1️⃣ 이상 탐지(Anomaly Detection)는 정상 패턴과 다른 데이터를 찾아내는 기법이다.
2️⃣ 이상치 탐지(Outlier Detection)와 유사하지만, 맥락과 패턴 학습 측면에서 조금 더 넓은 범위를 다룬다.
3️⃣ 대표 알고리즘
- One-Class SVM: 정상 데이터를 기준으로 경계를 형성
- Isolation Forest: 무작위 분할을 통해 쉽게 분리되는 데이터를 이상으로 간주
4️⃣ 금융(카드 사기, 돈세탁)과 제조업(설비 고장 예측, 품질 관리) 등 다양한 분야에서 활용할 수 있다.
- 이상 탐지의 개념 이해
- 주요 알고리즘 원리 및 활용 방법 숙지
- 산업별 사례 파악
비지도학습 기법 중 이상 탐지는 정상 패턴에서 벗어난 특이한 패턴을 식별하여, 금융·제조업 등 다양한 산업에서 사전 예방과 효율 극대화를 위해 활용되는 핵심 기술을 알아보겠습니다!
이상탐지
데이터에서 ‘정상(normal) 패턴’과 크게 다른 행위를 보이는 특이한 패턴(이상, anomaly)을 찾는 기법
- ex) 정상 거래 내역과 비교했을 때 매우 높은 금액을 단숨에 인출하는 거래, 센서 신호가 갑자기 급등 또는 급락하는 경우 등
이상치 탐지와의 차이
-
이상치 탐지(Outlier Detection)는 단순히 통계적으로 극단값(Outlier)을 찾는 데 초점을 둔다.
ex) 평균에서 크게 벗어난 데이터 포인트를 찾는 방식 -
이상 탐지(Anomaly Detection)는 단순 극단값 뿐 아니라, 맥락(Context)이나 시계열 상의 패턴을 함께 고려하여 ‘비정상’인지를 판단하는 것을 의미하는 경우가 많다.
ex) 시간적 흐름이나 주변 맥락, 다른 변수들과의 상관관계까지 고려하는 경우
이상 탐지 알고리즘
각 알고리즘은 비지도학습(레이블이 없는 상황)에서 데이터의 분포/패턴을 학습하고, 그로부터 크게 벗어나는 포인트를 ‘이상’으로 간주
One-Class SVM
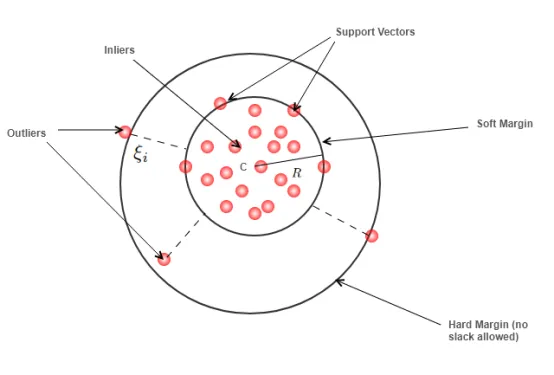
-
SVM(Support Vector Machine)은 원래 이진 분류를 위해 고안된 알고리즘이지만,
One-Class SVM은 ‘단 하나의 클래스(정상 클래스)’만을 학습해 해당 클래스 영역을 정의.
정상 데이터가 분포하는 공간 주위에 경계를 형성(“decision boundary”)하고, 경계 밖에 있는 데이터는 ‘비정상’으로 분류한다. -
특징
- 고차원 공간에서도 비교적 잘 동작할 수 있다(커널 함수의 사용).
- 데이터 스케일링과 커널 파라미터 선택이 중요. (예: RBF 커널일 때 γ값, nu(ν) 값 등)
Isolation Forest
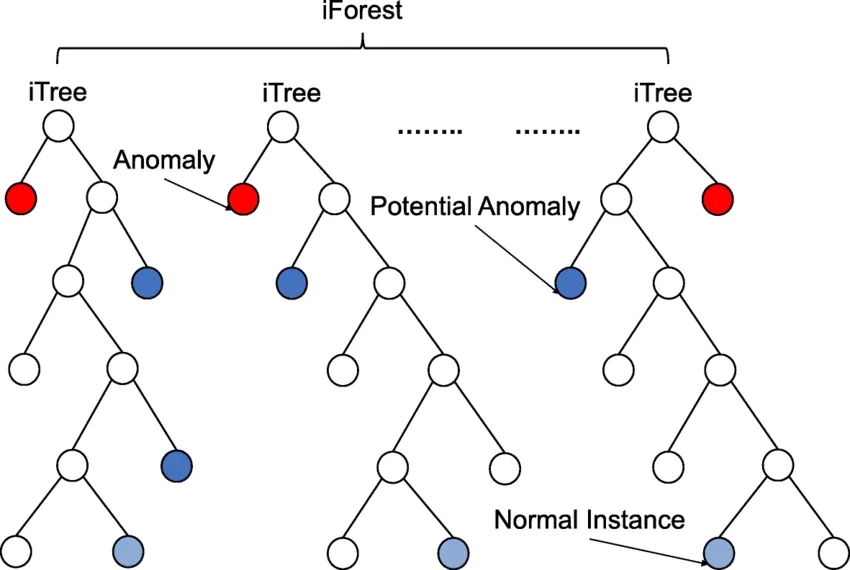
랜덤 포레스트와 유사한 아이디어에 기반.
“이상치(이상 데이터)는 전체 데이터 중 상대적으로 적고, 특정 속성값에서 극
단적인 위치를 차지하는 경우가 많다.”는 가정 하에,무작위로 특성과 분할값을 골라 데이터를 계속 나누어가는 과정에서 ‘쉽게 분리(또는 격리)되는’ 데이터는 이상일 가능성이 높다고 본다.
- 특징
- 랜덤 포레스트 방식으로 여러 개의 무작위 트리를 구성하고, 각 트리에서 한 데이터가 분리되는 “깊이(depth)”를 측정하여 이상 점수를 부여.
- 대규모 데이터셋에서도 빠르게 동작하는 편이며, 구현이 간단하고 직관적.
코드
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 1. 데이터 로드: Iris 데이터셋
from sklearn.datasets import load_iris
data = load_iris()
X = data.data
y = data.target # 여기서는 실제 라벨을 이용하지 않음
# 간단히 2개 특성만 사용 (예: 꽃받침 길이, 꽃받침 너비) --> 시각화 편의를 위해
X_2d = X[:, :2] # shape: (150, 2)
# 2. One-Class SVM
from sklearn.svm import OneClassSVM
oc_svm = OneClassSVM(nu=0.05) # 예시 파라미터
oc_svm.fit(X_2d)
# 예측: 1(정상), -1(이상치)
y_pred_oc = oc_svm.predict(X_2d)
# 3. Isolation Forest
from sklearn.ensemble import IsolationForest
iso_forest = IsolationForest(contamination=0.05, random_state=42)
iso_forest.fit(X_2d)
# 예측: 1(정상), -1(이상치)
y_pred_if = iso_forest.predict(X_2d)
# 4. 이상치로 예측된 샘플 인덱스 추출
outliers_oc = np.where(y_pred_oc == -1)[0] # One-Class SVM이 예측한 이상치
outliers_if = np.where(y_pred_if == -1)[0] # Isolation Forest가 예측한 이상치
print("=== One-Class SVM ===")
print("이상치로 탐지된 샘플 개수:", len(outliers_oc))
print("이상치 인덱스:", outliers_oc)
print("\n=== Isolation Forest ===")
print("이상치로 탐지된 샘플 개수:", len(outliers_if))
print("이상치 인덱스:", outliers_if)
# 5. 시각화
# 2차원 특성 공간에서 이상치로 판별된 점들을 빨간색으로 표시
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].scatter(X_2d[:, 0], X_2d[:, 1], label='Normal')
axes[0].scatter(X_2d[outliers_oc, 0], X_2d[outliers_oc, 1],
color='red', edgecolors='k', label='Outliers')
axes[0].set_title("One-Class SVM")
axes[0].set_xlabel("Sepal Length")
axes[0].set_ylabel("Sepal Width")
axes[0].legend()
axes[1].scatter(X_2d[:, 0], X_2d[:, 1], label='Normal')
axes[1].scatter(X_2d[outliers_if, 0], X_2d[outliers_if, 1],
color='red', edgecolors='k', label='Outliers')
axes[1].set_title("Isolation Forest")
axes[1].set_xlabel("Sepal Length")
axes[1].set_ylabel("Sepal Width")
axes[1].legend()
plt.tight_layout()
plt.show()
-
One-Class SVM
OneClassSVM(nu=0.05)로 모델을 생성fit(X_2d)로 학습한 뒤,predict(X_2d)결과로 1(정상), -1(이상치) 레이블을 받습니다.nu는 데이터 스케일이나 분포에 따라 조정 가능하며,nu=0.05는 전체 데이터 중 약 5% 정도를 이상치로 잡겠다는 것.
-
Isolation Forest
IsolationForest(contamination=0.05, random_state=42)로 모델 생성fit(X_2d)로 학습 후,predict(X_2d)결과로 1(정상), -1(이상치) 레이블 받기contamination=0.05로 이상치 비율(오염도)을 대략 5%로 가정.
-
예측된 이상치 인덱스 확인
np.where(y_pred_oc == -1),np.where(y_pred_if == -1)로 각각 이상치로 분류된 샘플의 인덱스를 찾기.- 이상치로 진단된 개수와 인덱스를 출력
-
시각화
- 2개의 서브플롯을 만들어, 하나는 One-Class SVM 결과, 다른 하나는 Isolation Forest 결과를 표시합니다.
- 이상치로 분류된 점들을 빨간색으로 강조합니다(
scatter에서 다른 색상으로 표시). - 실제론 Iris 데이터는 극단 이상치가 별로 없으므로 결과가 다소 유사하거나 적을 수 있습니다.
- 필요에 따라 인위적으로 이상 샘플을 삽입하거나, 다른 데이터셋을 사용하면 좀 더 극명한 차이를 볼 수 있습니다.
