MySQL Driver 설치
Python 에서 MySQL 을 사용하기 위해서는 먼저 MySQL Driver 를 설치합니다.
pip install mysql-connector-python
 설치를 하고 import 를 입력해 mysql.connector 모듈을 불러옵니다.
설치를 하고 import 를 입력해 mysql.connector 모듈을 불러옵니다.
만약 모듈을 설치하는데
Requirement already satisfied 라는 문구가 뜨면 이미 설치가 되었다는 메세지입니다.
MySQL 접속
 변수를 입력하고 mysql.connector 모듈을 불러온 다음,
변수를 입력하고 mysql.connector 모듈을 불러온 다음,
connect() 함수를 사용합니다. 괄호 안에는 호스트, 사용자 이름, 비밀번호 를 입력합니다.
Local Database 연결
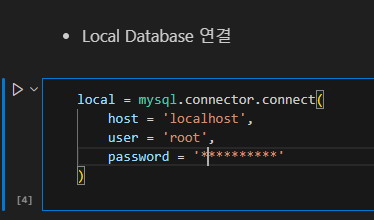 로컬로 연결할 때는 호스트에 'localhost'를 입력하면 접속이 됩니다.
로컬로 연결할 때는 호스트에 'localhost'를 입력하면 접속이 됩니다.
AWS RDS 연결
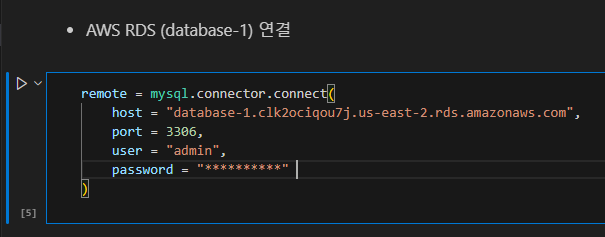 AWS RDS에 연결하려면 호스트를 엔드포인트로 입력하고
AWS RDS에 연결하려면 호스트를 엔드포인트로 입력하고
포트넘버를 추가로 입력해야 합니다.
Close Database
 사용을 다 마치고 접속했던 데이터베이스를 닫으려면
사용을 다 마치고 접속했던 데이터베이스를 닫으려면
Close() 함수를 사용합니다.
💡팁💡
접속한 데이터베이스가 많게 되면 사용자가 헷갈릴 수 있습니다.
따라서, 접속하고 사용하지 않는 데이터베이스는 닫아주는게 좋은 습관입니다.
특정 Database 접속
 MySQL 접속과 같은 방법입니다.
MySQL 접속과 같은 방법입니다.
여기에 접속하기 원하는 데이터베이스를 추가합니다.
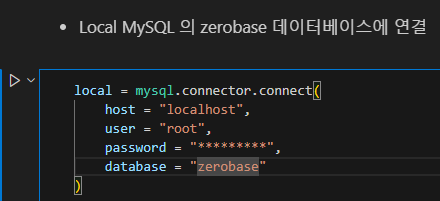 mysql -u root -p password database 와 같은 원리입니다.
mysql -u root -p password database 와 같은 원리입니다.
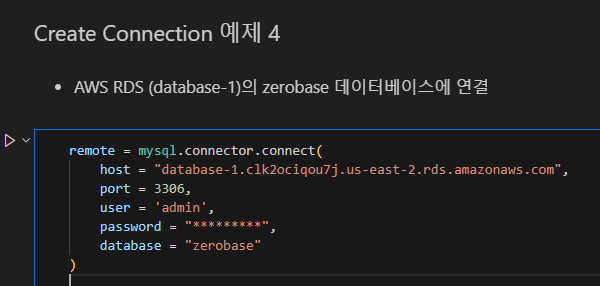
mysql -h <엔드포인트> -P <포트> -u <마스터 사용자 이름>
-p <패스워드> <데이터베이스 이름> 과 같은 원리입니다.
Execute SQL
작성한 쿼리를 실행하기 위해 cursor() 매서드를 사용합니다.
그리고 cursor()를 실행하기 위해 execute() 매서드를 사용합니다.
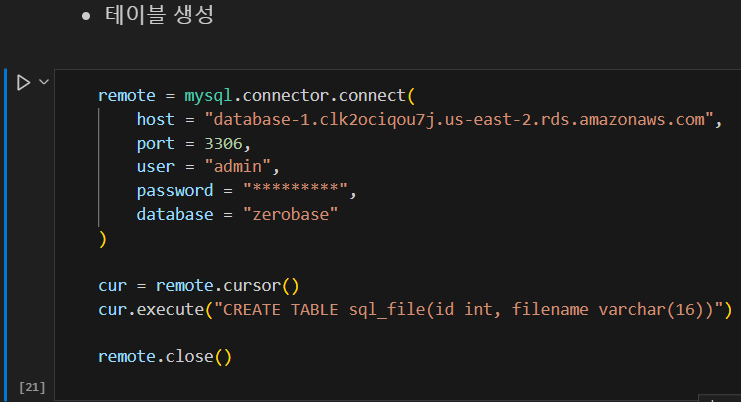 매서드를 사용해 sql_file이라는 테이블을 생성, id, filename 컬럼추가,
매서드를 사용해 sql_file이라는 테이블을 생성, id, filename 컬럼추가,
타입 설정을 실행하는 것을 볼 수 있습니다.
커서가 무엇인지 자세한 내용은 링크를 참고하시길 바랍니다.
https://cobook.tistory.com/93#%--%EC%BB%A-%EC%--%-C%C-%A--CURSOR-
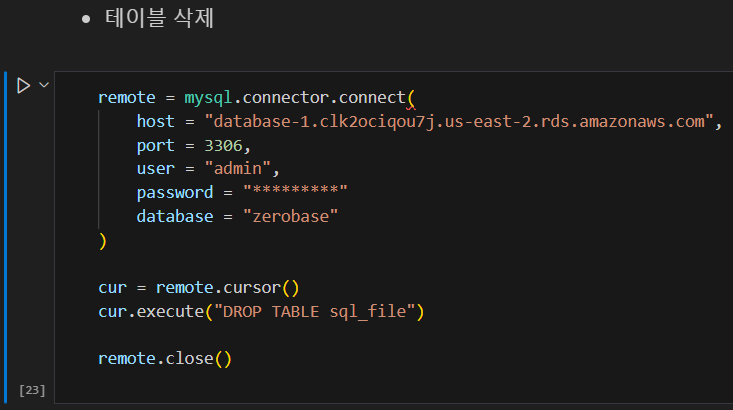 매서드를 사용해 sql_file이라는 테이블을 삭제하는 것을 볼 수 있습니다.
매서드를 사용해 sql_file이라는 테이블을 삭제하는 것을 볼 수 있습니다.
Execute SQL file 1
SQL 파일을 생성해서 불러오는 방법도 있습니다.
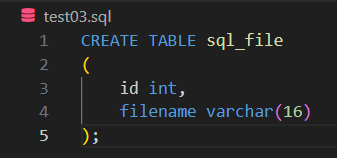 test03 이라는 새로운 sql 파일을 생성하고,
test03 이라는 새로운 sql 파일을 생성하고,
sql_file 이라는 테이블을 생성합니다.
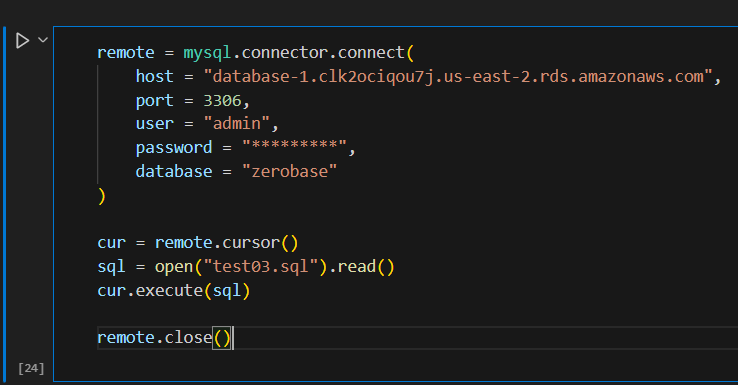 AWS RDS에 접속 후 쿼리 작성,
AWS RDS에 접속 후 쿼리 작성,
SQL 파일을 불러오기 위해 open(), 읽기 위해 read() 매서드를 사용합니다.
그리고 작성한 쿼리를 실행하기 위해 cursor(), execute() 매서드를 사용합니다.
**현재는 같은 경로에 test03 파일이 있어서 파일 이름만 적었지만
파일의 경로가 다르면 그 경로도 입력해주어야 합니다.**
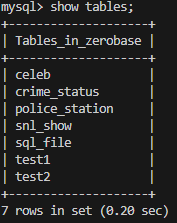
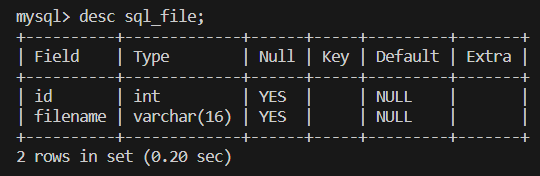 sql 파일이 설정한 타입 그대로 테이블로 생성된 것을 볼 수 있습니다.
sql 파일이 설정한 타입 그대로 테이블로 생성된 것을 볼 수 있습니다.
Execute SQL file 2
SQL 파일에 쿼리가 여러 개 존재하는 경우가 있습니다.
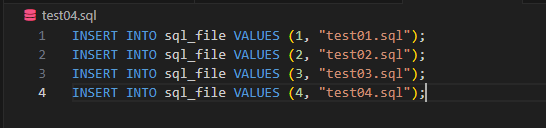
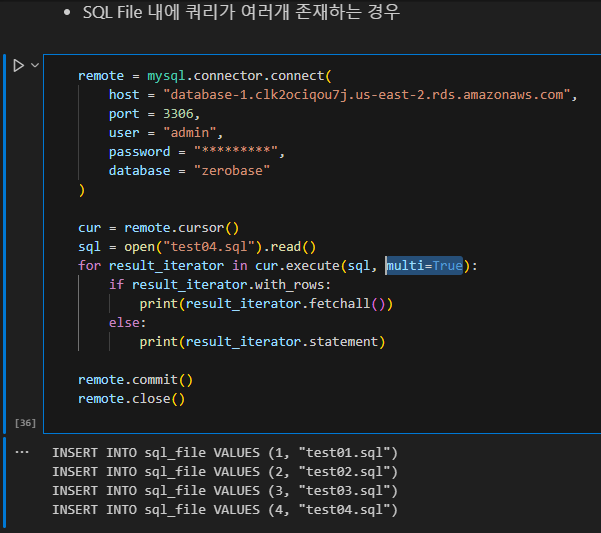 이 때는 execute() 매서드에 multi=true 옵션을 부여합니다.
이 때는 execute() 매서드에 multi=true 옵션을 부여합니다.
multi True는 쿼리문이 여러개일 때 인식시켜주는 함수로 보입니다.
그리고 execute() 매서드 만으로는 SQL테이블에 입력(변화)가 일어나지 않기 때문에
commit() 매서드를 사용해서 SQL테이블 데이터에 변화를 주도록 합니다.
COMMIT() : 테이블 데이터의 변화, 적용을 지시합니다
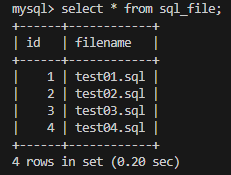 테이블 안에 데이터가 추가적으로 들어간 것을 볼 수 있습니다.
테이블 안에 데이터가 추가적으로 들어간 것을 볼 수 있습니다.
Fetch ALL
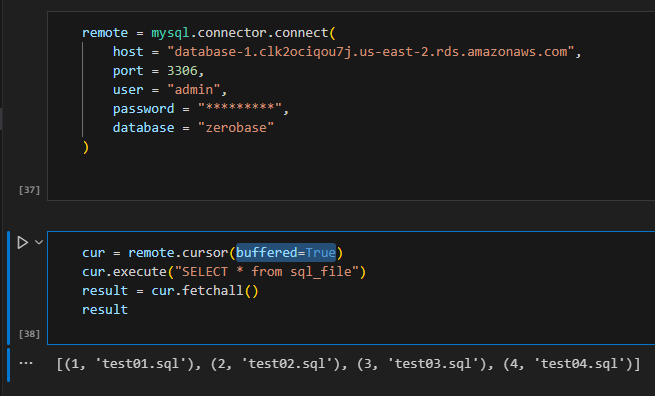 AWS RDS에 접속 후 쿼리를 작성합니다.
AWS RDS에 접속 후 쿼리를 작성합니다.
테이블의 데이터를 조회, 검색하려고 하지만 읽어올 데이터 양이 많은 경우가 있습니다.
이 때, cursor() 생성 시 buffered=True 라는 버퍼 옵션을 줍니다.
그리고 필요한 테이블의 정보를 가져오도록 fetchall() 매서드를 사용해
결과값(정보)을 조회할 수 있습니다.
fetchall() : 결과값이 row를 포함하고 있는 쿼리를 조회합니다.
결과를 확인해보니,
데이터가 튜플 형태와 바깥에는 리스트 형태로 담겨져있는 것을 볼 수 있습니다.
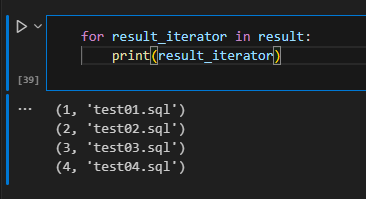
즉, 리스트 형태니까 변수선언이 가능하며 반복문 사용이 가능합니다.
