Python
사용법

import from 모음
import random as rd => rd.randint(범위시작값,범위끝값) ※ 파이썬에서 얘만 끝값포함Python 함수 모음
\n : 개행
""" : 글자 적힌 그대로 출력
type(대상) : 대상 자료형 확인
isinstance(대상, 자료형) : 대상이 해당 자료형인지 확인(True, False를 반환)
리스트명.append(값) : 맨 뒤에 값 추가
리스트명.insert(인덱스,값) : 원하는 인덱스에 값 추가 (나머지 값들은 한 칸씩 밀림)
del 리스트명[인덱스] : 인덱스에 해당하는 요소를 지움
리스트명.remove(값) : 순차적으로 접근하였을 때 마주친 값 하나를 지움
리스트명.sort() : 오름차순 정렬
리스트명.reverse() : 역순(정렬이 아닌 거꾸로 뒤집음)
리스트명.index() : 값의 위치(인덱스) 반환 → 해당 값의 인덱스를 찾고자 할 때!
len(리스트명) : 길이 확인
range() : 필요한 만큼의 숫자를 만들어내는 함수 (시작값,끝값,{증감량})이스케이프 문자
: 프로그래밍할 때 사용할 수 있도록 미리 정의해둔 문자 조합
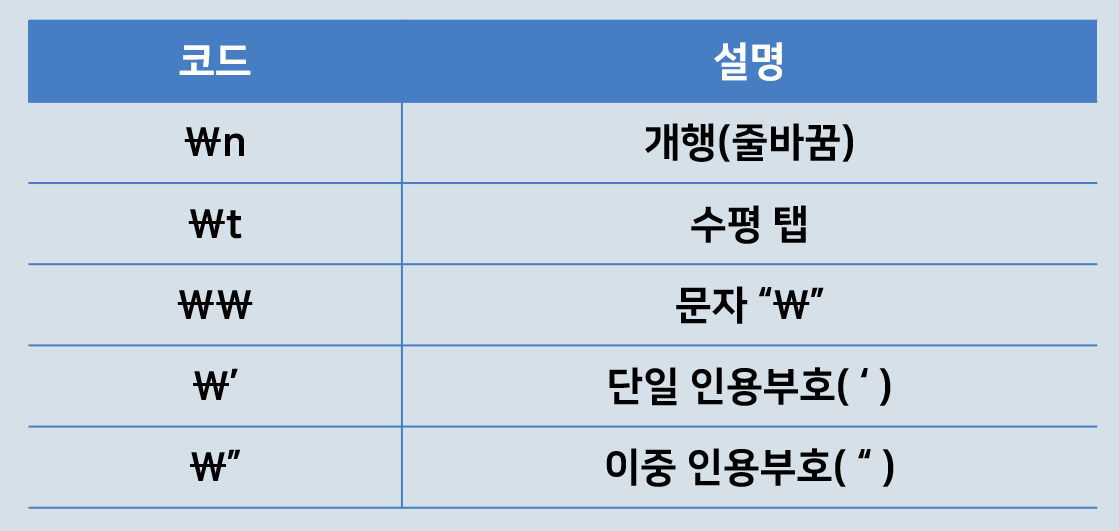
개행시켜 출력하기
파이썬
-동적언어
- 직관적, 명시적, 간결함
파이썬\n 동적언어\n 또는
"""3개 안에 개행시켜 적기두 개 단어 붙이기
s1 = "My name"
s2 = " is MG"
print(s1, s2, sep = "")문자열 인덱싱, 슬라이싱
인덱스(index) : 데이터가 생성될 때 자동으로 부여되는 순서 번호
- 인덱싱(indexing) : 무엇(인덱스)인가를 '가리킨다'라는 의미
- 슬라이싱(slicing) : 무엇(인덱스 범위)인가를 '잘라낸다'는 의미
- 슬라이싱은 시작값은 포함, 끝값은 미포함!- '-'로 뒤부터 슬라이싱 가능
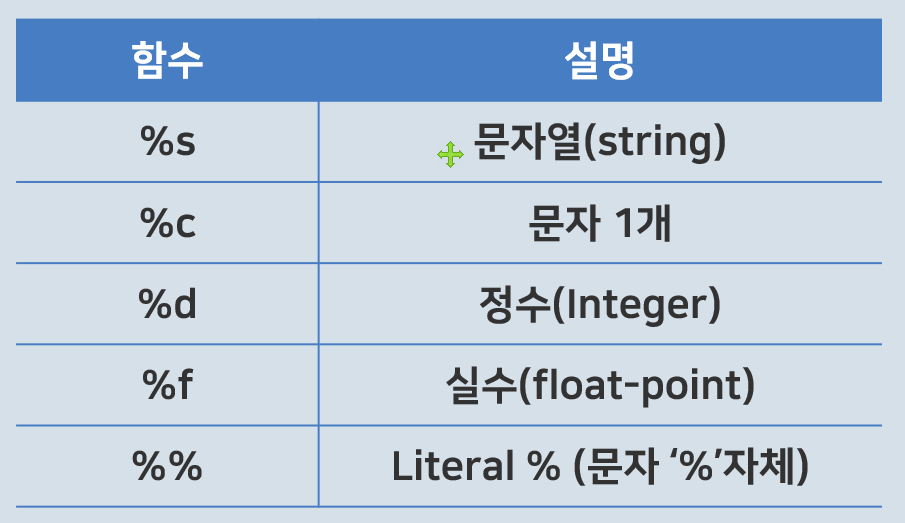
문자열 포매팅 (%기호, format(), f문자열)
첫번째 방법 : % 기호 포매팅
day= 27
month = 9
s = "오늘은 %월 %일 입니다."%(month, day)
두번째 방법 : format()을 사용한 포매팅
day= 27
month = 9
s = "오늘은 {}월 {}일 입니다.".format(month,day)
세번째 방법 : f문자열 포매팅 (가장 많이사용)
day = 27
month = 9
s = f"오늘은 {month}월 {day}일 입니다."문자열 포맷코드
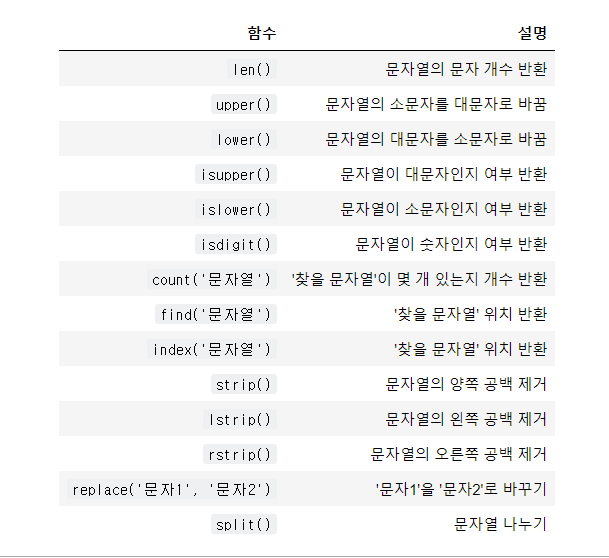
문자열 함수
숫자와 문자열 사칙연산(강제 형변환)
사용자한테 값 입력받아서 사칙연산 결과 뽑기
=> num1 = int(input("정수입력"))
num2 = int(input("정수입력"))
print(f"나누기 결과 : {num1 / num2:.2f}") 문자열 곱하기
s= "-"
10개 곱하기
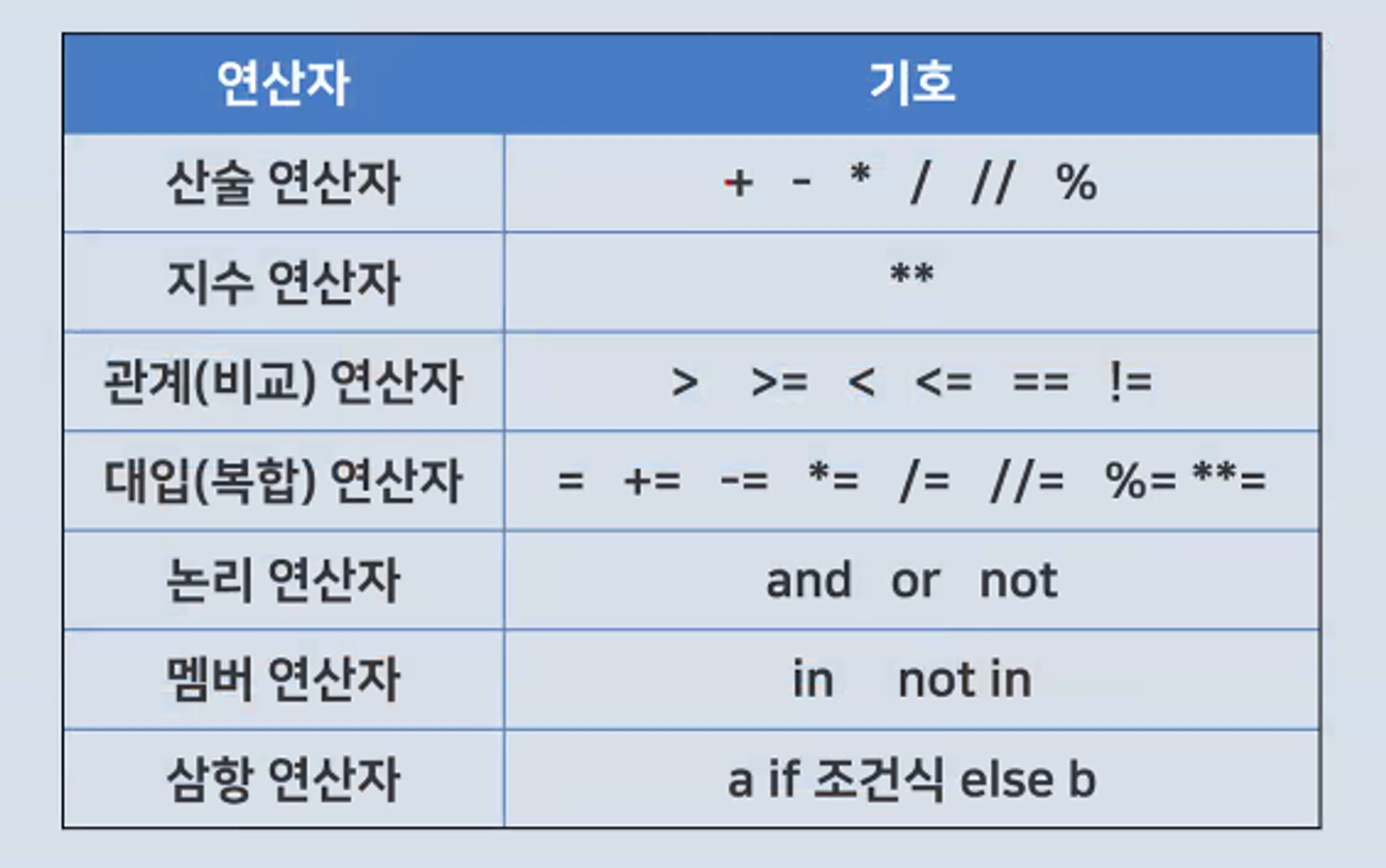
=> print(s*10)연산자(지수,복합,비교,논리,멤버)
3의 3승 구하기
=> 3**3a와 b값 바꾸기
a = 3
b = 7
=> temp = a
a = b
b = temp
=> a, b= b,a논리연산자 (and,or,not)과 비트연산자(&,|)는 다름
=> 논리연산자는 단일값 전용, 비트연산자는 다중값
비트는 0 or 1로만 출력 논리연산자는 값이 하나 ex) int
삼항연산자
a if 조건식 else b
True면 a실행, False면 b실행
score= 50
만약 점수가 60점이 넘는다면 트루 아니면 펄스
=> print(True) if score>=60 else print(False)
두개의 정수를 입력받아 큰 수에서 작은 수를 뺀 결괏값을 출력
=> num1 = int(input("정수1")
num2 = int(input("정수2")
num1-num2 if num1>num2 else num2-num1
정수를 입력받아 홀수인지, 짝수인지 출력
=> print(홀수) if num1%2==1 else print(짝수)조건문
점수 입력받아서 학점 부여하기
=> score = int(input("점수입력"))
if score <= 100 :
if score >= 90 :
grade = 'A'
elif score >= 80 :
grade = 'B'
elif score >= 70 :
grade = 'C'
elif score >= 60 :
grade = 'D'
else :
grade = 'F'
print(f"{score}점은 {grade}학점 입니다.")
else :
print("잘못 입력하셨습니다.")리스트
: 파이썬의 자료형 중 하나 java의 배열느낌
순서(인덱스가 존재)가 있는 수정 가능(삽입, 삭제, 수정)한 객체의 집합
대괄호([ ])로 작성되어지며, 리스트 내부의 값은 콤마(,)로 구분
생성
list1 = [2,5,7,9,10]
list1[3] => 9
list2 = [1,2,3,['a','b','c']]
list2[3][1] => 'b'
temp = list2[3]
temp[1] => 'b'
list3 = [0,1,2,3,4]
list3[1:3] => [1,2]
리스트 더하기
list4 = [1,2,3] list5 = [4,5,6]
list4 + list 5 => [1,2,3,4,5,6]
list4 *4 => [1,2,3,1,2,3,1,2,3,1,2,3]
추가 (.append(값), .insert(인덱스,값))
list6 = [0,1,2,3,4]
list6.append(5)
list6 => [0,1,2,3,4,5]
list6.insert(3,10)
list6 => [0,1,2,10,3,4,5]
수정 (인덱싱이나 슬라이싱 후에 대입)
list6[3:5] = [7]
list 6 => [0,1,2,7,4,5]
삭제 del리스트명[인덱스], 리스트명.remove(값)
del list6[3]
list6 => [0,1,2,4,5]
del list6[3:]
list6 =>[0,1,2]
list7 = ['a','b','c','d','b','e','f']
list7.remove("b")
list7 =>['a','c','d','b','e','f']
list8 = [9,77,13,51,100,3]
list8.sort() => [3,9,13,51,77,100]
list8.reverse() =>[3,100,51,13,77,9]
list8.sort() +
list8.reverse() => [100,77,51,13,9,3]
list8.index(13) => 3
len(list8) =>튜플
: 파이썬의 자료형 중 하나
순서(인덱스)가 있으나, 수정 불가능한 객체의 집합
소괄호(( ))로 작성되어지며, 튜플의 내부 값은 콤마(,)로 구분
생성
tuple1 = (0,1,2,3,('a','b','c'),5)
print(tuple1[2]) =>2
print(tuple1[1:4]) =>(1,2,3)
print(tuple1[4][1]) =>'b'
tuple1[0] = 0
=> 추가 삭제 불가반복문
while문 (while True :)
while문 사용을해서 파이썬 최고를 13번 출력
=> cnt = 1
while cnt <= 13 :
print('파이썬 최고')
cnt += 1
break문을 활용해서 동일하게
=> cnt = 1
while True :
print("파이썬 최고!")
if cnt >= 13 :
break
cnt += 1
랜덤으로 1부터 50사이의 숫자를 뽑으면
뽑은 숫자를 맞추는 up, Down 게임 구현
=>
from random import randint as rd
number = rd(1,50)
while True :
user_input = int(input("숫자를 입력하세요 >> "))
if user_input > number : # 사용자의 입력값이 컴퓨터가 뽑은 랜덤값보다 큰 경우
print(f"{user_input}보다 작은 수 입니다.")
elif user_input < number : # 사용자의 입력값이 컴퓨터가 뽑은 랜덤값보다 작은 경우
print(f"{user_input}보다 큰 수 입니다.")
elif user_input == number :
print("정답을 맞추셨습니다.")
breakfor문 (for 변수 in 시퀀스자료구조 :)
list1 = [1,2,3,4,5,6,7,8,9,10]
list1[::-1] => [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
97부터 77까지 출력하기
=> for i in range(97,76,-1) :
print(i, end=" ")
list1 = [[1,2],[3,4],[5,6]]
1 2
3 4
5 6 으로 출력 하려면?
=> for i,j in list1
print(i,j)
가장 큰 수를 찾기
list2 = [4,5,2,1,99,15,2,7,27]
=> max_data = list2[0]
for i in list2 :
if max_data< i :
max_data=i
print(max_data)
1 ~ 100 사이의 숫자 중 3의 배수인 값들의 합 출력
=> sum = 0
for i in range(101) # 시작값은 기본값이 0
if i%3==0 :
sum += i
print(sum)
for문을 이용하여 구구단 2단 출력
=> for dan in range(2,10) :
for i in range (1,10) :
print(f{dan} * {i} = {dan*i}, end = "\t")
print
별찍기(사용자가 입력한 정수만큼)
=> user_input = int(input("정수를 입력 >> "))
for i in range(1,user_input+1) :
print("*" * i)영화리뷰 분석하기

#파일 불러오기
import pickle
with open('./movie_review.pkl','rb') as f :
data = pickle.load(f)
#1
=>len(data)
#2
=> length = 0
cnt = len(data)
for i in data :
length += len(i[0])
print(f"리뷰의 평균 길이는 {length/cnt}개 입니다")
#3
=>
pos = 0
neg = 0
for i in data :
if i[1]==1 :
pos += 1
else :
neg += 1
print (pos)
print (neg)
#4
=>
maximum = len(data[0][0])
for i in data :
if maximum < len(i[0]) :
maximum= len(i[0])
max_content = i[0]
print(f"리뷰 최대 길이는 '{maximum}'입니다.")
print(max_content)
#5
=>cnt = 0
word = 'ㅋ'
for i in data :
if 'ㅋ' in i[0] : #댓글을 인덱싱해서 'ㅋ'이 들어있니?
cnt+=1
print(f"'ㅋ'이 포함된 리뷰는 {cnt}개 입니다.")
#6
=>cnt=0
word = input('찾을 데이터를 입력하세요')
for i in data :
if word in i[0] :
cnt += 1
print(f"'{word}'가 포함된 리뷰는 {cnt}개 입니다.") 딕셔너리(dictionary)
: 딕셔너리는 {변할 수 없는 key : 변해도 되는 Value}를 한 쌍으로 갖는 자료형
각각의 속성이나 개성을 표현할 때 딕셔너리를 사용
기호는 중괄호({}) 사용, 구분 기호는 콤마(,)
Key와 Value는 콜론(:)을 사용
생성
dic1 = {"key" : "Value", "name" : "BG", "age" : 20, "phone":"010-0000-0000"}
추가
=>dic1[0] = "01/05"
삭제
=>del dic1["age]
인덱싱 2가지
=> 에러발생하는것 dic1[phone]
=> 예외처리해주는것 dic1.get("phone")
수정
=>dic1["phone"] = "010-1111-1111"
딕셔너리 키값만 뽑아오기
=>dic1.keys()
딕셔너리 밸류값만 뽑아오기
=>dic1.values()
딕셔너리 키와 밸류값 뽑기
=>dic1.items()
key값만 뽑아보기 (for문)
=>for key in dic1.keys() :
print(key)
value값만 뽑아보기 (for문)
=> for value in dic1.values() :
print(value)
키와 밸류값 뽑기 (for문)
=> for key,value in dic1.items()
print(key,value)
딕셔너리 멤버연산자 활용
=>
#key값 in 딕셔너리명 → 딕셔너리의 키에 한해서만 동작
# value값은 조회불가!!
print("name" in dic1)
print("BG" in dic1)
score_dic ={'이름': ['임경남', '김은비', '송승호', '박원호', '김민수'],
'Python' : [90, 100, 85, 90, 80],
'Java' : [85, 80, 100, 95, 85],
'HTML/CSS' : [75, 70, 90, 80, 90]}
python과목의 평균 점수 구하기
=> py_avg= sum(score_dic['Python'])/len(score_dic['Python'])
if문으로 python과목 평균 구하기 =>
# if문 사용
py_avg = 0
for key in score_dic.keys() :
if key == 'Python' :
py_avg = sum(score_dic[key])/len(score_dic[key])
함수
: 호출 될 때 특정 기능을 실행하는 재사용 가능한 코드 블록
함수의 목적
- 반복적인 프로그래밍을 피할 수 있음
- 모듈화로 인해 전체적인 코드의 가독성이 좋아짐 (호출만 하면 되기 때문에)
- 프로그램에 문제가 발생하거나 기능의 변경이 필요할 때, 쉽게 유지보수가 가능
함수의 특성
- 기본값 설정가능
```ex) def power_of_N(num, power=2) return num**power => power_of_N(3)=> 9
```- return의 결괏값은 하나 (return을 두개로 하면 튜플)
- 결괏값과 반환값은 다르다!! (print 와 return)
정의
def num_sum(num1, num2) :
result = num1 + num2
return result
함수 호출
n1 =3
n2 = 10
num_sum(n1,n2)
문자열을 입력받아서 'ㅋ'을 제거하고 돌려주는 함수 정의
def s_replace(string1):
=> result = s_replace.replace('ㅋ','')
return result독스트링
: 정의된 함수에 대해 설명문을 작성하는 기능
"""""" (긴 줄 문자열 기호)
함수에서 매개변수 개수 모를때 (가변 매개변수)

매개변수 모르고 딕셔너리형태로 사용할때 (키워드 가변 매개변수)
Numpy Library
: Numerical Python의 약자(numpy)
- Python에서 수치계산을 위한 핵심 라이브러리
- ndarray(N-dimensional array) 자료 구조를 지원```
import numpy as np
Numpy 함수 모음
.shpae => 크기 확인하기
.ndim => 차원 확인하기
.size => 각각 요소들의 개수를 반환 cf) len() => 배열의 첫번째 차원의 길이를 반환
np.zeros => 모든 값을 0으로 초기화 (2차원 이상이면 튜플로 감싸줘야함)
np.full => 모든 값을 원하는 값으로 초기화 ((행,열),원하는 값)
np.arange => np.arange(시작값, 끝값, 증감량)
np.unique() => np.unique() → 유일한 값을 변환
np.mean(arr) => 평균
np.sqrt(arr) => 제곱근(루트)
np.loadtxt('경로 및 파일명.확장자', delimiter='구분자', dtype = np.데이터타입)
.append => 추가
.reshape() => 원하는 행,열로 만들기
ndarray
- 다양한 수학 함수 지원
- 빠른 연산 속도 지원
- 브로드 캐스팅(차원을 동일시 하는 기능)
- 다차원의 배열 지원
- array 내부에는 동일한 자료형을 가짐
- 각 값들은 인덱스(index)가 부여되어 있습니다.(순서가 있다.)
ndarray 생성하기
1번째 방법 (1차원)
#시퀀스 자료형을 형변환 하는 방법
list1 = [1,2,3,4,5]
arr1 = np.array(list1)
2번째 방법 (1차원)
# 직접 array화 시켜주는 방법
arr2 = np.array([2,3,4,5,6])
3번째 방법 (2차원)
list2 = [[1,2,3],[4,5,6]]
arr3 = np.array(list2)브로드캐스팅
# 브로드 캐스팅
# 차원 수를 동일시 하는 기능
# 리스트의 경우 문자열을 연결하듯이, 하나의 리스트로 이어붙임
list1 = [1,2,3]
list2 = [4,5,6]
print(list1 + list2, end = "\n\n")
# ndarray의 경우 차원을 인식해서 각각의 요소들의 연산을 수행
arr1 = np.array(list1)
arr2 = np.array(list2)
print(arr1 +arr2, end = "\n\n")
#2차원과 1차원을 더했더니, 각각의 요소들을 찾아서 연산을 수행
arr3 = np.array([[1,2,3],[4,5,6]])
arr4 = np.array([7,8,9])
print (arr3 +arr4)
# 1차원과 0차원(요소 하나)를 곱했더니, 각각의 요소들을 찾아서 연산을 수행
arr5 = np.array([1,1,1])
arr5 * 5함수화하기
def array_info(array) :
~
def array_info(array) :
print(array)
print(f"shape (크기) : {array.shape}")
print(f"ndim (차원) : {array.ndim}")
print(f"size(요소 전체 개수) : {array.size}")
print(f"dtype(데이터 타입) : {array.dtype}")dtype과 shape 변경, reshape
# ndarray 생성할때 dtype 변경
temp1 = np.array(list3)
temp2 = np.array(list3, dtype = np.int64)
# 만들어진 array의 요소 dtype 변경
※ 한 다음 변수에 담기 (astype)
temp1 = temp1.(astype(np.int64)
# array 모양 바꿔주기
# 2차원의 경우 행과 열의 값이 맞게 떨어져야함 → size(요소 전체 개수)가 같아야함!
# reshape(행, 열)
temp1 = temp1.reshape(3,2)특정한 값으로 ndarray 생성하기
# 모든 값을 0으로 초기화
# np.zeros((행, 열)) → 2차원 이상의 array인 경우 튜플로 감싸주어야 함!
arr_zeros = np.zeros((5,2))
np.ones => 모든 값을 1로 초기화
np.full((행,열), 원하는값) -> 2차원 이상의 array인 경우 튜플로 감싸주어야 함
#랜덤값으로 배열 생성하기
# np.random.randint(시작값, 끝값 {, size=(행,열)})
# random 라이브러리의 randint는 끝값을 포함했었음
# np에서 제공하는 randint는 끝값을 포함하지 않음
arr_randint = np.random.randint(1,11, size = (3,2))실습
# 1~50이 담긴 1차원 array 생성(리스트 활용)
list1 = []
for i in range(1,51) :
list1.append(i)
arr = np.array(list1)
# ndarray로 범위 만들기
# np.arange(시작값, 끝값, 증감량)
arr2 = np.arange(1,51)
arr2 = arr2.reshape(5,10)ndarray 연산
# 리스트의 경우 문자열을 연결하듯이, 하나의 리스트로 이어붙임
list1 = [1,2,3]
list2 = [4,5,6]
print(list1 + list2, end = "\n\n")
[1,2,3,4,5,6]
# ndarray의 경우 차원을 인식해서 각각의 요소들의 연산을 수행
arr1 = np.array(list1)
arr2 = np.array(list2)
print(arr1 +arr2, end = "\n\n")
[5 7 9]
#2차원과 1차원을 더했더니, 각각의 요소들을 찾아서 연산을 수행
arr3 = np.array([[1,2,3],[4,5,6]])
arr4 = np.array([7,8,9])
print (arr3 +arr4)
[[8 10 12] [11 13 15]]
# 1차원과 0차원(요소 하나)를 곱했더니, 각각의 요소들을 찾아서 연산을 수행
arr5 = np.array([1,1,1])
arr5 * 5
array([5,5,5])
# 각각의 요소에 +3씩 연산
arr3 +3 ndarray 인덱싱 & 슬라이싱
인덱싱(indexing) : 값을 가리키다 → 자료구조 내에서 "1개의 요소"에 접근하는것
슬라이싱(slicing) : 값을 잘라오다 → 자료구조 내에서 "여러개의 요소"에 접근하는것
인덱스(index) : 데이터의 순서 → 방번호
# 1차원 array 생성 후 인덱싱
arr_1 = np.arange(10) # 시작값 생략 가능
# 슬라이싱
arr_1[3:9]
# 슬라이싱을 하고 한번에 데이터 넣기
list1 = []
for i in range(10) :
list1.append(i)
# 리스트값 수정
# 리스트는 슬라이싱하고 값을 넣게 되면 벙뮈 자체가 하나의 요소로 반환
list1[3:8] = [10,2]
print(list1)
# array값 수정
# array는 슬라이싱 된 요소들에 각각 하나씩 값을 수정
arr_1[3:8] = 102차원 array 인덱싱 & 슬라이싱
인덱싱 : array명[행값,열값]
슬라이싱 : array명[행의 시작값:행의 끝값 ,열의 시작값 : 열의 끝값]
# 2차원 array
arr2 = np.arange(1,51).reshape(5,10)
print(arr2[3,3]) # 튜플인덱싱, 한 번의 연산을 수행
# 2차원 array 슬라이싱
# array명[:,:]
arr2[2:5,:9]
print(arr2[:,0]) # 인덱싱과 슬라이싱 섞어서 가능!데이터 경로지정
절대경로
/ => 루트 디렉토리, 파익 시스템의 가장 상위 디렉토리
상대경로
./ => 현재 디렉토리, 생략 시 default값
../ => 상위 디렉토리를 나타냄. 한단계 위 디렉토리데이터 읽어오기
# 1. 데이터 읽어오기(.txt 파일 형식의 확장자 읽어오기)
# np.loadtxt('경로 및 파일명.확장자', delimiter='구분자', dtype = np.데이터타입)ndarry 연산 함수
sum(arr)을 하면 두 요소의 합을 해서 값이 나옴
ex) array([[2, 1, 3, 3, 2],
[4, 9, 2, 3, 9]])
sum(arr)=> [ 6 10 5 6 11]
print(arr.mean())
print(np.mean(arr))
# mean() : 평균
# sqrt() : 제곱근(루트)연산에 사용하는 함수들
단일배열
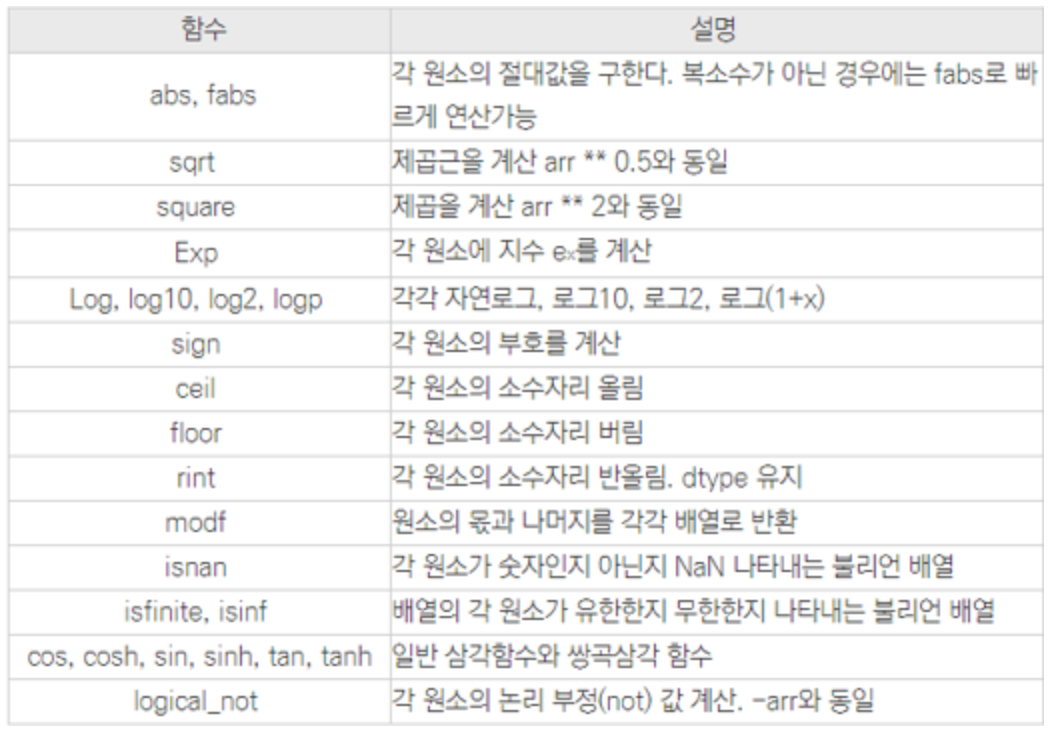
서로 다른 배열
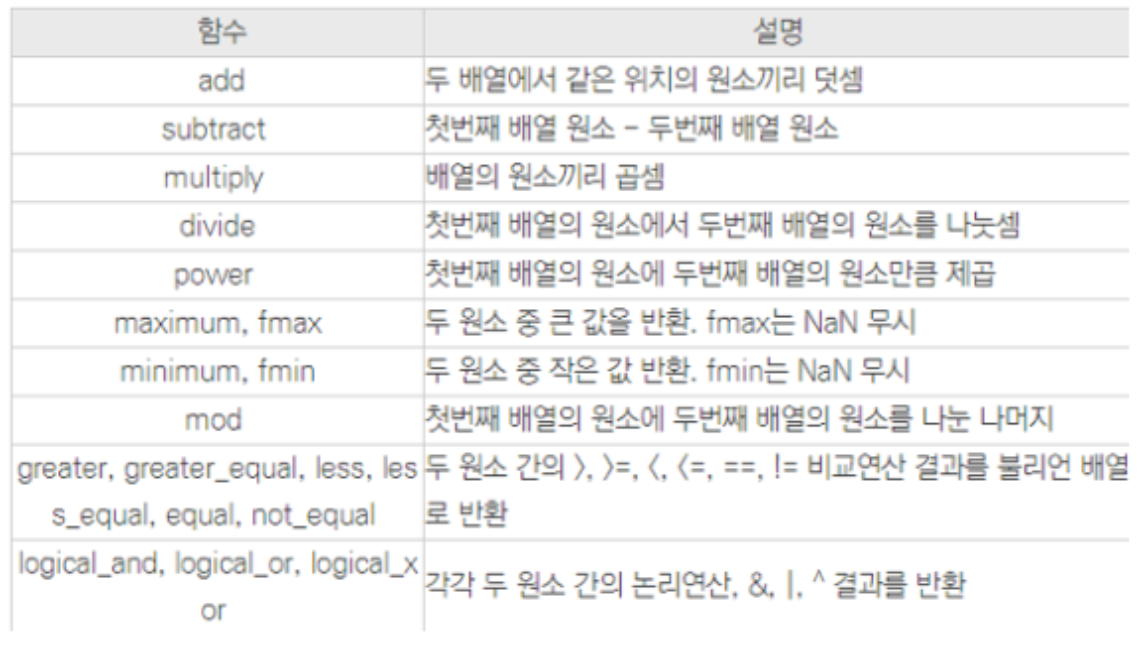
Boolean 인덱싱
: 배열 안에서 조건을 충족(특정 조건을 만족)하는 True인 값들만 추출해주는 인덱싱 방법
간단히 말해서 필터링을 연상
score = np.array([80,75,55,96,30])
# 80점 이상인 데이터만 추출
# 1. mask 만들기
mask = score >=80
# 2. 인덱싱
score[mask]
score[score>=80]실습(리스트 불리언인덱싱하기, csv 파일로 저장)
np.loadtxt("./data/new_ratings.dat",delimiter="|", dtype = np.int64)
# np.unique() → 유일한 값을 변환
#반복문의 실행 현황을 알려주는 라이브러리
from tqdm import tqdm as tq
# 리스트로는 고급인덱싱(불리언인덱싱)이 불가
# 그래서 array화(형변환)
# 근데 담고 봤더니, 동일한 자료형만 담는 array 특징 때문에 id값마저 실수로 담김
# 그래서 int형으로 바꾸면서 형변환
user_mean_arr=np.array(user_mean_list, dtype=np.int64)
# 각 사용자의 1번열(평균 평점)에 접근해서 평균 평점이 4점 이상인 행만 불리안인덱싱
mask= user_mean_arr[user_mean_arr[:,1]>=4]
# np.savetxt("저장할 파일명.확장자", array명, delimiter='구분자', fmt='데이터 표현')
np.savetxt("영화평점 분석.csv", mask, delimiter=',', fmt='%.3f')Pandas
: - Panel Datas의 약자
1. 다양한 파일 형식 지원
2. 데이터 정제 및 조작에 특화된 라이브러리
- 데이터 이상치, 결측치, 중복 제거 등 다양한 기능을 제공
- 데이터 필터링, 병합, 피벗 등을 지원하여 복잡한 데이터를 손쉽게 분석
3. DataFrame, Series 자료 구조 지원
- DataFrame : 2차원 이상
- Series : 1차원
- ndarray를 활용하여 만든 자료 구조이기 때문에 NumPy Library와 상호작용이 뛰어남import pandas as pd
Series
: java의 배열같은 의미, 1차원 데이터에 사용되는 자료구조
Series 함수 모음
pop = pd.Series([9668465, 3391946, 2642828, 1450062], index=['서울','부산','인천','광주']
# 원본 유지하면서 복사하기
pop2 = pop.copy()
# Series 값 확인하기
display(pop.values)
display(pop.array)
pop.index => 인덱스명 확인
pop.dtype => 자료형 확인
type(pop) => Series type 확인
pop.name = '인구' => Series에 이름 지정 -> 컬럼명 지정
Series 인덱싱, 슬라이싱
#인덱싱
pop[1],pop['부산'] => 딕셔너리(key값)처럼 둘다 가능
#다중 인덱싱
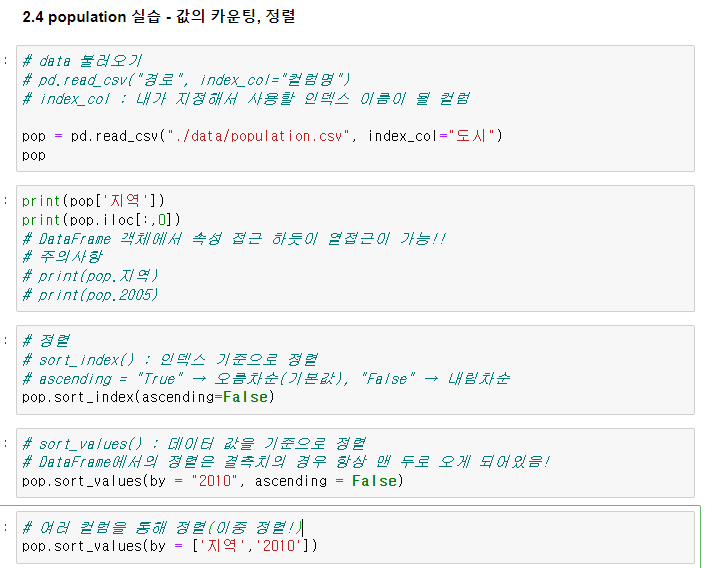
pop[[0,3,1]], pop[['서울','광주','부산'] => 둘다 가능loc, iloc
pop.loc['부산'] => loc 인덱싱 ('인덱스 이름'으로 접근)
pop.iloc[0:2] => iloc 인덱싱('행번호'로 접근)
pop.loc[['부산','광주']] => loc 다중인덱싱
pop.iloc[[1,3]] => iloc 다중인덱싱
# 응용!
target = ['광주','부산']
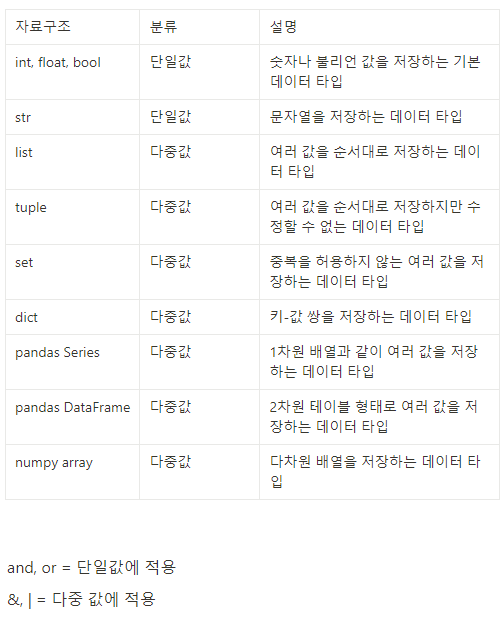
pop.loc[target]| 자료구조 | 분류 | 설명 |
|--------------------|-----------|------|
| int, float, bool | 단일값 | 숫자나 불리언 값을 저장하는 기본 데이터 타입 |
| str | 단일값 | 문자열을 저장하는 데이터 타입 |
| list | 다중값 | 여러 값을 순서대로 저장하는 데이터 타입 |
| tuple | 다중값 | 여러 값을 순서대로 저장하지만 수정할 수 없는 데이터 타입 |
| set | 다중값 | 중복을 허용하지 않는 여러 값을 저장하는 데이터 타입 |
| dict | 다중값 | 키-값 쌍을 저장하는 데이터 타입 |
| pandas Series | 다중값 | 1차원 배열과 같이 여러 값을 저장하는 데이터 타입 |
| pandas DataFrame | 다중값 | 2차원 테이블 형태로 여러 값을 저장하는 데이터 타입 |
| numpy array | 다중값 | 다차원 배열을 저장하는 데이터 타입 |DataFrame
2차원 데이터에서 사용되는 pandas 자료 구조
첫번째 방법
# 딕셔너리를 통한 컬럼 단위로 생성하기
data = {'ITPM':[463,9543,57],
'업무분석가': [544,11226,68],
'IT아키텍트':[518,10672,64],
'UIUX개발자':[291,6003,36]}
df = pd.DataFrame(data)
# index명 수정
df.index = ['일평균임금', '월평균임금', '시간평균임금'] (인덱스의 개수만큼 적어주기)두번째 방법
data2 = [[463,544,518,291],
[9543,11226,10672,6003],
[57,68,64,36]]
colums = ['ITPM', '업무분석가', 'IT아키텍트','UIUX개발자']
rows = ['일평균임금', '월평균임금', '시간평균임금']
# DataFrame(데이터, index=[인덱스명1, 인덱스명2...], columns = [컬럼명1, 컬럼명2....])
df2 = pd.DataFrame(data2, index=rows, columns=colums)전치 : 행과 열을 바꿈 df2.T
df2.values(값)
df2.index(행값)
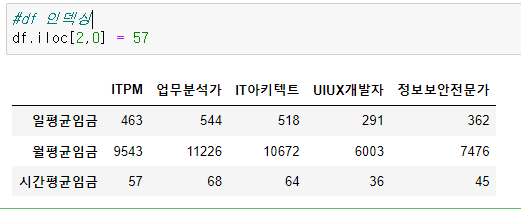
df2.columns(열값)DataFrame 인덱싱, 슬라이싱
display(df['ITPM']) # 1차원 인덱싱
display(df[['ITPM']]) # 2차원 인덱싱추가하기 -> 하나의 Series를 추가
df['정보보안전문가'] = [~,~,~]
loc[]인덱서, iloc[]인덱서
loc[] 인덱서
location → "인덱스 명"과 "컬럼명"을 가지고 값을 인덱싱/슬라이싱
df.loc['행의 시작 이름'{:'행의 끝 이름','열의 시작 이름':'열의 끝 이름'}]
df.loc['a',:] == df.loc['a']
iloc[] 인덱서
integer location → "인덱스 번호"과 "컬럼 번호"을 가지고 값을 인덱싱/슬라이싱
df.iloc['행의 시작 번호'{:'행의 끝 번호','열의 시작 번호':'열의 끝 번호'}]
df.iloc[0,:] == df.iloc[0]
# iloc의 경우 끝 값 포함하지 않음인덱싱은 끝값 빼지 않으니 주의
ex)
DataFrame Boolean 인덱싱
인코딩 에러
encoding 방식의 종류 : euc-kr, utf-8, cp949
축의 방향(axis)
axis = 0 -> 위,아래 (행방향)
axis = 1 -> 양 옆 (열방향)
# 2반을 기준으로 정렬 (내림차순 버전)
display(score.sort_values(by = "2반" , ascending=False))
display(score.sort_values(by='2반')[::-1])DataFrame에서는 행에 대한 객체를 지원하지 않음 (기본적으로 열(Series)에 대한 객체를 지원)
del scroe.loc['~~']drop() 함수 : 행을 삭제, inplace = True와 함께 사용하여야 실행이 됨.
첫번째 값은 누적의 우려가 있음
score['합계'] = score.sum(axis = 1) # score.loc[:,:]과 동일함
score['합계'] = score.loc[:,:'4반'].sum(axis = 1).astype() : 데이터 타입 변경하는 함수
apply,applymap
apply() -> 열이나 행에 대해 배열 형태로 적용되는 함수
applymap() -> 각 원소에 대해 적용되는 함수 (전체에 다 적용할때)
merge() -> 병합 함수
두 개의 pandas 객체를 합칠 때 특정 "컬럼"의 값을 기준으로 합치는 함수
pd.merge(left, right, how='inner', on="컬럼명")
left, right : 각각의 판다스 객체(DataFrame)
how : 어떻게 병합할건지 방식 지정
left면 앞에 적힌 함수 전체 다와 겹치는 값 출력 (DB와 헷갈리지 않게 주의)
concat() -> '이어붙이다'
concat() → "축의 방향(axis)"을 기준으로 병합
merge()의 단점은 pandas 객체가 2ea까지만 가능 → concat은 이를 보완
pd.concat([df1, df2...], axis=0, join='outer', ignore_index=False)
axis : 병합할 축의 방향 (기본값은 0)
join : 어떻게 병합할건지 방식지정
outer(기본값) : 합집합 형태로 반환
inner : 교집합 형태로 반환
ignore_index= True => 이어붙였을때 인덱스 다시 붙여주는 것(ex 12123=> 12345)
병합하기 실습
titanic = pd.concat([s1,s2,s3], axis=1)
# column명 부여하기
titianic.columns = ['PassengerID', 'Gender', 'Survived']group() 함수
groupby(by="컬럼명"),집계함수()
카테고리 생성하기
'카테고리컬 데이터'라고도 부름
# 나이 데이터로 카테고리 생성해보자!
# 1. 데이터 생성
ages = [0,2,10,15,21,23,37,61,20,41,100,52,78]
# 2. 범주 생성
# 0~19, 20~47, 48~60, 61~
# ※ '범주'는 시작값을 포함하지 않음!
bins = [-1,19,47,60,100]
# 3. 범주 명칭 생성
name = ['미성년자', '청년', '중년', '노년']
# pd.cut([데이터], [범주], labels = [범주 명칭])
categori = pd.cut(ages,bins,labels=name)
# 생성된 카테고리의 정보를 알려줌
# length : 데이터 길이
# 범주의 개수 및 범주 정보
# ages 데이터를 DataFrame 화
age_df = pd.DataFrame(ages, columns=['나이'])
age_df['카테고리'] = categori최종 실습
# data 불러오기
data2019 = pd.read_csv("./data/2019.csv", encoding = 'euc-kr' , index_col = '관서명')
data2020 = pd.read_csv("./data/2020.csv", encoding = 'euc-kr', index_col = '관서명')
data2021 = pd.read_csv("./data/2021.csv", encoding = 'euc-kr', index_col = '관서명')
# 데이터의 행,열 개수 파악
print(data2019.shape)
print(data2020.shape)
print(data2021.shape)
# 행 개수가 다른 DataFrame의 데이터 삭제
data2021.drop('광주지방경찰청', inplace= True)matplotlib
: 2D 그래프로 시각화가 가능한 라이브러리
파이썬에서 데이터를 차트로 그려줌
차트의 종류는 산점도, 막대, 파이, 히스토그램, 꺽은선 그래프 등 다양함
import matplotlib.pyplot as plt
plot : 꺽은선
bar : 막대
barh : 수평막대
scatter : 산점도
x = np.arange(8)
y = [5,2,3,6,8,7,5,7]
plt.plot(x,y, ls = '-.', c = '#FF6347', lw = 5, marker = '$♤$', mec = 'y', mfc = 'r', ms=10 )
# 그래프 숫자 표시 범위 지정(xlim, ylim)
# 범위를 지정하여 그래프 확대, 축소 출력 가능
plt.xlim(-2, 10)
plt.ylim(-5, 12)
# 그리드 그리기 (모눈종이, 격자눈금)
plt.grid()
# 눈금 출력하기
plt.yticks(y)
plt.xticks(x)
plt.show()# 속성값
# 1. 라인의 스타일 설정 : ls(Line Style) -> 문자열 ('-', '--', '-.', ':')
# 2. 라인의 두께 지정 : lw(Line Width) -> 그냥 숫자로 적어주기!! 문자X
# 3. 선의 색 바꾸기 : c(color) -> 선색과 마커의 색까지 모두 변경
# 4. 값의 위치 표시 : marker -> 문자열 (특수문자하려면 특수문자 앞뒤로 $ 넣기)
# 5. 마커 내부 색깔 : mfc(marker face color) -> 문자열
# 6. 마커 선 색깔 : mec(marker edge color) -> 문자열
# 7. 마커 크기 : ms -> 숫자
# 8. 마커 선 굵기 : mew(marker egde width) -> 숫자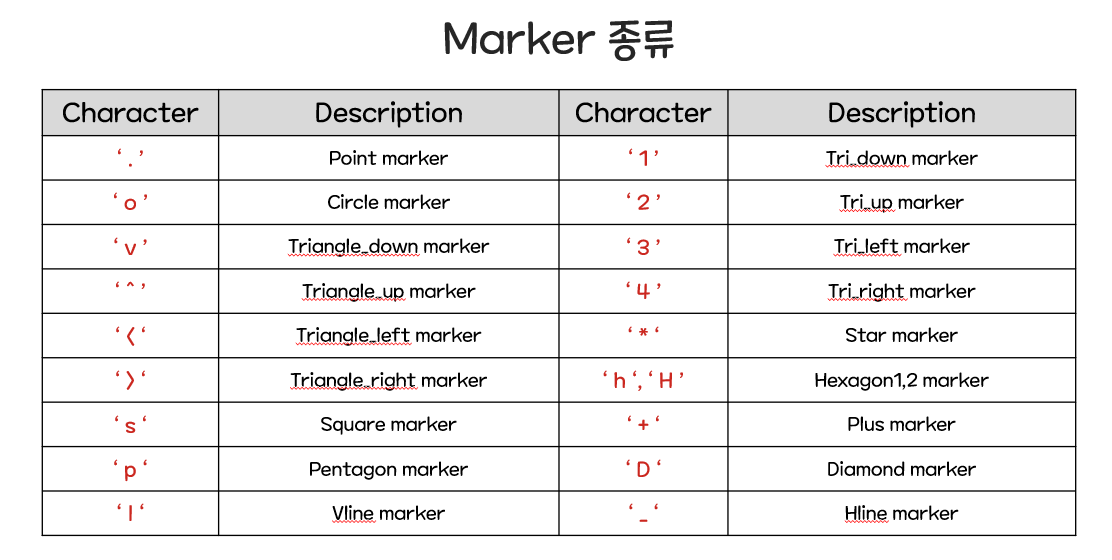
<색상 코드표>
https://www.rapidtables.org/ko/web/css/css-color.html
여러개 차트 하나의 공간에 그리기
from matplotlib import rc
rc('font', family = 'malgun Gothic')
# font : 폰트를 설정하겠다
# family : 글꼴집합이라는 의미로 글꼴명을 적어주면됨
2개
plt.plot(x, y1)
plt.plot(x, y2)
3개 이상
# 여러 개의 차트 하나의 공간에 그리기
x = [1,2,3,4]
y = [2,4,6,8]
z = [3,6,9,12]
plt.plot(x, label = 'x데이터' )
plt.plot(y, label = 'y데이터' )
plt.plot(z, label = 'z데이터' )
# 범례 설정하기
# 범례 : 참고사항, 데이터를 식별하기 위한 text
plt.legend() Scatter (산점도)
import pandas as pd
df = pd.DataFrame(np.random.rand(50,4), columns = ['A','B','C','D'])
# 최상단 데이터 확인
df.head(10)
# 최하단 데이터 확인
df.tail(10)
plt.scatter(x= df['A'], y= df['B'], label = 'Group1', c='g')
plt.scatter(x= df['C'], y= df['D'], label = 'Group2', c='salmon')
plt.legend()
plt.show()plt 함수 모음
#plt.text (x좌표 (- 이동할 정도), y좌표, 적고자 하는 값)
for i in range(0,6):
plt.text(x[i] - 0.1, y[i]-5, f'{y[i]}')
#plt.ylim(시작값,끝값)
#plt.title(이름, loc = 'left' or 'right')
#data['컬럼명'].value_counts() : # value_count : 특정 컬럼의 값들의 개수를 각각 출력
#plt.figure(figsize = (,)) => 차트 사이즈 조절import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv('Traffic_Accident_2017.csv', encoding = 'euc-kr')
변수.sort_index() => 가나다순으로 정렬하기
변수 = 변수[['','',''...]] => 임의로 재정렬하기
pd.set_option('display.max_columns', None) => 열값의 생략값 보이게 하기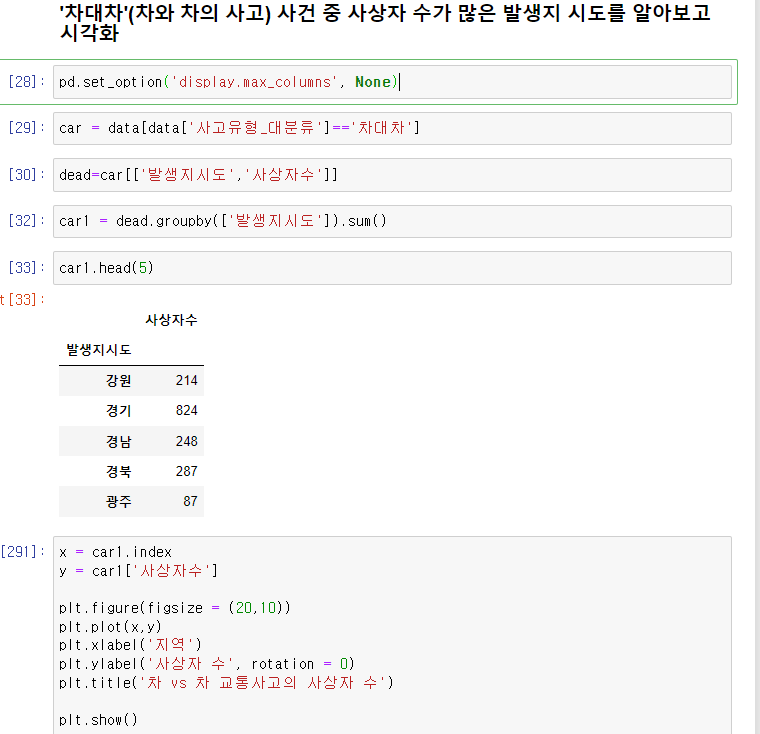
위 데이터를 내림차순 정렬하기
car1.sort_values('사상자수', ascending=False)