
안녕하세요. 제가 오늘은 제가 배우고 있는 헬스케어 쪽으로 테이블을 만들고, 이해와 활용을 기반으로 한번 떠들어 제껴보도록 하겠습니다.
GOAL
- 다중 테이블 JOIN (INNER/LEFT/RIGHT/FULL) 이해 & 활용
- GROUP BY / HAVING 집계와 조건
- 서브쿼리로 복잡한 문제 쪼개기
먼저, 대학병원이나 진료과들이 여럿 있는 병원에서 '예약 테이블', '의사 테이블', '환자 테이블' 3가지로 나누어서 각각 다른 테이블로 저장하고 관리가 진행이 된다고 해봅시다.
<예약 테이블>
| doctor_id | name | specialty |
|---|---|---|
| 1 | 김오즈 | 외과 |
| 2 | 오스타 | 내과 |
| 3 | 정우성 | 피부과 |
<의사 테이블>
| appointment_id | patient_id | doctor_id | visit_date |
|---|---|---|---|
| 1001 | 1 | 1 | 2025-10-25 |
| 1002 | 2 | 2 | 2025-10-26 |
| 1003 | 3 | 1 | 2025-10-26 |
| 1003 | 4 | 55 | 2025-10-27 |
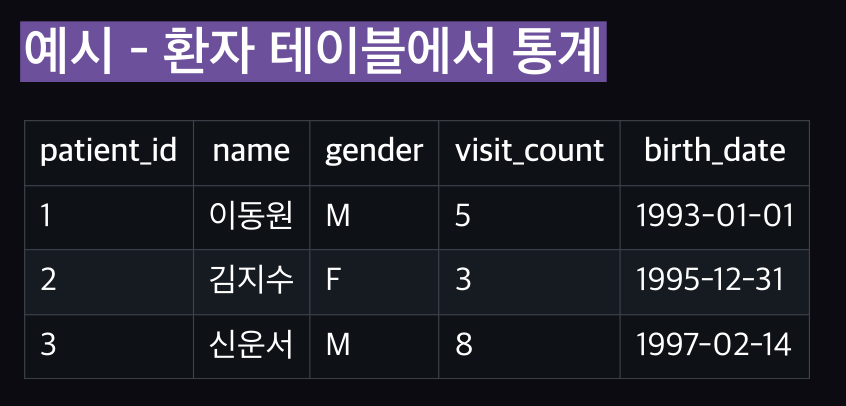
<환자 테이블>
| patient_id | name | gender | visit_count | birth_date |
|---|---|---|---|---|
| 1 | 류현진 | M | 7 | 1987.03.25 |
| 2 | 홍지수 | F | 15 | 2000.07.13 |
| 3 | 문동주 | M | 3 | 2003.12.23 |
이렇게 테이블이 각가 있으면 수정과 보관 (유지/보수라고 보통 얘기함)이 편합니다.
근데 편한 대신에 내가 원하는 정보가 만약 진료 기록과 의사 정보를 알고 싶은데, 이는 한 테이블에 같이 있지 않고 떨어져 있습니다.
예약 테이블(appoinments)에 의사 ID만 있고, 이름이 없습니다. 테이블 하나로 내가 원하는 정보(컬럼)만 깔끔하게 정리되어 있는걸 보고 싶을 때, 'JOIN'을 시키면 말끔히 해결이 됩니다.
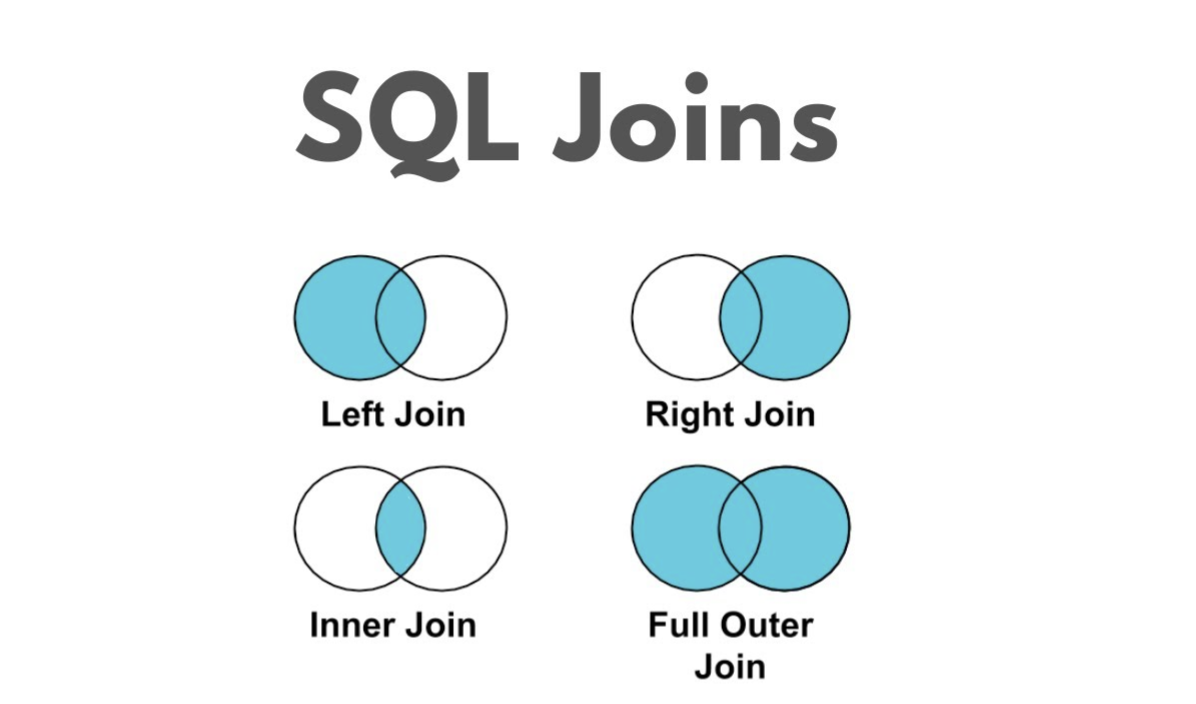
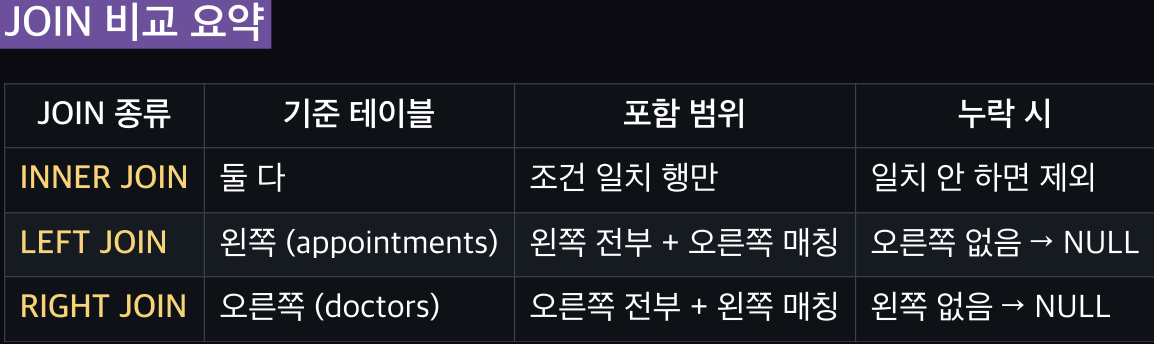
JOIN 개요
| 타입 | 설명 | 결과 |
|---|---|---|
| INNER JOIN | 양쪽 모두 매칭되는 행만 | 교집합 |
| LEFT JOIN | 왼쪽 모두 + 매칭 | 왼쪽 기준 |
| RIGHT JOIN | 오른쪽 모두 + 매칭 | 오른쪽 기준 |
AS의 개요
AS는 SQL에서 컬럼명이나 테이블명에 ‘별칭(alias)’을 붙이는 키워드 
INNER JOIN (내부 조인)

조건에 일치하는 행만가져온다. (모두 매칭 된 데이터만 표시)
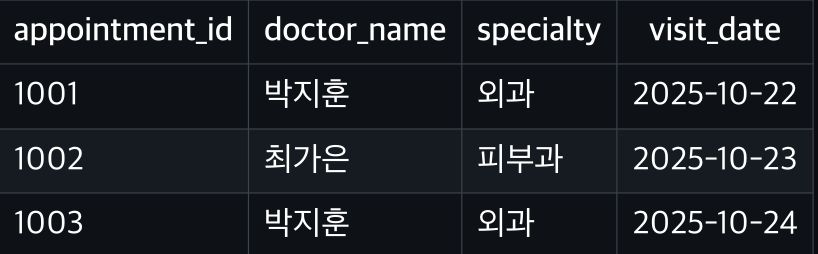
1004번 예약(doctor_id=99)은 doctors에 없으므로 제외
정우성(doctor_id=3)은 appointments에 없으므로 제외
LEFT JOIN (왼쪽 우선)
왼쪽(appointments)의 모든 데이터를 유지
오른쪽(doctor)에서 매칭 안 되면 NULL

실행하면
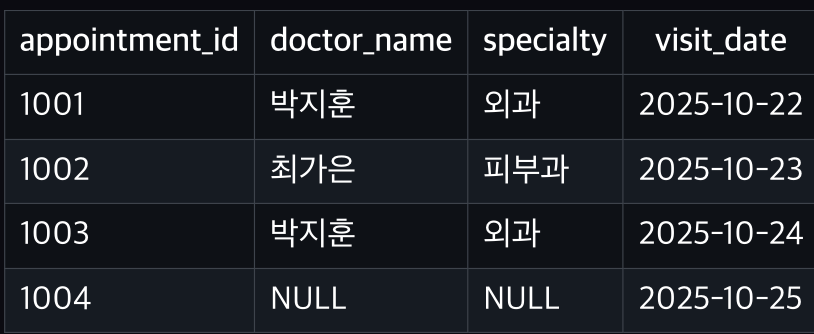
appointments는 전부 출력됨
→ doctor_id=99는 doctors에 없어서 NULL
RIGHT JOIN (오른쪽 우선)
오른쪽(doctors)의 모든 데이터를 유지
왼쪽(appointments)에서 매칭 안 되면 NULL

실행하면,
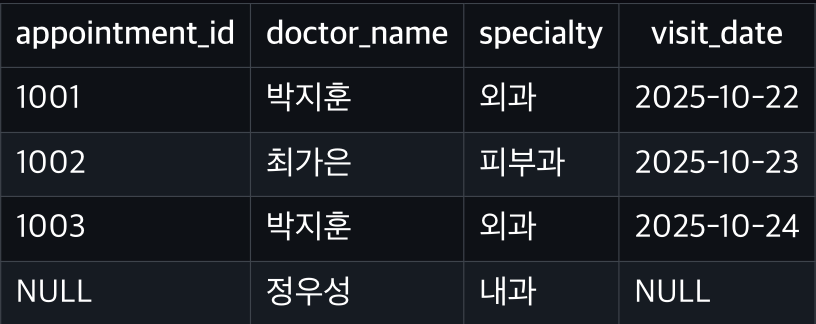
doctors는 전부 출력됨
→ 정우성(doctor_id=3)은 예약이 없으므로 appointment_id와 visit_date가 NULL
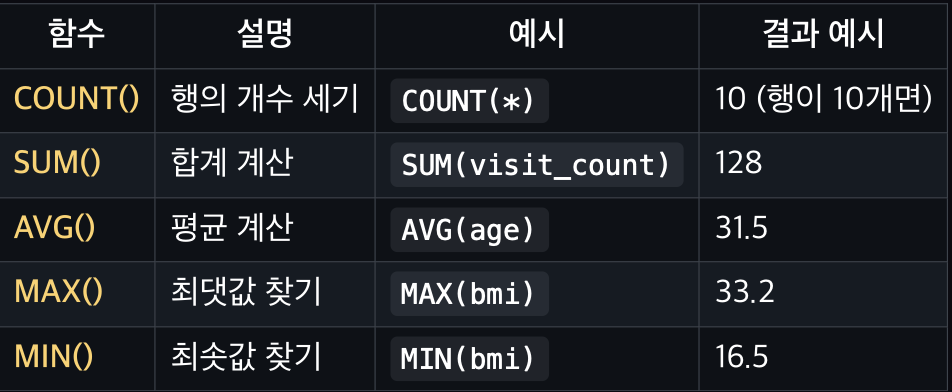
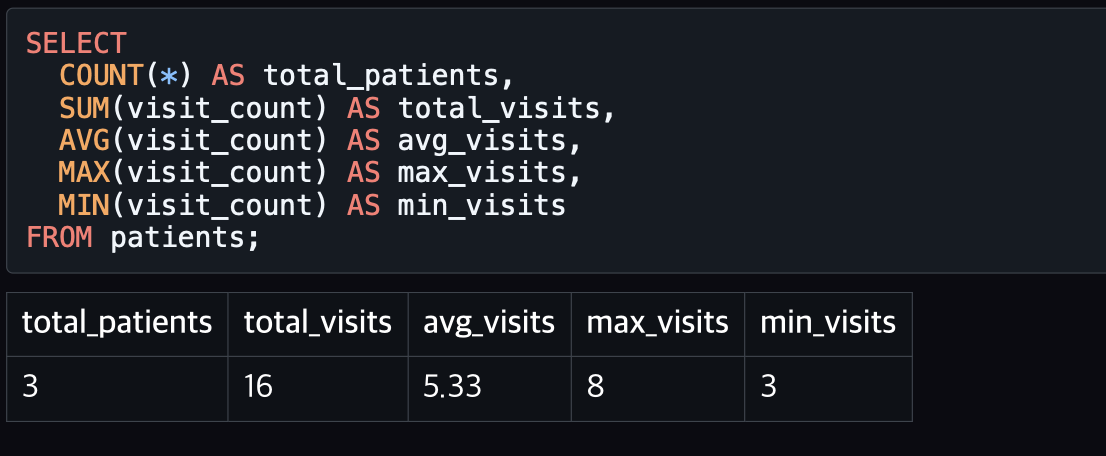
집계 함수(Aggregate Function)란?
- 여러 행 (Row)을 하나의 통계값으로 요약하는 함수
예를 들어 “진료 건수”, “환자 수 ”, “평균 BMI”, “가장 최근 방문 일” 등
주요 집계 함수
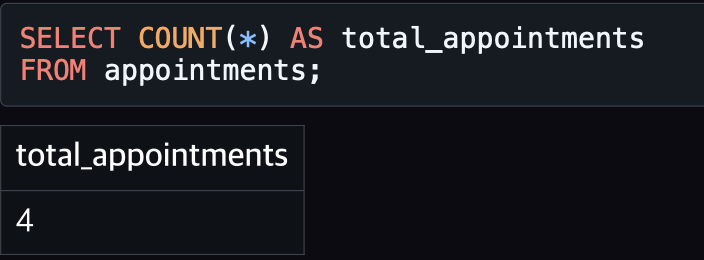
COUNT()
진료 전체 건수
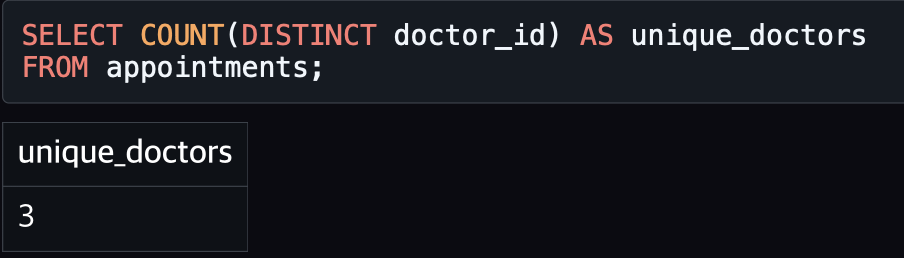
COUNT(DISTINCT 컬럼명) — 중복 제거 후 개수
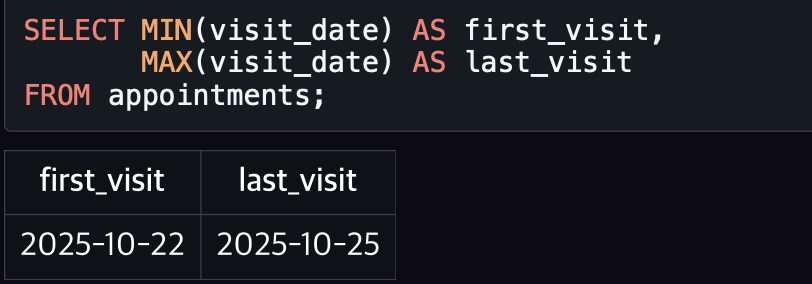
MIN()/ MAX()
전체 진료 기록 중에서 첫 방문일과 마지막 방문일을 구함
평균, 합계, 최대, 최소
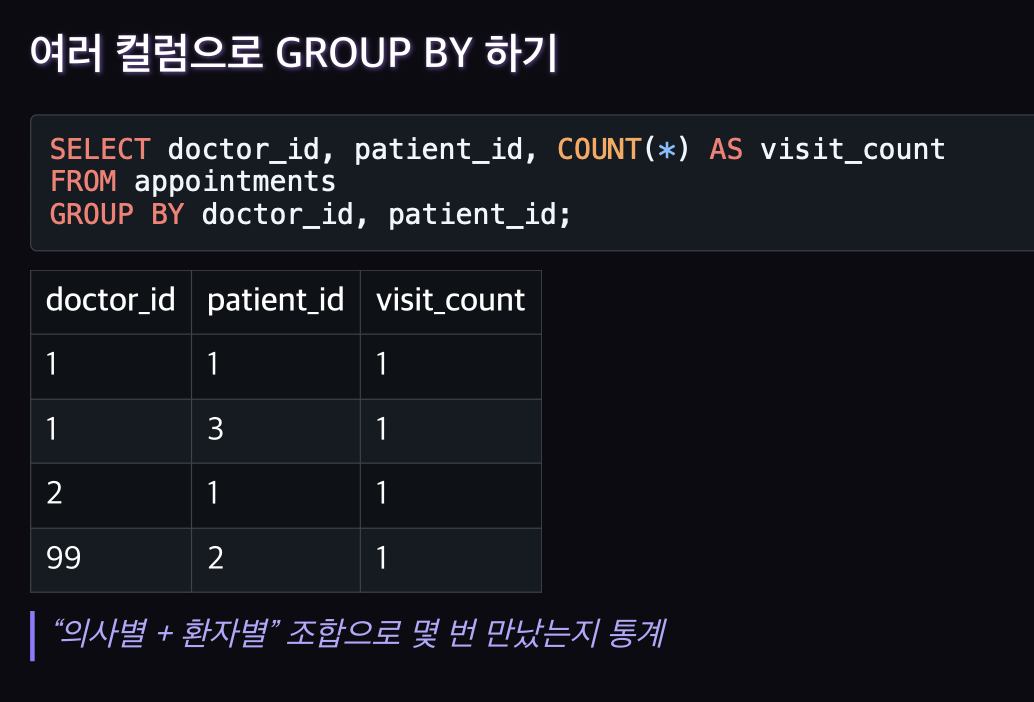
GROUP BY란?
공통된 값을 가진 행(Row)들을 하나의 그룹으로 묶어 그룹별로 집계함수를 적용하는 문법

GROUP BY = “무엇을 기준으로 묶을지”
COUNT(), SUM(), AVG() 등 집계함수 = “묶인 그룹에 어떤 통계를 낼지”

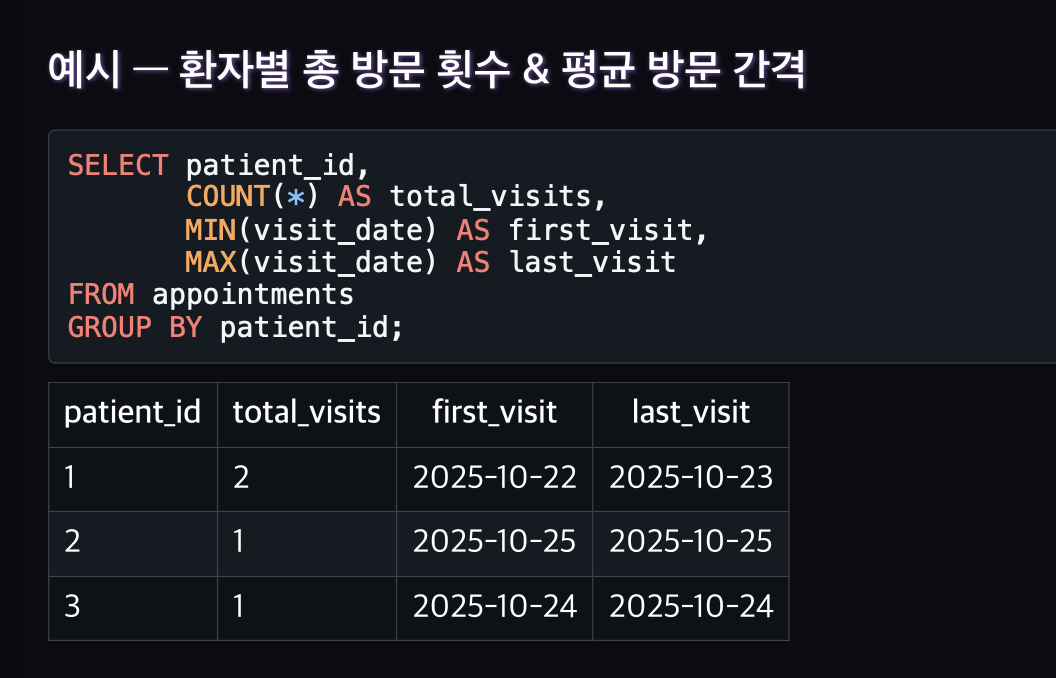
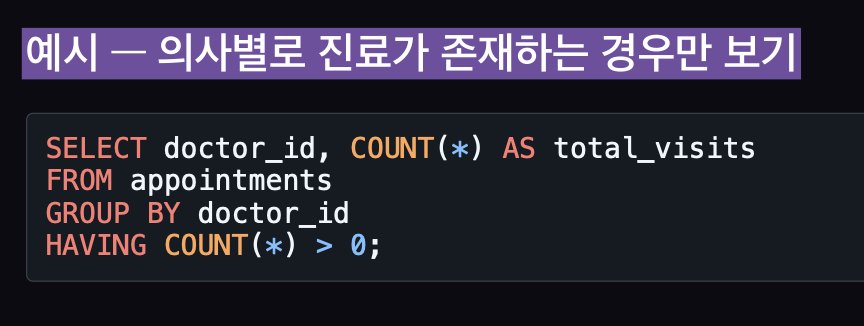
HAVING절
HAVING은 WHERE처럼 조건을 거는 역할을 하지만,
집계된 결과(그룹 이후)에 필터를 거는 문법

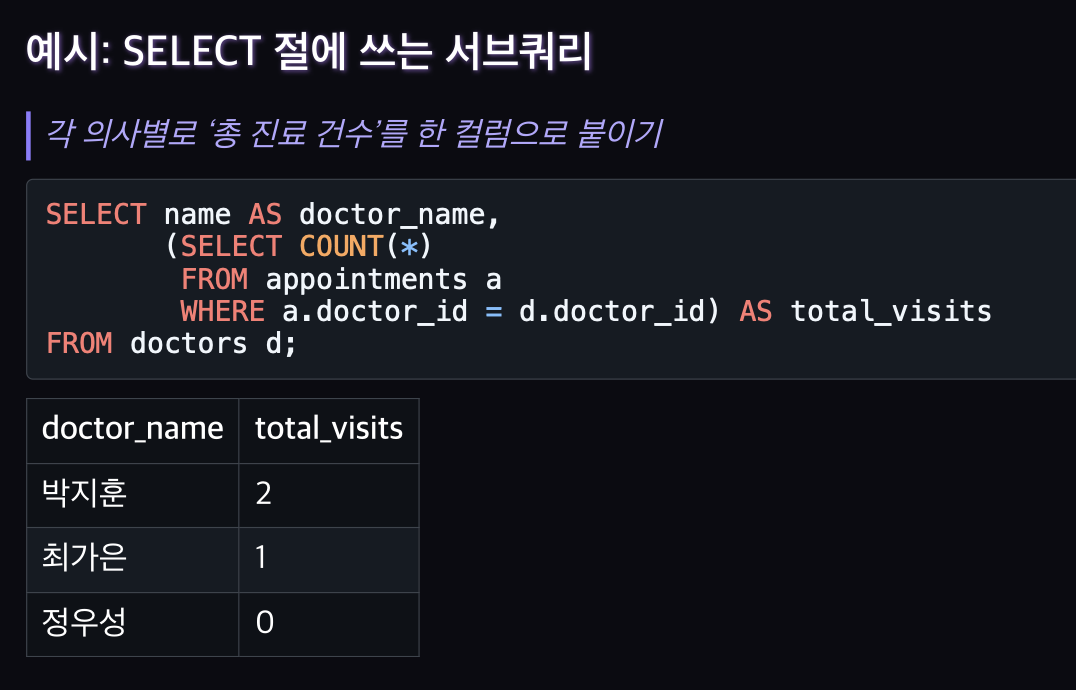
서브쿼리(Subquery)
쿼리 안에 또 다른 쿼리를 넣는 것.
복잡한 조건이나 계산을 간결하게 표현할 수 있다.





오랜만에 글을 올려보아용 ㅎ 며칠동안 할 일이 좀 있어서...예 글쓰러 잘 못 왔습니다ㅠㅠ
꾸준히 오는게 제일 베스트긴 한데 마음처럼 그게 잘 안되네요 ㅜㅜ
지금 다른 것들도 일을 벌리고 있는 중이라 그게 끝나면 바로 다시 오도록 하겠습니다!!
