논문 'Estimating psychological networks and their accuracy: A tutorial paper' 을 읽고 정리한 내용입니다.
이해하기 위한 용도로 적은 것이므로 언제든 수정될 수 있습니다. 🙇♀️
개요
심리 네트워크의 사용은 다양한 연구 분야에서 인기를 얻고 있다.
일반적인 논문들에서는 이러한 심리 네트워크를 추정 및 해석하는 주제를 다루지만,
얼마나 정확한 네트워크가 추정되고 또 얼마나 안정적인지 확인하고자 하는 작업은 거의 수행되지 않는다.
논문에서는 심리 네트워크의 정확성과 안정성, 견고성을 평가하는 법을 제안하고,
해당 기능들을 사용할 수 있는 R package bootnet을 소개한다.
또한, 논문에서는 샘플링 변동을 통해 네트워크 정확도 문제를 해결하는 것을 목표로 한다.
추정된 네트워크의 정확도를 평가하기 위해서 논문에서는 부트스트랩 루틴 을 사용해
(1) Edge Weight들의 신뢰구간을 구하고
(2) 중심성 지수의 안정성을 조사하며
(3) 앞선 과정에서 도출된 값(Edge Weight / 중심성 지수)이 다른 값(Edge Weight / 중심성 지수)들과 차이가 있는지 알아보는 차이 검정을 실시하는 방법을 제안한다.
Bootstrap
Bootstrap이라는 단어를 보고 가장 먼저 프론트엔드 프레임워크인 Bootstrap만 떠올랐다.
통계학에서의 Bootstrap은 현재 내가 가진 데이터들 중
데이터를 무작위로 재추출함으로써 자료를 생성하고,
그로 부터 통계량을 구해내는 것을 뜻한다. 중복을 허용한다.
즉, 데이터들 중에서 n개를 복원추출하고 그들의 평균을 구한다.
이 과정을 수천번 반복하면 평균의 분포를 알 수 있게 되며
이를 통해 정확도가 높은 통계량들을 추론해낼 수 있다.
Bootstrap 기법은 신뢰성을 평가하는데 유용하게 쓰인다.
https://learningcarrot.wordpress.com/2015/11/12/부트스트랩에-대하여-bootstrapping/
https://learnshare.tistory.com/17
상단의 블로그를 참고했습니다.
네트워크 시뮬레이션
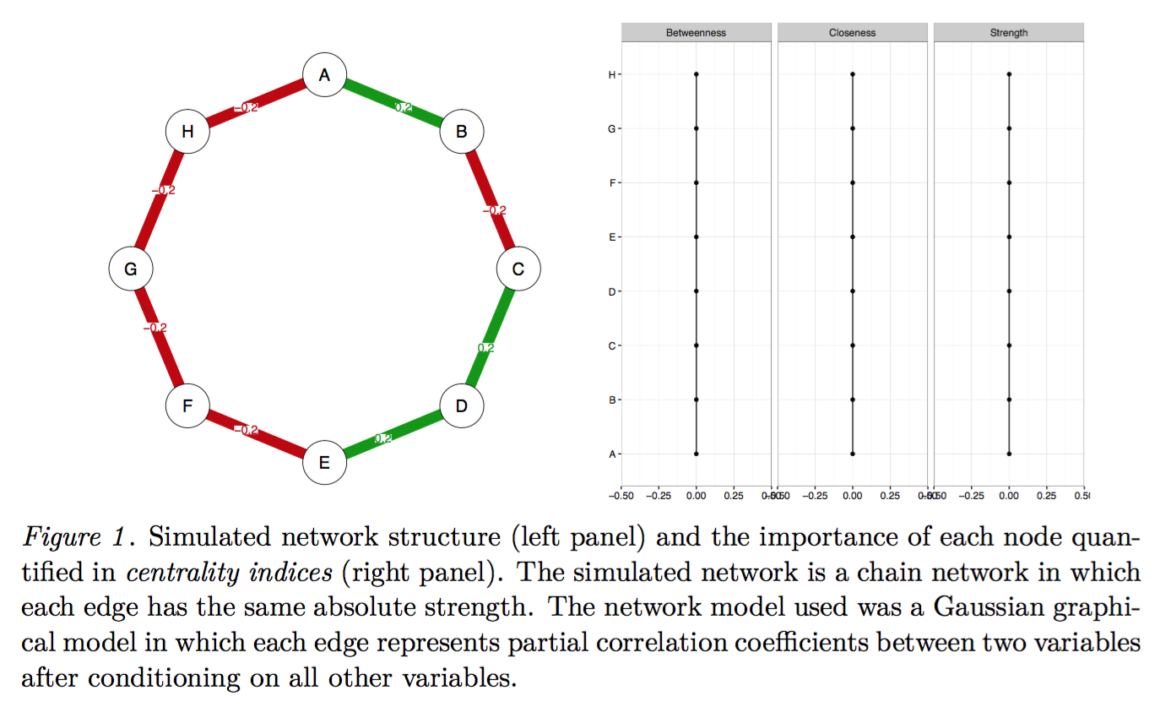
위 사진은 시뮬레이션 된 네트워크의 실제 구조와
중앙값 지수로 정량화 된 각 Node의 중요도를 나타내며,
해당 네트워크는 각 Edge의 절대 강도가 동일하다.
모든 Edge는 동등하며, 모든 중심성 추정치도 동등하다는 것을 뜻한다.
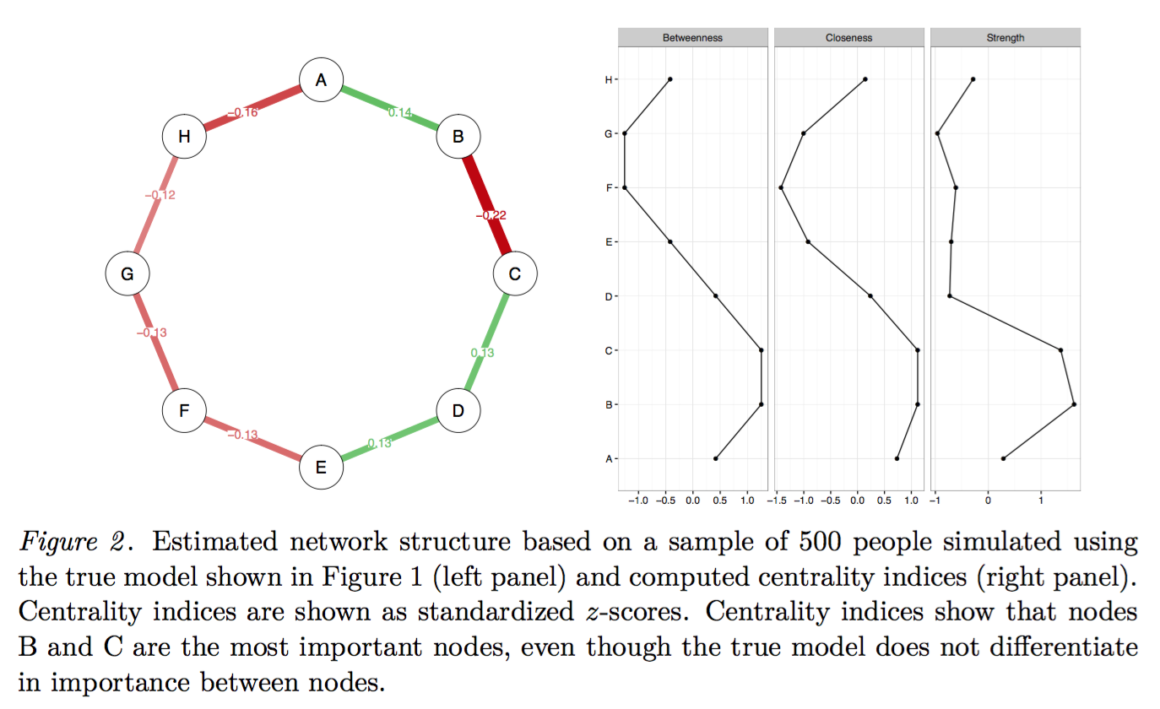
진짜 네트워크에서 n=500에 대한 데이터를 추출해 시뮬레이션 해보면,
8개의 Node와 500명의 사용자가 있는 데이터 세트를 얻을 수 있다.
Edge와 중심성 추정치는 더 이상 동등하지 않다.
B-C가 가장 강하며, B는 가장 높은 중심성을 가지고 있다고 결론 지을 것이다.
그러나 실제 모델에서는 모든 Edge와 중심성 추정치가 같다.
하지만 이는 실제 모델에서 데이터를 시뮬레이션 한 것이기 때문에,
우리는 사실 모든 Edge 및 중심성 추정치가 동등하다는 것을 알고 있다.
이처럼 진짜 네트워크와 시뮬레이션 한 네트워크의 결과가 다른 문제는,
(a) 참여자가 적거나
(b) Node가 많거나
(c) a, b 둘 다일 때더 더욱 눈에 띄게 된다.
우리가 단면적 데이터를 사용해서 만들어낸 현재의 네트워크를 추정하기 위해서는
사실, 매우 많은 양의 매개변수가 필요하기 때문에 이런 문제가 나타나는 것이다.
그래서, 방법은?
Edge Weight에 대한 신뢰구간(CI) 추정
우리는 Edge Weight의 변동성을 평가하기 위해 신뢰구간을 추정할 수 있다.
신뢰구간을 구성하는 간단한 방법에는 부트스트랩 방법이 있다.
<부트스트랩으로 신뢰구간 구하기>
1. 앞서 말한 부트스트랩 방법대로 내 손에 있는 데이터들 중에서 n개를 복원추출한다.
2. 추출한 표본으로부터 알고 싶은 통계량(평균 등)을 구하는 과정을 R(>1000)번 반복한다.
3. x% 신뢰구간을 구하기 위해 R개의 결과 분포의 양쪽 끝에서 (100-x)/2% 만큼 잘라낸다.
4. 절단한 양 끝점들이 x% 부트스트랩 신뢰구간 양 끝점이 되는 것이다.
https://liujingjun.tistory.com/67
상단의 블로그를 참고했습니다.
Tutorial
먼저 네트워크의 Edge Weight를 얼마나 정확하게 추정하는지를 조사하려 한다.
이를 위해 무료로 사용할 수 있는 데이터세트 (N=359)를 가져와서
다음과 같은 17개의 PTSD 증상에서 정규화 된 네트워크를 추정한다.
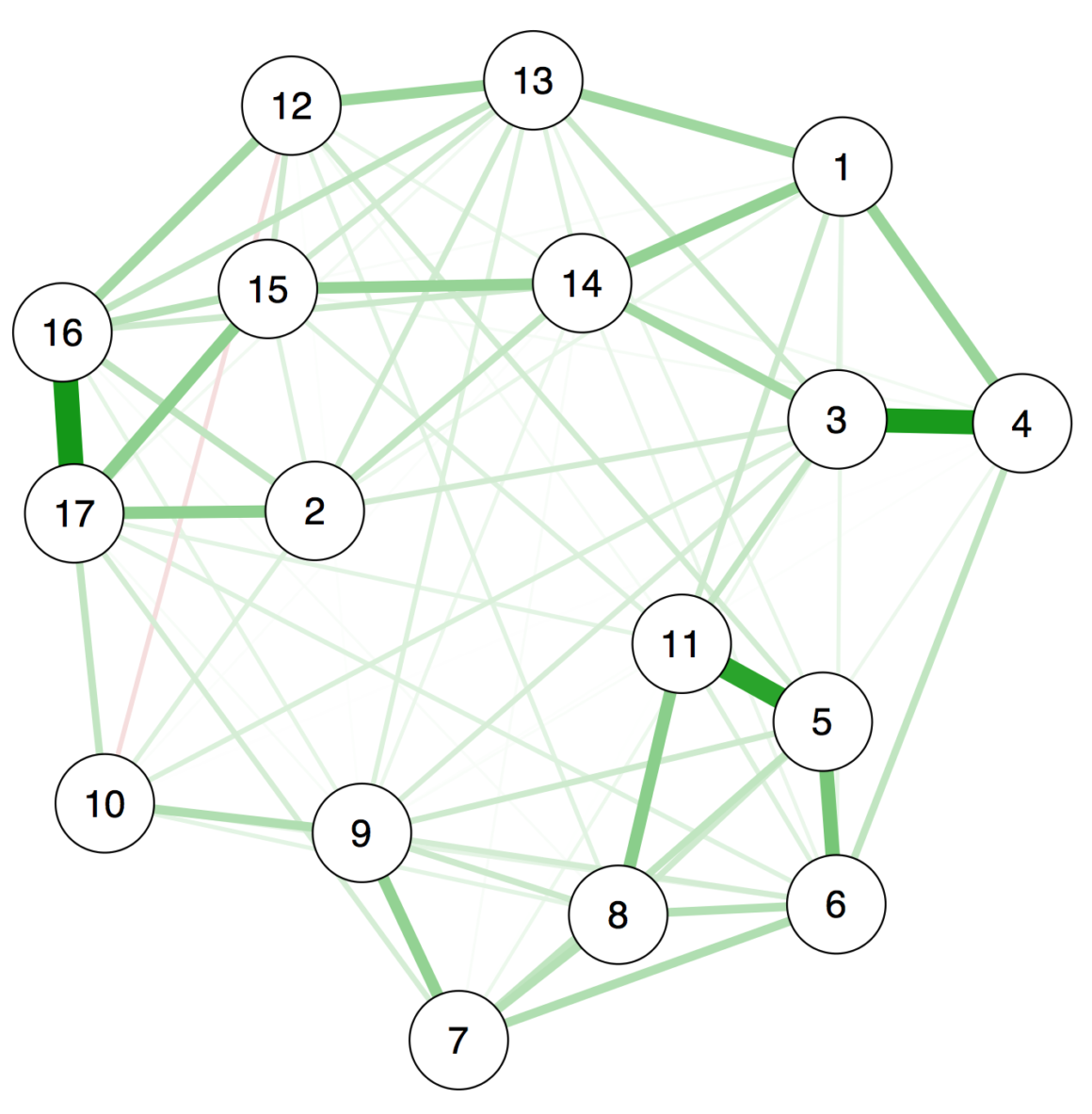
R package bootnet를 사용하면 Edge Weight의 정확도를 추정할 수 있다.
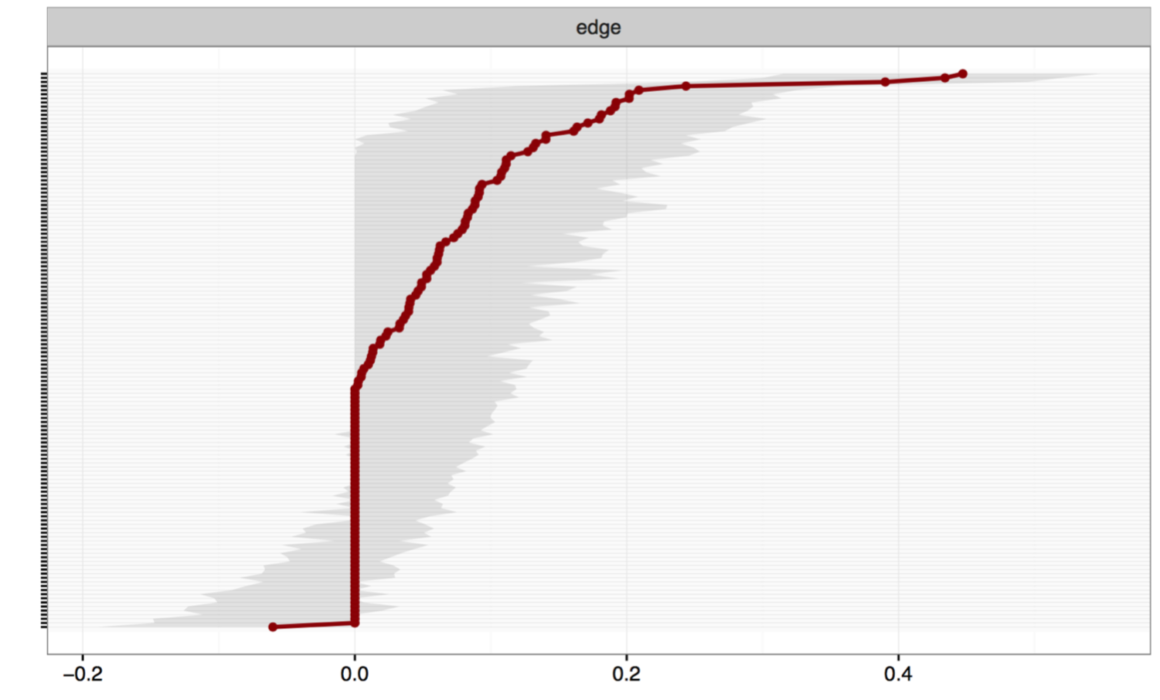
먼저 Y축에는 네트워크의 모든 Edge가 레이블이 생략된 채로 적혀 있고
가장 높은 Edge에서 낮은 Edge로 정렬 된다.
빨간 점은 네트워크 Edge weight이며
회색 영역은 Edge Weight 주변의 95% 신뢰구간을 나타낸다.
Node가 더 적을 수록 그리고 참가자가 더 많아질 수록
Edge의 신뢰성은 높아지고 Edge 주변의 신뢰구간은 작아진다.
해당 케이스는 16-17, 3-4, 5-11을 제외한 대부분의 Edge의 신뢰구간이 겹치는데,
이는 그룹간의 차이가 통계적으로 유의하지 않음을 뜻하고,
위의 네트워크 시각화 결과가 잘못 도출된 것이라는 것을 의미한다.
결국 일부 Edge는 다른 약한 Edge보다 강해 보이지만,
95% 신뢰구간과 겹치기 때문에 실제로는 서로 다르지 않다.
그렇기 때문에 만약 17개의 Node가 고정되어 있는 경우,
여기에 있는 359명보다 더 많은 참여자를 확보해야된다는 결론이 도출된다.
Edge Weight 간의 부트스트랩 차이 테스트
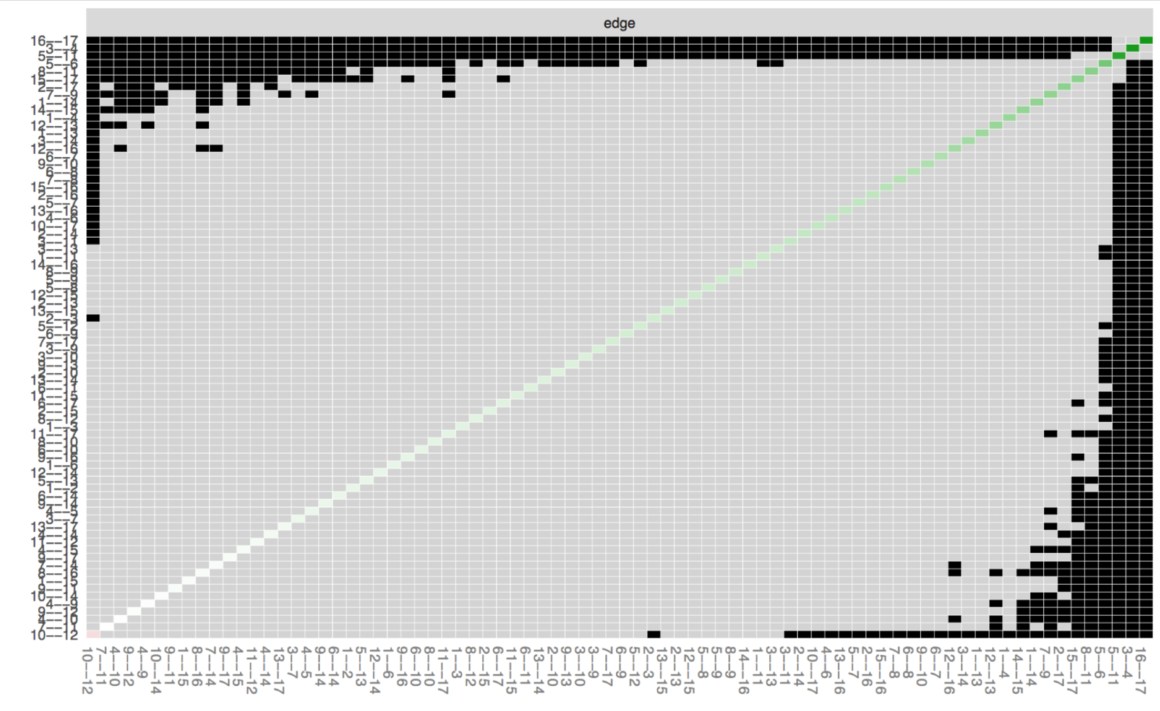
Edge A-B가 Edge A-C보다 유의하게 큰지 여부를 알고 싶을 수 있다.
특정 Edge끼리 서로 다른지의 여부를 확인하려면 bootnet 에서 Edge Weight 차이 검정을 할 수 있다.
x축과 y축은 모든 Edge를 나타내며, 대각선으로는 Edge Weight 값을 나타낸다.
검은 부분은 두 Edge 사이의 상당한 차이가 있음을 뜻한다.
위의 결과를 통해 대부분의 Edge가 유의한 차이가 없다는 것을 이미 알았으므로
검은 부분이 별로 없는 것이 놀라운 결과는 아니다.
중심성 지수 안정성 평가
중심성의 정확성을 통찰하기 위해서는 데이터의 subsets을 기반으로하여
중심성 지수 순서의 안정성을 조사하는 것이 좋다.
Tutorial
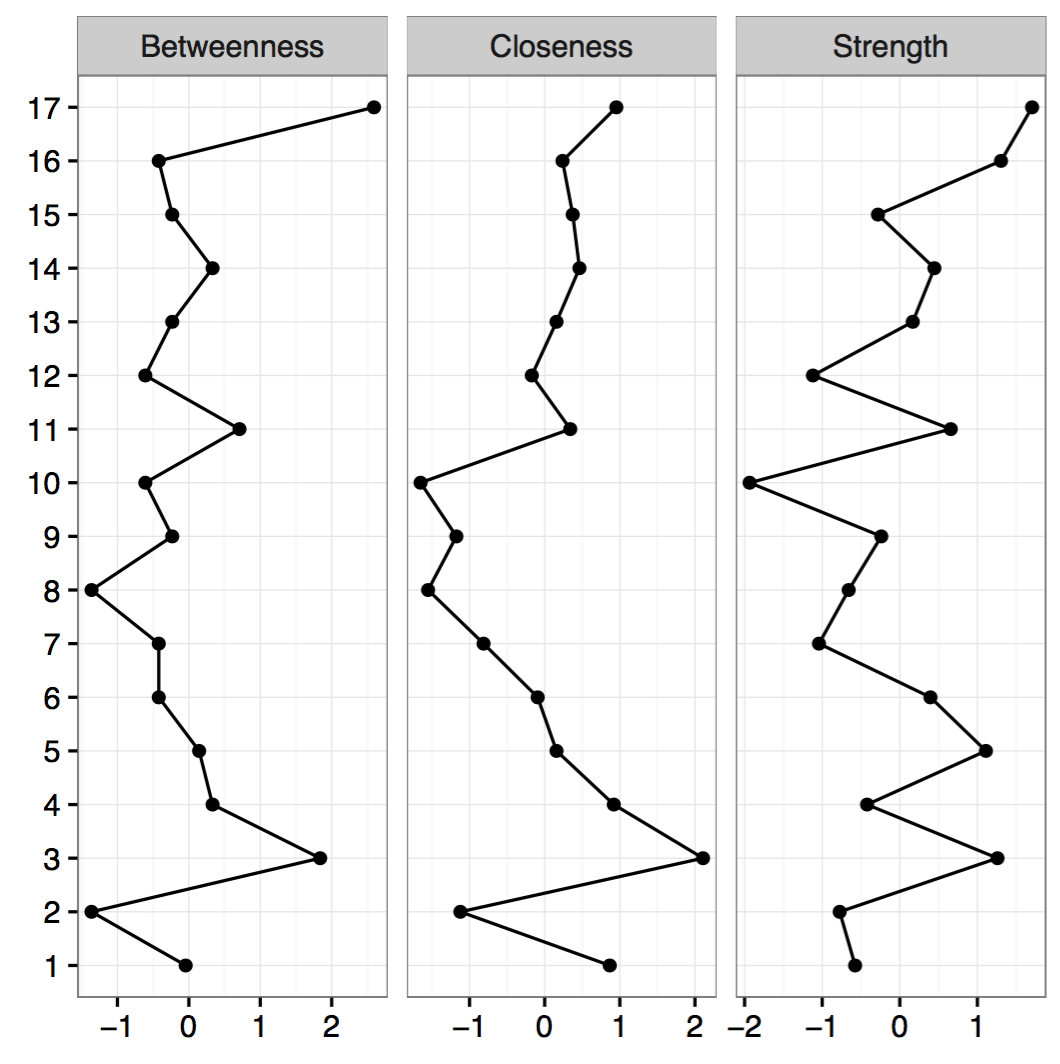
strength 중심성을 보면, Node 17의 중심 강도가 가장 높다.
그러나 위 네트워크 시각화 사진을 보면 17번이 명확히 16번 보다 더 중심적이라고 말할 수는 없는 부분이다.
중심성 지수 간의 부트스트랩 차이 테스트
Node A가 Node B의 중심성 지수보다 유의하게 큰지 여부를 알고 싶을 수 있다.
이제 다시 부트스트랩 방법을 사용한다.
데이터를 샘플링 해서 새 네트워크를 구성하고
중앙값을 다시 추정하는 과정을 수천 번을 반복 한다.
전체 데이터 집합의 중심성 수치의 순서와
참가자의 50%를 떨어뜨린 데이터 집합의 중심성 순서가 매우 유사하다면
중심성의 순서가 안정적이라는 의미다.
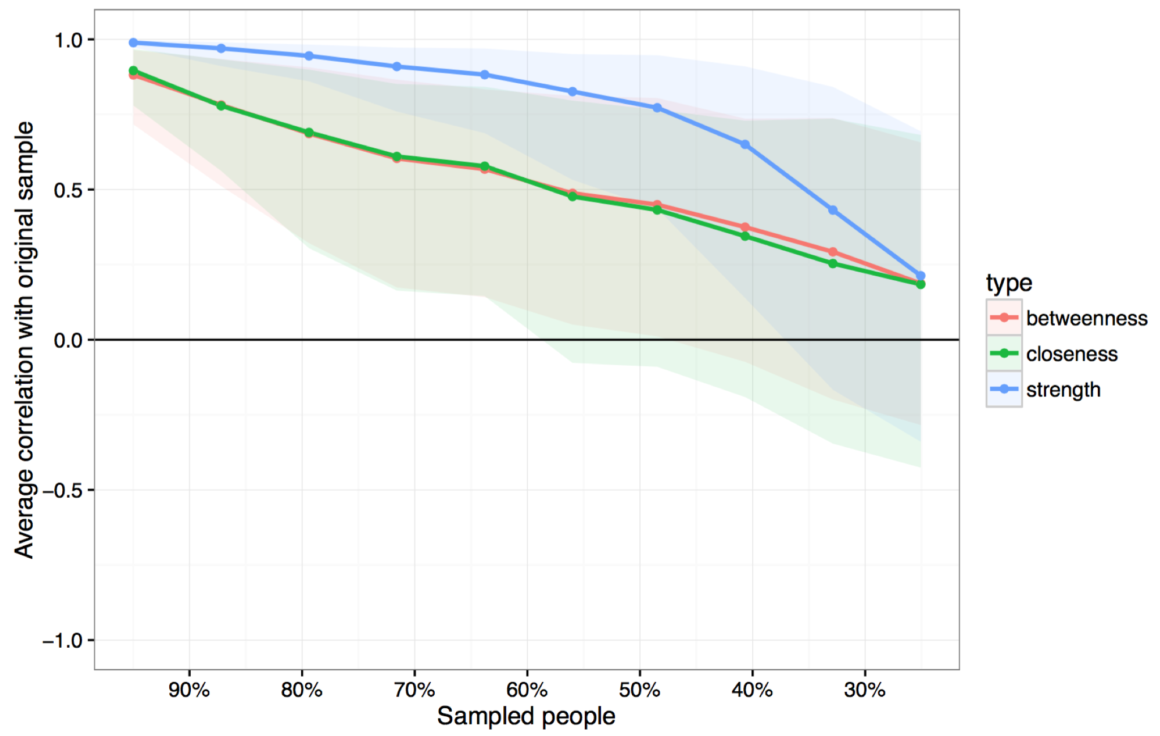
파란색 strength 중심성은 다른 것들에 비해 안정성이 높다는 것을 알 수 있다.
전체 데이터 집합의 strength 중심성 순서와
데이터 중 50%만을 표본으로 추출한 데이터 집합 사이의 상관 관계는 0.75 정도지만
그리 나쁘지 않다고 해석 가능하다.
💡https://psych-networks.com/tutorials/
💡https://link.springer.com/content/pdf/10.3758/s13428-017-0862-1.pdft
