
1. 임베디드 소프트웨어의 종류
- 운영체제가 있는 시스템
운영체제가 있는 소프트웨어에서는 운영체제 외에 여러 기능을 제공하는 소프트웨어로 미들웨어 (middleware)가 존재한다. 애플리케이션에 탑재하고 싶은 기능이 운영체제나 미들웨어에 미리 준비되어 있는 때에는 목적에 맞는 필요한 절차를 작성하는 것만으로 실현할 수 있다.
이러한 시스템에는 대표적으로 범용 운영체제인 리눅스 기반으로 동작하는 라즈베리 파이 시리즈 가 있다.
- 운영체제가 없는 시스템
운영체제가 없는 때에는 미들웨어도 없으므로 목적을 실현할 절차를 모두 만들어야 한다. 요구사항을 실현하려면 어떠한 기능이 필요한지 분석해야 한다. 따라서 임베디드 시스템은 하드웨어를 어떻게 사용하면 기능 요구사항을 만족할 수 있는지 검토하는 작업이 필요하다.
단, 운영체제가 없다고 해도 전부 처음부터 만들지는 않는다. 필요 최소한의 기능은 라이브러리(library)라는 형태로 개발환경에서 제공된다. 라이브러리를 사용함으로써 화면에 문자를 표시하거나 시리얼 포트 경유로 통신하는 동작을 실현할 수 있다.
2. 임베디드 소프트웨어를 개발하는 흐름
* 크로스 컴파일
에디터를 사용하여 PC에서 고급 언어를 프로그래밍해 소스 코드를 작성하는 것까지는 PC용 프로그램 개발과 같지만, PC에 들어 있는 GCC 환경으로는 그대로 임베디드 시스템에서 실행할 수 없다. 왜냐하면 PC에 들어 있는 CPU와 임베디드 시스템의 CPU가 서로 다르기 때문이다.
이 때문에 임베디드 시스템에 맞춘 전용 환경을 구축해야 한다. 이 임베디드 시스템 전용의 개발환경을 크로스 개발환경(cross development environment)이라고 부른다.
* 빌드 작업
컴파일만으로는 임베디드 시스템의 CPU가 이해할 수 있는 형태까지는 완성되지 않는다. 따라서 이하의 빌드 과정이 필요하다:
- 고급 언어(e.g. C언어)의 소스코드 -> 컴파일러 (컴파일) -> 어셈블러 파일
- 어셈블러 파일 -> 어셈블러 -> OBJ 파일 생성
- OBJ 파일 -> 링크 파일(링커) -> 링크 파일
- 링크 파일 -> 바이너리 도구 -> HEX 파일
여기에서 링크 파일은 ELF 이며 이는 심볼의 조회 및 재배치가 가능한 운영체제에서 실행이 가능한 형식의 포맷이고, HEX 는 ELF 를 완전히 풀어서 특정 하드웨어에서 실행이 가능하게 만든 형식이다. (출처는 다음과 같다: https://www.quora.com/What-is-the-difference-between-elf-and-hex-file)
빌드(Build)와컴파일(Compile)의 차이
- 컴파일:
사람이 프로그램이 언어를 사용하여 작성한 소스 코드(소프트웨어의 설계도)를 컴퓨터에서 실행 가능한 형식의 오브젝트 코드로 변환하는 것을 가리킨다.- 빌드:
사람이 프로그래밍 언어를 사용해서 작성한 소스코드를 컴파일한 후, 해당 실행 환경에서 실제로 실행 가능한 형식으로 변환하는 것을 가리킨다.
필자는 이를 감각적으로 알고 있긴 했으나 정확한 정의는 오늘 처음 알게 되었다.
- 실제 빌드의 흐름 확인하기
#include <stdio.h>
char str[] = "hello, world!\n";
int data;
int func(int x, int y)
{
return x + y;
}
int main(int argc, char *argv[])
{
data = func(2021, 2022);
if (argc == 1) {
printf("%s\n", "argument not found!");
} else {
printf("%s:%x\n", str, data);
}
return 0;
}이하의 명령어를 입력하여 ELF 파일을 생성한다:
avr-gcc -Os -Wall -mmcu=atmega328p main.c -o main.elf책에서는 위 명령 인자를 전혀 설명하지 않는데 간단하게 풀어 쓰자면 이하와 같다:
-Os:Optimize forsize. 크기에 대한 최적화를 수행하라는 인자이다. 실행 속도보다 산출물의 크기에 초점을 맞춘다.-Wall:Warnings forall. 말 그대로 모든 경고 메세지를 출력한다.-mmcu:machinemcu,ISA (Instruction Set Architecture)혹은MCU의 타입을 지정하는 명령어이다. 책에서 실습하는Arduino Uno가atmega328p를 사용하기 때문에 이러한 옵션을 준 것 같다.
다시 이하의 명령어를 입력하여 생성된 ELF 파일을 HEX 파일 로 변환한다. 이것이 아두이노에서 실행 가능한 임베디드 소프트웨어의 파일이다:
avr-objcopy -I elf32-avr -O ihex main.elf main.hex* 프리프로세스 처리
프리프로세스 처리는 컴파일의 전단계 처리다. C언어의 매크로를 전개해 #include나 #ifdef 등의 디렉티브(directive)를 처리한다. 다음의 명령어는 프리프로세스 처리만을 실시한다:
avr-gcc -Os -Wall -mmcu=atmega328p -E main.c > preprocess.c* 컴파일 처리

컴파일 처리는 프리프로세스 처리에 의해 전개된 소스 코드를 어셈블러 코드(assembler code, 어셈블리어라고도 부른다)로 변환하는 작업이다. 어셈블리어는 CPU용의 기계어를 사람이 이해하기 쉬운 형태로 나타낸 것이다:
avr-gcc -Os -Wall -mmcu=atmega328p -S preprocess.c* 어셈블 처리
컴파일을 통해 어셈블리어로 변환한 결과를 OBJ 형식으로 변환한다. 라이브러리를 사용하고 있을 때 이 단계에 만들어진 OBJ 형식의 파일에는 라이브러리에서 제공하는 부품이 결여되어 있으므로 이것만으로는 동작할 수 없다.
이하의 명령은 어셈블 처리만을 실시한다:
avr-ass -mmcu=atmega328p -o main.o preprocess.s생성된 main.o 파일은 당연히 바이너리 파일이므로 텍스트 에디터로 읽어도 해석할 수 없다.
* 링크 처리
링크 처리는 의존하고 있는 라이브러리 등을 합체하여 실제로 실행할 수 있는 파일로 변환하는 작업이다. 다음의 명령은 링크 처리만을 실시한다:
avr-ld -o main.elf main.o \
./arduino-1.8.19/hardware/tools/avr/avr/lib/avr5/crtatmega328p.o \
./arduino-1.8.19/hardware/tools/avr/avr/lib/avr5/libc.a \
./arduino-1.8.19/hardware/tools/avr/avr/lib/avr5/libatmega328p.a \
./arduino-1.8.19/hardware/tools/avr/lib/gcc/avr/7.3.0/avr5/libgcc.a
PC 용의 프로그램이라면 위 단계에서 동작시킬 수 있지만 임베디드 시스템에서는 ROM 에 실행 형식의 파일을 기록해 넣어 두어야 한다.
* HEX 파일 변환
실제로 ROM에 기록하기 위해서는 HEX 파일로의 변환을 실시한다. 다음의 명령은 main.elf 라는 파일을 읽어 들여 main.hex 를 출력한다:
avr-objcopy -I elf32-avr -O ihex main.elf main.hex여기에서 생성된 HEX 파일을 임베디드 시스템의 ROM 에 기록해 실행한다.
위에서 필자가 삽화로 올린 예제 프로그램은 필자의 git 에 정리하여 올려 두었으므로 그냥 clone 해서 ./require 실행 후 make 를 입력하면 빠르게 빌드해서 결과를 확인할 수 있다.
3. 어셈블리 언어로부터 알 수 있는 것
make asm 을 입력하면 -O0 옵션(최적화 금지)을 이용하여 컴파일을 수행한다. 끝난 뒤에는 avr-objdump 를 통해 disassembly 를 수행한다:
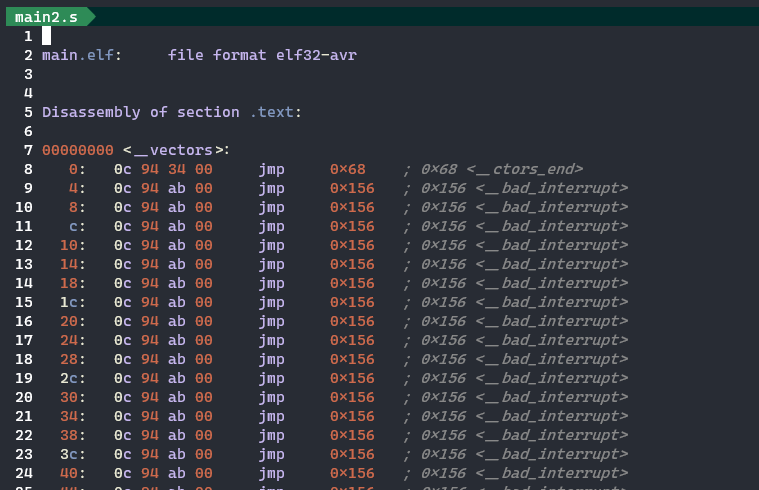
- 스타트업 루틴
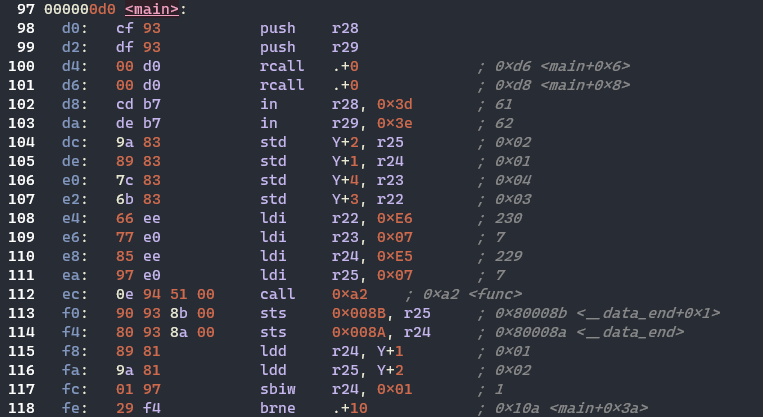
파일을 따라가다 보면 000000d0 <main>: 이라는 부분(책과는 코드가 달라서 주소도 조금 다름)이 나타난다. 이것은 main 함수가 어셈블리어로 변환된 부분으로, 000000d0 는 16진수로 표현된 메모리의 주소다. 그러나 그 앞에도 수십 행의 처리가 쓰여 있다. 이것들은 스타트업 루틴(start-up routine) 이라고 부르는 것이다.
임베디드 시스템은 main 함수를 호출하기 전에 하드웨어의 초기 설정과, 소프트웨어가 동작하기 위해 필요한 초기 설정을 해야 한다. 이러한 초기 설정을 하지 않으면 프로그램이 동작하지 않는다.
프로그램이 동작하려면 CPU가 이용하는 메모리의 ROM 영역, RAM 영역의 설정이나, 함수를 호출했을 때에 이용되는 스택(stack)이라는 영역의 초기화 설정, 전역 변수의 초기화 등 프로그램이 이용하는 메모리의 초기 설정을 실시해야 하기 때문이다.
- main() 함수가 호출될 때까지의 흐름 추적
임베디드 시스템의 전원이 켜지면 리셋 신호가 CPU 에 보내진다. 리셋 신호를 CPU 가 받게 됨으로써 CPU 의 동작이 시작한다. 그리고 메모리 주소의 0번지부터 프로그램이 실행되기 시작한다.
먼저 인터럽트 벡터의 설정이 이뤄지고, 계속해서 스택 영역, 데이터 영역 등이 초기화되기 시작한다. 그 후에 main 함수가 호출된다:
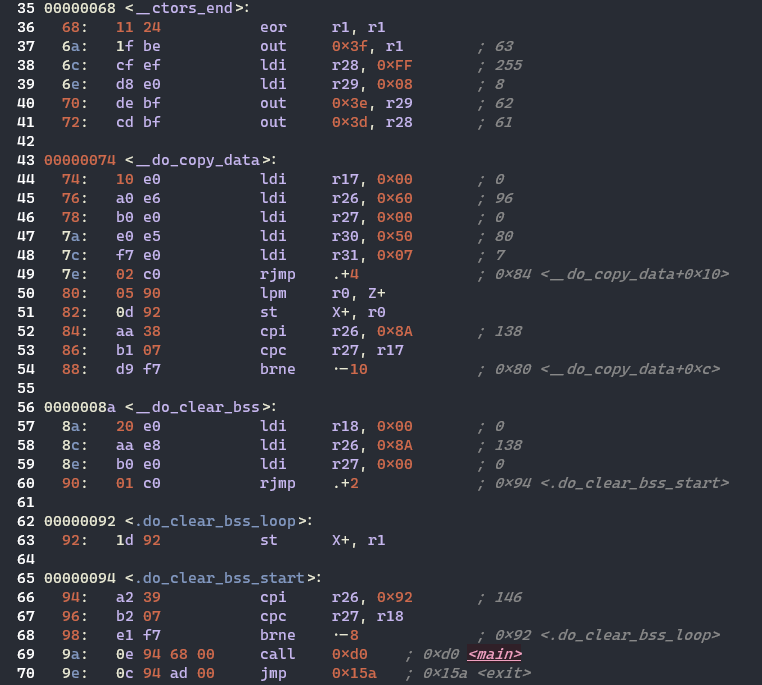
* 인터럽트 벡터 설정

현재는 Reset Vector (0x00) 의 주소만 설정되어 있다. jmp 0x68 은 __ctors_end 로 점프한다.
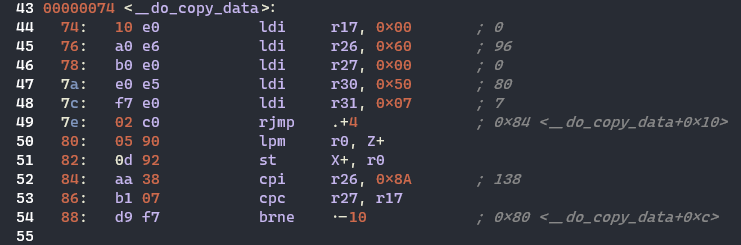
* 스택 포인터(stack pointer) 초기 설정

* 데이터 영역의 초기 설정
* 프로그램 본체(main)로의 제어 전달
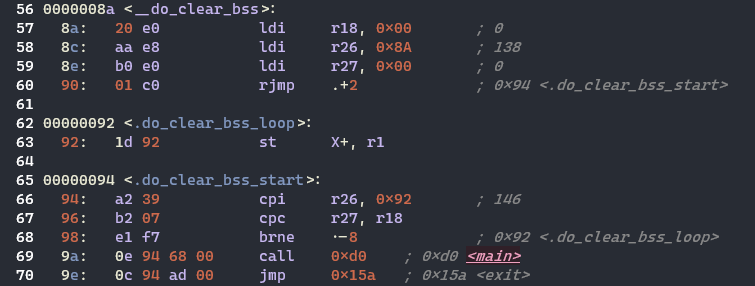
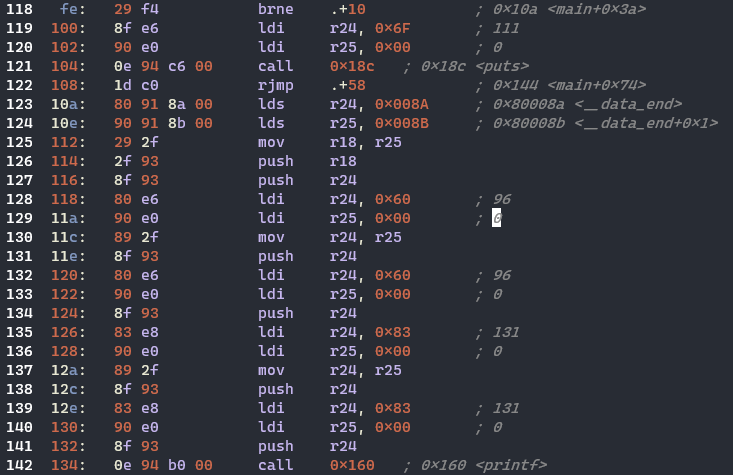
* main 함수의 실행

112행에서 <func> 함수를 호출, 121행에서 <puts>, 142행에서 <printf> 함수 호출
- 메모리 맵
메모리 각 영역의 역할을 나타낸 것을 메모리 맵이라고 부른다. 메모리 맵은 CPU에 의존하므로 소프트웨어 쪽에서 변경할 수 없다. 그러므로 소프트웨어가 CPU의 메모리 맵에 맞추어야 한다.
메모리 맵은 크게 코드 영역과 데이터 영역의 두 영역으로 나뉜다. 코드 영역은 읽기 전용의 영역으로 ROM 공간을 가리킨다. 데이터 영역은 읽고 쓰기가 가능한 영역으로서 RAM 공간을 가리킨다. 즉, 소프트웨어 측면에서 봤을 때 ROM/RAM 등의 하드웨어의 사용 영역에 대한 배치를 나타낸다.
영역은 섹션 (Section)이라고 불린다. 대표적인 섹션은 이하와 같다:
| 섹션명 | 영역명 | 프로그램과의 관계 |
|---|---|---|
| text | 코드 | 기계어(프로그램의 명령)를 보관한다. |
| data | 초기화 완료 데이터 | 초기값을 갖는 변수를 보관한다. |
| bss | 초기화 미완료 데이터 | 초기값을 갖지 않는 변수를 보관한다. |
ELF 파일을 avr-objdump 라는 명령을 사용해 살펴보면 다음과 같은 헤더 정보를 볼 수 있다:
avr-objdump -x -h main.elf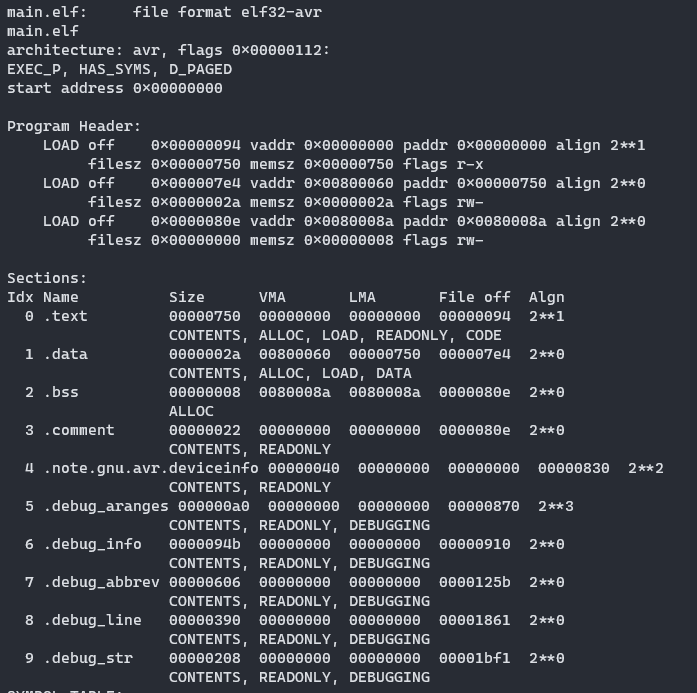
Sections 부분의 각 섹션의 위치(주소)가 적혀 있다. 이를 통해 main.c 에서 이용하는 변수인 str 과 data 가 어떤 섹션에 배치되었는지도 살펴볼 수 있다:
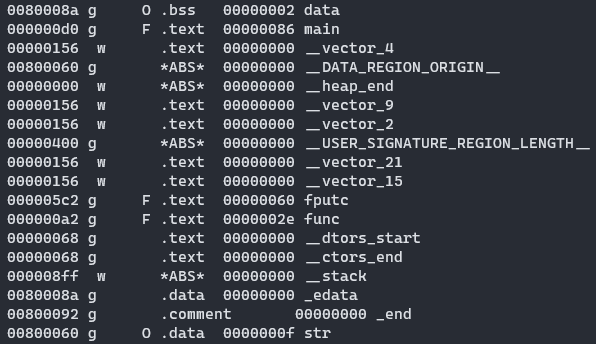
data 는 .bss 영역, str 은 .data 영역에 배치되어 있음을 알 수 있다.
- 스택
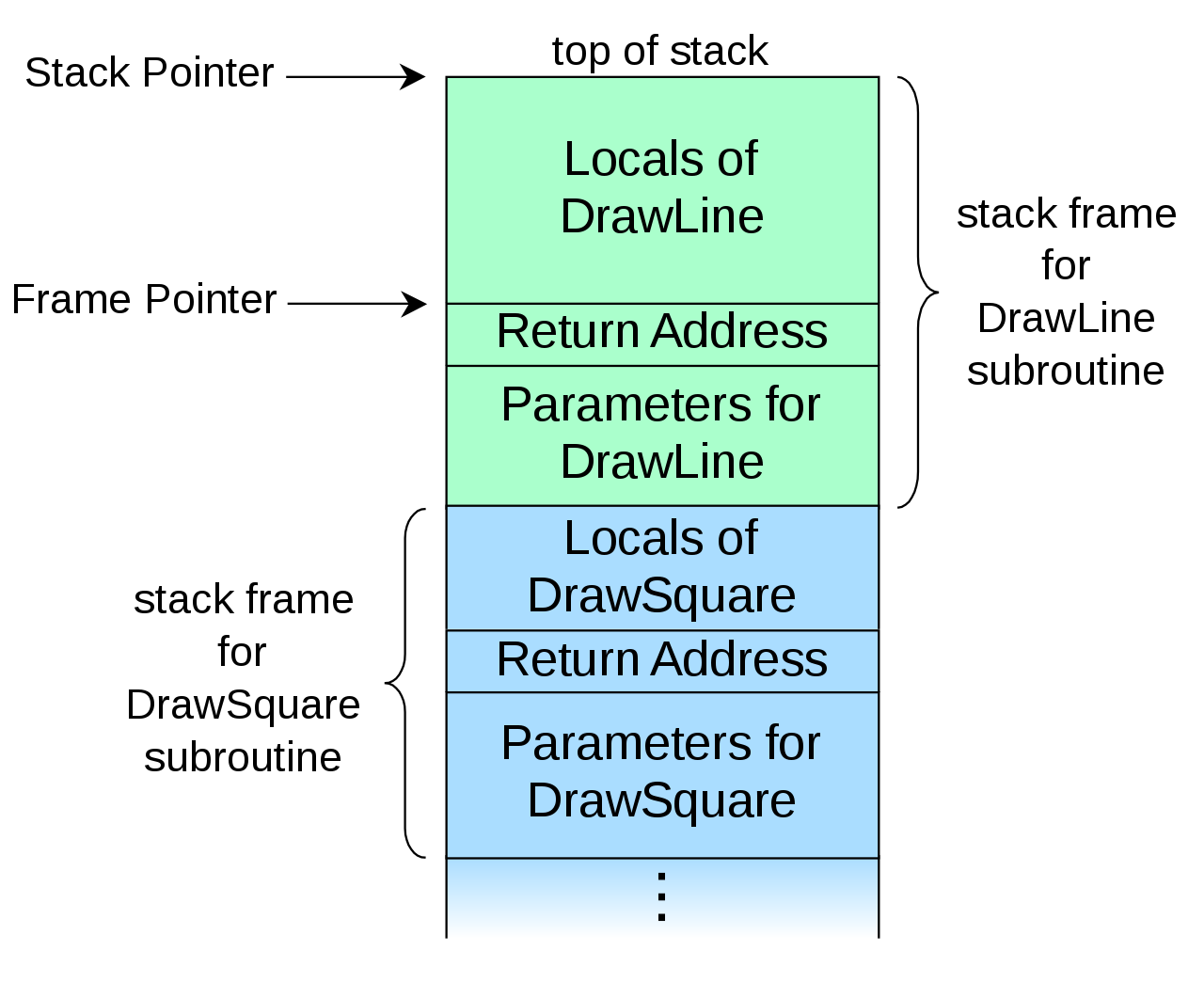
(Wikipedia, Call stack, 삽화 이미지) 일반적으로 삽화의 반대 방향으로 스택이 자라난다. (주소가 작아지는 방향으로)
스택은 함수를 호출할 때에 이용되는 메모리 영역이다. 소재로 사용하는 main.c 에서는 func 함수, printf 함수를 호출하고 있다. 자신의 함수에서 다른 함수를 호출할 때 패러미터를 건네는 번지나 되돌아올 번지를 기억해야 한다. 이때 이용하는 것이 스택 영역이다.
func 함수를 호출하기 전에, main 함수에서는 스택 포인터를 조작해 되돌아갈 번지, 패러미터 X 와 패러미터 Y 를 스택에 넣는다. 호출된 func 함수에서는 인수 X, Y 를 꺼내 연산을 실시하고 반환값을 보관한다. 처리가 종료되면 되돌아갈 번지를 꺼내어 main 함수로 되돌아간다.
- 스택과 인터럽트
인터럽트가 발생한 때에도 스택이 이용된다. 인터럽트가 발생하면 인터럽트 벡터에 등록되어 있는 처리가 실행된다. 그 처리를 실행하기 전에 인터럽트가 발생하기 전에 처리하고 있던 번지로 되돌아갈 번지로 스택을 등록한다.
인터럽트는 함수 호출과는 드라게 언제 발생할지 모른다. 인터럽트가 발생한 때에는 인터럽트 발생 전의 반환 번지 외에 CPU 가 갖고 있던 내부 상태도 스택에 넣어 두어야 한다.
* 스택과 CPU 의 상태
인터럽트 발생 시의 스택 조작은 CPU의 명령으로 실시하기 때문에 특별히 의식할 필요는 없지만, 디버그 때의 스킬로서 인터럽트 발생 시의 스택 용도, CPU의 동작 원리를 파악 해 둘 것을 추천한다. 인터럽트가 발생한 경우에 CPU 상태를 스택에 넣어 두는 것은 왜일까? 그것은 상태 레지스터 등 시스템 레지스터의 상태와 관련되어 있다.
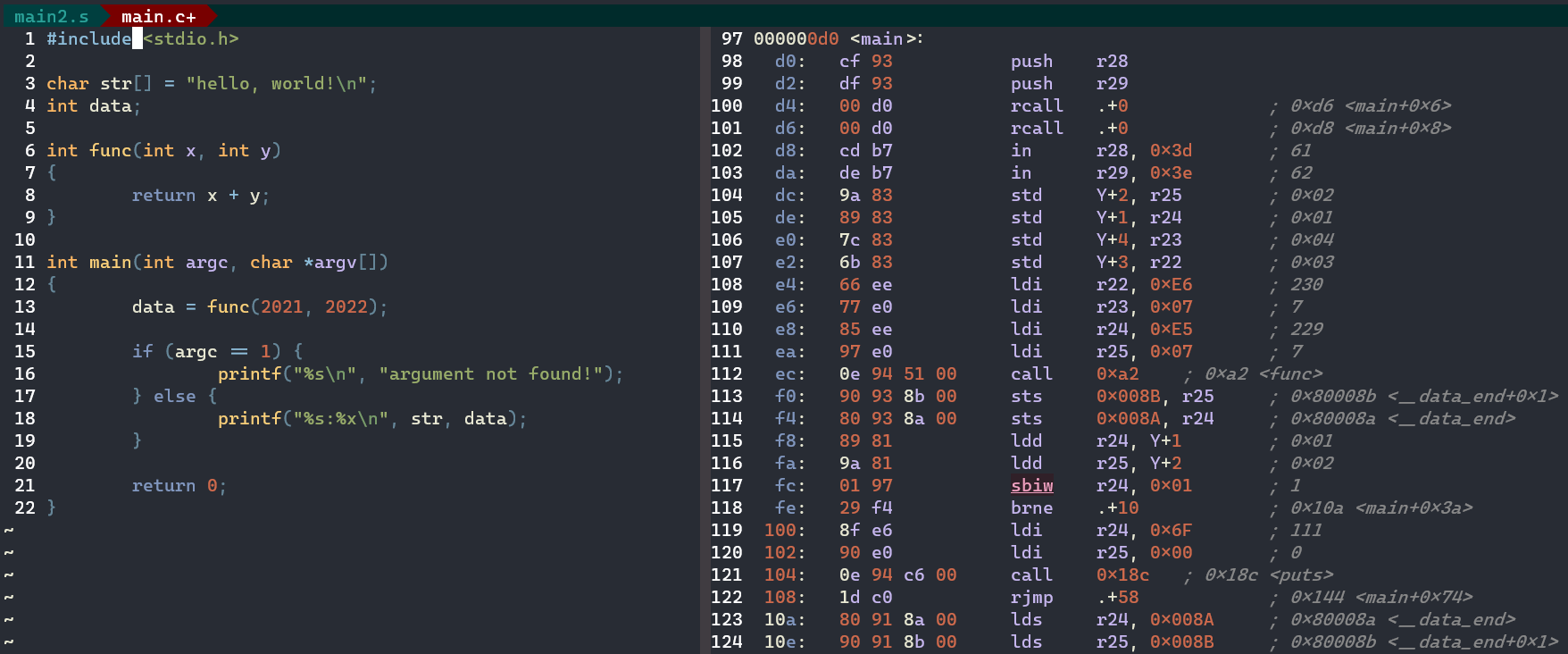
어셈블리 코드 117 행의 sbiw 가 argc 에서 1을 차감하는 코드이고 위 연산 결과가 상태 레지스터에 저장되는데 뺄셈 명령의 결과가 0인 경우는 Zero Flag 가 1, 결과가 0이 아닌 경우는 Zero Flag 가 0 이 된다. 그 다음은 분기 명령인 brne 가 실행되는데 brne 는 상태 레지스터의 Zero Flag를 보고, 어느 쪽으로 분기할지를 결정한다.
인터럽트가 발생한 위치에 따라 다르겠지만, sbiw 연산 직후에 인터럽트가 발생하기 되면 인터럽트 핸들러 처리 수행 과정에서 상태 레지스터의 결과가 덮어씌워질 가능성이 있다. 따라서 이러한 상태 정보를 미리 백업해두고 인터럽트 종료 후에 다시 복구해야 한다.
우리는 이를 Context Switching 이라고 부른다.
4. 임베디드 소프트웨어의 테스트 환경
- ICE(In-Circuit Emulator)
ICE 는 임베디드 시스템에 탑재되어 있는 CPU를 대신해서 동작하는 기기를 말한다. ICE 에는 몇 가지 종류가 있다:
| ICE의 종류 | 개요 | 장점 | 단점 | 가격 |
|---|---|---|---|---|
| JTAG ICE | JTAG 인터페이스로 임베디드 시스템의 CPU가 갖고 있는 디버깅 기능을 이용한다. | 임베디드 시스템의 CPU 가 갖고 있는 기능만 사용할 수 있다. | 임베디드 시스템의 CPU에 기능이 없으면 이용할 수 없다. | 저가 |
| 풀(full) ICE | 임베디드 시스템의 CPU 를 에뮬레이션한다. | 임베디드 시스템의 CPU를 대신해서 무엇이든 가능하다. | 가격이 고가. 최근에는 그다지 이용하지 안흔다. | 고가 |
JTAG ICE 를 이용하려면 임베디드 시스템의 CPU에 디버깅 기능이 필요하다. 최근의 경향이라면 임베디드 시스템의 CPU가 고성능화되어서 OCD(On-Chip-Debugger)가 점차 표준 탑재되고 있다. 이 때문에 JTAG 인터페이스를 이용한 테스트가 주류를 이루고 있다.
ICE를 이용함으로써 임베디드 시스템의 CPU로부터 메모리를 참고하거나 주변장치의 액세서를 확인할 수 있다. 먼저 하드웨어의 액세스가 정상적인 것을 확인한 후에 소프트웨어의 동작을 확인한다.
* 시리얼의 이용
JTAG 인터페이스 이외에 시리얼(serial, 직렬) 포트를 사용한 테스트도 있다. ICE와는 달리 테스트나 디버깅에 이용하는 기능은 제공되지 않기 때문에 시리얼 포트에 출력하는 기능을 구현하여 모니터링을 실시한다.
* 파형의 관측
하드웨어 계측 기기로서 로직 분석기, 오실로스코프 라는 계측기를 사용하는 일이 많을 것이다. 둘 다 하드웨어의 파형 측정에 사용되는 기기로서 하드웨어 기술자는 이 두 가지를 이용하여 테스트 및 디버그를 실시하는 것이 보통이다.
로직 분석기는 시간 을 계측하는 경우나 하드웨어 사양서의 시퀀스 다이어그램대로 동작하고 있는지를 기능적으로 확인할 경우에 편리하다.
오실로스코프튼 전기적인 특성을 측정할 수 있는 기기다. 하드웨어의 파형으로 H/L 레벨 을 측정할 때에 사용된다.
임베디드 소프트웨어에서는 로직 분석기와 오실로스코프를 하드웨어와 소프트웨어의 동작 분리 시에 사용한다. 예를 들어, 인터럽트 신호 등의 하드웨어로부터 통지되는 이벤트가 소프트웨어에서는 통지되지 않는 상황을 생각해 볼 수 있다. 만약 계측 기기를 사용하여 신호를 관측할 수 있다면 문제는 소프트웨어에 있다고 판단해 문제점을 분리해 낼 수 있다.
5. 임베디드 시스템 프로그래밍에서의 C언어
- 최적화 옵션의 장점과 단점
대부분의 임베디드 시스템은 제약 사항으로 메모리(ROM/RAM) 용량에 제한이 있거나 처리 시간에 제약이 있기 때문에 프로그램을 최적화해야 한다. 이때에 컴파일러의 최적화 옵션을 사용하여 프로그램 구조를 최적화함으로써 제약 사항을 지키도록 하낟. 단, 컴파일 시의 최적화에 따라 프로그램이 의도하지 않는 동작을 하는 경우도 있다.
- volatile 선언
임베디드 시스템에서는 주기적으로 하드웨어를 감시해 상태가 변한 것을 감시하는 처리인 폴링(polling) 이 빈번히 발생한다. 인터럽트 기능을 갖고 있지 않는 주변장치 등을 감시하기 위해 사용된다.
for (;;) {
if ((*(uint64_t *) (0x0000000F)) & 0x04) {
/* 적절한 처리 */
break;
}
}
/* 위 코드는 최적화 과정에서 이하의 코드로 변경될 수 있다. */
if ((*(uint64_t *) (0x0000000F)) & 0x04) {
for (;;) {
/* 적절한 처리 */
break;
}
} 이때 주변장치의 감시를 위해 레지스터 주소를 지정한 처리를 작성했다고 하자. 그러나 컴파이럴는 주변장치의 레지스터 주소를 알지 못하기 때문에 최적화 옵션을 지정하여 컴파일하면 의도하지 않은 상황으로 전개될 가능성이 있다. 이 때에는 volatile 선언 으로 최적화를 하지 않도록 지정한다:
if ((*(volatile uint64_t *) (0x0000000F)) & 0x04) {
for (;;) {
/* 적절한 처리 */
break;
}
}- unsigned 와 signed
임베디드 시스템의 경우 주변장치의 레지스터 등은 비트로 상태를 나타내기 때문에 읽어낸 값에 따라 의도하지 않은 값이 될 가능성이 있다. 따라서 하드웨어를 제어할 때는 비트 조작이나 레지스터의 값이 마이너스로 판단되지 않도록 unsigned 타입을 이용하는 것이 좋다:
typedef struct {
signed int control_bit: 1; // 0 이나 -1 중 하나가 된다. 1 은 되지 않는다.
}
typedef struct {
unsigned int control_bit:1; // 0 이나 1 중 하나가 된다.
}- pragma
하드웨어나 메모리 주소를 지정하여 데이터나 코드를 배치하고 싶은 경우는 pragma 를 이용한다. pragma 를 사용하면 메모리 맵에 독자적인 섹션을 늘려서 데이터나 코드를 배치할 수 있다. 예를 들어, 데이터나 코드를 RAM 에 배치해서 실행하거나, 또는 데이터는 플래시 메모리에 두는 식으로 실제 어느 하드웨어를 사용할 것인지 지정할 수 있다.
단, pragma 는 컴파일러에게 지시를 하기 위한 옵션이므로 사용 가능 여부는 컴파일러에 의존한다.
- 포인터와 배열
임베디드 시스템의 CPU는 PC만큼 빠르지 않다. ROM이나 RAM 등의 메모리도 용량이 한정되어 있다. 이렇나 제약 사항과의 가성비를 고려해, 처리 속도나 메모리 용량의 삭감 등을 주의해야 한다. 따라서 코드를 작성할 때에는 하드웨어의 성능을 고려한 코딩을 하는 것이 중요하다.
#include <stdio.h>
int main(void)
{
int i, j;
char buf[10];
for (i = 0, j = 0; i < 10; i++, j++) {
buf[i] = j + 1;
printf("%x\n", buf[i]);
}
return 0;
}위 코드의 어셈블리 코드가 아래 코드의 어셈블리 코드보다 길고 처리 과정도 많다:
#include <stdio.h>
int main(void)
{
int i, j;
char buf[10];
char *ptr;
ptr = buf
for (i = 0, j = 0; i < 10; i++, j++) {
*ptr = j + 1;
printf("%x\n", *ptr);
ptr++;
}
}원본 포인터 주소(buf)를 가지고 있으므로 실제론 i 도 필요하지 않기 때문에 코드를 더 줄일 수 있다.
- 인터럽트 핸들러
인터럽트 핸들러(interrupt handler)는 인터럽트 처리에 등록하기 위해 작성된 프로그램이다. 인터럽트 처리는 일반적인 처리보다도 CPU가 먼저 동작시킨다. 그러한 이유로 인터럽트 처리가 길면 일반 처리에 영향을 끼치므로 되도록 간단하고 최소한의 처리만을 작성하도록 주의한다.
AVR의 환경에서는 다음과 같이 기술함으로써 인터럽트 벡터로 등록할 수 있다. ISR() 이라는 매크로 함수를 이용해서 등록하고 싶은 인터럽트 벡터 위치를 지정한다.
#include <avr/io.h>
#include <avr/interrupt.h>
/* timer0 의 인터럽트 함수 등록 */
ISR(TIMER0_COMPA_vct)
{
/* 여기에 인터럽트 시의 처리를 작성 */
}
int main(void)
{
TCCR0A = 0b10000010; /* 10: 비교 매치 A로, 10:CTC 모드 */
TCCR0B = 0b00000001; /* 주파수 분할 없음 */
TIMSK0 = 0b00000010; /* 비교 매치 A 의 인터럽트를 설정 */
/* 비교 매치할 시간 설정 */
OCR0A = 32499; /* 32.5ms 로 비교 매치 @1MHz */
sei(); /* 인터럽트 허가 */
for (;;) {
/* main 처리를 기술한다. */
}
return 0;
} 참고로 위 코드에서 나온 리터럴 상수 0b10000010 는 C 표준이 아닌 GCC 확장 기능이다. 따라서 위와 같은 형태의 표기는 지양하고 0x 리터럴 접두사를 사용하는 것이 좋다.
출처
[Site] https://www.quora.com/What-is-the-difference-between-elf-and-hex-file
[Site] https://ww1.microchip.com/downloads/en/DeviceDoc/Atmel-7810-Automotive-Microcontrollers-ATmega328P_Datasheet.pdf
[Image] https://en.wikipedia.org/wiki/Call_stack
[Book] 임베디드 엔지니어 교과서, 와타나베 노보루, 마키노 신지 지음, 정인식 옮김, 제이펍 출판사
