결정트리
결정 트리 (Decision Tree) 이해하기
결정 트리는 데이터 분석과 머신러닝에서 널리 사용되는 지도 학습 알고리즘 중 하나입니다. 이 포스팅에서는 결정 트리의 개념, 동작 방식, 장단점, 활용 사례, 그리고 Python 코드 예제를 통해 결정 트리에 대해 자세히 알아보겠습니다.
1. 결정 트리란 무엇인가요?
결정 트리(Decision Tree)는 트리 구조를 기반으로 데이터를 분류하거나 예측하는 데 사용되는 모델입니다. 각 노드는 하나의 속성을 기준으로 데이터를 분할하고, 최종 리프 노드가 분류 결과나 예측 값을 제공합니다. 이를 통해 사람이 이해하기 쉬운 규칙 기반 모델을 생성할 수 있습니다.
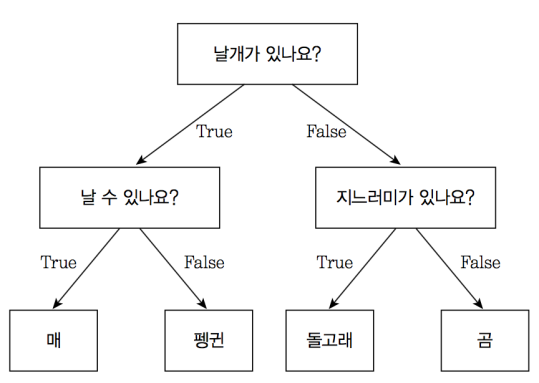
2. 결정 트리의 동작 방식
결정 트리는 다음과 같은 단계로 작동합니다:
- 루트 노드 생성: 전체 데이터 집합에서 최적의 분할 기준을 선택합니다.
- 노드 분할: 각 노드에서 기준 속성에 따라 데이터를 분할합니다.
- 리프 노드 생성: 특정 조건이 충족되면 더 이상 분할하지 않고 리프 노드에 결과 값을 할당합니다.
- 완성: 모든 데이터를 처리할 때까지 위 과정을 반복합니다.
일반적으로 분할 기준은 지니 지수(Gini Impurity) 또는 정보 이득(Information Gain)을 사용하여 결정합니다.
3. 결정 트리의 장점과 단점
장점
- 이해와 해석이 쉬움: 트리 구조로 시각화할 수 있어 비전문가도 결과를 쉽게 이해할 수 있습니다.
- 사전 처리 요구 사항이 적음: 데이터의 스케일링이나 정규화 없이 사용할 수 있습니다.
- 다양한 데이터 타입 지원: 수치형과 범주형 데이터를 모두 처리할 수 있습니다.
단점
- 과적합 위험: 가지치기를 사용하지 않으면 과적합(overfitting)이 발생할 수 있습니다.
- 작은 변화에 민감: 데이터에 작은 변화가 있어도 트리 구조가 크게 달라질 수 있습니다.
- 복잡한 트리 생성 가능: 데이터가 복잡할 경우 매우 깊은 트리가 생성되어 해석이 어려워질 수 있습니다.
4. 결정 트리의 활용 사례
결정 트리는 다양한 분야에서 사용됩니다:
- 의료: 환자의 증상에 따라 질병을 진단하는 데 사용
- 금융: 고객의 신용 점수를 기반으로 대출 승인 여부 결정
- 마케팅: 고객 세분화와 타겟팅 광고 전략 개발
5. 결정 트리 Python 코드 예제
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 모델 생성 및 학습
clf = DecisionTreeClassifier(max_depth=3, random_state=42)
clf.fit(X, y)
# 결정 트리 시각화
plt.figure(figsize=(12, 8))
plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()위 코드는 사이킷런(sklearn) 라이브러리를 사용하여 결정 트리를 학습하고 시각화하는 예제입니다.
정리
결정 트리는 직관적이고 강력한 예측 모델로, 데이터 분석과 머신러닝에서 중요한 역할을 합니다. 그러나 과적합을 방지하고 일반화 성능을 향상시키기 위해 가지치기와 같은 기술을 적절히 활용하는 것이 중요합니다
