컴퓨터에서의 데이터 표현
- 컴퓨터 내부(Memory, Register)에서 데이터가 표현되는 방식을 이해하는 것은 매우 중요합니다.
- Byte Ordering
- 프로그램 소스코드
- 프로그램 실행코드
- char
- int, short int, long int
- float, double
- type casting
- 연산
바이트 값의 인코딩
- 1 Byte = 8 bits
- 00000000 to 11111111
- 0 to 2554
- 00 to FF
'0' to '9' and 'A' to 'F' (16진법)
FA1D37B는 C에서 다음과 같이 표시합니다.
- 0xFA1D37B
- 0xfa1d37b
컴퓨터의 워드 길이
- 정수 값의 크기를 말합니다. (주소의 길이가 되기도 하고요)
- 요즘 대부분은 64bit(8byte) 워드입니다.
- 32bit의 경우 주소 범위가 4 GB로 제한됩니다.
- 메모리가 많이 필요한 프로그램에서는 제약이 될 수 있습니다.
- 64bit 워드 컴퓨터는
- 가용 주소 공간 ≈ bytes
- x86-64 컴퓨터는 48bit 주소를 지원합니다. (256 TB)
- 컴퓨터는 다양한 데이터 타입을 지원합니다.
- 워드의 일부분 또는 여러 워드 길이의 데이터 타입
- 모든 데이터 타입은 바이트의 배수를 길이로 갖습니다.
워드 기반 메모리 구조
주소는 메모리에서 바이트의 위치를 지정
- 워드의 첫번째 바이트의 위치를 지정하고
- 연속된 워드의 주소는 4 또는 8 씩 증가합니다.
CPU의 메모리 할당 요청
32-bit: 4 bytes 할당
64-bit: 8 bytes 할당
Byte Ordering
여러 바이트로 이루어진 데이터는 어떤 순서로 저장되는가?
- Sun, Mac, 인터넷: "Big Endian"
- LSB가 최대 주소의 위치에 기록됩니다
- x86, Android, IOS, Window를 실행하는 ARM processor: "Little Endian"
- LSB가 최소 주소의 위치에 기록됩니다
Example
-
변수 x는 다음과 같은 4 bytes의 워드이다: 0x01234567
-
x의 주소 &x는 현재 0x100이다
-
Big Endian:
0x100: 01
0x101: 23
0x102: 45
0x103: 67 -
Little Endian:
0x100: 67
0x101: 45
0x102: 23
0x103: 01
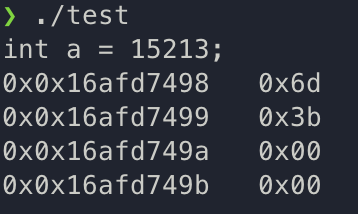
Linux에서 바이트의 출력
데이터를 바이트로 출력해주는 프로그램 작성
typedef unsigned char *pointer;
void show_bytes(pointer start, int len) {
int i;
for (i = 0; i < len; i++) {
printf("0x%p\t0x%.2x\n", start + i, start[i]);
}
/* Printf Directives
%p: Print Pointer
%x: Print Hexadecimal */
printf("\n");
}
int main() {
int a = 15213;
printf("int a = 15213;\n");
show_bytes((pointer) &a, sizeof(int));
return 0;
}Result
C언어에서의 비트 수준 연산
비트 연산자 (&, |, ~, ^)
- 정수형 연산자에 적용 가능
- 인자들을 비트 벡터로 처리
- 인자들은 비트들끼리 연산
C언어에서의 논리 연산
비트 수준 연산자와는 다름
&& vs &, || vs |
&&, ||, !
- 0은 거짓으로 처리
- 0이 아닌 값들은 모두 참으로 처리
- 연산의 결과는 0 또는 1
- 수식의 결과가 첫번째 인자를 계산해 결정될 수 있으면 두 번째 인자는 계산하지 않습니다.
Shift 연산
Left Shift: x << y
- 비트벡터 x를 왼쪽으로 y 위치만큼 이동
- 왼쪽에 있던 비트들은 사라집니다.
- 오른쪽은 0으로 채웁니다.
Righe Shift: x >> y
- 비트벡터 x를 오른쪽으로 y위치만큼 이동
- 오른쪽에 있던 비트들이 없어집니다.
- Logical Shift
- 왼쪽을 0으로 채웁니다.
- Arithmetic Shift
- MSB를 복제합니다.
- Undefined Behavior
- shift의 크기가 음수이거나 word 길이보다 큰 경우는 undefined behavior 입니다.
