
이번 장에서는 리눅스 커널의 또 하나의 자료구조, 레드-블랙 트리(red-black tree) 에 대해서 살펴 보도록 하겠다. 레드-블랙 트리는 그 자체로 두-세개 이상의 글을 할애해야 할 정도로 그 내용이 많기에, 알고리즘을 직접적으로 설명하진 않고 커널에서 어떻게 이를 다루는지에 초점을 맞춰 진행하겠다.
시간이 된다면 레드 블랙 트리에 대한 글은 따로 작성토록 하겠다.
1. 레드 블랙 트리 소개

레드 블랙 트리는 이진 탐색 트리에서 좀 더 발전된 자가 균형 이진 탐색 트리(Self‑balancing binary search tree)이다. 일반적인 이진 탐색 트리는 삽입 순서에 따라 최악의 경우 n 개의 원소에 대해 n 번의 탐색을 시도해야 할 수도 있다. 반대로 레드 블랙 트리는 각 원소를 적절하게 좌우로 삽입하여 불균형을 완화하고 개략적(roughly) 으로 균형을 잡는다.
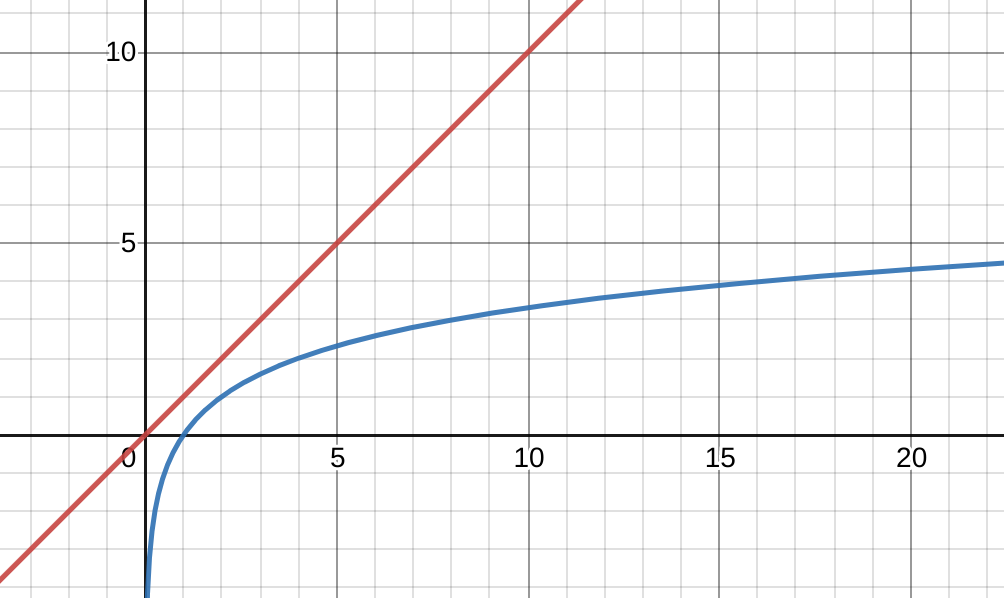
이진 탐색 트리는 탐색에 대한 인 반면 레드 블랙 트리는 탐색에 대한 효율이 이다. 그래서 리눅스 커널은 보통 데이터의 양이 적을 때에는 상대적으로 간단한 구조의 연결 리스트를 사용하고 데이터의 양이 많아지면 탐색 효율을 위해 레드 블랙 트리를 사용한다.
2. 시간 측정: get_cycles()
이번 장에서는 리눅스 커널의 레드 블랙 트리 성능을 분석할 예정이다. 따라서 성능 분석에 사용할 도구인 get_cycles() 함수에 대해 먼저 간단하게 설명하고 시작하겠다.
1. 함수 정의
get_cycles() 함수는 CPU 의 사이클 함수를 반환하는 함수로 아키텍처에 독립적인 함수이다. CPU 사이클을 반환하는 함수이므로 아키텍쳐의 종속적인 것이 아닐까? 생각할 수 있다. 맞다, 실제로 get_cycles() 함수는 아키텍처의 의존적인 rdtsc() 함수를 래핑하여 만든 함수이다. 필자는 x86 을 사용하고 rdtsc() 함수는 다음과 같이 정의되어 있다.
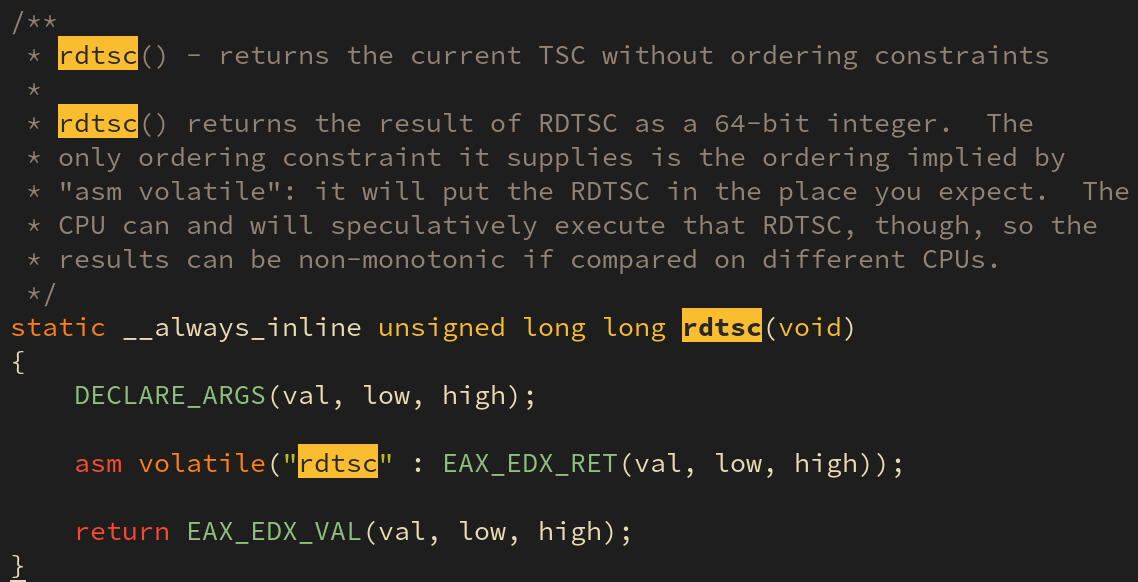
arch/x86/include/asm/msr.h 에서 그 내용을 확인할 수 있다.
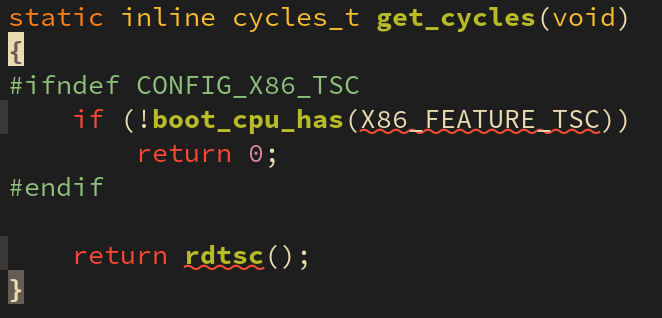
get_cycles() 함수는 arch/x86/include/asm/tsc.h 에 위와 같이 정의되어 있다.
2. 실행 예제
get_cycles() 함수를 테스트하기 위한 간단한 모듈을 작성해보았다:
#include <linux/kernel.h>
#include <linux/module.h>
static void busy_loop(u64 iters)
{
volatile int sink;
do {
sink = 32;
sink += 1;
sink /= 4;
} while (--iters > 0);
(void) sink;
}
#define LOOPS_CNT (1024 * 1024 * 100)
static int __init test_cycles_init(void)
{
u64 time1, time2, time3;
u64 cycles = 0;
printk("test_cycles_init() start...\n");
for (int i = 0; i < 10; i++) {
time1 = get_cycles();
busy_loop(LOOPS_CNT);
time2 = get_cycles();
time3 = time2 - time1;
cycles += time3;
printk("loop_rdtsc %02d: run_cycles = %llu, one call: %llu cycles\n",
i + 1, time3, div_u64(time3, LOOPS_CNT));
}
time1 = div_u64(cycles, LOOPS_CNT * 10);
printk("loop_rdtsc average: one call = %llu cycles\n", time1);
printk("test_cycles_init() end.\n");
return 0;
}
static void __exit test_cycles_exit(void)
{
printk("test_cycles_exit().\n");
}
module_init(test_cycles_init);
module_exit(test_cycles_exit);
MODULE_LICENSE("GPL v2");위 코드는 대입, 덧셈, 나눗셈, 뺄셈을 수행하는 코드를 1024 * 1024 * 100 번 수행하는 busy_loop 함수를 호출하여 걸리는 시간을 측정하는 코드이다. 함수 한번의 호출에 걸리는 사이클과 한번의 반복에 걸리는 사이클을 출력한다.
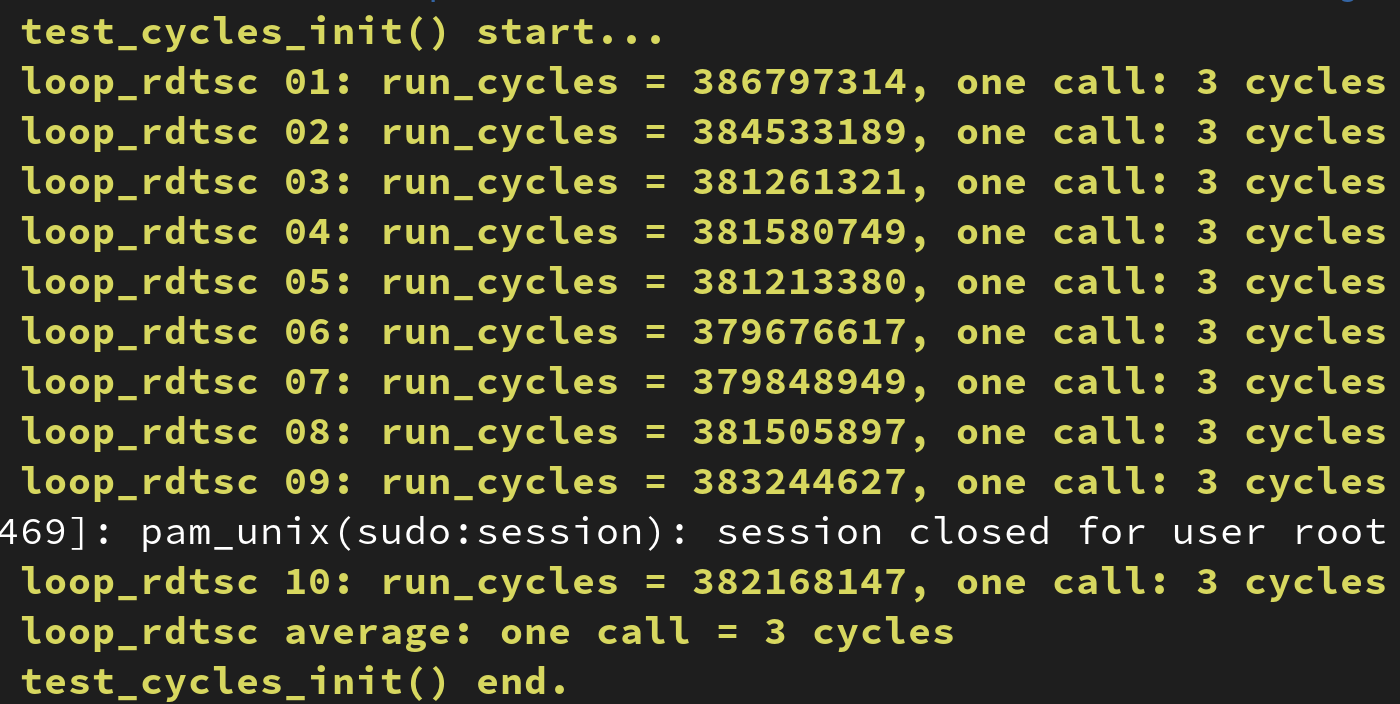
결과는 위와 같았다. 네 개의 연산(대입, 덧셈, 나눗셈, 뺄셈)을 수행하는데 오직 세 사이클만이 소요되었다.
3. 레드 블랙 트리 코드 분석
리눅스 커널은 reb-black tree 테스트를 위한 예제 코드를 제공한다. 해당 소스를 통해 red-black tree 의 노드 삽입, 삭제, 탐색에 대한 성능 테스트를 진행해보겠다.
해당 소스는 lib/rbtree_test.c 에 있으므로 이를 확인하겠다.
1. rbtree 구조체 메모리 할당 및 초기화
가장 먼저 모듈이 삽입되었을 때 실행되는 함수는 rbtree_test_init() 이다.
static int __init rbtree_test_init(void)
{
int i, j;
cycles_t time1, time2, time;
struct rb_node *node;
// nnodes = 100, pref_loops = 1000
nodes = kmalloc_array(nnodes, sizeof(*nodes), GFP_KERNEL);
if (!nodes)
return -ENOMEM;
printk(KERN_ALERT "rbtree testing");
prandom_seed_state(&rnd, 3141592653589793238ULL);
init();가장 먼저 레드 블랙 트리의 노드를 동적할당한 이후 init() 함수를 호출하여 각 노드의 value 와 key 값을 임의의 난수로 초기화한다. 초기화하는 대상은 node 가 아닌 nodes 이고 이는 아래와 같이 정의되어 있다:
struct test_node {
u32 key;
struct rb_node rb;
/* following fields used for testing augmented rbtree functionality */
u32 val;
u32 augmented;
};
static struct rb_root_cached root = RB_ROOT_CACHED;
static struct test_node *nodes = NULL;2. 테스트 1, 2: 삽입과 삭제
time1 = get_cycles();
for (i = 0; i < perf_loops; i++) {
for (j = 0; j < nnodes; j++)
insert(nodes + j, &root);
for (j = 0; j < nnodes; j++)
erase(nodes + j, &root);
}
time2 = get_cycles();
time = time2 - time1;
time = div_u64(time, perf_loops);
printk(" -> test 1 (latency of nnodes insert+delete): %llu cycles\n",
(unsigned long long)time); 가장 먼저 time1 을 get_cycles() 함수의 반환값으로 초기화(현재 사이클을 저장)한다. 이후 perf_loops 만큼 nnodes 개의 노드를 삽입하고 삭제하는 작업을 반복한다. 실행이 끝나면 time2 에 다시 현재 사이클을 저장하여 그 차이(수행에 걸린 사이클)를 출력한다.
테스트 2 는 insert 와 erase 가 insert_cached 와 erase_cached 로 바뀌었을 뿐 테스트 1 과 큰 차이는 없다.
3. 테스트 3: 노드 탐색 (inorder)
time1 = get_cycles();
for (i = 0; i < perf_loops; i++) {
for (node = rb_first(&root.rb_root); node; node = rb_next(node))
;
}
time2 = get_cycles();
time = time2 - time1;
time = div_u64(time, perf_loops);
printk(" -> test 3 (latency of inorder traversal): %llu cycles\n",
(unsigned long long)time);
테스트 3 은 rb_first() 를 호출하고 이후 rb_next() 함수를 반복적으로 호출하여, 트리를 inorder (중위순회) 방식으로 방문하는데 걸리는 시간을 출력한다.
4. 테스트 4: 노드 탐색(leftmost)
time1 = get_cycles();
for (i = 0; i < perf_loops; i++)
node = rb_first(&root.rb_root);
time2 = get_cycles();
time = time2 - time1;
time = div_u64(time, perf_loops);
printk(" -> test 4 (latency to fetch first node)\n");
printk(" non-cached: %llu cycles\n", (unsigned long long)time);
time1 = get_cycles();
for (i = 0; i < perf_loops; i++)
node = rb_first_cached(&root);
time2 = get_cycles();
time = time2 - time1;
time = div_u64(time, perf_loops);
printk(" cached: %llu cycles\n", (unsigned long long)time);
테스트 4 는 rb_first 그리고 rb_first_cached 함수를 반복적으로 호출하여 걸리는 시간을 출력한다. rb_first 는 가장 왼쪽(leftmost)의 원소를 찾기 위해 트리를 따라 내려가는 반면 cached 는 미리 가장 왼쪽의 노드를 저장해두었다가 반환한다.
5. 실행결과
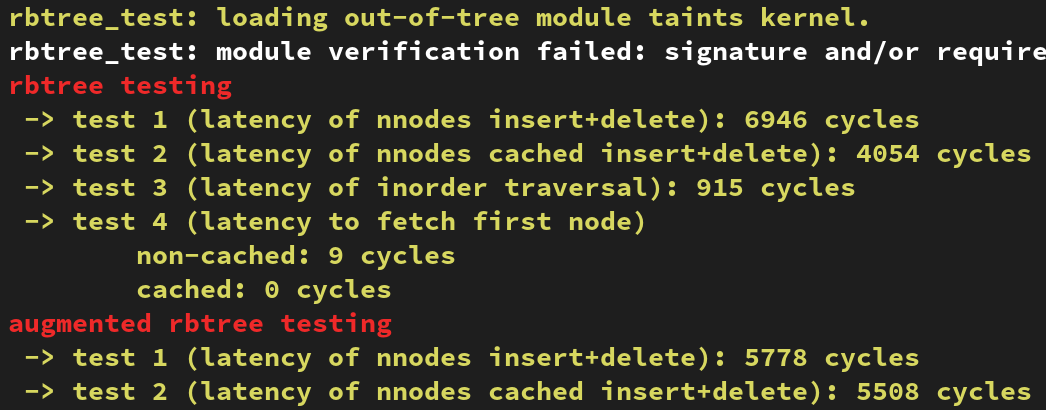
실행 결과는 매우 직관적이다. 각 테스트에 걸린 사이클 수를 출력하는데 테스트 4 의 경우 cached 에 0 사이클이 소요되었다. 이는 rb-tree 가 leftmost 노드의 위치를 기억해두었다가 반환하기 때문이다. augmented rbtree 는 위에서 소개하지 않은 내용인데 rbtree 에 추가적인 정보(단일 키가 아닌 범위에 해당하는)를 더 저장한다. 자세한 내용은 출처를 참조하길 바란다.
출처
[그래프] https://www.desmos.com/calculator
[책] 리눅스 커널 소스 해설: 기초 입문 (정재준 저)
[이미지] https://ko.wikipedia.org/wiki/레드-블랙_트리
[사이트] https://www.kernel.org/doc/Documentation/rbtree.txt
