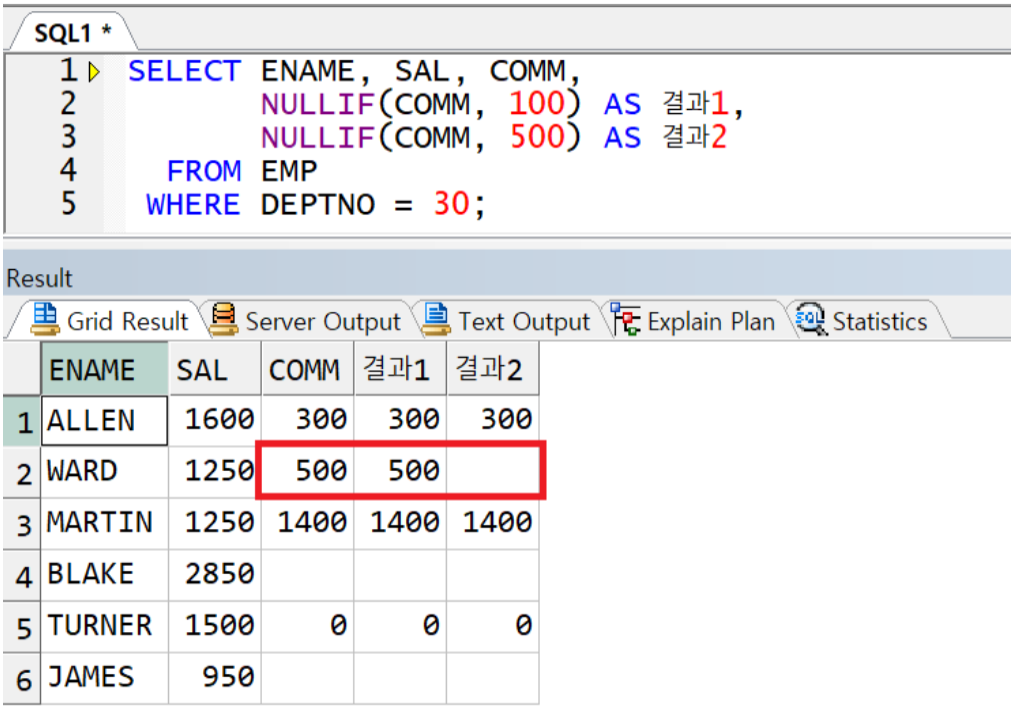
결과 1 의 경우 COMM 의 값이 100 과 일치하는 행이 없으므로 원래 값을 유지,
결과 2 의 경우 COMM 의 값이 500 인 WARD 의 COMM 만 NULL 로 변경되어 출력
4. where 절
Where절
테이블의 데이터 중 원하는 조건에 맞는 데이터만 조회하고 싶을 경우 사용
| 조건문 | 설명 |
| ----------------------- | ------------------------------------------- |
| BETWEEN a AND b | A와 B 사이에 있는 범위 값을 모두 검색 |
| IN(a, b, c) | A, B, C 중 하나와 같은 값을 검색 |
| LIKE | 특정 패턴을 가지는 조건을 검색 (예: %, _ 와 함께 사용) |
| IS NULL / IS NOT NULL | NULL 값이거나, NULL이 아닌 값을 검색 |
| A AND B | A 조건과 B 조건을 모두 만족하는 값을 검색 |
| A OR B | A 조건이나 B 조건 중 하나라도 만족하는 값을 검색 |
| NOT A | A가 아닌 모든 조건을 검색 |
| !=, <> | A와 같지 않은 값을 검색 (두 문법 동일) |
- 문자나 날짜 상수 표현 시 반드시 홑따옴표 사용(다른 절에서도 동일 적용)
- ORACLE 은 문자 상수의 경우 대소문자를 구분
- SQL Server 은 기본적으로 문자상수의 대소문자를 구분하지 X
in연산자
포함연산자로 여러 상수와 일치하는 조건 전달 시 사용
상수를 괄호로 묶어서 동시에 전달(문자와 날짜 상수의 경우 반드시 홑따옴표와 함께)
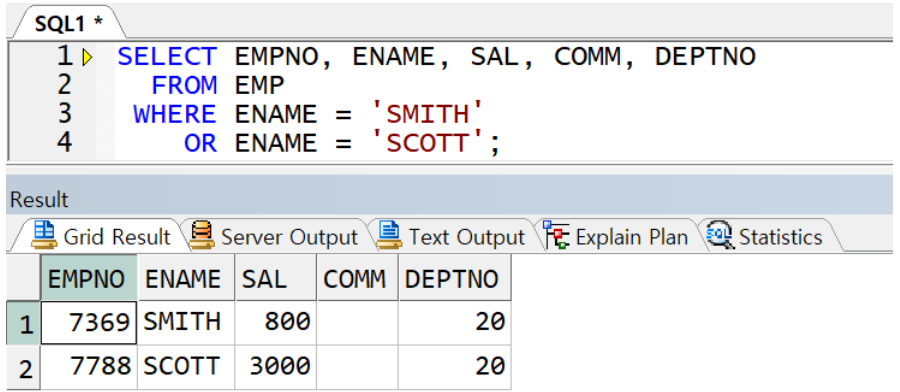
동일한 조건대상(ENAME)이 계속 반복돼야 하는 불편함 ->in연산자를 쓰면 해소
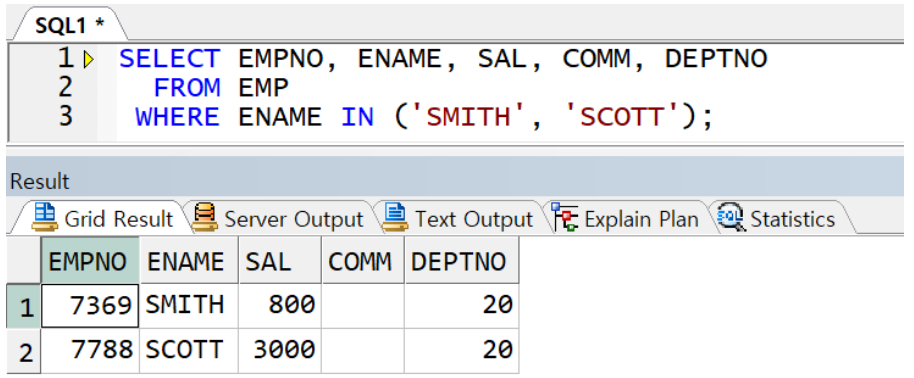
like연산자
- %와 와 함께 사용됨
1) % :자리수 제한 없는 모든이라는 의미
2) : 하나 당 한 자리수를 의미하며 모든 값을 표현함
예제) LIKE 연산자
• ENAME LIKE 'S%' : 이름이 S 로 시작하는
• ENAME LIKE '%S%' : 이름에 S 를 포함하는
• ENAME LIKE '%S' : 이름이 S 로 끝나는
• ENAME LIKE ' S%' : 이름의 두 번째 글자가 S 인(맨 앞이 _ 인것 주의! %이면 자리수 상관없이 S를 포함하기만 하면 됨)
• ENAME LIKE 'S' : 이름의 가운데 글자가 S 이며 이름의 길이가 5 글자인
NOT 연산자
조건 결과의 반대집합. 즉, 여집합을 출력하는 연산자
NOT 뒤에 오는 연산 결과의 반대 집합 출력
주로 NOT IN, NOT BETWEEN A AND B, NOT LIKE, NOT NULL 로 사용
5. group by 절
group by 절
- 만약 그룹 연산에서 제외할 대상이 있다면 미리 WHERE 절에서 해당 행을 제외함 (WHERE 절이 GROUP BY 절보다 먼저 수행되므로)
- 그룹에 대한 조건은 WHERE 절에서 사용할 수 없음
- GROUP BY 절을 사용하면 데이터가 요약되므로 요약되기 전 데이터와 함께 출력할 수 없음
- GROUP BY 절에 명시되지 않은 컬럼 전달 불가!
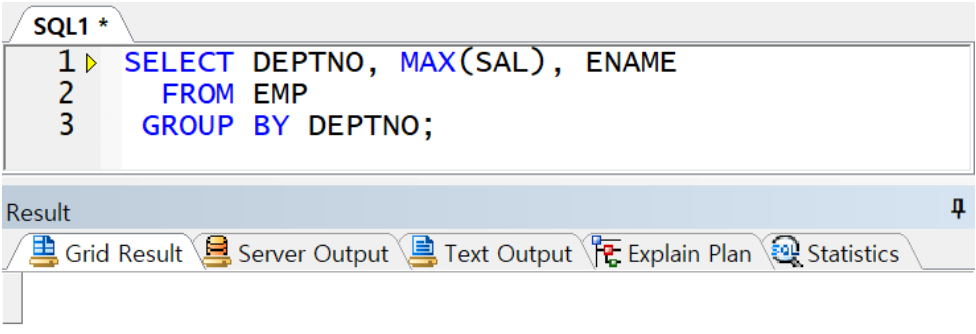
GROUP BY 절에 DEPTNO 를 사용하면 DEPTNO 가 같은 값끼리 묶여서 요약 정보만 SELECT 절에 표현
가능. 따라서 GROUP BY 컬럼과 집계 함수를 사용한 결과만이 전달 가능
ENAME은 집계 함수도 아니고, GROUP BY에도 포함되지 않음 → SQL 표준 위반. 값없음
having 절
- 그룹 함수 결과를 조건으로 사용할 때 사용하는 절
- WHERE 절을 사용하여 그룹을 제한할 수 없으므로 HAVING 절에 전달
- 내부적 연산 순서가 SELECT 절보다 먼저이므로 SELECT 절에서 선언된 Alias 사용 불가
6. order by 절
- 유일하게 SELECT 절에 정의한 컬럼 별칭 사용 가능
- 날짜 : 과거 날짜부터 시작해서 최근 날짜로 정렬
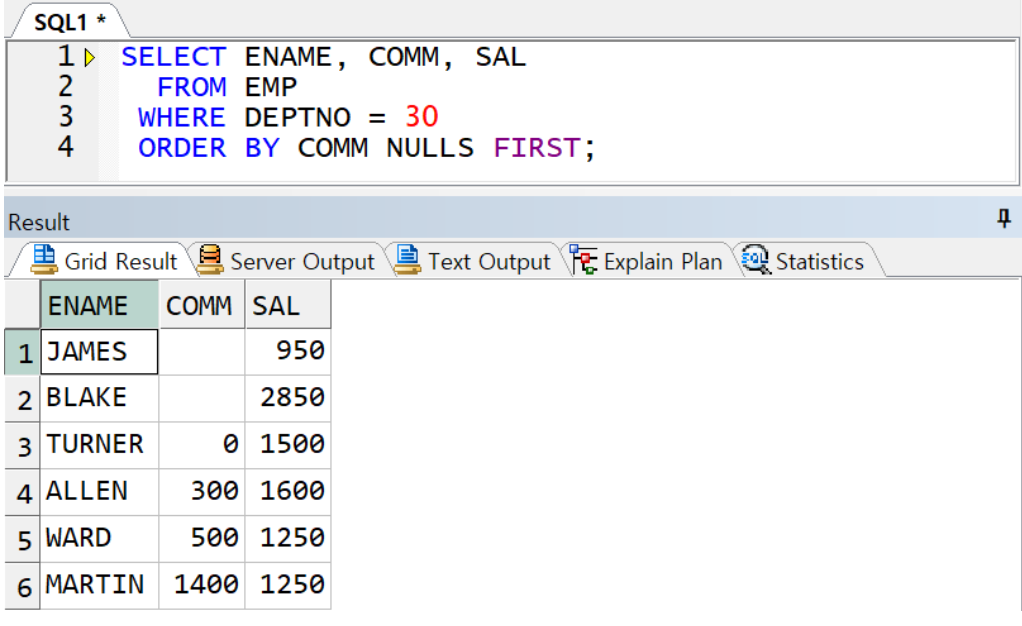
NULL 의 정렬
- NULL 을 포함한 값의 정렬 시 ORACLE 은 기본적으로 NULL 을 마지막에 배치(SQL Server 는 처음에 배치)
- ORACLE 은 ORDER BY 절에 NULLS LAST | NULLS FIRST 을 명시하여 NULL 정렬 순서 변경 가능