SQL Database
SQL은 Structured Query Language 의 약자이며 데이터베이스 자체가 아니다
특정 유형의 데이터베이스와 상호작용하기 위해 사용할 수 있는 쿼리언어이다.
SQL을 사용하면 RDBMS ( Relaional DataBase Management Systems ) 에서
데이터들을 저장, 업데이트 삭제 및 검색할 수 있다.
또한 데이터베이스는 두가지 특징을 가진다.
- 데이터는 구조화된 데이터스키마 형식을 따라 데이터베이스 테이블에 저장된다.
- 데이터는 관계를 통해 연결된 여러개의 테이블에 분산된다.
Strict Schema
데이터는 테이블 안에 레코드( Row )로 저장이 되고 각 테이블은 명확하게 정의된 구조를 가진다.
구조는 필드 이름 및 데이터 유형에 대해 정의된다.
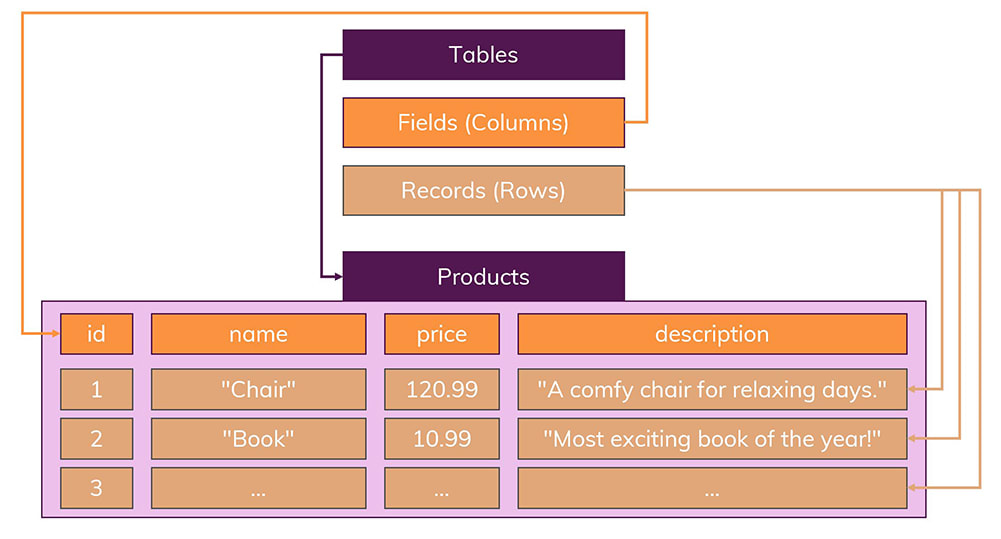
이 스키마형식에 맞지 않는 레코드는 추가할 수 없다.
Relations
SQL database의 중요한 부분으로 Relations가 있다.
데이터를 여러 테이블로 분할하여 데이터 중복을 피할 수 있다.
따라서 Users, Products, Orders 각각의 테이블을 생성하고
각 테이블에는 다른 테이블 중 하나에 저장되지 않는 데이터만 저장된다.
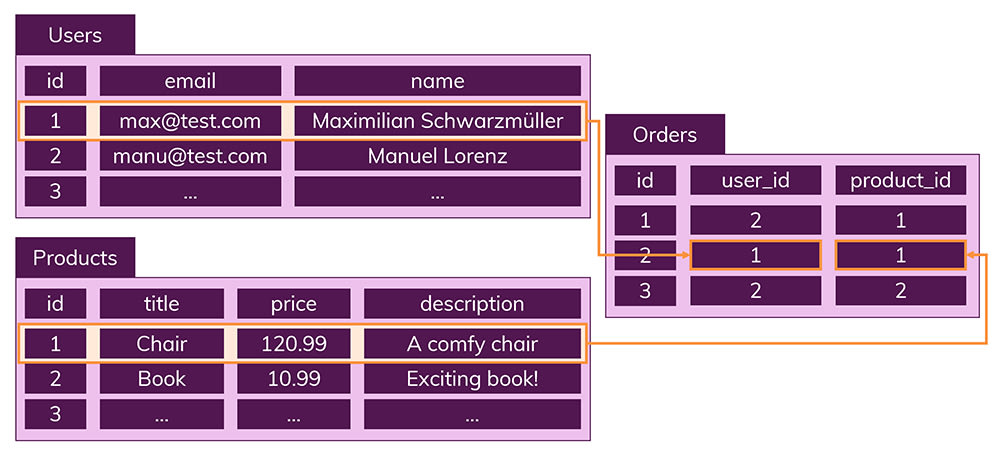
이 명확한 구조는 장점을 가진다.
데이터는 항상 한 테이블에서만 관리되고 테이블간 중복되지 않기 때문에
다른 테이블에 잘못된 데이터가 들어있을 경우가 없다.
NoSQL Database
NoSQL은 이름처럼 SQL의 접근방식을 따르지 않는다.
- No Schemas
- No Relations
SQL에서 Table은 NoSQL에서 Collections이며
Records는 Documents라고 부른다.
이것은 단순 이름만 짓는 것이 아니라 핵심적인 차이가 있다.
서로 다른 구조의 데이터를 동일한 컬렉션에 넣을 수 있으며 SQL 에서는 이러한 작업을 수행할 수 없다.
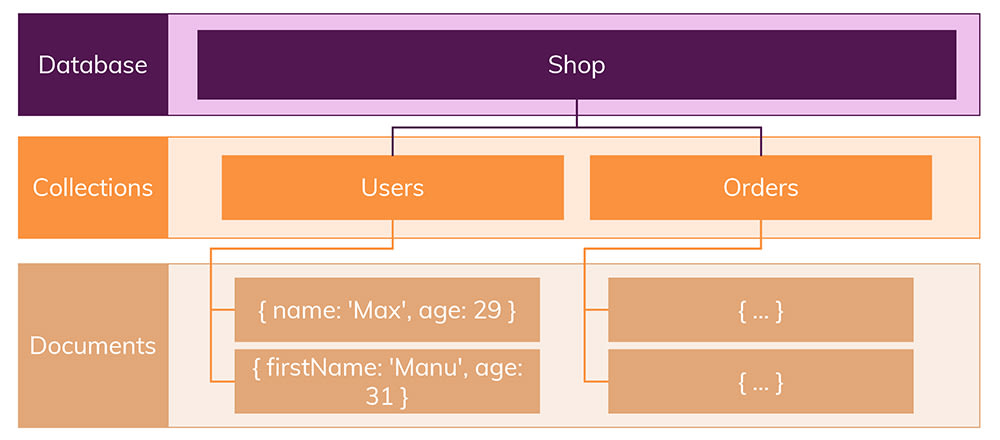
문서는 JSON데이터와 비슷하며, 스키마에 대해 걱정할 필요가 없다.
일반적으로 관련 데이터를 collection에 넣는다.
많은 order을 받는다면 일반적인 정보를 모두 포함한 데이터를 orders 컬렉션에 저장한다.
즉 관계형 데이터베이스에서 사용했던 Users나 Products정보 또한 Orders에 포함되어 저장한다.
따라서 여러 테이블 / 콜렉션에 join할 필요없이 이미 필요한 모든 것을 갖춘 문서를 작성하게 된다.
실제로 NoSQL에서는 join이란 개념이 존재하지 않는다.
대신 컬렉션을 통해 데이터를 복제하여 각 컬렉션 일부분에 속하는 데이터를 정확하게 산출하도록 한다.

이러한 데이터 중복 개념은 처음에는 불편해 보일 수 있다.
실수로 컬렉션 B에서는 데이터를 수정하지 않았는데 컬렉션A에서만 데이터를 수정할 위험이 있다.
특정 데이터를 같이 사용하는 모든 컬렉션에서 똑같이 데이터 수정을 하도록 해야한다.
하지만 큰 장점은 복잡한 ( 어떤 시점에서는 느린 ) join 으로 작업할 필요가 없다는 것이다.
모든 데이터는 필요한 구조에 이미 저장되어 있다.
특히 자주 변경되지 않는 데이터에 유용하다.
Vertical & Horizontal Scaling
또한 데이터베이스를 비교할 때 고려해야 할 개념으로 Scaling ( 확장 ) 이 있다.
확장은 수직적과 수평적 확장이 있으며
-
수직적 확장
데이터베이스 서버의 성능을 향상시키는 것 ( 예로 CPU를 업그레이드 하는 것 )
-
수평적 확장
반면 수평적 확장은 더 많은 서버가 추가되고 데이터베이스가 전체적으로 분산되는 것을 의미
하나의 데이터베이스에서 작동하지만 여러 호스트에서 작동한다.
데이터 저장방식으로 인해 SQL 데이터베이스는 일반적으로 수직 확장만 지원한다.
수평적 확장은 NoSQL에서만 가능.
SQL 데이터베이스는 샤딩 ( Sharding ) 의 개념을 알고 있지만 특정 제한이 있으며 구현하기 어렵다.
NOSQL는 이를 기본적으로 지원하므로 여러 서버에서 데이터베이스를 쉽게 분리 할 수 있다.
각각의 장단점
SQL 장점
- 명확하게 정의된 스키마
- 데이터를 효율적, 체계적으로 저장할 수 있다.
NoSQL 장점
- 유연한 데이터 모델
일반적으로 NoSQL 데이터베이스는 매우 유연한 스키마를 가진다.
유연한 스키마는 요구사항의 변화에 따라 데이터베이스의 변화를 쉽게 만든다.
- 수평적인 확장
대부분의 SQL 데이터베이스는 현재 서버의 요구사항을 초과할 경우 수직적 확장을 해야한다.
(더 크고 비싼 서버로 마이그레이션해야합니다 ).
반대로 NoSQL 데이터베이스는 수평으로 확장할 수 있으므로 필요할 때마다 저렴한 범용서버를 추가할 수 있다.
- 빠른 쿼리
SQL 데이터베이스의 경우 여러 테이블의 데이터를 결합해야한다.
또한 테이블사이즈가 커지면 조인이 비싸질 수 있다.
SQL 단점
- 테이블 구조가 미리 정의되어 있기 때문에 확장하기 쉽지 않다.
- 관계를 맺기에 Join문이 많은 복잡한 쿼리 생성
NoSQL 단점
- 중복된 데이터가 변경된 경우 여러 개의 콜렉션에서 데이터를 바꿔야한다.
언제 무엇을 쓰는게 좋을까?
SQL
- 관계를 맺고있는 데이터가 자주 변경되는 앱일 경우
- 명확한 스키마가 사용자와 데이터에게 중요한 경우
NoSQL
- 정확한 데이터 구조를 알 수 없거나 변경 / 확장 될 수 있는 경우
- 읽기 처리를 자주하지만 데이터를 자주 변경하지 않는 경우
- DB의 수평적 확장이 필요할 때