
📝 이번 포스트는 "Real-Time Grasp Detection Using Convolutional Neural Networks"논문에 대해 알아보도록 하겠습니다.
Abstract와 Introduction은 이해하기 쉬우니 직접 읽어보기를 권장하겠습니다.
2. RELATED WORK
과거 연구들은 3-D 시뮬레이션을 사용하여 좋은 grasp를 찾았습니다.
좋은 grasp를 찾기 위한 3-D 시뮬레이션 방법은 강력하지만, 적절한 grasp를 찾기 위해서는 물체에 대한 3-D모델과 다른 물리적 정보에 너무 의존합니다.
robotic system은 RGB-D 센서와 데이터를 활용하여 object recognition, detection, mapping과 같은 작업을 수행합니다.
최근 grasp detection 연구는 RGB-D 데이터만 사용하여 grasp를 찾는 문제에 초점을 두고 있습니다.
이 기법들은 머신러닝에 의존하여 데이터로부터 좋은 grasp의 특징을 찾습니다.
grasp에 대한 시각적 모델은 새로운 물체에 대해 잘 일반화하며, full physical model이 아니라 single view만을 필요로 합니다.
CNN은 feature extractor와 visual model을 학습하는 데 강력한 모델입니다.
과거 연구는 저자는 grasp detection을 위한 CNN을 sliding window detection 파이프라인 속 classifier처럼 성공적으로 사용하였습니다.
이 논문의 저자는 동일한 문제를 다루지만, 더 높은 정확도를 훨씬 빠른 속도로 다루는 다른 아키텍쳐와 파이프라인을 사용하였다고 합니다.
3. PROBLEM DESCRIPTION
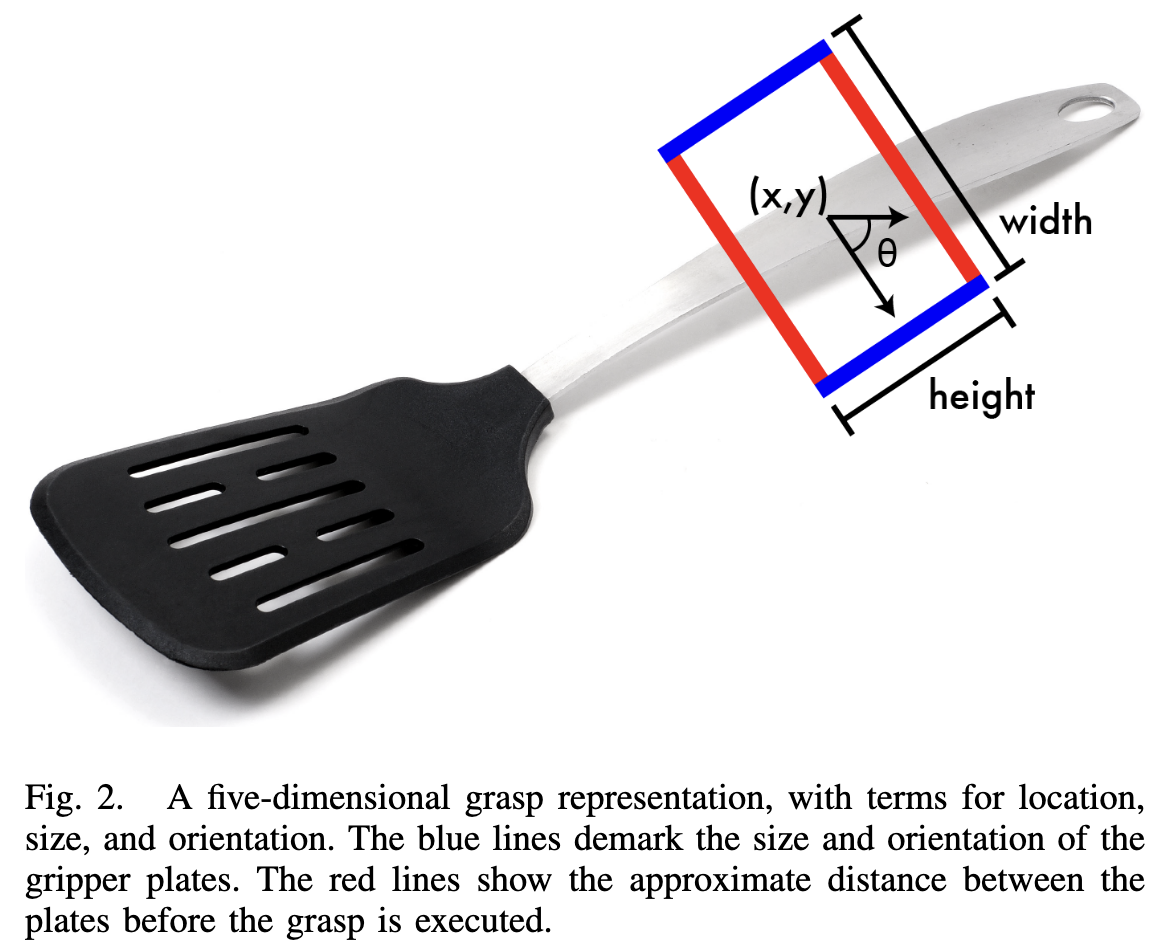
저자는 물체를 안전하게 들어올리고 잡을 수 있는 방법을 찾고자 했습니다.
저자는 이전 연구 논문에서 참고하여 5차원 representation을 사용합니다.
이 representation은 물체를 잡기 전에 평행 플레이트 그리퍼의 위치와 방향을 나타냅니다.
Ground truth grasp는 위치, 크기, 방향을 포함하는 사각형을 뜻합니다.
: 박스의 중심 x좌표
: 박스의 중심 y좌표
: 수평x축을 기준으로 방향을 뜻하는 변수 (0~360로 표현하여 방향을 알 수 있다.)
: 박스의 높이
: 박스의 너비
로 표현됩니다.
전체 3-D grasp 위치와 방향을 찾는 대신에 저자는 좋은 2-D grasp가 3-D로 투영되어 scene을 보는 로봇이 해석할 수 있다고 가정합니다.
5차원 representation을 사용하면 grasp detection 문제는 computer vision에서의 object detection과 유사해지며, 그리퍼의 방향(orientation)만 차이가 있습니다.
4. GRASP DETECTION WITH NEURAL NETWORKS
CNN은 classfication과 detection과 같은 computer vision 문제에서 다른 기술들 보다 큰 격차로 우수한 성능을 보였습니다.
CNN은 이미 sliding window 기법에서 classifier로 적용되었을 때 grasp detection에서 좋은 성능을 보였습니다.
저자는 많은 계산 비용을 줄이고 싶어서, 물체의 전체 이미지에 대해 전역적인 grasp detection을 수행했습니다.
A. Architecture
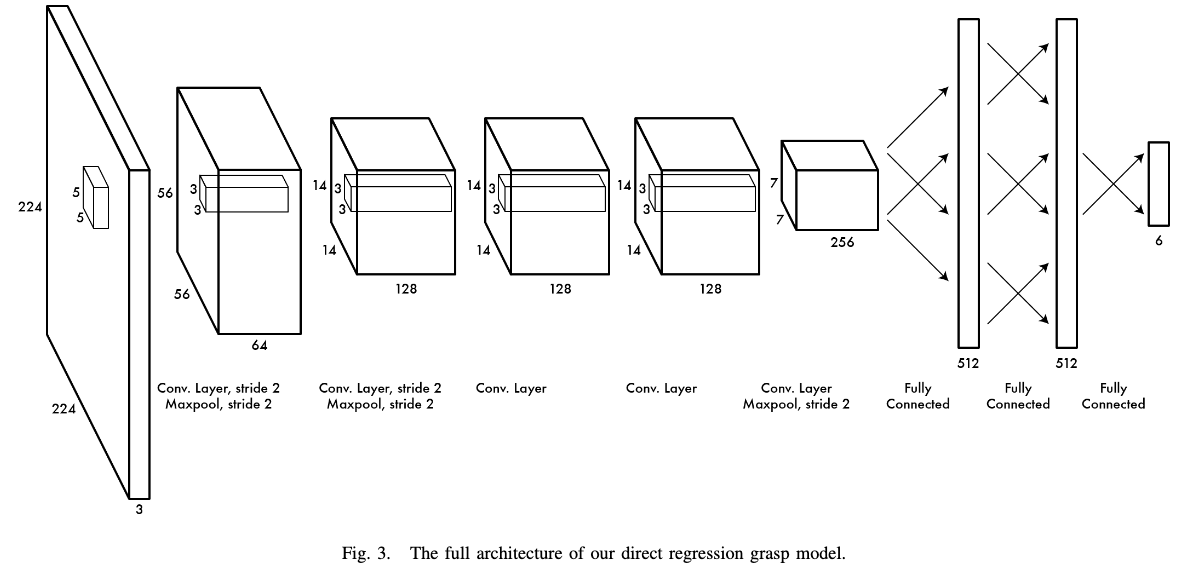
저자의 CNN 모델은 AlexNet을 기반으로 만들었습니다.
모델명은 딱히 짓지 않았나 봅니다. 논문에 자신의 CNN 모델에 대한 명칭을 명시하지 않았습니다.
저자의 CNN 모델은 5개의 conv layer와 3개의 FC layer로 구성됩니다.
conv layer는 normalization과 maxpooling layer와 같이 배치되어 있습니다.
B. Direct Regression To Grasps
저자의 모델은 RGB-D 이미지에서 grasp 좌표로 regression 하는 것입니다.
입력 이미지는 CNN모델을 연산을 거치고 결과로 6개의 grasp coordinate를 얻습니다.
이 6개는
: 객체의 중심 x좌표
: 객체의 중심 y좌표
: 객체의 너비
: 객체의 높이
: ground truth 좌표 중 하나였던 를 활용하여 얻은 값
: ground truth 좌표 중 하나였던 를 활용하여 얻은 값
C. Regression + Classification
로봇이 잡은 객체를 사용하기 위해서는 반드시 먼저 객체를 인식해야 합니다.
모델을 확장함으로써 recognition과 grasp detection이 하나의 효율적인 파이프라인으로 결합될 수 있음을 보였습니다.
아키텍쳐를 수정하여 출력층에 객체 카테고리에 해당하는 추가적인 뉴런을 추가하였습니다.
이 모델은 direct regression 모델처럼 빠른데 이유는 아키텍쳐의 대부분을 변경하지 않았기 때문입니다.
D. MultiGrasp Detection
핵심
이 부분은 MultiGrasp 모델을 설명하는 단락입니다.
다중 객체 탐지라고 이해하면 됩니다.
앞서 설명한 모델들은 이미지당 하나의 grasp만 있다고 가정하고 예측하려고 했습니다.
MultiGrasp는 이미지를 NN그리드로 나누고 각 그리드셀 당 하나의 grasp가 존재한다고 가정합니다.
각 셀은 하나의 grasp를 예측하고 예측한 grasp가 객체일 확률도 예측합니다.
MultiGrasp모델의 output은 N N 7입니다.
첫 번째 컬럼은 ground truth grasp이 들어있을 확률을 나타내는 히트맵이고, 나머지 6개는 , , , , , 입니다.
MultiGrasp를 train할 때 고려해야 할 것이 있습니다.
MultiGrasp가 매번 이미지를 볼때마다 무작위로 최대 5개의 grasp를 선택하여 ground truth로 취합니다.
히트맵이 N N 개의 셀 중 5개만 1로 채우고 나머지는 0으로 채워집니다.
또한 그 Grasp들이 속하는 셀을 계산하고 해당 셀의 ground-truth 열에 grasp 좌표를 채웁니다.
그리고 훈련 중에는 역전파를 하지 않습니다.
왜냐하면 오직 5개만 1로 채워져있고 그 이외의 많은 셀들이 0으로 비어 있기 때문입니다.
대신, 히트맵 채널 전체와 ground truth grasp가 포함된 특정 셀에 대해 역전파를 구합니다.
5. EXPERIMENTS AND EVALUATION
A. Grasp Detection
이 논문이 발표되기 이전 연구들은 Cornell 데이터셋에서 grasp를 evaulationg할 때 두 가지 metric을 사용하였습니다.
-
point metric
predict한 grasp의 중심과 ground-truth grasp의 중심 간의 거리를 측정합니다.
이 말은 즉 euclidean distance를 구한다는 뜻이죠.
euclidean distance가 최대한 0에 수렴해야 grasp한 것으로 간주할 것입니다.
그러나 이 metric에는 두 가지 문제점이 있습니다.
첫 번째, grasp의 각도와 크기를 고려하지 않았다는 점입니다.
두 번째, 과거 연구에서는 threshold로 어떤 값을 사용했는지 공개하지 않아 새로운 결과와 기존 결과를 비교하기가 어렵다는 점입니다.
저자는 이러한 이유로 point metric을 사용하지 않았습니다. -
rectangle metric
grasp 각도가 ground-truth grasp와 30도 이내여야 했습니다.
그리고 예측한 grasp와 ground-truth grasp의 Jaccard index가 25% 이상이여야 했습니다.Jaccard Index란?
Intersection over Union과 거의 똑같은 개념이다.
통계용어로써 통계학에서는 주로 이 용어로 사용한다고 한다.하지만 25%라는 낮은 Jaccard index가 문제점이였습니다.
이전 연구와 마찬가지로, 저자는 five-fold cross validation을 수행했습니다.
데이터는 두 가지 방법으로 나누었는데
- Image-wise splitting : 이미지를 랜덤하게 나눕니다.
이 방법은 모델이 이전에 본 객체의 새로운 위치에 얼마나 잘 일반화할 수 있는지 테스트하는 것입니다. - Object-wise splitting : 객체를 랜덤하게 나누어, 동일한 객체에 속하는 모든 이미지를 동일한 cross-validation에 넣습니다.
이 방법은 모델이 새로운 객체를 얼마나 잘 일반화하는 지 테스트 하는 것입니다.
실제로 두 방법의 결과가 비슷했다고 합니다.
B. Object Classification
Cornel Grasping Dataset를 16개의 카테고리로 직접 분류했으며, 가장 적게 포함된 카테고리는 20개의 이미지가 있으며, 가장 많은 카테고리는 156개의 이미지가 있습니다.
클래스 라벨을 사용하여 regression + classification 모델을 train과 test합니다.
test 시에는 resgression + classification 모델이 동시에 최적의 grasp와 객체의 카테고리를 예측합니다.
C. Pretraining
grsap에 train 하기 전 ImageNet classification에 pretrain을 했습니다.
이전 자료에 따르면, CNN을 pretrain하는 것은 train 시간면에서 큰 향상을 보였고, 오버피팅을 방지하였습니다.
저자는 AlexNet에 RGB-D 데이터를 사용하기 위해 Blue 채널을 Depth 채널로 대체하여 사용했다고 합니다.
다른 입력 채널하나를 추가할 수 있지만 그렇게 하면 네트워크 전체를 pretrain할 수 없게 되어서 Blue채널을 Depth채널로 대체하였다고 합니다.
D. Training
cross-validation의 fold마다 각 epoch=25으로 훈련시키고, lr=0.0005, weight decay = 0.0001, drop out = 0.5 등 하이퍼파라미터 설정을 이렇게 했다고 합니다.
E. Preprocessing
데이터를 네트워크에 입력하기 전에 전처리를 했다고 합니다.
Blue 채널 대신에 Depth 채널로 대체하였고, Depth는 0~255사이의 값으로 정규화했습니다.
훈련 데이터를 준비할 때, 우리는 데이터를 광범위하게 데이터 증강을 합니다.
이미지를 무작위로 이동시키고 회전시킵니다.
320 320 pixel 크기의 center crop을 하고 랜덤하게 50 pixel 만큼 x축 y축 방향으로 이동시키고, 무작위로 회전시킵니다.
그 다음 224 224 사이즈로 resize합니다.
훈련 데이터셋은 이미지당 3000개 증강하고 테스트 데이터셋은 상하좌우 이동이나 회전 없이 resize만 수행합니다.
DISCUSSION, CONCLUSION, ACKNOWLEDGEMENTS는 직접 읽어보기를 권장하겠습니다.
