
JPA로 개발 중에 레포에서 가져오는데 쿼리를 적게 날리고 싶었다.
일단 다 가져온 다음에 분리작업을 해서 dto 에 넣는게 더 효율적일 것 같다는 생각에 리팩토링을 진행함.
코드 비교
조건을 걸어서 해당 조건에 충족하는 데이터만 가져오려고 했다.
근데 다 가져와야하니까 3번 다 날렸다.
조건절 넣어서 쿼리 3번 날리던 기존 방법
public ResponseSchoolDto viewSchool(Long userId) {
// schoolType (HIGH, UNI, GRAD) 에 따라 리스트를 다르게 보낸다.
List<School> highSchools = schoolRepository.findByUserUserIdAndSchoolType(userId, SchoolType.HIGH);
List<School> uniSchools = schoolRepository.findByUserUserIdAndSchoolType(userId, SchoolType.UNI);
List<School> gradSchools = schoolRepository.findByUserUserIdAndSchoolType(userId, SchoolType.GRAD);
List<SchoolDto> highSchoolDtos = highSchools.stream()
.map(SchoolDto::from)
.collect(Collectors.toList());
List<SchoolDto> uniSchoolDtos = uniSchools.stream()
.map(SchoolDto::from)
.collect(Collectors.toList());
List<SchoolDto> gradSchoolDtos = gradSchools.stream()
.map(SchoolDto::from)
.collect(Collectors.toList());
return ResponseSchoolDto.builder()
.HIGH(highSchoolDtos)
.UNI(uniSchoolDtos)
.GRAD(gradSchoolDtos)
.build();
}filter() 추가
일단 다 가져온 School 리스트에서 schoolType을 가져온 후 그 아이가 내가 원하는 애면 들어가도록 해줬다.
public ResponseSchoolDto viewSchool(Long userId) {
// 한 번에 다 받아와서 filter로 구분하기
List<School> allSchools = schoolRepository.findByUserUserId(userId);
List<SchoolDto> highSchoolDtos = allSchools.stream()
.filter(school -> school.getSchoolType() == SchoolType.HIGH)
.map(SchoolDto::from)
.collect(Collectors.toList());
List<SchoolDto> uniSchoolDtos = allSchools.stream()
.filter(school -> school.getSchoolType() == SchoolType.UNI)
.map(SchoolDto::from)
.collect(Collectors.toList());
List<SchoolDto> gradSchoolDtos = allSchools.stream()
.filter(school -> school.getSchoolType() == SchoolType.GRAD)
.map(SchoolDto::from)
.collect(Collectors.toList());
return ResponseSchoolDto.builder()
.HIGH(highSchoolDtos)
.UNI(uniSchoolDtos)
.GRAD(gradSchoolDtos)
.build();
}결과
쿼리 한번으로 가져온 후 필터 처리해서 같은 결과가 나옴을 확인할 수 있따!.
쉽게 보자면 db에서 분기처리를 해서 가져오느냐, 가지고 와서 java에서 처리하느냐 차이인 듯하다.
이렇게 다 ~ 가져와야 하는 경우에는 쿼리를 3번 보내기보다는 java에서 처리하는 게 낫다고 판단해서 이렇게 리팩토링을 했다.
팀원들과 의논해 본 결과 한번에 가져올 수 있는 쿼리는 이렇게 가져오는게 당연히 맞다고 결론이 났다.

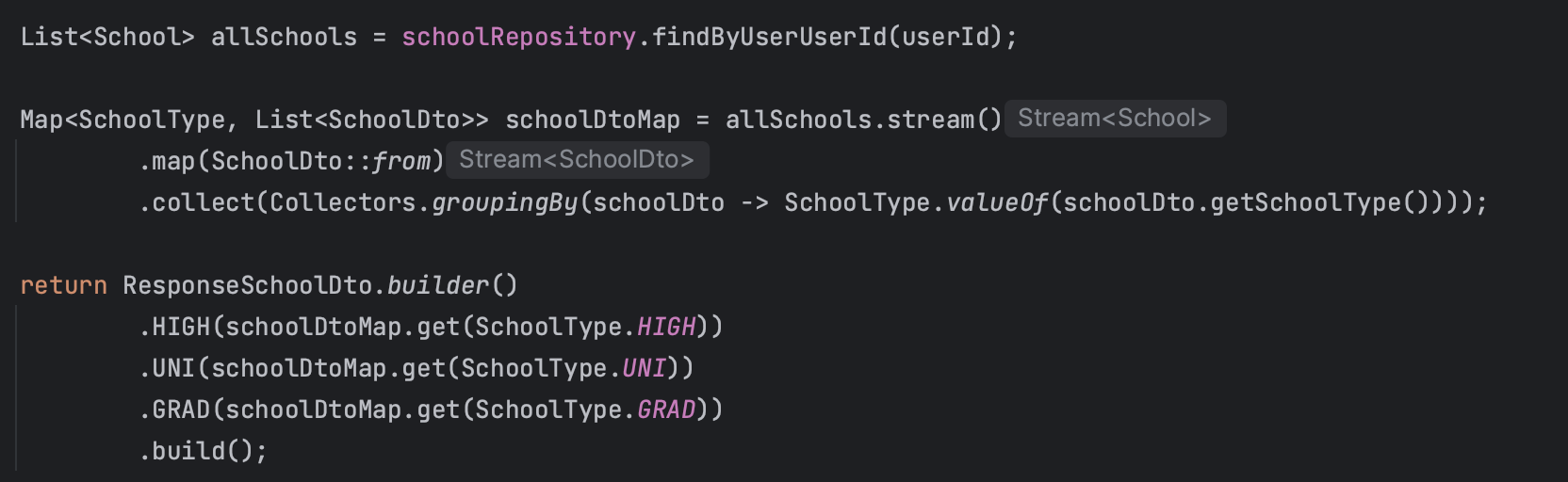
+추가로 코드 리팩토링
filter도 필요없이 코드를 짜보겠다.
위에서는 필터로 나누면서 얘가 여기면 여기! 이렇게 짰는데 <<이게 아니라
하나씩 돌면서 얘는 여기네 <<이렇게 찾게 하고 싶었다.
List<SchoolDto> highSchoolDtos = allSchools.stream()
.filter(school -> school.getSchoolType() == SchoolType.HIGH)
.map(SchoolDto::from)
.collect(Collectors.toList());
List<SchoolDto> uniSchoolDtos = allSchools.stream()
.filter(school -> school.getSchoolType() == SchoolType.UNI)
.map(SchoolDto::from)
.collect(Collectors.toList());
List<SchoolDto> gradSchoolDtos = allSchools.stream()
.filter(school -> school.getSchoolType() == SchoolType.GRAD)
.map(SchoolDto::from)
.collect(Collectors.toList());위에서 코드를 이렇게 짰는데 고민하다 GPT의 도움을 빌려봤다.
근데 개쩌는 코드가 나왔다.
무슨 컬렉션을 쓰면 되게요???
두근두근 ...
- Map 을 쓰자 !
- List.collect(Collectors.groupingBy()) 라는 것이 있단다.
// 이렇게 하면 스쿨타입별로 리스트가 각각 존재할 수 있게 된다...
Map<SchoolType, List<SchoolDto>> schoolDtoMap = allSchools.stream()
.map(SchoolDto::from)
.collect(Collectors.groupingBy(schoolDto -> SchoolType.valueOf(schoolDto.getSchoolType())));
// 그리고 리턴해줄때 get해서 꺼내가면됨. 미쳐따
return ResponseSchoolDto.builder()
.HIGH(schoolDtoMap.get(SchoolType.HIGH))
.UNI(schoolDtoMap.get(SchoolType.UNI))
.GRAD(schoolDtoMap.get(SchoolType.GRAD))
.build();현재 SchoolType 이 Enum 타입이라 그렇지 일반 변수였으면 훨씬 더 쉽게 빼냈을 것이다.
Collectors 메서드들을 잘 살피면 순환돌 때 꽤나 유용한 것이 많겠다.
결론
이번 포스팅에서는
Collection 클래스의 stream 변환부터
Stream API의 filter, map, collect 그리고
Collectors 의 groupingBy 까지 사용하면서
응답값을 처리하는 과정에 대해 알아보았다.
Collectors 클래스 이거 대단한 자식이다.
컬렉션을 잘 활용할 줄 알아야겠다. 허구한 날 List만 쓰다니 .. Map이나 Set도 자주 기억해주자!
