드라이버 코드 분석하다 자꾸 DMA 에서 막혀서 이참에 확실하게 다 정리할 계획이다. 네트워크 디바이스 관점에서 정리할 것이다.
0. CPU 주소와 DMA 주소
DMA API 를 이해하기 위해선 여러 종류의 주소의 차이를 이해하는 것이 중요하다.
* 가상 주소
커널은 일반적으로 가상 주소를 사용한다. kmalloc(), vmalloc() 계열의 함수가 반환한 주소 값은 가상 주소 이다.
* 물리 주소
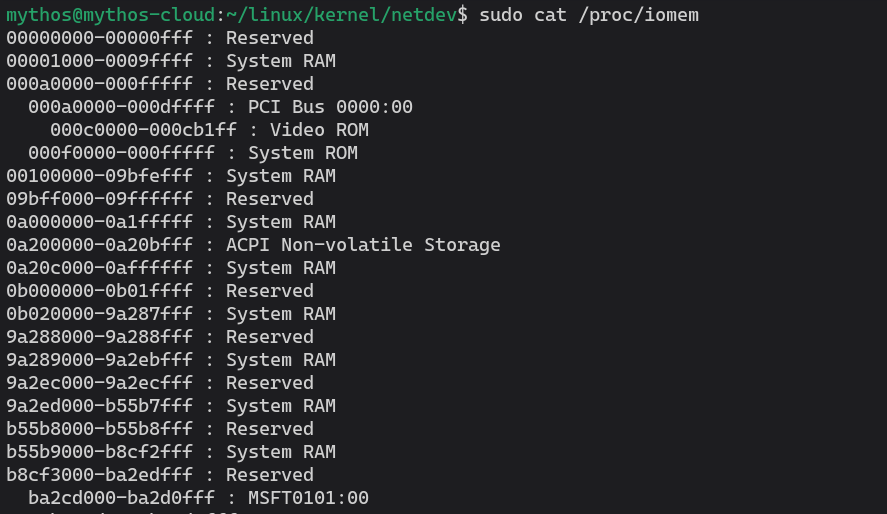
가상 메모리 시스템 (TLB, page tables, etc.) 은 가상 주소를 CPU 물리 주소로 변환하게 된다. 이러한 주소는 phys_addr_t 혹은 resource_size_t 와 같은 형태로 저장된다. 커널은 register 와 같은 장치의 자원을 물리적 주소로 관리한다. 이러한 주소는 /proc/iomem 혹은 /proc/ioports 에서 확인 가능하다.
물리적 주소는 드라이버에게 직접적으로 유용하진 않기 때문에, ioremap() 을 사용해 공간을 맵핑하고 가상 주소를 생성해야 한다.
* 버스 주소
I/O 장치는 세 번째 종류의 주소, 버스 주소를 사용한다. 만약 장치가 MMIO 주소에 있는 레지스터를 가지거나, 혹은 시스템 메모리를 읽기 위해 DMA 를 수행한다면, 장치에 의해 사용되는 주소는 버스 주소이다. 일부 시스템에선 버스 주소는 CPU 물리 주소와 같지만, 일반적으론 그렇지 않다. IOMMU 와 호스트 브릿지는 물리 주소와 버스 주소 사이의 임의의 매핑을 생성할 수 있다.
장치의 관점에선, DMA 는 버스 주소 공간을 사용하지만, 해당 공간의 일부로 제한될 수 있다. 예를 들어, 시스템이 메인 메모리와 PCI BAR 에 대해 64-bit 주소를 지원하더라도 IOMMU 를 사용할 수 있고 장치는 32-bit DMA 주소만 사용하면 된다.
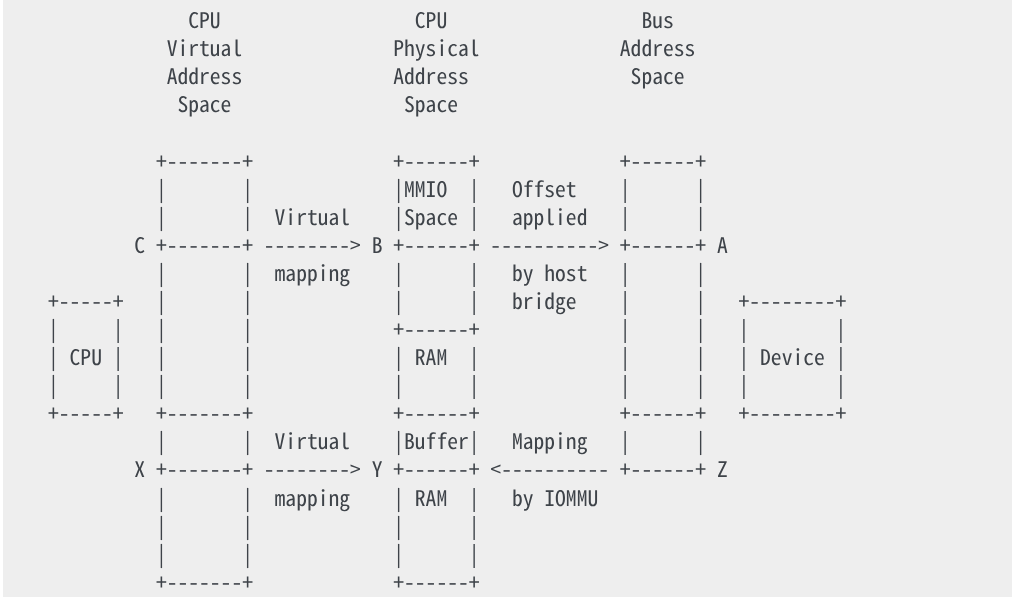
numeration process (장치 탐색) 과정에서, 커널은 I/O 장치와 그것들의 MMIO 공간, 그리고 이들을 시스템과 이어주는 호스트 브릿지에 대해 알게 된다. 예를 들어, PCI 장치가 BAR (Base Address Register)를 가지고 있다면, 커널은 BAR 를 통해 버스 주소(A)를 읽고 이를 CPU 물리 주소(B)로 변환하게 된다.
주소 B 는 struct resource 에 저장되는데 이는 /proc/iomem 에 노출된다. 드라이버가 장치를 요청할 때, 일반적으로 ioremap() 을 사용해 물리 주소 B 를 가상 주소 (C) 로 매핑한다. 이후, 버스 주소(A) 에 위치한 장치 레지스터에 접근하기 위해 ioread32(C) 와 같은 방식을 쓸 수 있다.
* DMA 주소
주의: 여기서부턴 장치(device), 드라이버(driver) 구분 잘 해서 읽기
만약 장치가 DMA 를 지원한다면, 드라이버는 kmalloc() 과 같은 인터페이스를 통해 버퍼를 만들 수 있고 이는 가상 주소(X)를 반환한다. 가상 메모리 시스템은 X 를 시스템 RAM 물리 주소(Y)로 매핑한다. 드라이버는 가상 주소 X 를 통해 버퍼에 접근할 수 있으나, DMA 는 CPU 가상 메모리 시스템을 거치지 않기 때문에 장치 자체는 접근할 수 없다.
일부 단순한 시스템은 장치가 직접 물리 주소 Y 로 DMA 할 수 있으나, 대부분의 경우, IOMMU 하드웨어가 DMA 주소를 물리 주소로 변환한다 (e.g. Z 를 Y 로 변환). DMA API 가 존재하는 이유는 다음과 같다: 드라이버는 dma_map_single() 과 같은 인터페이스를 통해 가상 주소 X 를 전달할 수 있고, 이는 IOMMU 매핑을 위한 설정과 함께 DMA 주소 (Z) 를 반환한다. 이후 드라이버는 장치에게 Z 를 통해 DMA 할 수 있음을 알리고, IOMMU 는 이를 시스템 RAM 에 있는 주소 Y 의 버퍼에 매핑한다.
리눅스가 동적 DMA 매핑을 하기 위해선 드라이버의 도움을 필요로 한다. 즉, DMA 주소는 실제로 사용되는 동안만 매핑되어야 하고, DMA 전송 이후에는 매핑이 해제되어야 한다.
1. DMA 가능한 메모리
kmalloc() 혹은 kmem_cache_alloc() 과 같은 함수로 획득한 메모리는 DMA 메모리로 사용할 수 있지만, vmalloc() 과 같은 함수로 할당받은 메모리는 DMA 로 매핑할 수 없다. 하지만 vmalloc() 으로 할당한 각각의 페이지 테이블로부터 물리 주소를 획득한 뒤에 DMA 로 매핑하는 것은 가능하다. (일반적으로는, 연속되지 않기 때문에 안되는 것 같다.)
이러한 규칙 때문에, 커널 이미지 주소, 모듈 이미지 주소, 스택 주소 등은 DMA 로 쓸 수 없다. 이러한 모든 주소는 물리적 메모리의 나머지 부분과는 완전히 다른 곳에 매핑될 수 있기 때문이다. 사용이 가능할지라도 I/O 버퍼가 CPU 캐시 라인에 정렬되어 있지 않다면 데이터 공유 문제가 발생하여 덮어 쓰일 수 있다.
2. DMA 주소 지정 수준
커널은 기본적으로 장치가 32-bit DMA 주소를 쓴다고 가정한다. 64-bit 장치의 경우 이 값을 늘려야 하고, 제한이 있는 경우라면 32-bit 보다 더 줄여야 한다.
정확한 동작을 위해선, 장치의 DMA 주소 지정 수준을 알리기 위해 DMA 마스크를 설정해야 한다. 이는 dma_set_mask_and_conherent() 로 가능하다. 이 함수는 streaming 과 coherent API 모두에 대해서 마스크를 설정한다. 만약 특별한 요구조건을 필요로 한다면 각각을 따로 설정하는 것도 가능하다.
dma_set_mask(struct device *dev, u64 mask)dma_set_coherent_mask(struct device *dev, u64 mask)
여기에서 dev 는 장치의 구조체를 가르키는 포인터이고, mask 는 장치가 지원하는 주소의 비트를 뜻한다. 예를 들어, &pdev->dev 는 PCI 장치의 포인터이다.
위 함수들은 제공한 주소 마스크로 장치가 DMA 를 제대로 수행할 수 있음을 나타내기 위해 보통 0 을 반환한다. 그러나 만일 주어진 시스템을 지원하기에 마스크가 너무 작은 경우 에러를 반환할 수도 있다.
지원하지 않는 플랫폼에서의 DMA 수행 결과는
undefined behavior이다.
실패한 경우, 두 가지 선택지가 있다:
1. non-DMA 모드로 데이터를 전송한다. (가능한 경우에)
2. 이 장치를 무시하고, 초기화하지 않는다.DMA 마스크에 실패했을 때 KERN_WARNING 을 출력하는 것이 권장된다.
3. DMA 매핑 종류
DMA 매핑에는 두 가지 종류가 있다:
- Coherent DMA
Coherent DMA 매핑은 주로 드라이버 초기화 과정에서 이뤄지고, 드라이버의 끝에서 언매핑된다. 하드웨어는 장치와 CPU 가 병렬로 데이터에 접근할 수 있으며 소프트웨어 플러싱 없이도 서로가 수행한 업데이트를 볼 수 있음을 보장해야 한다.
coherent를synchronous라 생각하라.
현재 디폴트는 하위 32 비트의 DMA 공간의 coherent 메모리를 반환하는 것이다. 하지만 이후의 호환성을 생각해서 디폴트가 현재 드라이버에서 괜찮더라도 coherent mask 를 설정해야 한다.
coherent 매핑을 사용하는 좋은 예시는 다음과 같다:
- 네트워크 카드의 DMA 링 디스크립터
- SCSI adapter mailbox command data structures.
- Device firmware microcode executed out of main memory.
위 예시가 요구하는 불변성(invariant)은 CPU 가 메모리에 저장한 모든 내용이 장치에서 즉시 인식되어야 한다는 것이고, 그 반대의 경우도 마찬가지이다. coherent mapping 은 이를 보장한다.
Coherent DMA메모리는 메모리 배리어를 사용할 필요가 없음을 뜻하지 않는다. CPU 는 일반적인 메모리와 같이 coherent 메모리 저장에 대해 reorder 할 수 있다. 따라서 첫 번째 워드가 두 번째 워드의 업데이트보다 선행되어야 한다면 다음과 같이 작성해야 한다:desc->word0 = address; wmb(); desc->word1 = DESC_VALID;그리고 일부 플랫폼에서는 드라이버가 CPU 쓰기 버퍼를 플러시해야 할 수도 있다. (e.g. PCI 브릿지에서 쓰기 버퍼를 플러시 할 때와 같이 레지스터의 값을 쓴 후에 읽는 방식으로)
- Streaming DMA
Streaming DMA 매핑은 일반적으로 하나의 DMA 전송에 대해 매핑을 하고, 그 직후에 바로 언매핑한다 (그 아래에서 dma_sync_* 를 쓰지 않는 한). 하드웨어는 순차적 접근에 대한 최적화를 할 수 있다.
streaming을asynchronous혹은outside the coherency domain이라 생각하라.
streaming 매핑을 사용하는 좋은 예시는 다음과 같다:
- 디바이스에 의해 송/수신되는 네트워킹 버퍼
- SCSI 장치에 의해 읽히고/쓰여지는 파일 시스템 버퍼
이러한 종류의 매핑을 사용하는 인터페이스는 구현에 있어서 하드웨어가 허용하는 한도 내에서 어떠한 종류의 최적화도 수행할 수 있도록 설계되었다.
두 가지 DMA 매핑 모두 버스로부터 오는 정렬 제한을 가지지 않으나, 일부 장치는 그러한 제한이 있을 수 있다. 또한, DMA-coherent 하지 않은 캐시를 사용하는 시스템은 버퍼가 다른 데이터와 캐시 라인을 공유하지 않을 때 더 잘 동작한다.
4. 예시로 알아보는 DMA 매핑
필자가 분석하는 D-Link NIC 가 어떻게 DMA 매핑을 사용하는지 알아볼 것이다.
1. Coherent DMA mapping for ring descriptor
// static int rio_probe1()
pci_set_drvdata (pdev, dev);
ring_space = dma_alloc_coherent(&pdev->dev, TX_TOTAL_SIZE, &ring_dma, GFP_KERNEL);
np->tx_ring = ring_space;
np->tx_ring_dma = ring_dma;
ring_space = dma_alloc_coherent(&pdev->dev, RX_TOTAL_SIZE, &ring_dma, GFP_KERNEL);
np->rx_ring = ring_space;
np->rx_ring_dma = ring_dma; 처음에 언급했던 것과 같이 일반적으로 coherent DMA 는 장치의 초기화 과정(rio_probe1()) 에서 이뤄지며, 예시에서 나왔던 것처럼 ring descriptor 를 초기화하기 위해 쓰였다.
// static void rio_remove1()
unregister_netdev(dev);
dma_free_coherent(&pdev->dev, RX_TOTAL_SIZE, np->rx_ring, np->rx_ring_dma);
dma_free_coherent(&pdev->dev, TX_TOTAL_SIZE, np->tx_ring, np->tx_ring_dma);
pci_iounmap(pdev, np->ioaddr); 장치가 제거되면 그때에 드라이버가 dma_free_coherent() 를 호출하여 ring descriptor 를 제거하게 된다.
2. Streaming DMA mapping for sk_buff
// static int alloc_list()
for (i = 0; i < RX_RING_SIZE; i++) {
struct sk_buff *skb = netdev_alloc_skb();
np->rx_skbuff[i] = skb;
np->rx_ring[i].next_desc = np->rx_ring_dma
+ ((i + 1) % RX_RING_SIZE) * sizeof(struct netdev_desc));
np->rx_ring[i].fraginfo = dma_map_single(&np->pdev->dev, skb->data, np->rx_buf_sz, DMA_FROM_DEVICE);
} sk_buff 할당 후 이를 dma_map_single() 함수로 매핑을 하는 과정을 볼 수 있다.
// static int receive_packet()
if (desc->status & RFDDone) { // 해당 패킷이 도착했다면
dma_unmap_single(&np->pdev->dev, desc_to_dma(desc), np->rx_buf_sz, DMA_FROM_DEVICE);
skb_put (skb = np->rx_skbuff[entry], pkt_len);
}
...
skb = netdev_alloc_skb();
np->rx_skbuff[entry] = skb;
np->rx_ring[entry].fraginfo = dma_map_single(&np->pdev->dev, skb->data, np->rx_buf_sz, DMA_FROM_DEVICE); 패킷이 들어와서 인터럽트가 발생하면 해당 sk_buff 를 바로 unmapping 하고 다시 새로운 sk_buff 로 할당 후 매핑하는 과정을 거친다.
dma_sync_single_for_cpu(&np->pdev->dev, desc_to_dma(desc), np->rx_buf_sz, DMA_FROM_DEVICE);
skb_copy_to_linear_data(skb, np->rx_skbuff[entry]->data, pkt_len);
skb_put(skb, pkt_len);
dma_sync_single_for_device(&np->pdev->dev, desc_to_dma(desc), np->rx_buf_sz, DMA_FROM_DEVICE); 만일 잠깐 읽기만 해야 한다면, dma_sync_single_for_cpu() 와 dma_sync_single_for_device() 를 사용한다.
물론 실제 로직은 이것보다 훨씬 복잡하나 핵심적인 내용은 위와 같다.

