참고 사이트들
시간 복잡도
https://moonsu.tistory.com/58
https://easy-code-yo.tistory.com/13
연결리스트
https://overcome-the-limits.tistory.com/16
스택
https://www.geeksforgeeks.org/stack-data-structure/?ref=ghm
https://medium.com/@songjaeyoung92/%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0-javascript-stack-%EC%9D%B4%EB%9E%80-31f9bbb84897
#1. 배열
1. 크기
선언할 때 고정적이다.
- 메모리 안에서 데이터들이 나란히 놓여지기 위해 미리 배열의 길이(=메모리 공간)를 설정해줘야한다. (Python과 JS는 알아서 설정해줌.)
- 이러한 특징 덕분에 컴퓨터는 이 배열의 길이와 어디서 시작하고 끝나는지를 알 수 있게 됨.
2. 참조 성능
좋다. 주소가 연속적이기 때문이다.
- 인덱스 값이 있어서 그걸로 조회하면 되기 때문에, 특정 값에 도달하려고 처음부터 원하는 값까지 모두 거치지 않아도 된다. (연결 리스트와 대비된다.)
3. 수정(추가/제거) 성능
좋지 않음.
- 수정이 필요할 경우, 재선언 해야한다. (연결 리스트와 대비된다.)
4. 공간 복잡도
좋다.
- 왜 좋지?
5. 시간 복잡도
O(1) 이다.
해설:
- O(big Oh) = 최악의 실행시간 = 상한(upper bound)을 의미
- 여기서 1은 상수(constant)를 의미
- 찾고자 하는 값이 몇 번째 인덱스에 있는지 알고 있다면 매우 빠르게 검색가능(시작 주소값에서 단순사칙연산)
#2. 연결 리스트
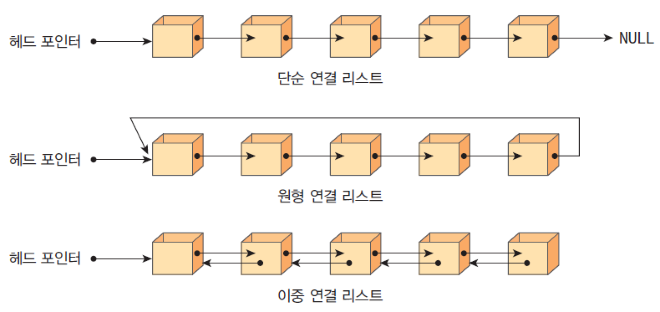
단순 연결 리스트, 원형 연결 리스트, 이중 연결 리스트로 나뉜다.
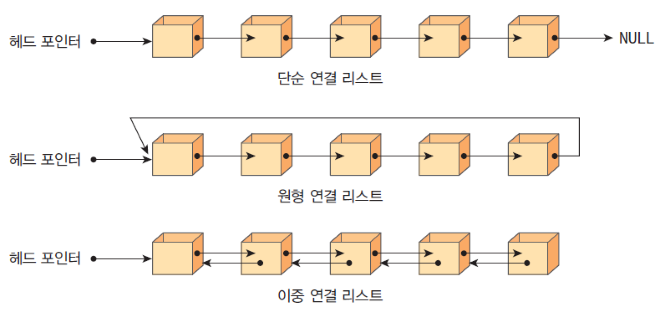
0. 용어
- 노드 node: 기본 단위. 연결 리스트에서는 데이터와 포인터(위에 보이는 화살표) 정보를 가졌다.
- head : 연결 리스트 구조에서 맨 앞
- tail : 연결 리스트 구조에서 맨 뒤
- next : 다음 노드에 대한 참조
- prev : (이중 연결 리스트) 이전 노드에 대한 참조
1. 크기
동적. 언제든지 바뀔 수 있다!
2. 참조(읽기/쓰기)성능: 안좋음.
연결 리스트 공통
- 여러 노드들의 연결에 따라 이어진 구조. 위 이미지에서는 마치 물리적으로도 차례대로 위치한 것 같지만, 노드로 이어진 '순서'만 그렇고 '위치'는 전혀 아니다. = 주소가 비연속적. (예시로 승무원의 비행 노선을 생각해보자.)
- 다음 노드가 없을 경우: next에 null을 저장한다.
단순 연결 리스트
- 중간이나 마지막을 참조하게 될 경우, head(연결 리스트의 첫 데이터)부터 순서대로 거쳐가야 목표 지점에 닿는다.
- 위 사유로 뒤 쪽의 노드를 탐색 할 경우, 탐색 속도가 많이 느려진다.
- 각 데이터는 바로 다음 참조데이터의 값만 가지고 있다.
이중 연결 리스트의 경우:
- 장점: next 외에도 prev(역방향 화살표: 위 그림 참고)를 활용해서 지나온 node를 다시 빠르게 접근할 수 있다.
- 단점: 그러나 prev의 사용은 곧 추가 저장 공간의 필요로 이어저 단점이 되기도 한다.
원형 연결 리스트의 경우:
- 장점: 마지막으로 작업하던 위치를 head 및 tail로 설정하여 작업하던 곳에서 이어 연산(탐색/삽입/삭제 등)할 수 있게 한다.
- 단점: 다만 이 경우 데이터 순서의 개념이 계속 변화, 각각의 순서가 모호해진다. 즉 인덱스를 사용한 탐색이 어려워진다.
3. 수정(추가/제거)성능
매우 쉬움.
추가하는 경우: 시간 복잡도 O(1). (1은 상수)
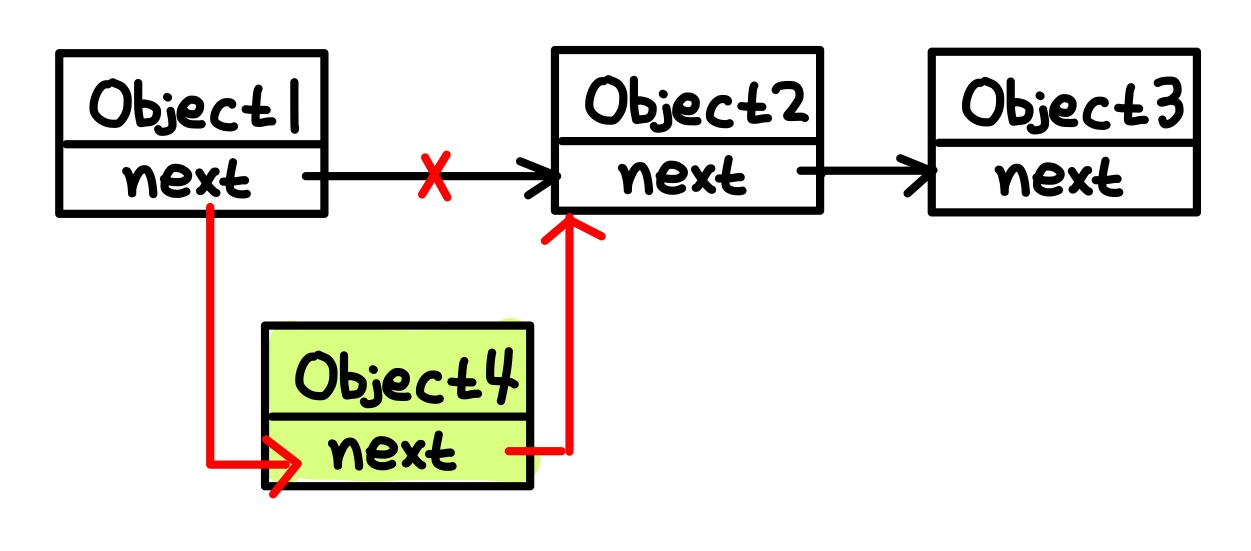
- 기존의 링크를 끊고(위 'x'), 추가할 위치의 이전 요소 tail(object 1)과 삽입할 자료(object 4)를 연결. 그 다음 삽입할 자료(object 4)의 tail과 그 다음 요소(object 2)를 연결.
제거하는 경우: 참고로 시간 복잡도 O(1). (1은 상수)
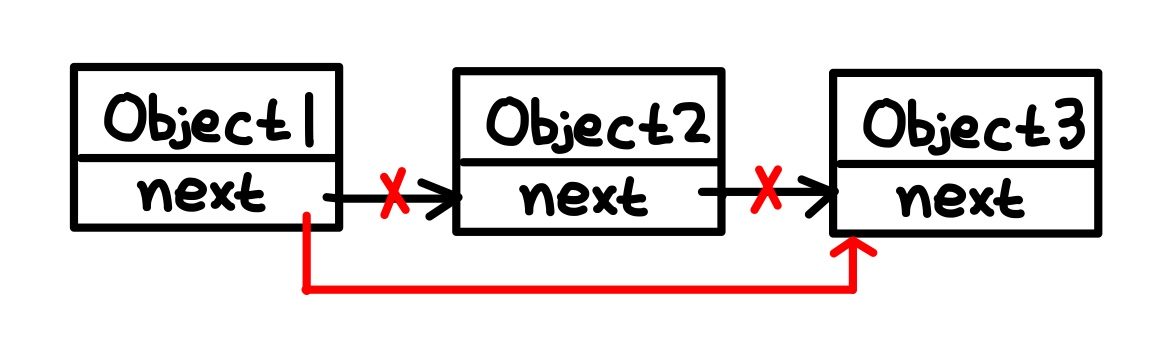
- 기존의 링크를 끊고(위 'x'), 삭제 대상 요소(object 2) 직전에 있는 요소(object 1)의 tail을 그 다음 대상 요소(object 3)에 연결하면 됨.
4. 공간복잡도
안좋음.
5. 시간복잡도
O(1) 또는 O(k).
- 추가/제거: 시간 복잡도 O(1) (1은 상수)
- k번째 원소에 접근: O(k)
#3. 스택
0. 용어
- top : 데이터가 입출력되는 위치
- bottom : top의 데이터가 0인 상태
- .push : 입력. top의 위치에 데이터를 입력하고, top을 증가시킨다.
- .pop : 출력 및 삭제. top을 감소시키고, 해당 위치의 데이터를 삭제한다.
1. 특징
정보를 접근할 때 제한이 있는 선형 데이터 구조이다.
어떤 제한? : 후입선출(Last In, First Out - aka LIFO)순이라는 점.
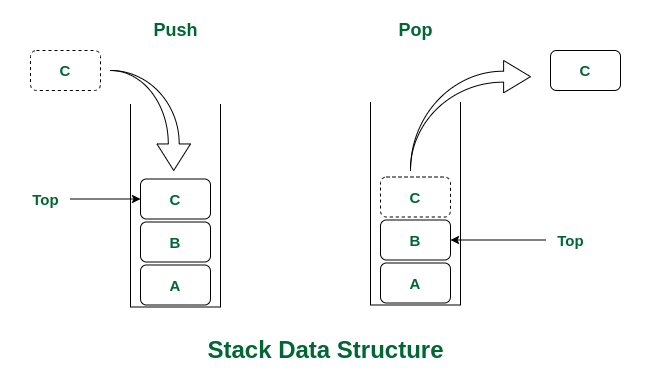
A를 꺼내려면 1) C를 먼저 꺼내고 2) B도 꺼낸 후 3) A를 꺼내야 한다! (그래서 선입후출 FILO: First In, Last Out 이라고도 할 수 있다.)
스택 입력/출력(삭제) : 아래 그림 참고하기.
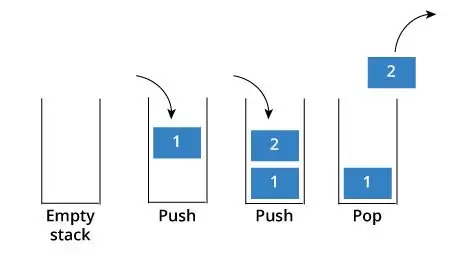
2. 장점
- 구조가 단순해 구현이 쉬움.
- 참고: JS내 스택 구현은 JS의 특성 덕분에 쉽지만, 다른 언어에서는 맨 위 값을 기억하고 있어야 사용 가능하다고 한다. - 읽기/쓰기(참조)에 좋음.
3. 단점
- 데이터의 크기를 미리 정해야 함.
- 저장 공간 낭비가 일어날 수 있음.
#4. 스택 오버플로우
콜스택에 데이터가 계속 입력될 경우 일어난다.
발생 원인:
- 함수에서 너무 큰 지역 변수를 선언하거나,
- 함수를 재귀로 무한정 호출.
