Background
Pytorch에서는 tensor의 requires_grad=True 일 때, 연산의 자동미분을 지원한다. tensor를 생성할 때 requires_grad=False 이기 때문에 requires_grad=True임을 명시해줘야 한다.
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
Q = 3*a**3 - b**2
external_grad = torch.tensor([1., 1.])
Q.backward(gradient=external_grad)
print(a.grad) # tensor([36., 81.])
print(b.grad) # tensor([-12., -8.])Q.backward(gradient=external_grad)는 'Q를 계산하면서 사용된 변수의 gradient를 구해서 각 변수에 저장하세요' 라는 의미이다.- backward의 파라미터인 gradient에는 최종 연산 결과인 Q 자기 자신에 대한 변화율이 들어간다.
- 따라서 Q와 gradient의 모양은 같아야 한다.
- 벡터의 각 원소에 대한 가중치를 다르게 설정할 수도 있다. [1., 2.]로 설정하면, 첫번째 원소는 1, 두번째 원소는 2만큼의 가중치가 더해져 Q에서 사용된 파라미터 변수의 grad에 적용된다.
- backward연산을 하는 마지막 식이 scalar식이면 gradient 속성을 None으로 할 수 있다.(명시하지 않다도 된다.)
y.sum().backward()이렇게 임의로 sum()으로 scalar값을 만들면 gradient 속성을 명시하지 않아도 된다.
Chain Rule
위 규칙을 이용하여 z식에서 x에 대한 미분계수를 구할 수 있다.
x = torch.ones(2, 2, requires_grad=True)
print(x)
y = x * 2
z = y * y
# dz/dx = dz/dy * dy/dx = 2y * 2 = 8x
z.sum().backward()
print(x.grad)
# tensor([[1., 1.],
# [1., 1.]], requires_grad=True)
# tensor([[8., 8.],
# [8., 8.]])신경망에서 autograd를 이용하여 loss function에서 각 parameter의 gradient를 쉽게 구할 수 있다.
Computational Graph
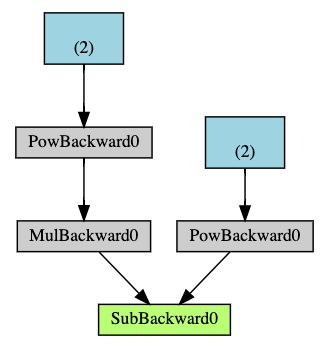
autograd는 tensor의 모든 연산을 위 그림과 같은 형태의 방향성 비순환 그래프(DAG; Directed Acyclic Graph)로 기록한다. 화살표 방향은 순전파 방향과 동일하다.
root인 연두색 노드에서 .backward()가 호출되면 chain rule을 이용하여 파랑색 leaf node까지 역전파가 일어난다.
이 그래프는 Dynamic하다. Dynamic하다는 것은 미리 그래프를 정의하고 연산하는 것이 아니라, 그래프는 실행 시점에 생성된다는 것이다.
한 번의 forward에 하나의 그래프가 만들어지고 backward시 그래프가 초기화된다.
이는 Pytorch가 가지고 있는 Tensorflow, Keras와 구분되는 특징이다.
No-grad Mode
with torch.no_grad()으로 no-grad mode로 진입해 이 구역 안에서 생성된 tensor는 gradient를 기록하지 않는다.
x = torch.ones(2, 2, requires_grad=True)
y = x * 2
print(y.requires_grad) # True
with torch.no_grad():
y = x * 2
print(y.requires_grad) # False- gradient를 기록할 필요가 없을 때 사용하면 메모리를 절약할 수 있다.
- 모델을 validation, inference 할 때 주로 쓰인다.
reference

What's on your mind?