
안녕하세요! 머신러닝을 공부하다 보면 꼭 만나게 되는 모델인 SVM(Support Vector Machine)은 이름부터 서포트, 벡터, 머신… 뭔가 강력해 보이는데, 막상 원리를 파고들면 수식이 많아서 지레 겁먹기 쉬운 친구이기도 합니다. 저도 처음엔 그냥 분류하는 모델 중 하나라고만 생각했는데, 왜 SVM이 오랫동안 사랑받아왔는지 그 핵심 아이디어를 알고 나니 정말 매력적인 모델이라는 걸 깨달았습니다.
📍 오늘 이야기의 핵심 키워드
1. 최대 마진 (Maximal Margin) : SVM이 추구하는 단 하나의 목표, 경계선과 데이터 사이의 거리를 최대로!
2. SVM (Support Vector Machine) : 데이터를 가장 잘 나누는 최적의 경계선을 찾는 알고리즘
3. 서포트 벡터 (Support Vectors) : 이 경계선을 결정하는 가장 중요한 핵심 데이터들
4. 결정 경계 (Decision Boundary) : 두 그룹을 나누는 기준선
5. 라그랑주 듀얼 (Lagrange Dual Formulation) : 커널 트릭 (Kernel Trick)으로 직선으로 나눌 수 없는 데이터들을 마법처럼 나눠주는 비결
- 가장 '안전한' 경계선 긋기 (Maximal Margin)
자, 우리에게 빨간 점과 파란 사각형을 나누는 임무가 주어졌다고 해봅시다.
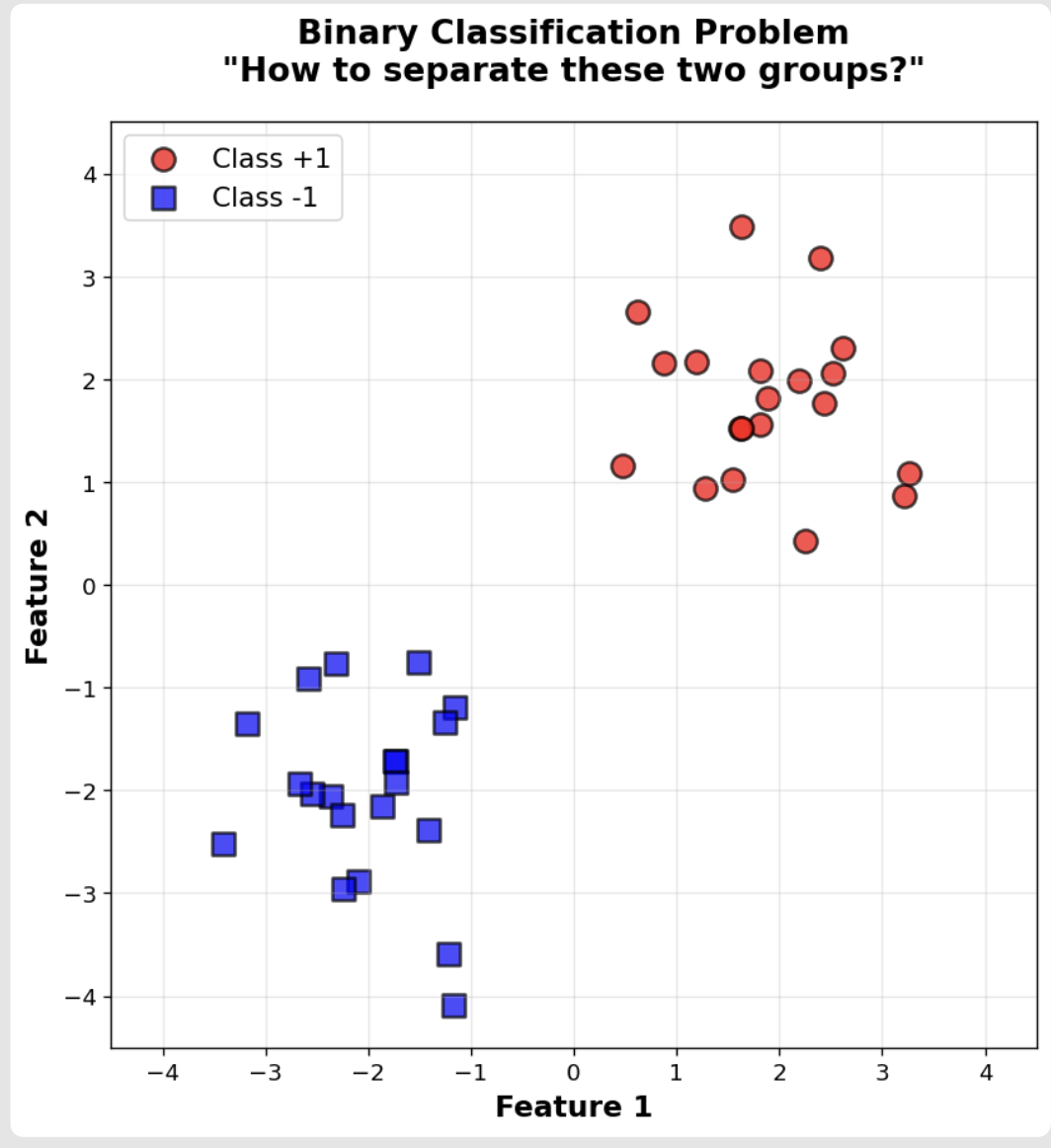
어떻게 선을 그으시겠어요? 사실 두 그룹을 나누는 선은 무한히 많이 그릴 수 있죠.
하지만 SVM은 그중에서도 가장 좋은 선을 찾고 싶어 합니다. 그럼 대체 '좋은 선'이란 뭘까요?
나쁜 선: 데이터에 너무 아슬아슬하게 붙어있는 선. 이런 선은 나중에 새로운 데이터가 조금만 다르게 들어와도 잘못 분류할 위험(Overfitting)이 큽니다.
좋은 선 (SVM이 찾는 선): 양쪽 그룹의 데이터로부터 최대한 멀리 떨어져 '안전거리(Margin)'를 확보한 선입니다.
SVM은 이 '안전거리', 즉 마진(Margin)을 최대화 하는 것을 유일한 목표로 삼습니다. 마진이 넓을수록 새로운 데이터가 들어와도 안정적으로 분류할 수 있으니까요. 이걸 바로 'Maximal Margin Classifier'라고 부릅니다.
- 경계선을 결정하는 핵심 용병, 서포트 벡터 (Support Vectors)
그럼 이 최대 마진은 어떻게 정해질까요? 여기서 SVM의 이름이기도 한 서포트 벡터(Support Vectors)가 등장합니다.
서포트 벡터란, 우리가 그린 결정 경계선과 가장 가까이에 있는, 즉, 마진 경계선 위에 정확히 위치한 데이터들을 말합니다. 비유하자면, 이 서포트 벡터들은 마진이라는 다리를 떠받치는 기둥 같은 존재예요. 이 서포트 벡터들만이 경계선을 결정하는 데 영향을 준다는 사실입니다. 경계선에서 멀리 떨어져 있는 나머지 90~95%의 평범한 데이터들은 아무리 많아도 경계선 위치에 1도 영향을 주지 않습니다. SVM은 전체 데이터의 5~10% 정도밖에 안되는 이 핵심 용병(서포트 벡터)들만 붙잡고 "너희들로부터 가장 멀리 떨어지는 선을 그릴게!"라고 말하는 것과 같습니다.
그 두 클래스로 나누는 선(또는 평면(3D) 또는 초평면(고차원))을 Decision Boundary (결정 경계)라고 합니다.
수학이 마법을 부리는 순간 (Dual & Kernel)좋아요, 마진을 최대로 하고 서포트 벡터가 중요하다는 건 알겠어요. 근데 그걸 컴퓨터가 어떻게 찾죠?
당연히 수학으로 풉니다. SVM은 마진을 최대로 하라!는 목표를 ||w|| (w의 크기)를 최소화하는 수학 문제로 바꿔서 풉니다. 마진의 폭이 2/||w||라서, ||w||가 작아질수록 마진은 커지거든요!
그런데 여기서 똑똑한 수학자들이 한 가지 묘안을 더 냅니다. 바로 '라그랑주 듀얼(Lagrange Dual Formulation)'이라는 방법인데요.
이게 왜 필요하냐면,
1. 고차원 데이터에 엄청나게 효율적입니다.
우리가 다루는 데이터가(키, 몸무게)처럼 2차원(d=2)이면 좋겠지만, 만약 수만 픽셀짜리 이미지 데이터라면 d가 수만 개가 됩니다. 기존의 Primal 방식은 이 d의 개수에 따라 계산량이 폭증하는데, Dual 방식은 데이터의 개수(n)에만 의존해요. 특징(차원)이 100만 개라도 데이터가 1000개뿐이라면(d >> n), Dual 방식이 압도적으로 빠릅니다.
- 커널 트릭이라는 마법을 쓸 수 있게 해줍니다.
만약 데이터가 직선(선형)으로 도저히 나눌 수 없는 복잡한 형태라면 어떡할까요? 커널 트릭은 이 데이터들을 더 높은 차원(예: 2D -> 3D)으로 순간이동시켜서, 그곳에서는 깔끔하게 평면으로 나눌 수 있게 해줍니다. Dual 방식은 이 커널 트릭을 적용하기에 완벽한 형태를 갖추고 있죠.
SVM 전체 과정 요약
1단계: 데이터를 보고 최적화 문제 설정
↓
2단계: 문제를 Dual 형태로 변환 (커널 트릭 준비)
↓
3단계: 최적화 알고리즘으로 해결
↓
4단계: Support Vector 찾기
↓
5단계: 경계선 완성!
전체 내용 정리
Part 1: SVM의 핵심
• Margin을 최대한 크게 만드는 경계선 찾기
• 큰 Margin = 좋은 일반화 성능
Part 2: 핵심 아이디어
• Support Vector: Margin 위의 핵심 데이터
• 최적화 문제로 최적의 경계선 찾기
Part 3: 더 강력하게
• 커널 트릭: 비선형 문제 해결
• Dual 문제: 커널 트릭을 사용하기 위해 필요
Part 4: 작동 원리
• Lagrangian: 문제를 변환하는 방법
• α 값으로 Support Vector 찾기
Scikit-learn으로 SVM 사용는 실습

실행하면
이러한 결과를 얻을 수 있습니다. 클래스가 0과 1로 나뉘는걸 볼 수 있습니다.
X_test에 총 30개의 데이터가 있었기 때문에(test_size=0.3), 모델도 30개의 답(예측값)을 순서대로 쫙 내놓은 거예요. 그 결과로 출력값은 "학습을 마친 모델이, 처음 보는 테스트 데이터(X_test)가 어떤 클래스(0 또는 1)에 속할지 예측한 결과"입니다.
이 예측값(predictions)이 있으니, 이제 우리는 실제 정답(y_test)과 비교해서 모델이 얼마나 잘 맞혔는지 채점을 할 수 있겠죠? 그게 바로 모델의 성능 평가가 됩니다!
model.predict()로 모델의 예측 답안을 봤다면, 다음 코드는 모델이 "어떻게 그런 답을 낼 수 있었는지" 그 근거가 되는 핵심 증거 자료를 보여주는 시각화 과정이에요.
실행하면
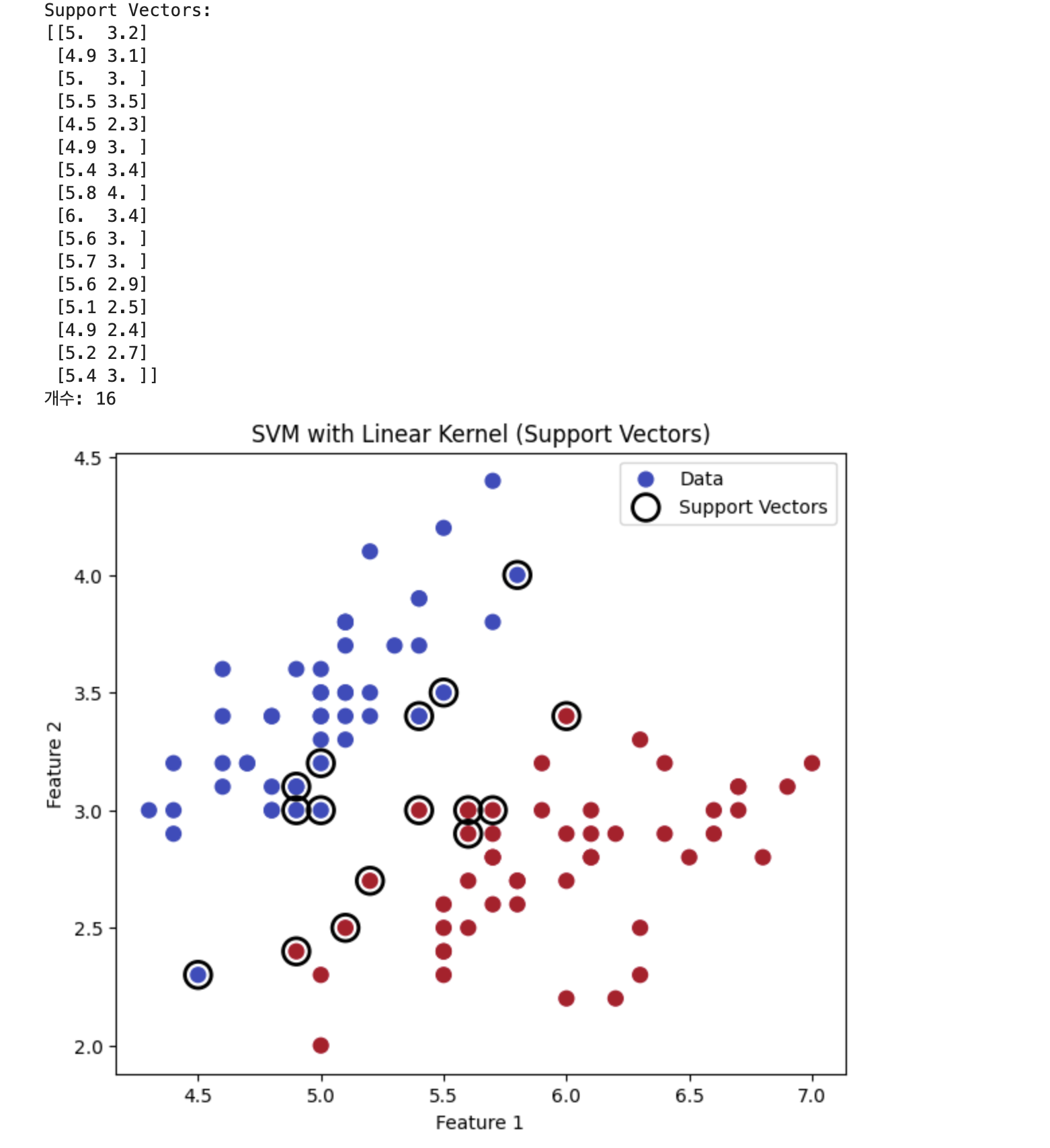
이러한 결과를 얻게 됩니다.
위에 print문은 핵심 데이터(서포트 벡터)들의 실제 좌표값과 중요한 점이 총 몇 개인지 개수를 알려줍니다.
그리고 시각화에서는 그 점들이 어디에 있는지 확인시켜 줍니다. 이 코드를 실행하면, 전체 데이터 중에서 유독 검은색 테두리가 쳐진 특별한 점들이 보일 겁니다.
바로 그 점들이 SVM이 분류 경계선을 결정하기 위해 기둥으로 삼은 서포트 벡터입니다. 이 시각화를 통해 "아, 정말로 두 그룹의 경계선에 가장 아슬아슬하게 붙어있는 점들(서포트 벡터)을 이용해서 경계선을 만드는구나!"라는 SVM의 핵심 원리를 직접 눈으로 검증할 수 있게 됩니다.

오늘 내과 진료 보고 왔다가 약국 들려서 약 처방 받는데 텐텐이 눈앞에 보여서 flex- 손으로 여러개 칵 집어서
계산해벌임 나름 므찐 어른 흉내 내봄
