본 자료 정리는 'Operating System Concepts'(Tenth Edition) - Abraham Silberschatz 원서에 출처합니다.
Copyright © 2020 John Wiley & Sons, Inc.
Chapter 3: Processes
- Process Concept
- Process Scheduling
- Operations on Processes
- Interprocess Communication
- IPC in Shared-Memory Systems
- IPC in Message-Passing Systems
Objectives (목표)
- 프로세스의 개별 구성 요소를 식별하고 운영 체제에서 이러한 구성 요소가 어떻게 표현되고 스케쥴 되어 있는지 설명
- 이러한 작업을 수행하는 적절한 시스템 호출을 사용하여 프로그램을 개발하는 것을 포함하여 운영 체제에서 프로세스가 생성되고 종료되는 방법을 설명
- 공유 메모리 및 메시지 전달을 사용하여 프로세스 간 통신을 설명하고 대조
Process Concept
운영체제에 대해 논의할 때 중요한 것 중 하나는 "모든 CPU 활동들을 어떻게 부를 것인가?"이다. 초기 컴퓨터는 작업(job)을 실행하는 배치 시스템이었다. 이어서 사용자 프로그램 혹은 task을 실행하는 시분할 시스템이 등장했다. 단일 사용자 시스템에서는 프로세스를 실행한다.
프로세스: 실행중인 프로그램. 작업단위이다.
프로세스의 현재 활동 상태는 program counter 값과 프로세서 레지스터의 내용으로 표시된다.
프로그램은 디스크(실행 파일)에 저장된 수동 개체이고 프로세스는 활성화 개체이다.
(실행가능한 파일이 메모리에 로드 되면 프로그램이 프로세서가 된다.)
프로그램 실행은 GUI 마우스 클릭, 명령줄 입력 등을 통해 시작한다.
- 책에는 job과 process라는 용어를 거의 같은 의미로 사용한다.
Process Concept2
일반적으로 프로세스의 메모리 배치는 여러 구역으로 구분되는데, 이 구역에는 다음이 포함된다.
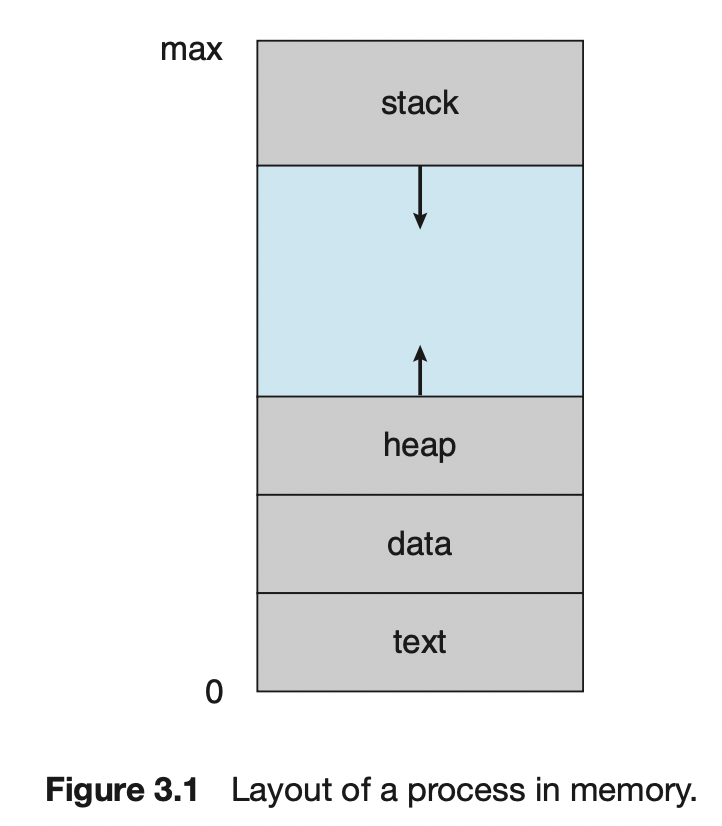
- Text section: 실행 코드
- Data section: 전역 변수
- Heap section: 프로그램 실행 중에 동적으로 할당되는 메모리 (e.g. new Class().. 객체를 담는 공간)
- Stack section: 함수를 호출할 때 임시적 데이터 저장장소 (e.g. 함수 매게변수, 반환주소, 지역변수..)
text, data 영역의 크기는 고정되기 때문에 프로그램 실행시간 동안 크기가 변하지 않는다.
그러나 stack, heap 영역의 크기는 가변적인데, 함수가 호출될 때마다 함수 매개변수, 지역 변수 및 복귀 주소를 포함하는 활성화 레코드(activation record)가 stack에 push 되며, 함수에서 제어가 되돌아오면 stack에서 활성화 레코드가 pop된다.
마찬가지로 메모리가 동적으로 할당됨에 따라 힙이 커지고, 메모리가 시스템에 반환되면 축소된다.
stack, heap 구역이 서로의 방향으로 커지더라도 운영체제는 서로 겹치지 않도록 해야한다. (그림 참조)
- 하나의 프로그램은 여러개의 프로세스를 실행할 수 있다.
(e.g. chrome에 여러 창을 띄워놓고 작업하는 경우)
Process State
프로세스는 실행되면서 그 상태가 변한다. 프로세스의 상태는 부분적으로 그 프로세스의 현재 활동에 따라서 정의된다. 프로세스는 다음 상태 중 하나에 있게 된다.
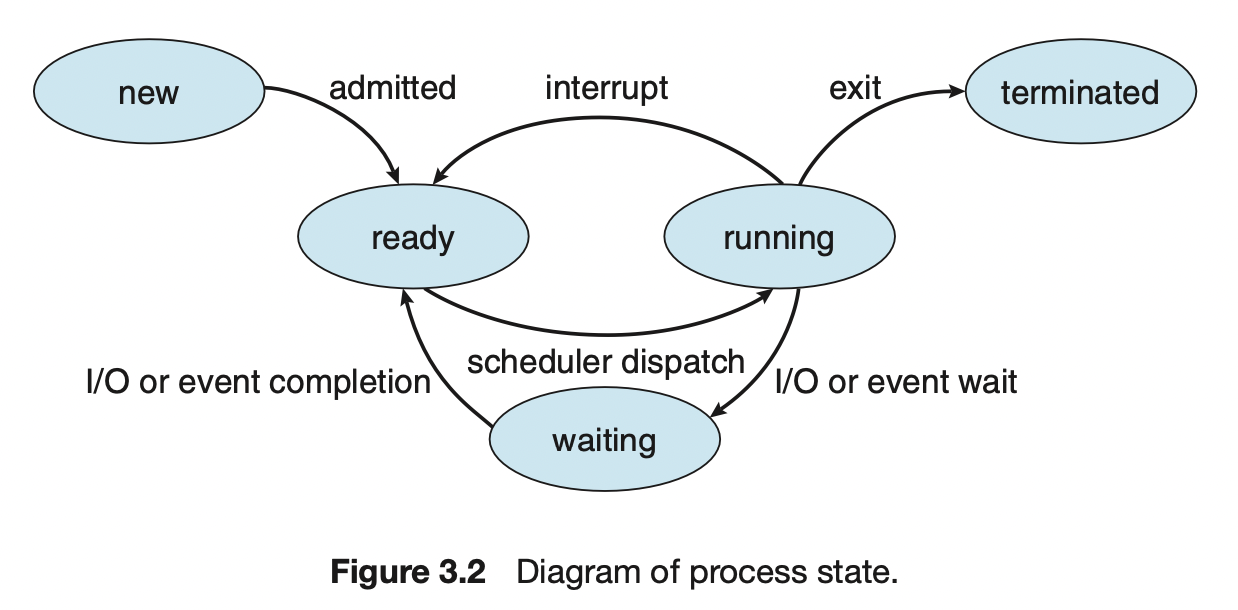
new: 프로세스가 생성되고 있다.
running: 명령어들이 실행되고 있다.
waiting: 프로세스가 어떤 이벤트가 일어나기를 기다린다. (e.g. 입출력 완료 또는 신호의 수신)
ready: 프로세스가 처리기에 할당되기를 기다린다.
terminated: 프로세스의 실행이 종료된다.
어느 한 순간에 프로세서 코어에서는 오직 하나의 프로세스만이 실행된다. 하지만 많은 프로세스가 waiting, ready 상태에 있을 수 있다.
Process Control Block (PCB)
각 프로세스와 관련된 정보를 표현한다. (task control block 이라고도 불린다.)
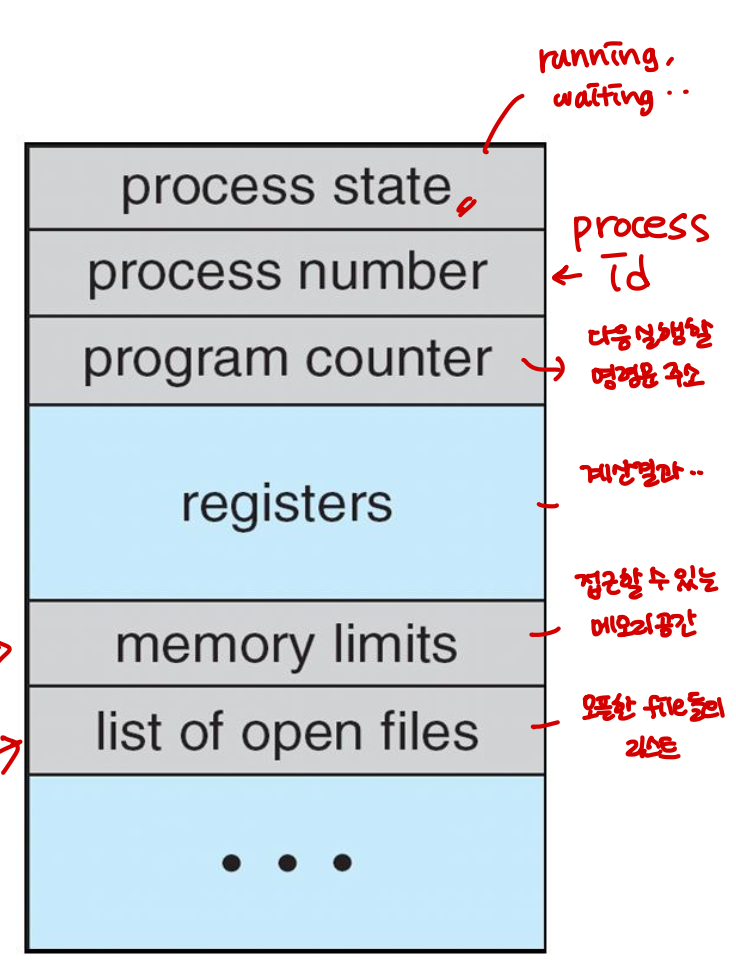
- Process state: running, waiting, etc..
- Program Counter: 다음 실행할 명령어의 주소를 가르킨다.
- CPU registers: 여러 레지스터와 상태 코드 정보를 포함하는데, 이들은 나중에 프로세스가 다시 스케쥴 될 때 계속 올바르게 실행되도록 하기 위해서 인터럽트 발생 시 저장되어야 한다.
- CPU-scheduling information: 프로세스 우선순위, 스케쥴 큐에 대한 포인터 등을 포함한다.
- Memory-management information: 운영체제에 의해 사용되는 메모리 시스템에 따라 기준(base)레지스터, 한계(limit)레지스터의 값, 페이지 테이블, 세그먼트 테이블 등과 같은 정보를 포함한다.
- Accounting information: CPU 사용시간과 경과 시간, 시간제한, 계정 정보, 프로세스 번호 등을 포함한다.
- I/O status information: 프로세스에 할당된 입출력 장치, 열린 파일 목록 등을 포함한다.
Threads
위에서 설명한 프로세스 모델은 한 프로세스가 단일의 실행 스레드를 실행하는 프로그램이라 가정하였다.
하지만 현대 운영체제는 한 프로세스가 다수의 실행 스레드를 가질 수 있도록 허용한다. 이러한 특성은 여러 스레드가 병렬로 실행될 수 있다는 것을 의미한다.
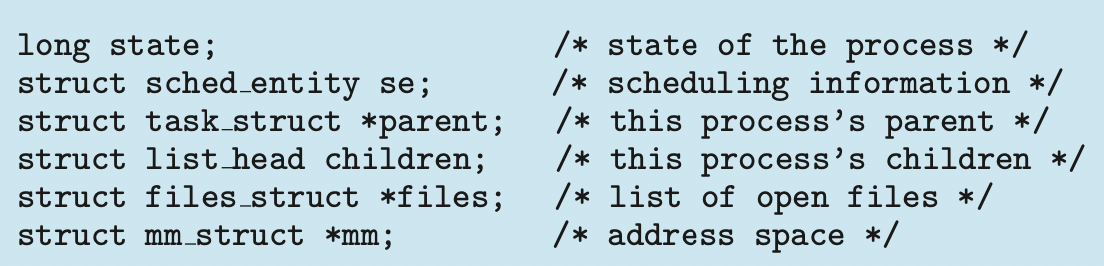
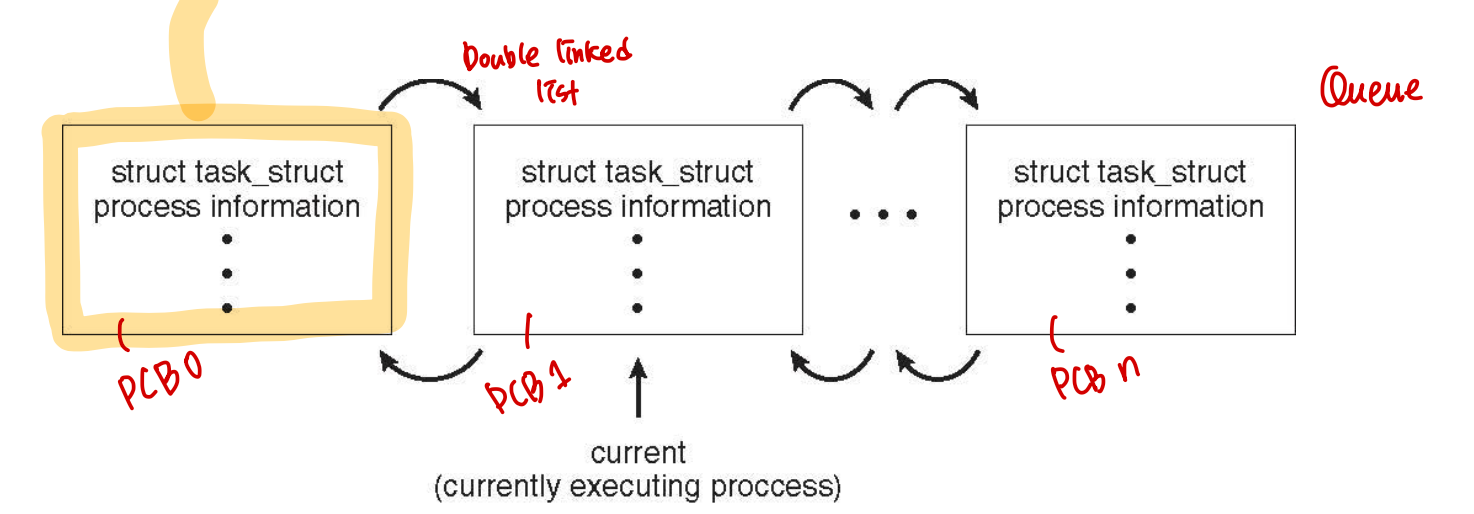
Process Representation in Linux
Represented by the C structure taks_struct
Process Scheduling
multiprogramming 과 time sharing 의 목적은 CPU 활용성을 최대화 하는 것과 사용자의 상호작용을 위해 프로세스 간에 CPU 코어를 빠르게 전환하는 것이다.
이를 위해 프로세스 스케쥴러는 CPU에서 실행 가능한 여러 프로세스 중에서 하나의 프로세스를 선택해 실행한다.
Degree of multiprogramming: 현재 메모리에 있는 프로세스 수
밸런싱을 위해 고려되는 프로세스의 일반적인 동작
- I/O bound process: 계산보다 I/O를 수행하는데 더 많은 시간을 소비한다. (e.g. word, powerpoint..) 계산량이 적기 때문에 CPU 실행시간이 짧다.
- CPU-bound process: 계산에 더 많은 시간을 할애한다. (e.g. 기상량, 빅데이터 처리..) 계산량이 많기 때문에 비교적 CPU burst가 길다.
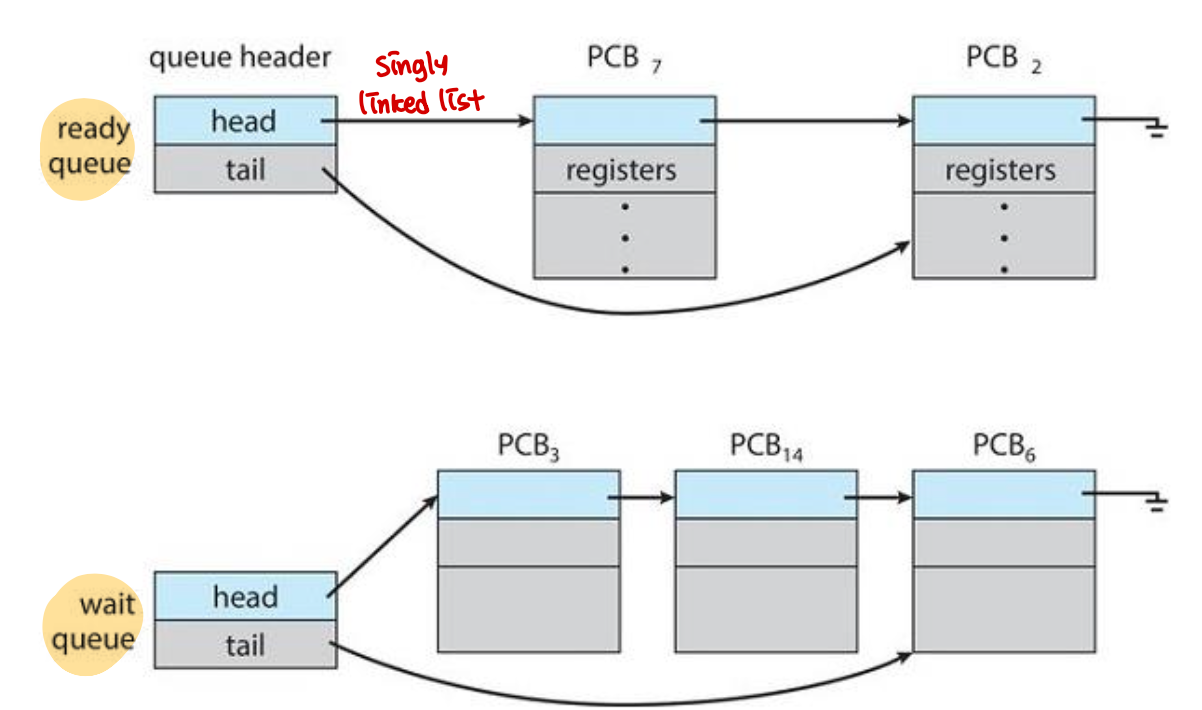
Scheduling Queues
Ready queue: 주 메모리에 있는 모든 프로세스의 집합이다. 프로세스가 시스템에 들어가면 ready queue에 들어가서 준비 상태가 되어 CPU 코어에서 실행되기를 기다린다.
Wait queues: 프로세스에 CPU 코어가 할당되면 프로세스는 잠시 동안 실행되어 결국 종료되거나, 인터럽트 되거나, I/O 요청 완료와 같은 특정 이벤트가 발생할 때까지 기다린다. (여러 종류가 있음)
Representation of Process Scheduling
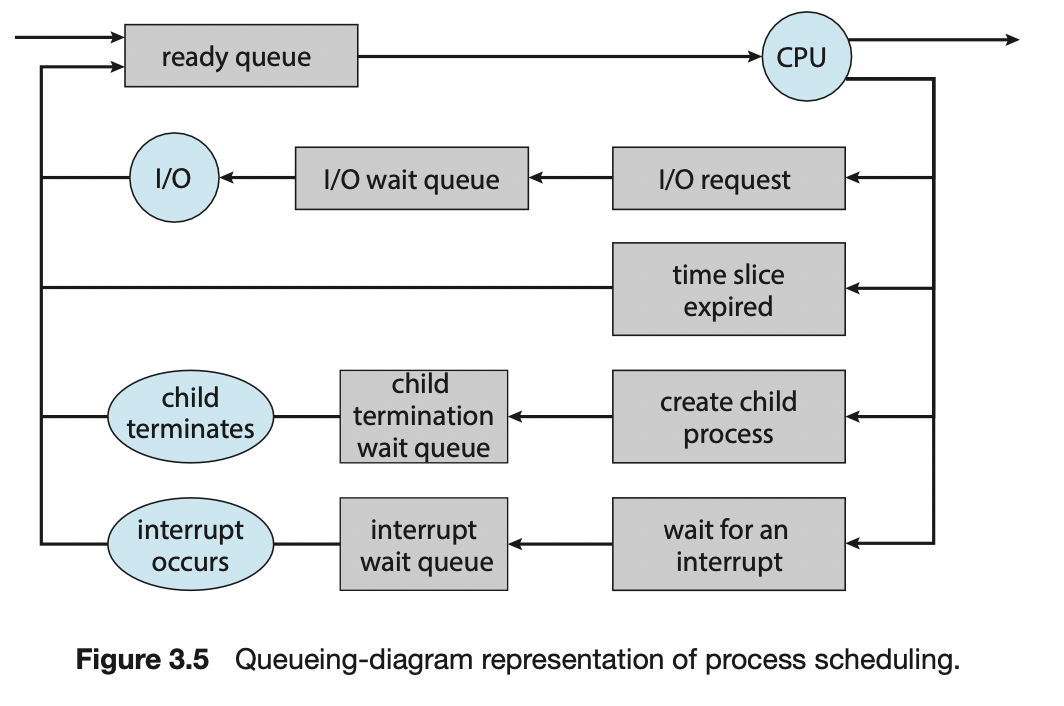
Queueing diagram은 queues, resources, flows를 나타낸다.
CPU Scheduling
프로세스는 ready queue와 다양한 wait queue 사이에서 마이그레이션 된다.
(마이그레이션: 한 운영환경으로부터, 대개의 경우 좀 더 낫다고 여겨지는 다른 운영환경으로 옮겨가는 과정)
CPU scheduler는 다음에 실행할 프로세스를 선택하고 CPU를 할당한다.
( CPU 스케쥴러는 최소한 100 milliseconds 마다 실행된다. [2019년 기준] )
일부 운영체제는 스와핑(swapping)이라는 중간 형태의 스케쥴링을 갖고 있는데,
핵심 아이디어는 때로는 메모리에서 프로세스를 제거하여 다중 프로그래밍의 정도를 감소시키는 것이 유리할 수 있다는 것이다. 이후 디스크에서 메모리로 swap in 하여 상태를 복원할 수 있기 때문에 이 기법을 swapping이라고 한다.
Context Switch
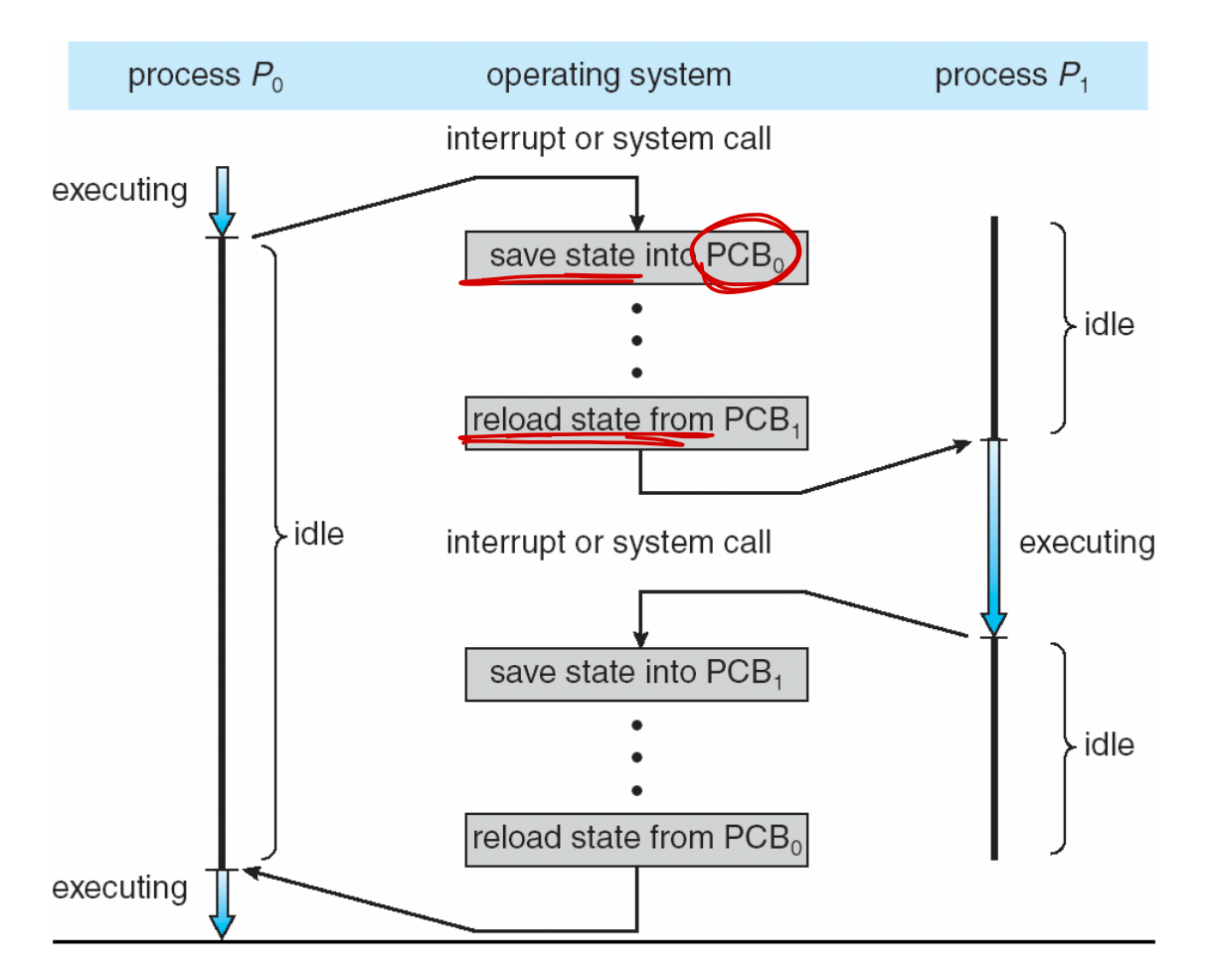
인터럽트는 운영체제가 CPU 코어를 현재 작업에서 뺏어 커널 루틴을 실행할 수 있게 한다. 인터럽트가 발생하면 시스템은 인터럽트 처리가 끝난 후에 문맥(context)을 복구할 수 있도록 현재 실행 중인 프로세스의 문맥을 저장할 필요가 있다.
이 문맥은 프로세스의 PCB에 표현된다.
CPU가 다른 프로세스로 전환할 때 시스템은 이전 프로세스의 상태를 저장(state save)하고 context switch을 통해 새 프로세스에 대해 저장된 상태를 로드(state restore)해야 한다.
컨텍스트 전환 시간은 오버헤드이다. context를 전환하는 동안 시스템이 유용한 작업을 수행하지 않는다.
(-> OS와 PCB가 복잡할수록 컨텍스트 전환이 길어진다.)
하드웨어 지원에 따른 시간 (*참고)
( 일부 하드웨어는 CPU당 여러 레지스터 세트를 제공한다 -> 따라서 A를 실행하다가 B를 실행하더라도 PCB안의 것들이 미리 다 올라와있다. )
Context Switch From Process to Process
Operations on Processes
System provides mechanisms for:
- process creation
- process termination
Process creation
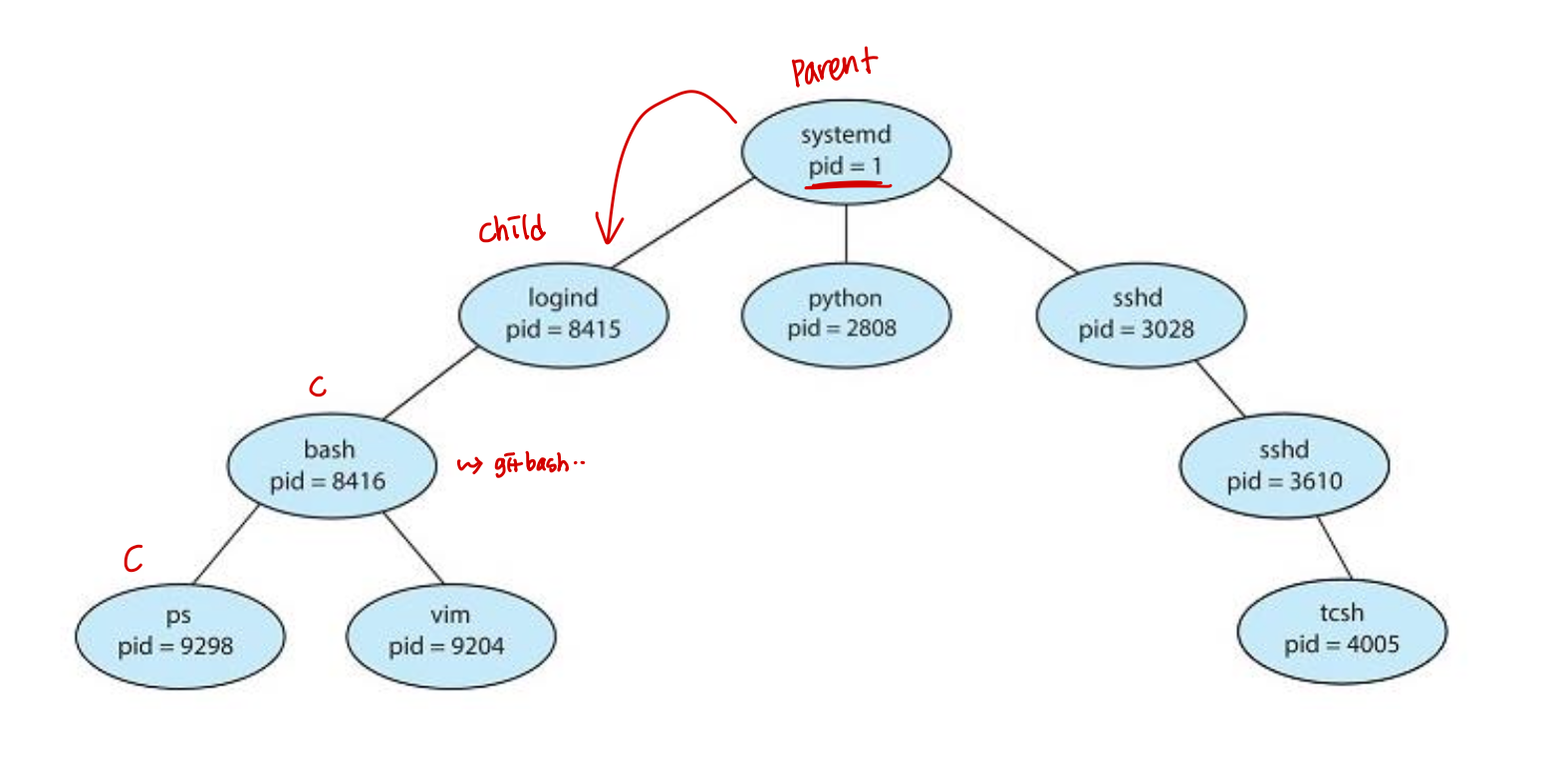
부모 프로세서는 자식 프로세서를 생성하고, 이는 차례로 다른 프로세스를 생성하여 프로세스 트리(tree of process)를 형성한다.
일반적으로 프로세스 식별자(pid)를 통해 프로세스를 식별하고 관리한다.
-
Resource sharing options
- 부모와 자식은 모든 리소스를 공유한다.
- 자식은 부모 리소스의 부분집합을 공유한다.
- 부모와 자식은 리소스를 공유하지 않는다.
-
Execution options
- 부모와 자식은 동시에 실행된다.
- 부모는 자식이 끝날 때까지 기다린다.
A Tree of Processes in Linux
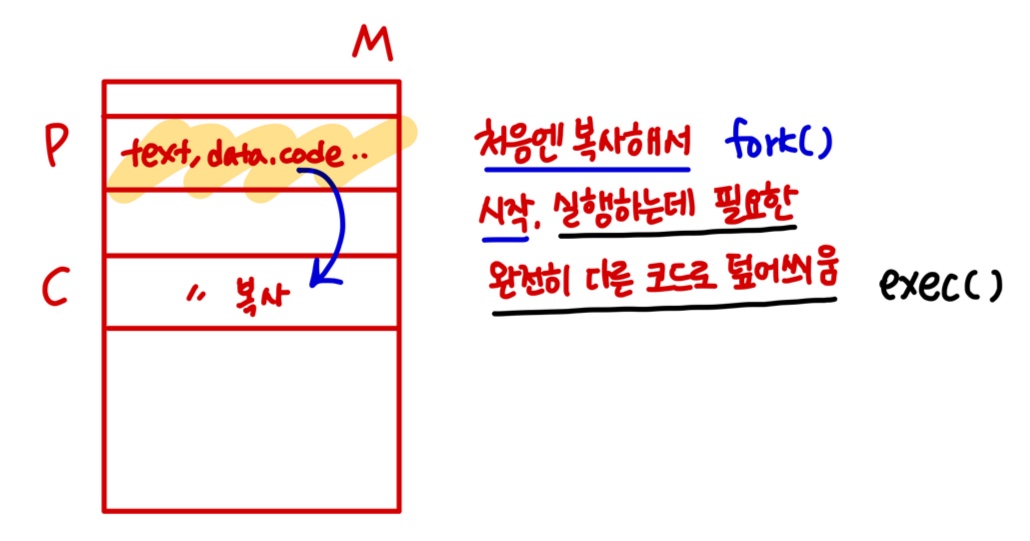
Process Creation2
Address-space possibilities (메모리에 있는 주소 공간)
- 자식 프로세스는 부모 프로세스의 복제이다.
- 자식은 로드된 새 프로그램을 가진다.
UNIX examples
- fork() 시스템 콜은 새로운 프로세스를 생성한다.
- exec() 시스템 콜은 프로세스 메모리 공간을 새 프로그램으로 교체하기 위한 시스템 콜인 fork() 다음에 사용된다.
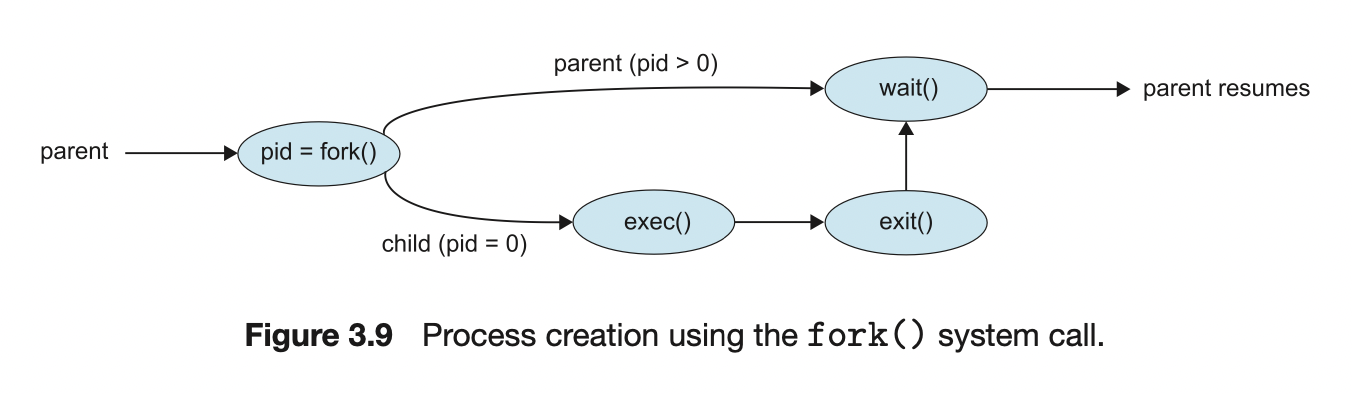
프로세스가 새로운 프로세스를 생성할 때는 두 프로세스를 실행시키는 데 두 가지 방법이 있다.
- 부모는 자식과 병행하게 실행을 계속한다.
- 부모는 일부 또는 모든 자식이 실행을 종료할 때까지 기다린다.
C Program Forking Separate Process

Process Termination
프로세스가 마지막 명령문의 실행을 끝내고, exit 시스템 콜을 사용하여 운영체제에 자신의 삭제를 요청하면 종료한다.
- 이 시점에서 프로세스는 자신을 기다리고 있는 부모 프로세스에 상태 값을 반환할 수 있다.
- 프로세스의 리소스는 운영 체제에 의해 할당 해제된다.
부모는 abort() 시스템 호출을 사용하여 자식 프로세스의 실행을 종료할 수 있다.
부모가 자식의 실행을 종료시키는 경우는 다음과 같다.
- 자식이 자신에게 할당된 자원을 초과하여 사용할 때
- 자식에게 할당된 태스크가 더 이상 필요 없을 때
- 부모가 exit를 하는데, 운영체제는 부모가 exit 한 후에 자식이 실행을 계속하는 것을 허용하지 않는 경우
세 번째의 경우, 보통 부모 프로세스가 종료한 후에 자식 프로세스가 존재할 수 없다. 이 경우 부모가 종료되면 자식도 연달아 종료되는, 연쇄식 종료 작업(cascading termination)이 시행된다.
부모 프로세스는 wait() 시스템 호출을 사용하여 자식 프로세스의 종료를 기다릴 수 있다. 호출은 종료된 프로세스의 상태 정보와 pid를 반환한다.
pid = wait(&status);
좀비
종료되었지만 부모 프로세스가 아직 wait() 호출을 하지 않은 프로세스를 좀비(zombie) 프로세스라고 한다. 종료하게 되면 모든 프로세스는 좀비 상태가 되지만 아주 짧은 시간 동안만 머무른다.
고아
부모 프로세스가 wait()를 호출하지 않고 종료한다면, 자식 프로세스들은 고아(orphan) 프로세스가 된다.
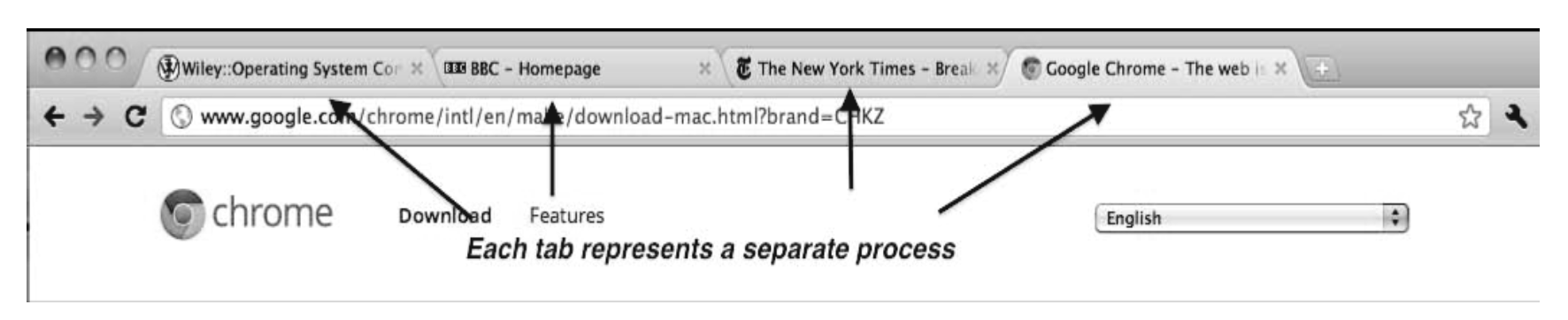
Multiprocess Architecture - Chrome Browser
대부분의 최신 웹 브라우저는 탭 브라우징을 제공하여 동시에 여러 웹사이트를 열 수 있다.
-한 웹사이트에서 문제가 발생하면 전체 브라우저가 중단되거나 충돌할 수 있다.
Google Chrome 브라우저는 3가지 유형의 프로세스가 있는 multiprocess이다.
- Browser 프로세스는 사용자 인터페이스, 디스크 및 네트워크 I/O를 관리한다.
- Renderer 프로세스는 웹 페이지를 렌더링하고 HTML, JavaScript를 처리한다. 열린 각 웹 사이트에 대해 새 renderer가 생성된다.
- Plug-in 프로세스는 유형별 플러그인 프로세스이다.
Interprocess Communication
시스템 내의 프로세스는 독립적이거나 협력적일 수 있다.
운영체제 내에서 실행되는 프로세스들은 독립 또는 협력적인 프로세스 두 가지로 분류된다.
간단히 말해서, 다른 프로세스와 데이터를 공유하면 협력(cooperating), 그렇지 않으면 독립적(independent)인 프로세스라고 한다.
프로세스 협력을 하는 이유
- 정보 공유
- 계산 가속화 (e.g. 방대한 양을 계산하는 경우 여러 프로세스에서 나눠서 계산)
- 모듈성
협력적 프로세스는 데이터를 교환할 수 있는 프로세스 간 통신(interprocess communication, IPC) 기법이 필요하다.
IPC의 두 가지 모델
- Shared memory
- 공유 메모리 모델에서는 협력 프로세스들에 의해 공유되는 메모리의 영역이 구축된다. 프로세스들은 그 영역에 데이터를 읽고 쓰고 함으로써 정보를 공유할 수 있다.
- Message passing
- 협력 프로세스들 사이에 교환되는 메시지를 통하여 이루어진다.
Communication Models
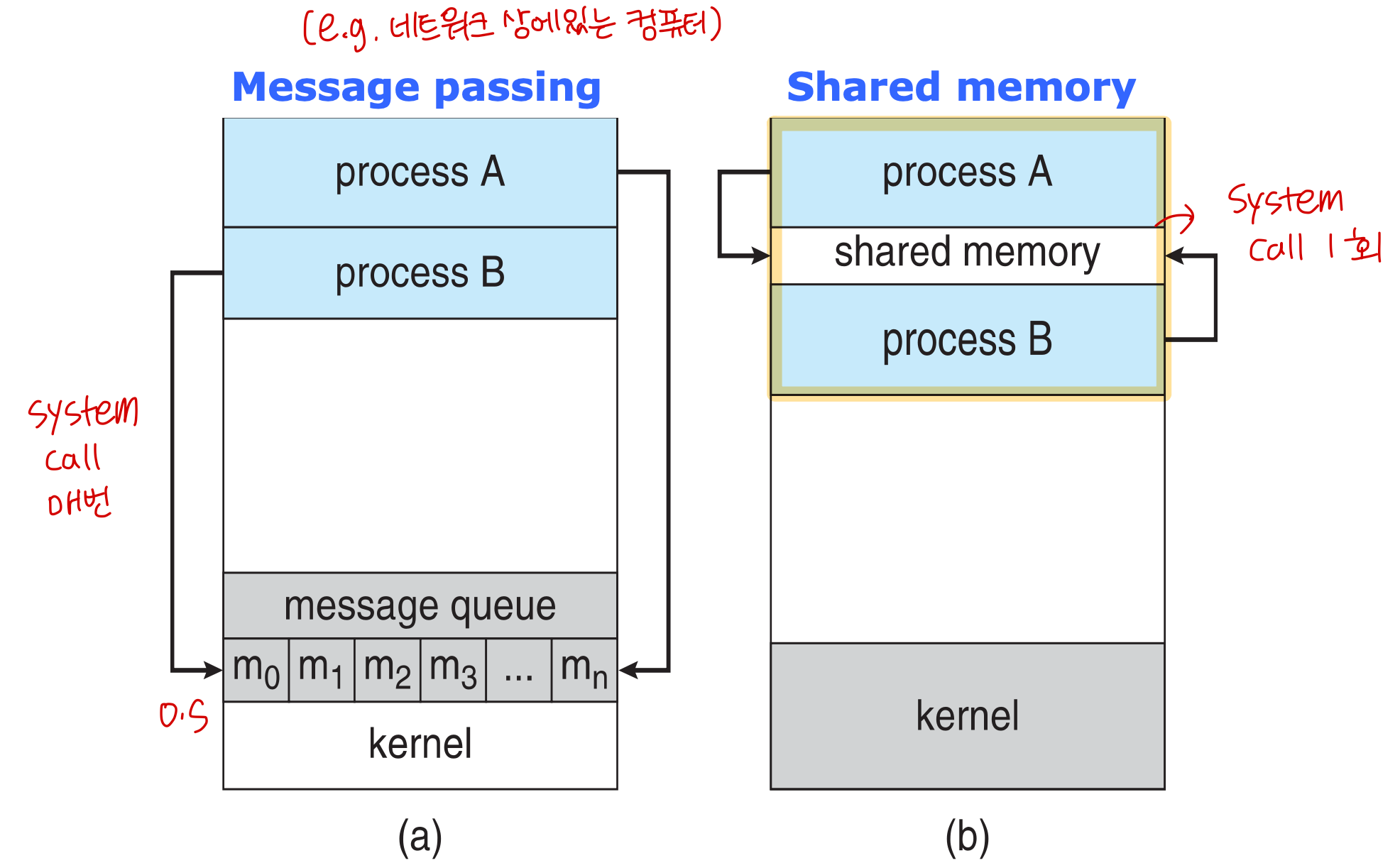
IPC in Shared-Memory Systems
- 통신을 원하는 프로세스 사이에 공유 메모리 영역이 설정된다.
- 통신은 운영 체제가 아닌 사용자 프로세스의 제어 하에 있다.
- 주요 문제는 사용자 프로세스가 공유 메모리에 액세스할 때 작업을 동기화할 수 있는 메커니즘을 제공하는 것이다.
- 동기화는 6장과 7장에 자세히 설명되어 있다.
Producer-Consumer Problem (Shared-Memory Systems)
공유 메모리를 사용하는 프로세스 간 통신에서는 통신하는 프로세스들이 공유 메모리 영역을 구축해야 한다.
공유 메모리 영역은 공유 메모리 세그먼트를 생성하는 프로세스의 주소 공간에 위치한다.
생산자 - 소비자 문제의 해결책으로 공유 메모리를 사용하는데, 생산자와 소비자 프로세스들이 병행으로 실행되도록 하려면, 생산자가 정보를 채워 넣고 소비자가 소모할 수 있는 항목들의 버퍼가 반드시 사용 가능해야 한다. 또 이 버퍼는 공유 메모리 영역에 존재해야 한다.
이때 두 가지 버퍼가 사용되는데, 무한 버퍼(unbounded-buffer)는 크기에 실질적인 한계가 없고 유한 버퍼(bounded-buffer)는 버퍼의 크기가 고정되어 있다고 가정한다.
Bounded-Buffer
- shared-buffer
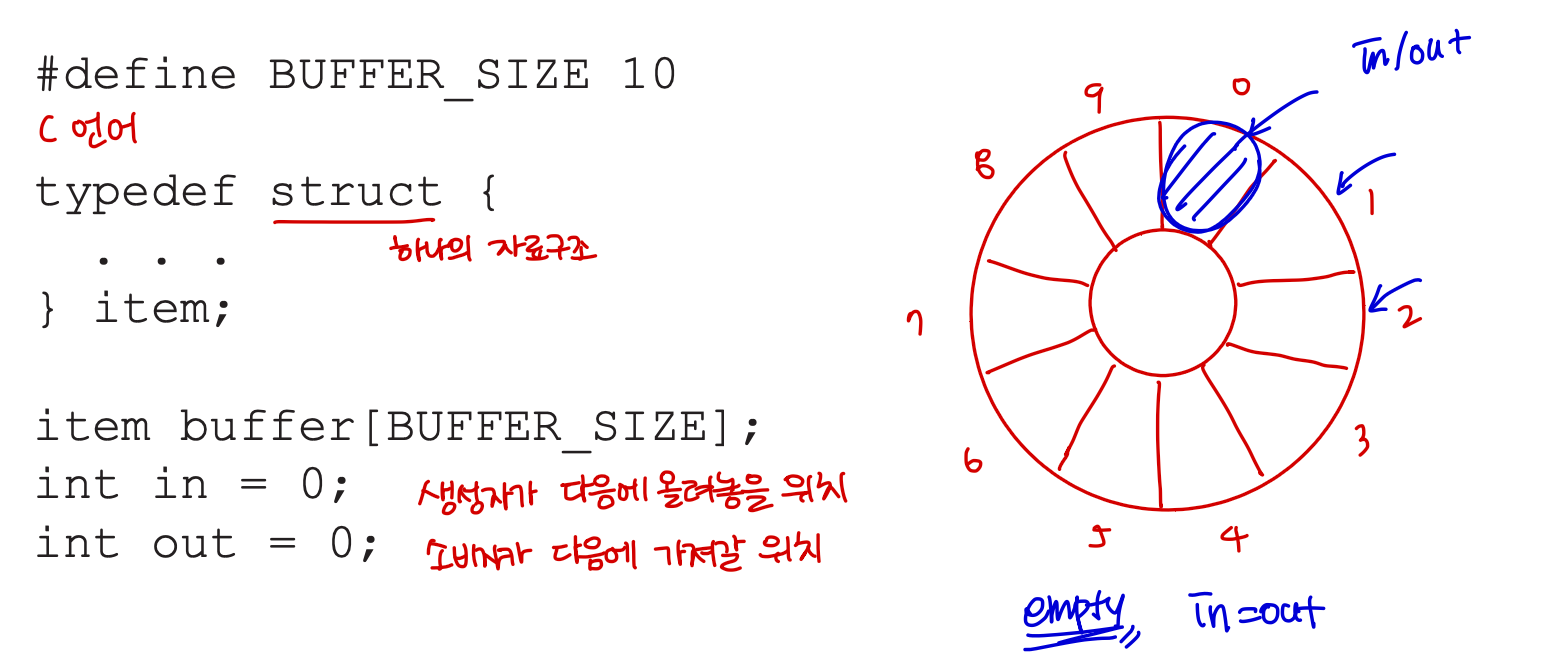
Solution is correct, but can only use BUFFER_SIZE-1 elements
Producer Process sharing Bounded-Buffer

Consumer Process sharing Bounded-Buffer

IPC in Message-Passing Systems
-
동일한 주소 공간을 공유하지 않고 프로세스가 통신하고 작업을 동기화하는 메커니즘
-
메시지 전달 기능은 두 가지 작업을 제공한다.
- send(message)
- receive(message)
-
특히 메시지 전달 방식은 네트워크에 연결된 다른 컴퓨터들에도 프로세스가 분산되어있는 경우 유용하다.
-
메시지 크기는 고정 또는 가변이다.
Message-Passing
프로세스 P와 Q가 통신하려면 다음을 수행해야 한다.
- 그들 사이의 통신 링크(communication link)설정
- send/receive를 통해 메시지 교환
통신링크의 논리적 구현
- 직접/간접 소통
- 동기/비동기 소통
- 자동/명시적 버퍼링
Direct Communication
프로세스는 서로의 이름을 명시적으로 지정해야 한다.
- send(P, message) - 프로세스 P에게 메세지 보내기
- receive(Q, message) - 프로세스 Q로부터 메세지 받기
직접 통신 링크의 특성
- 링크가 자동으로 설정된다.
- 링크는 정확히 두 개의 프로세스와 연결된다.
- 각 프로세스 쌍 사이에는 정확히 하나의 링크가 있다.
- 링크는 단방향일 수 있지만 일반적으로 양방향이다.
Indirect Communication
메세지는 mailbox로 보내고 받는다. (also referred to as ports)
- 각 mailbox에는 고유한 id가 있다.
- 프로세스는 mailbox를 공유하는 경우에만 통신할 수 있다.
프리미티브는 다음과 같이 정의된다.
- send(A, message) - 메일박스 A에게 메세지 보내기
- receive(A, message) - 메일박스 A로부터 메세지 받기
간접 통신 링크의 특성
- 프로세스가 공통 mailbox를 공유하는 경우에만 링크가 설정된다.
- 링크는 많은 프로세스와 연관될 수 있다.
- 각 프로세스 쌍은 여러 통신 링크를 공유할 수 있다.
- 링크는 단방향 또는 양방향일 수 있다.
Indirect Communication2
Mailbox sharing
- P1, P2, and P3 share mailbox A
- P1 sends; P2 and P3 receive
-> 누가 메세지를 받았을까?
Solutions
- 링크가 최대 두 개의 프로세스와 연결되도록 허용
- 한 번에 하나의 프로세스만 수신 작업을 실행하도록 허용
- 시스템이 receiver를 임의로 선택하도록 허용한다. sender는 receiver가 누구인지 알린다.
Operations
- mailbox(=port)를 생성한다.
- mailbox를 통해 메세지를 주고 받는다.
- mailbox를 파괴한다.
Synchronization ( Message-passing )
Message passing may be either blocking or non-blocking.
Blocking은 synchronous로 간주된다. (직접 수령)
- Blocking send : 발신하는 프로세스는 메시지가 수신 프로세스 또는 메일박스에 의해 수신될 때까지 차단된다.
- Blocking receive : 메시지가 이용 가능할 때까지 수신 프로세스가 차단된다.
Non-blocking은 asynchronous로 간주된다. (놓고 감)
- Non-blocking send : 발신하는 프로세스가 메시지를 보내고 작업을 재시작한다.
- Non-blocking receive : 발신하는 프로세스가 유효한 메시지 또는 null 값을 받는다.
다양한 조합이 가능하다.
- 만약 보내기와 받기가 모두 차단되면 rendezvous가 된다.
Buffering
링크에 첨부된 메시지 queue이다.
queue를 구현하는 방법
-
Zero capacity : 링크에 대기 중인 메시지가 없다 - 버퍼링 없음
- 발신자는 수신자를 기다려야 한다. (rendezvous)
-
Bounded capacity : n개 메세지의 유한한 길이 - 자동 버퍼링
- 링크가 가득 찬 경우 발신자는 기다려야 함
-
Unbounded capacity : 무한 길이 - 자동 버퍼링
- 발신자는 절대 대기하지 않는다.
수정해야될 사항이 있거나 잘못 번역된 문장이 있을경우 댓글로 알려주세요 :)
