0. 커널 스레드란?
커널 스레드 는 커널 공간에서만 실행되는, 유저 공간과 상호 작용하지 않는 스레드이다. 따라서 커널 스레드는 실행과 휴면 등의 모든 동작을 커널에서 직접 제어 · 관리하며, 대부분의 커널 스레드는 시스템이 부팅할 때 생성되고 시스템이 종료할 때까지 백그라운드로 실행된다.
1. 커널 스레드의 종류
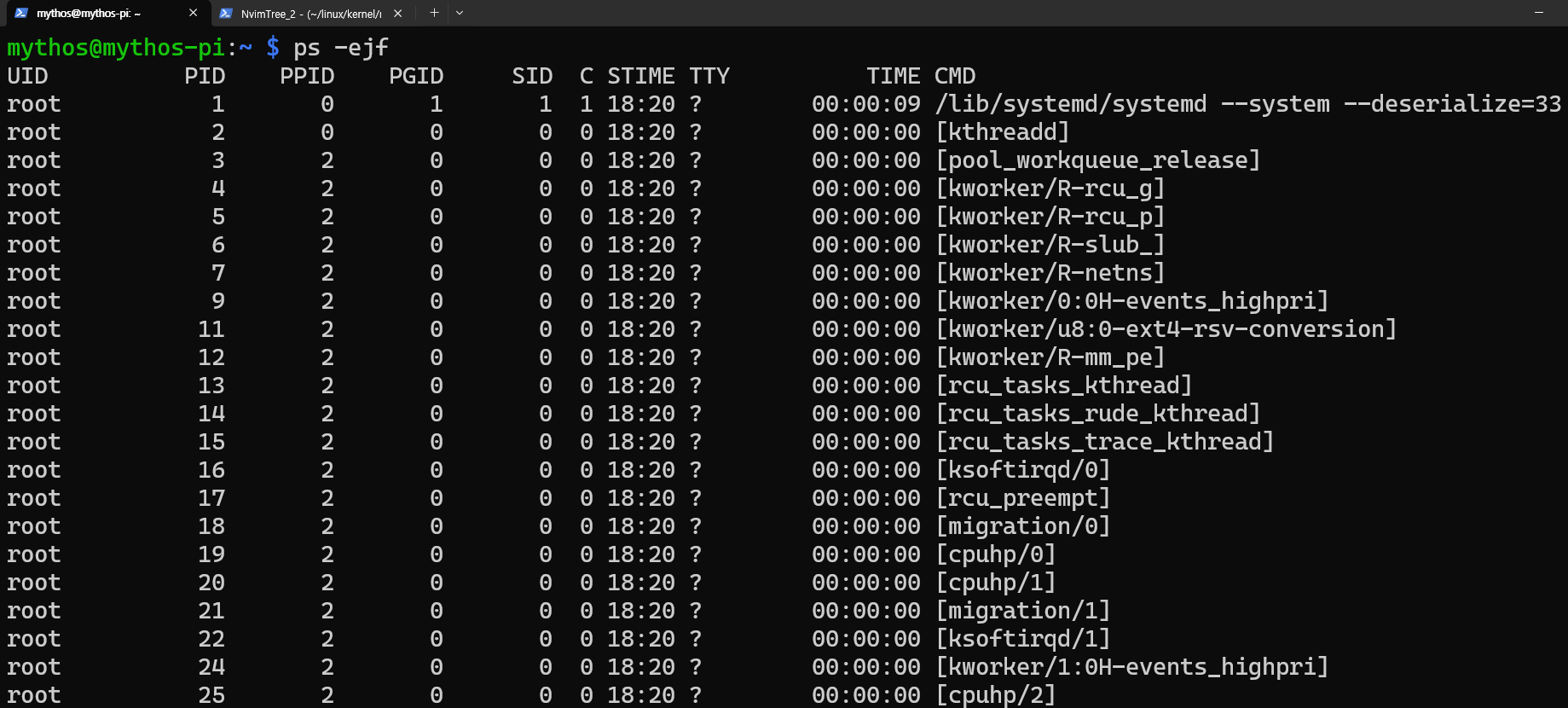

kthreadd프로세스
모든 커널 스레드의 부모 프로세스, 핸들러 함수는kthreadd()(kernel/kthread.c)이며 커널 스레드를 생성하는 역할을 수행한다.kworker스레드
큐잉된 워크(work)를 실행하는 프로세스이다. 스레드 핸들러 함수는worker_thread()(kernel/workqueue.c) 이며,process_one_work()(kernel/workqueue.c) 함수를 호출해서 워크를 실행하는 기능을 수행한다.ksoftirqd프로세스
이름과 같이Soft IRQ를 위해 실행하는 프로세스이다. 프로세스 이름 뒤에 붙는 숫자는 실행 중인 CPU 의 번호이다.ksoftirqd/3프로세스는 CPU3 에서만 동작한다.irq스레드
irq/irq-num-irq-name과 같은 형태의 이름을 가진 스레드를IRQ 스레드라 부르며 인터럽트 후반부 처리를 위해 쓰이는 프로세스이다.
2. 커널 스레드의 생성
커널 스레드의 생성 과정은 크게 2단계로 나뉜다:
- 단계:
kthreadd프로세스에게 커널 스레드의 생성을 요청kthread_create()kthread_create_on_node()
- 단계:
kthreadd프로세스가 커널 스레드를 생성kthreadd()create_kthread()
- 1 단계
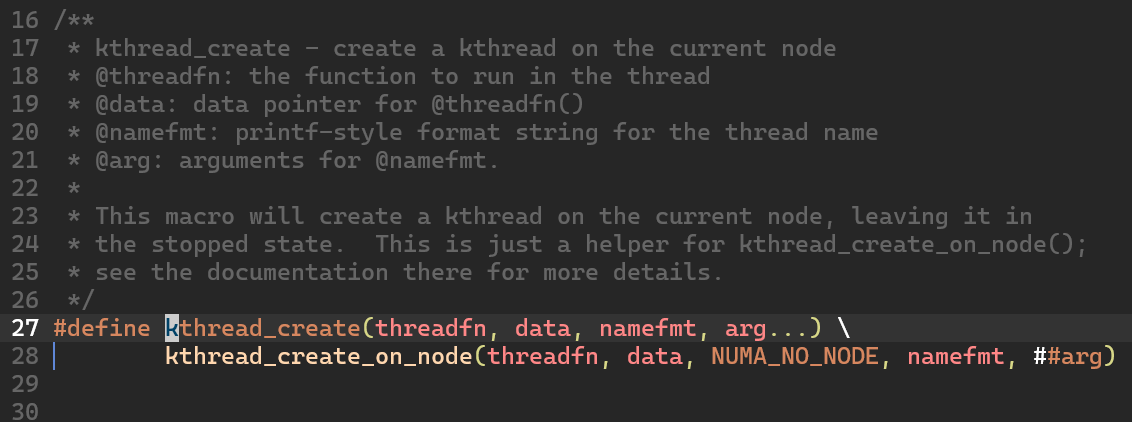
kthread_create() 는 kthread_create_on_node() 의 래퍼 매크로인데 별거 없다. 그냥 인자를 풀어서 넘겨준다.
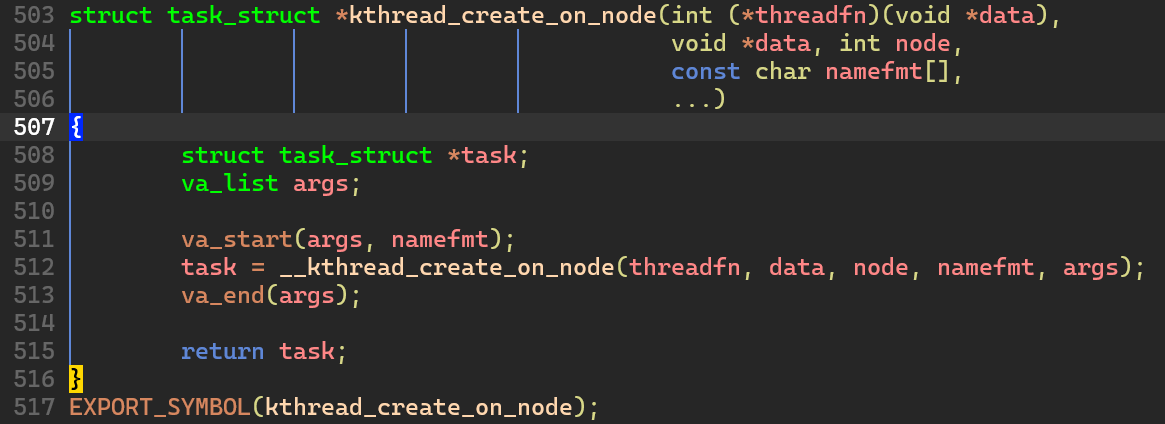
kthread_create_on_node() 함수도 그냥 인자를 va_list 로 읽어서 넘겨준다. 실질적인 함수의 본체는 __kthread_create_on_node() 이다.
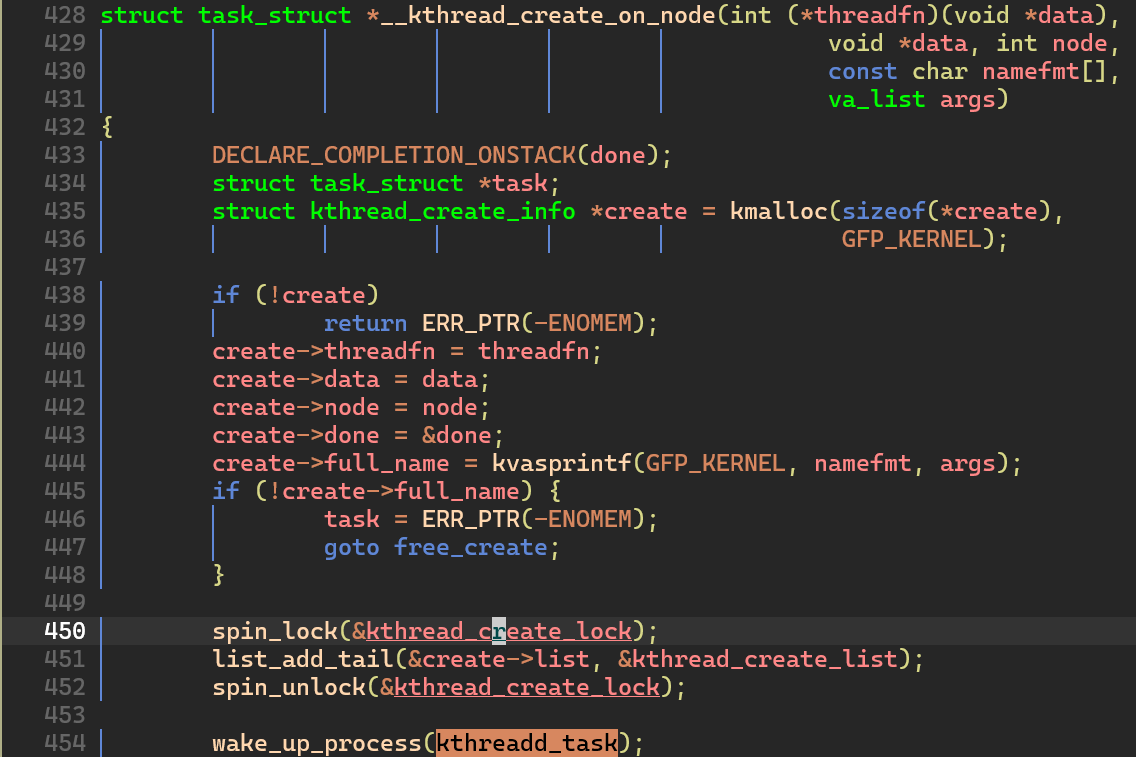
책에서는 full_name 과 관련된 내용이 빠져있는데 실제 코드에는 있다. 핵심적인 내용은 다음과 같다:
kmalloc()함수로kthread_create_info구조체를 할당하고, 구조체의 멤버를 채워 넣는다.kthread_create_list연결 리스트에 새롭게 생성한kthread_create_info구조체를 연결한다.
kthread_create_list는 전역 변수이다.wake_up_process로kthreadd_task를 깨운다.
kthread_create_list와 마찬가지로kthreadd_task역시 전역 변수로 등록되어 있다. 앞서 말했듯이kthreadd프로세스의 핸들러 함수는kthreadd()이므로 이 프로세스가 실행될 것이다.
- 2 단계
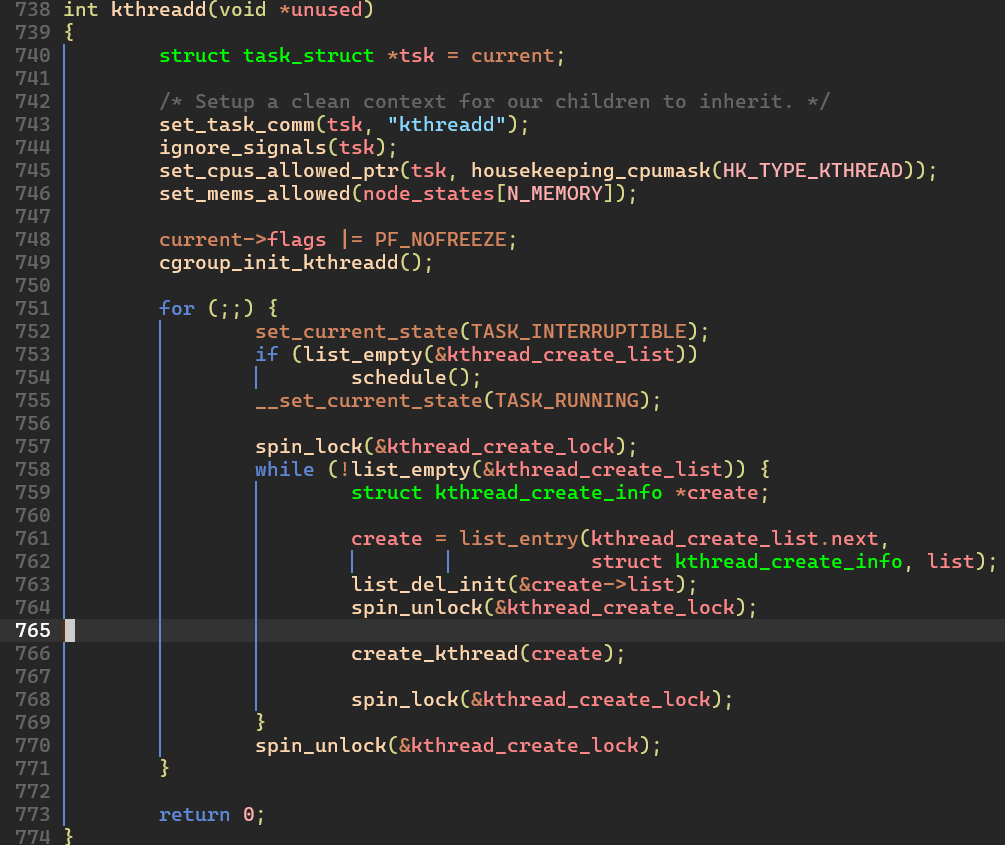
kthreadd() 함수는 짧고 간명하다:
- 최초에는
kthread_create_list가 비어있을 것이므로schedule()을 호출하여 deep sleep 에 빠진다. - 어느 날, 잠자던
kthreadd()의 코털을wake_up_process()로 건드린다. - 일어나서 어떤 새끼(
kthread_create_list)가 깨웠는지 확인하다. while문 돌면서 한 놈도 빠짐없이 전부 다 조진다.
이 과정에서kthread_create_lock을 풀고 잠그는 과정을 계속 반복하는데 왜 이렇게 했는지도 의문임. 단순한 추측인데, 새롭게 생성한 커널 스레드가 한번 더 스레드를 생성하면서spin_lock의 이중 잠금이 걸리는 것을 방지? 하려는 게 아닌가 싶다.- 쉬기 전에 처리하지 못한 잔챙이까지 잡아낸다. (왜 이런 구조로 만들었는지는 의문. 이것도 아마 새롭게 생성한 커널 스레드가 스케줄링 되면서 다시
kthread_create()를 호출할 수 있기 때문이 아닌가 하는 추측을 한다.)
* create_kthread() 함수 분석
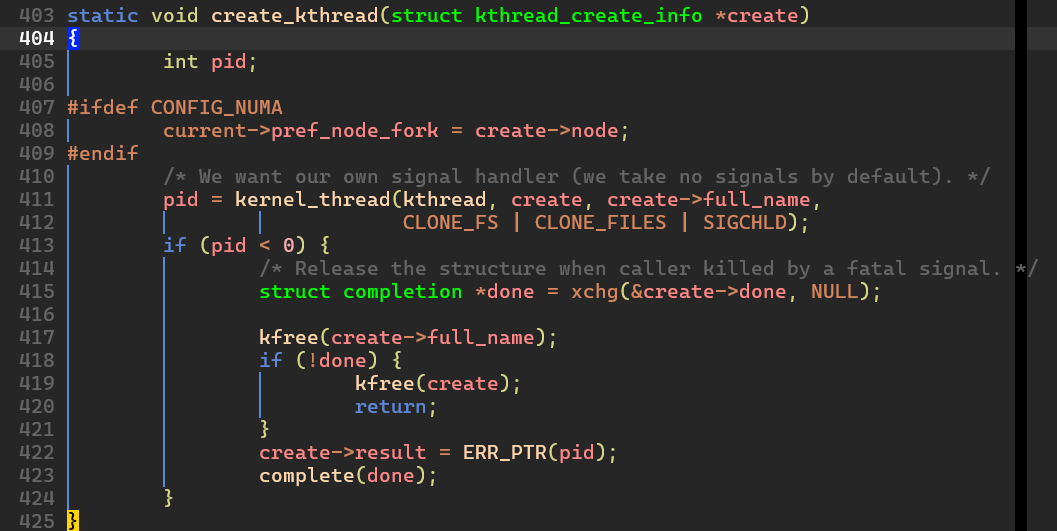
별거 없다. 그냥 kernel_thread() 를 수행한다. 다만 여기에는 kernel_thread() 실패에 대한 예외처리 코드가 함께 붙어있다.
* kernel_thread() 함수 분석
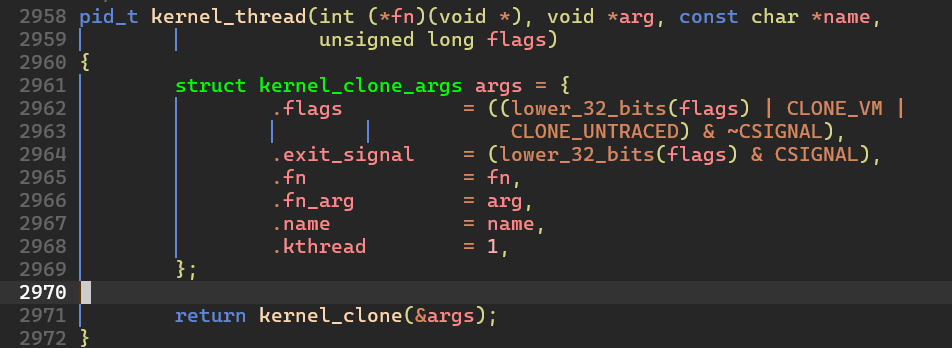
kernel_thread() 함수는 kernel_clone 함수 호출을 위해 args 를 구성해서 인자로 넘긴다. 결국 핵심 코드는 kernel_clone() 이다. 책에는 _do_fork() 로 나오는데 이건 과거의 구현이다.
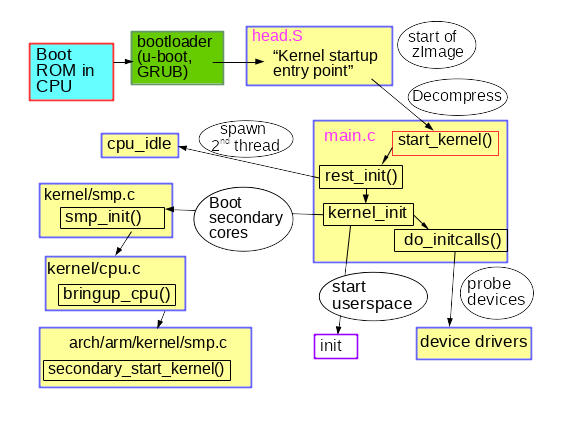 |
|---|
| 출처: https://opensource.com/article/18/1/analyzing-linux-boot-process |
궁금해서 kthreadd() 는 누가 생성하는지 확인해봤는데, 아무래도 커널 부팅 과정에서 생성되는 것 같다. init/main.c 의 rest_init() 함수에서 kernel_thread() 함수로 kthreadd 를 생성한다.
3. 커널 내부 프로세스의 생성 과정
책에서는 _do_fork() 로 소개되고 있는 kernel_clone() 함수의 동작은 크게 2단계로 분류할 수 있다:
- 단계: 프로세스 생성
copy_process()함수를 호출해서 프로세스를 생성한다. 함수의 이름에서 볼 수 있듯이 부모 프로세스의 리소스를 자식 프로세스에게 복제한다. - 단계: 생성한 프로세스의 실행 요청.
copy_process()함수를 호출해 프로세스를 만든 후wake_up_new_task()함수를 호출해서 프로세스를 깨운다. 이는 스케줄러에게 프로세스의 실행을 요청한다는 뜻이다.
- kernel_clone() 함수
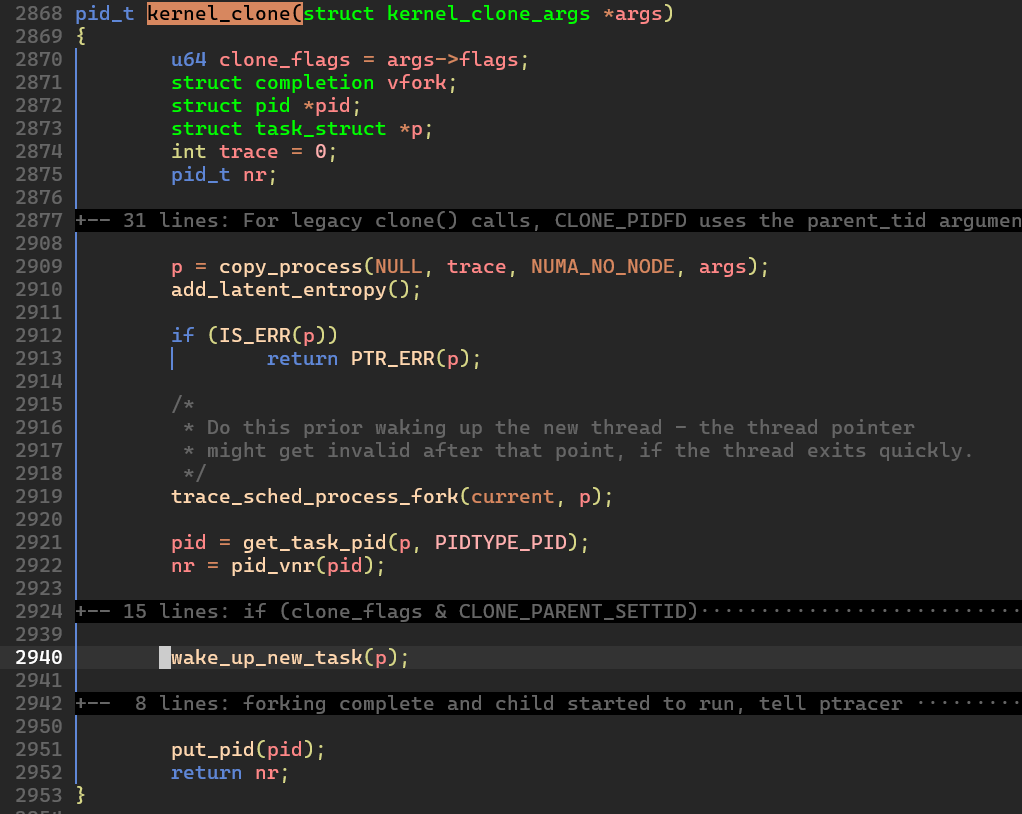
copy_process()함수를 통해 프로세스를 생성wake_up_new_task()함수로 생성한 프로세스를 깨움get_task_pid(),pid_vnr()함수로pid를 생성하고 반환.
- copy_process() 함수
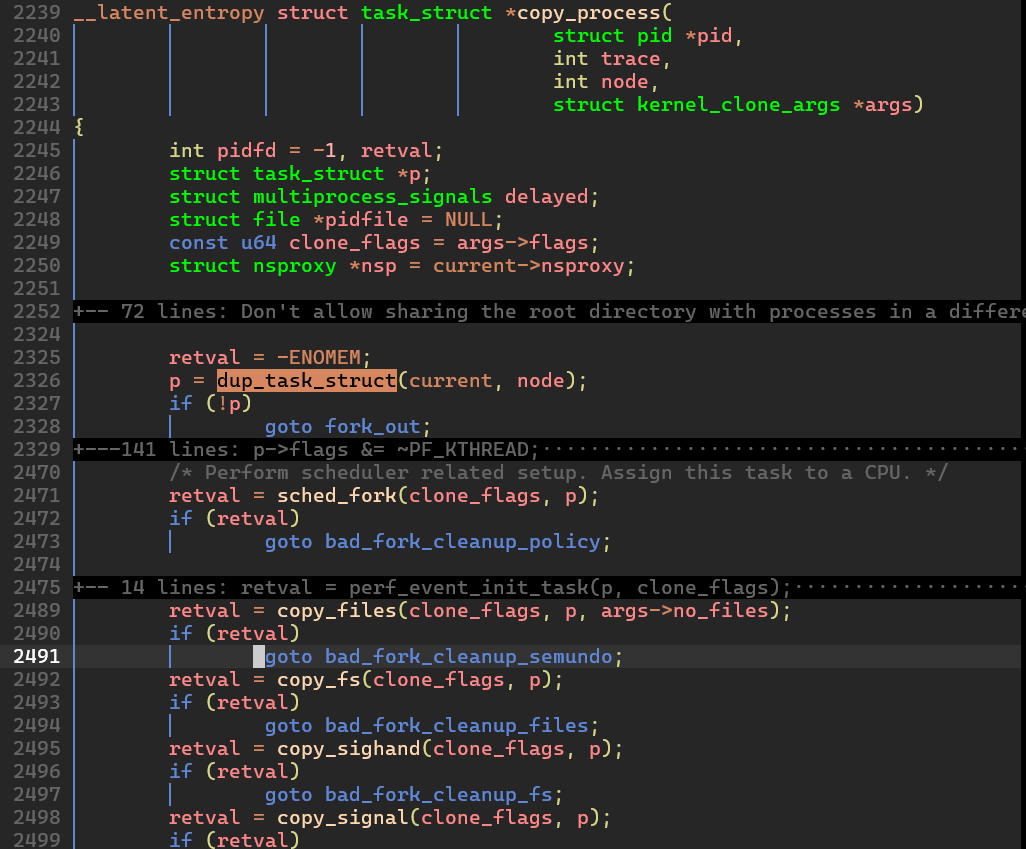
엄청나게 많은 라인을 스킵했는데... 핵심 동작은 다음과 같다:
dup_task_struct()함수로task_struct구조체와 프로세스가 실행될 스택 공간을 할당한다.sched_fork()함수를 통해task_struct구조체에서 스케줄링 관련 정보를 초기화한다.copy_XXX()류 함수로 프로세스의 자원(파일 디스크립터, 시그널 핸들러, 스레드, etc.)을 초기화한다. 이때, 생성 플래그에 따라 부모 프로세스로부터의 관계가 설정된다. (시스템 프로그래밍을 하다보면 signal 관련 정보나 file descriptor 의 공유 여부(Close-on-exec) 등등을 설정할 수 있는데 이에 해당하는 것 같다)
- wake_up_new_task() 함수
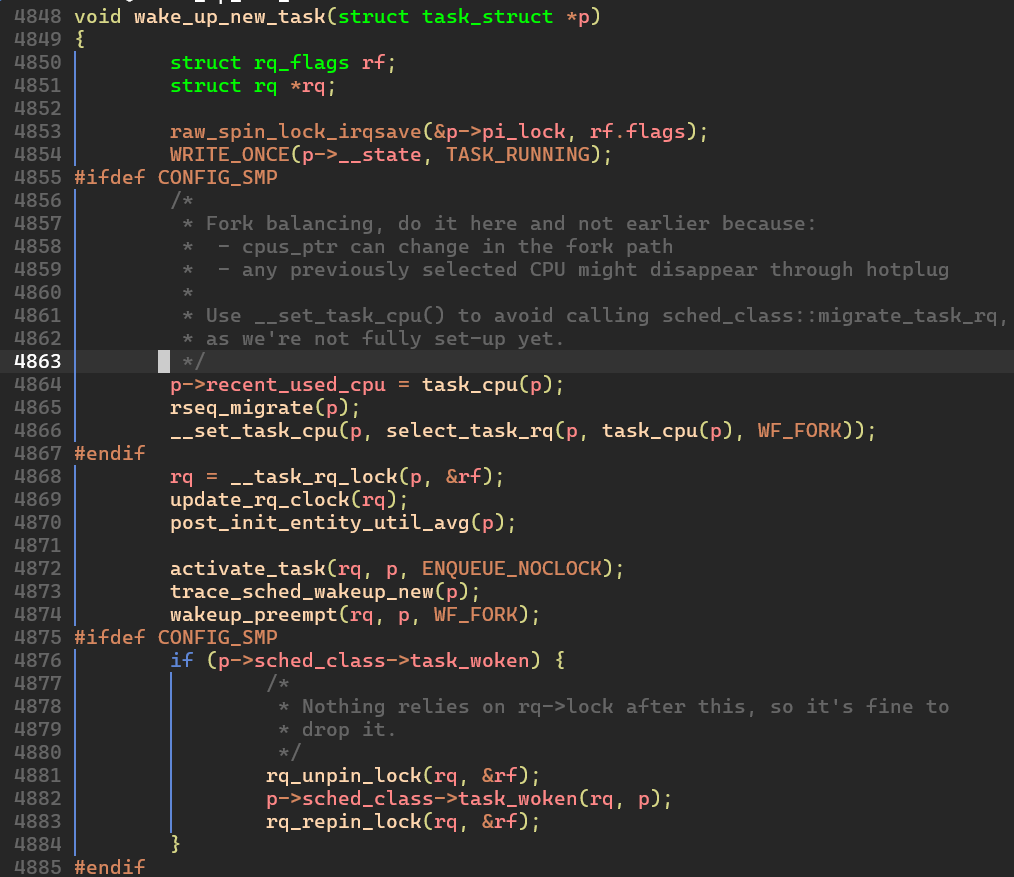
여기서부턴 책과 코드가 약간 다른데 핵심적인 내용은 다음과 같다:
- 프로세스 상태를
TASK_RUNNING으로 변경
WRITE_ONCE(p->__state, TASAK_RUNNING); - 현재 실행 중인 CPU 번호를
thread_info구조체의cpu필드에 저장
__set_task_cpu(p, select_task_rq(p, task_cpu(p), WF_FORK)); - 런큐에 프로세스를 큐잉
rq = __task_rq_lock(p, &rf); ... activate_task(rq, p, ENQUEUE_NOCLOCK);
4. 프로세스의 종료 과정
프로세스는 크게 두 가지 흐름으로 종료된다:
- 유저 애플리케이에서
exit()함수를 호출할 때 - 종료 시그널을 전달받았을 때
유저 프로세스가 정해진 시나리오에 따라 종료해야 될 때에는 exit() 함수를 호출하여 종료하고, 종료 시그널을 전달받은 경우 유저/커널 프로세스 관계 없이 커널 내부에서 소멸된다.
- do_exit() 함수
do_exit() 함수는 kernel/exit.c 에 정의되어 있고 다음과 같이 선언되어 있다:
void __noreturn do_exit(long code); do_exit() 함수는 실행 후 반환되지 않으므로 __noreturn annotation 이 붙는다. 전달되는 code 인자는 프로세스의 종료 코드를 의미한다. 동작방식은 다음과 같다:
init프로세스가 종료하면 강제 커널 패닉 유발- 프로세스 리소스 등을 해제
- 부모 프로세스에게 자신이 종료되고 있다고 알림
- 프로세스의 실행 상태를
task_struct구조체의state필드에TASK_DEADE로 설정 do_task_dead()함수를 호출해 스케줄링을 실행
책에서는 재호출 여부에 대한 내용도 있는데 rpi-6.6.y 기준으로는 해당 코드가 빠졌기 때문에 생략한다. (이 부분은 do_exit() 을 호출하는 make_task_dead() 에서 수행된다. do_group_exit() 에서는 수행되지 않는다. 일반적인 상황은 아닌듯 함)
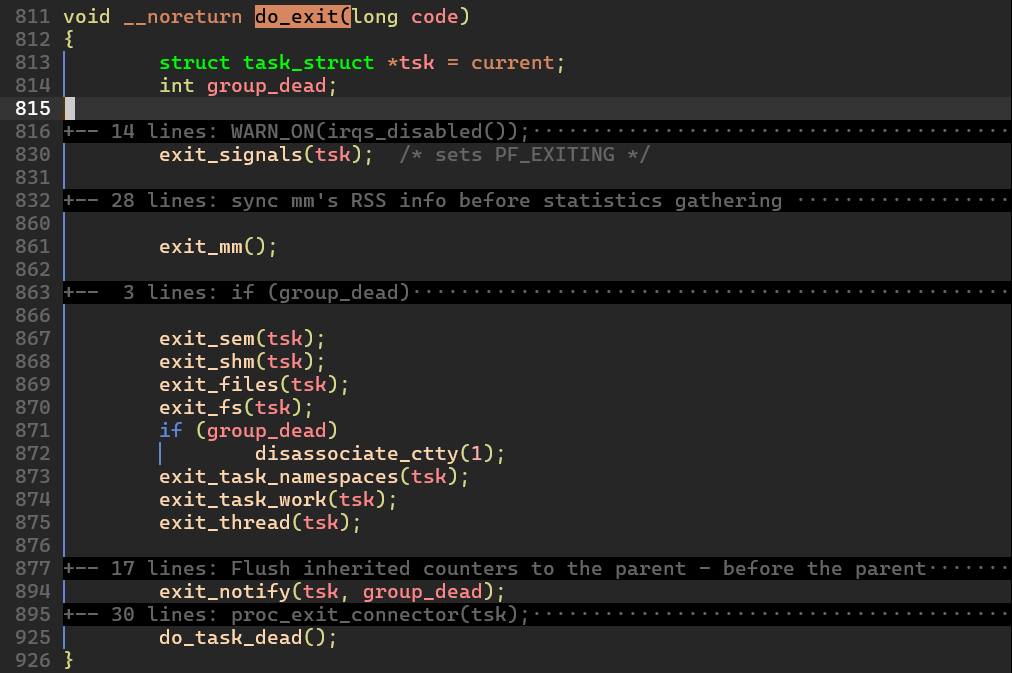
830번째 라인에서 exit_signals(tsk); 로 task_struct 구조체의 flags 에 PF_EXITING 플래그를 설정해서 현재 프로세스가 do_exit() 을 실행 중임을 알린다.
exit_mm() 함수를 호출해서 mm_struct 구조체의 리소스를 해제하고 메모리 디스크립터의 사용 카운트를 1만큼 감소시킨다. 이후에 프로세스가 사용하고 있는 자원을 반납한다.
exit_notify(tsk, group_dead) 함수를 호출해서 부모 프로세스에게 현재 프로세스가 종료 중이라는 사실을 통지한다.
마지막으로 do_task_dead() 함수를 호출한다. 당연히 종료되는 프로세스는 본인의 스택 영역을 해제할 수 없으므로 __schedule() 을 호출하여 해제하지 못한 남은 자원들의 반납을 수행하게 된다.
- do_task_dead() 함수 호출 뒤의 동작
__schedule() 함수가 호출된 뒤에는 context_switch() 함수가, 그 다음으로 finish_task_switch() 함수를 호출하게 된다. 위 함수들이 실행되는 과정에서 프로세스가 소멸하게 된다.
- 종료할 프로세스는
do_exit()함수에서 대부분의 자신의 리소스를 커널에게 반납하고 자신의 상태를TASK_DEAD로 변경한다. - 컨텍스트 스위칭을 한다.
- 컨텍스트 스위칭으로 다음에 실행하는 프로세스는
finish_task_switch()함수에서 이전에 실행했던 프로세스의 상태가TASK_DEAD라면 프로세스의 스택 공간을 해제한다.
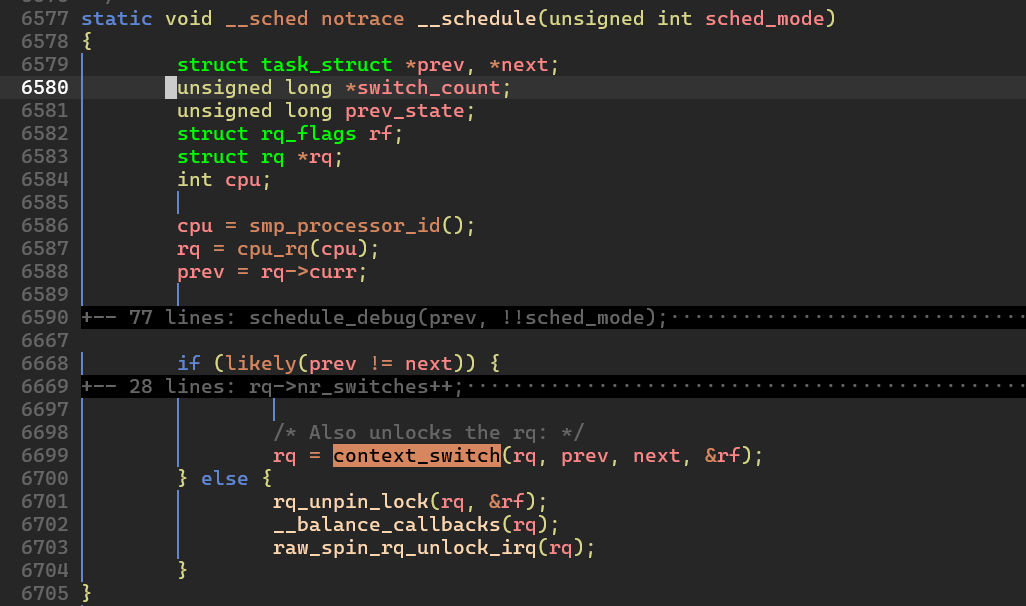
__schedule() 함수가 context_switch() 함수를 호출한다.
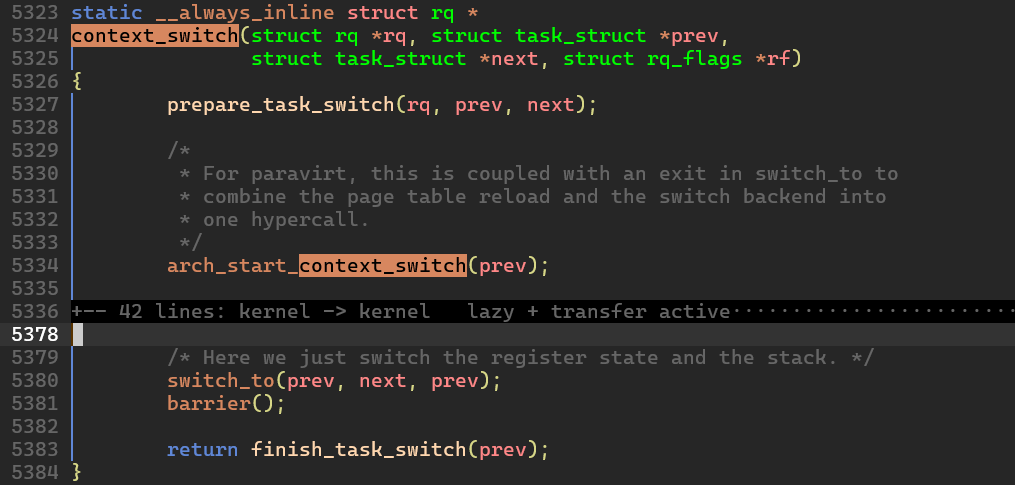
context_switch() 함수가 finish_task_switch() 함수를 호출한다. switch_to 를 호출한 시점에서 이전 프로세스에서 다음 프로세스의 전환이 이뤄졌으므로 finish_task_switch() 는 다음에 스케쥴링된 프로세스가 실행하게 된다.
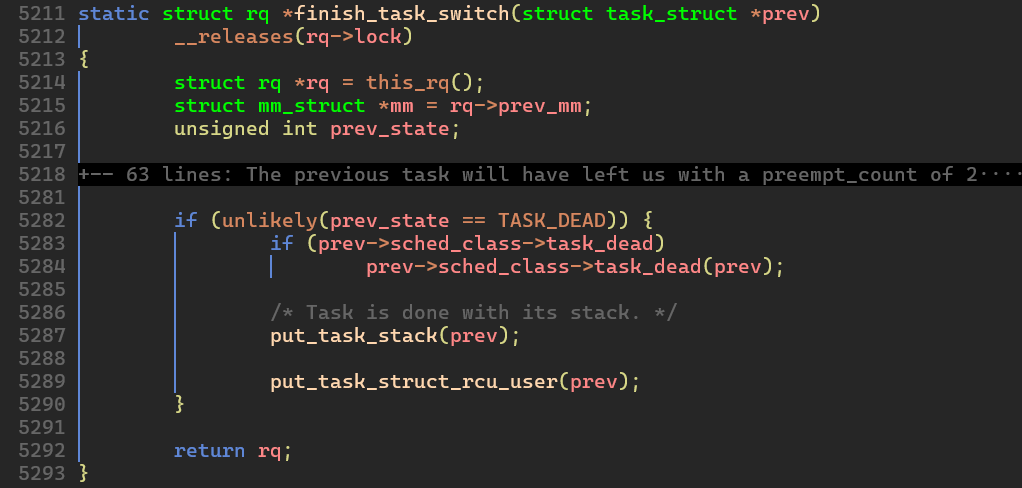
finish_task_switch() 함수는 put_task_stack() 함수를 호출해서 프로세스의 스택 메모리 공간을 해제하고 커널 메모리 공간에 반환한다.
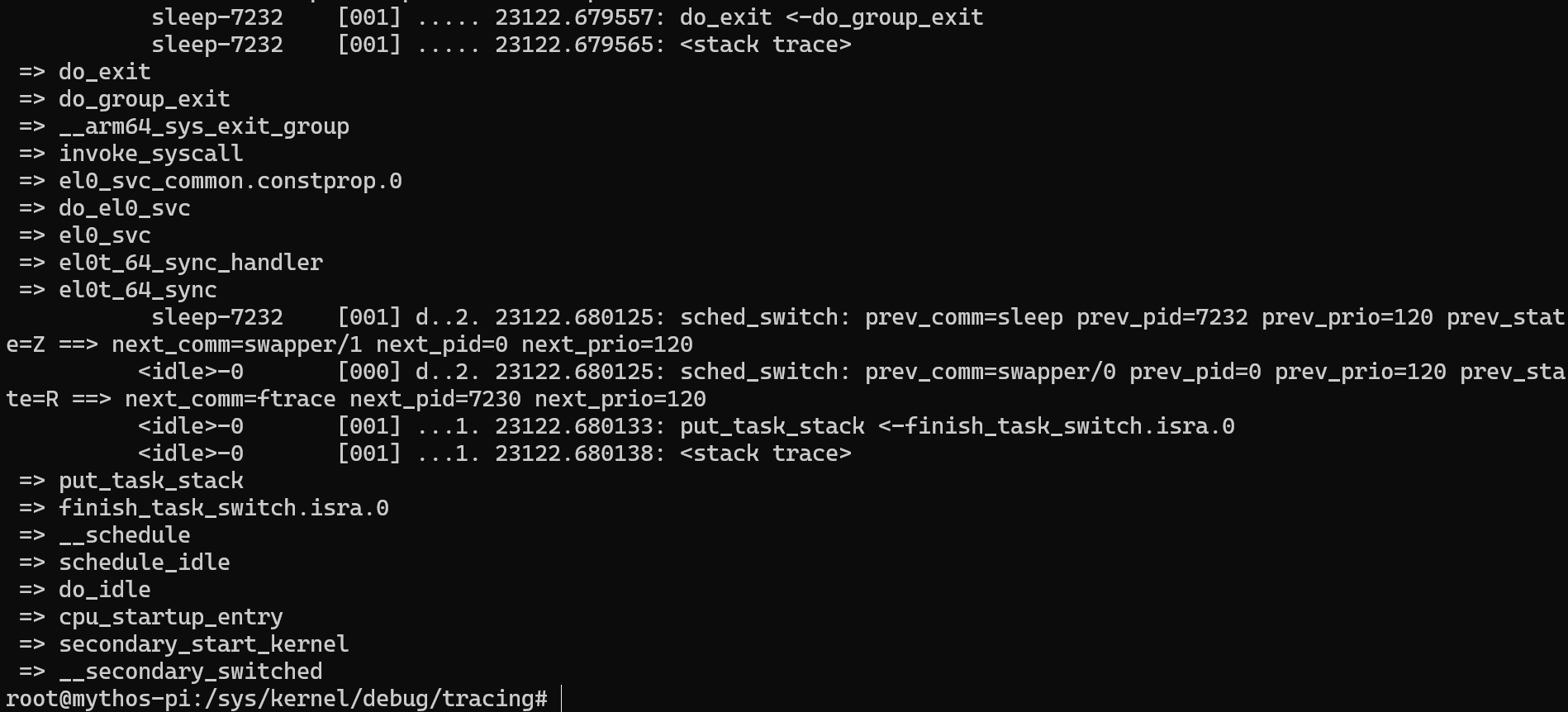
ftrace 로 확인해보면 __schedule() 함수가 반환된 이후 (프로세스가 변경된 이후) finish_task_switch() 함수가 호출되고 이어서 put_task_stack() 함수가 되어 최종적으로 스택 메모리 공간이 해제된다.
