왜 데이터베이스인가?
우리는 실세계에서 은행, 항공사, 대학, 도서관, 판매, 신용 카드 등을 이용하면서 항상 수많은 데이터를 다룬다. 데이터베이스는 모든 응용 소프트웨어를 건설하는 데 필수적이다.
데이터베이스의 역사
-
1960년대
File Systems : OS가 관리 -
1960년대 후반~1970년대 : DBMS 등장
Hierarchical model: IMS(IBM), tree, 계층형, 1:M 관계
Network model: IDS(Bachman(GE)), graph, M:N 관계
Relational model: Codd (IBM, Turing Award), table(행/열)
-> 사용자 입장에서 프로그램 사용하기 쉬움 -
1980년대:
상업용 relational DBMS, SQL이 표준 DBMS 언어가 됨
Object-Oriented DB, Object-Relational DB 등장 -
1990 - 2000년대:
의사결정, Data Warehouse, and Data Mining, XML 등에 활용 -
최근:
NoSQL: 빅데이터
Database
Data
- 정형 Structured
- 반정형 Semi-structured (Web data: HTML, XML 등 tree 구조)
- 비정형 Unstructured (image, audio, text, sensor data)
Database
- 의미적으로 관련 있는 데이터의 집합
- 대용량
- 디스크에 상주 : 메인 메모리는 휘발되고 용량 작고 secondary storage는 너무 느림
- 상시 운영: Retrieve, Insert, Delete, Update
- 다중 사용자에 의해 공유
DBMS(Database Management System)
Database Management System (DBMS)
: 데이터베이스를 저장하고 관리하는 소프트웨어 패키지
ex) Oracle, MySQL (Oracle), DB2 (IBM), SQL Server (MS), Sybase (SAP)
Database System : Database + DBMS
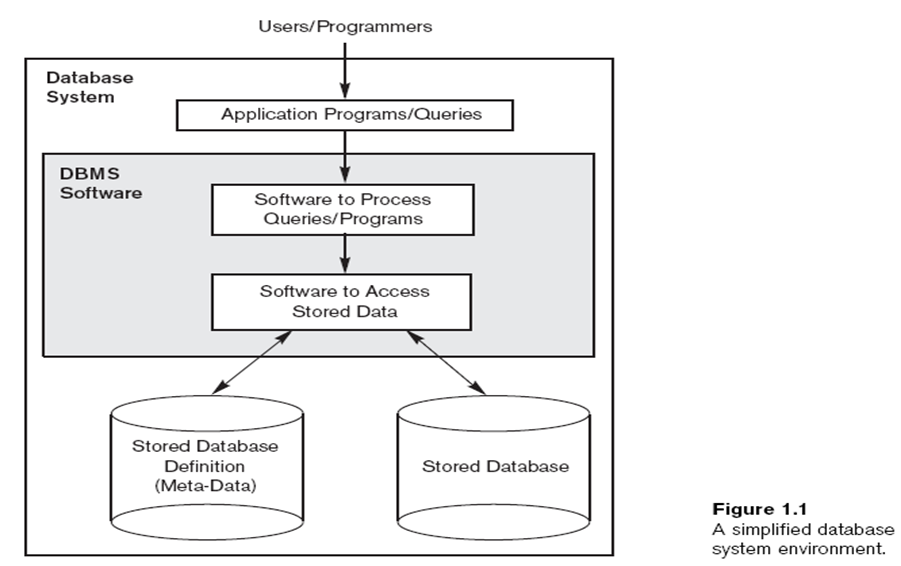
DBMS 이전: 파일시스템
- OS가 관리
- 전형적인 일반 파일들만 다룰 수 있었음
- 파일에 들어가는 레코드는 단순한 구조에 고정된 수의 필드만을 가짐
- 응용 프로그램에 파일 구조들이 내장됨
- 데이터를 검색하고 업데이트하기 위한 질의어가 없음
- 데이터를 관리하고 제어하는 특별한 프로그램이 없음
파일 시스템의 문제점
-
데이터 추상화 어려움
: 사용자들은 그들의 응용 프로그램에 데이터베이스의 물리 구조를 명시해야 함 -
데이터/프로그램 의존성 문제
: 사용자 응용 프로그램은 디스크에 저장된 데이터베이스의 물리적 구조에 의존적임 -
데이터 중복 문제
: 저장 공간 낭비, 데이터 불일치 -
데이터 무결성 어려움
무결성 제약(결함이 없도록 해 주는 제약 조건)을 따르고 확인해야 함
- Student IDs must be distinct.
- Bank account balance > $100.
- Every student takes 3 ~ 6 courses per semester.
- 동시 접근 어려움
동시에 데이터베이스에 접근하는 많은 사용자들을 허용해야 할 필요
통제되지 않는 접근은 불일치로 이끌 수 있음
동시성 제어 필수
- 데이터 회복 어려움
시스템 실패는 데이터베이스에 불일치를 남길 수 있으므로 정확한 상태로 회복해야 함
- 질의 처리 어려움
빠른 질의 처리를 위한 질의 최적화 필요
통제되지 않은 질의 처리는 심가하게 느린 반응 시간을 이끌 수 있음
- 데이터 보안 어려움
민감한 데이터에 접근하는 어떤 사용자들을 막을 필요
검색과 업데이트에 대한 접근 권한을 분류할 필요
DBMS가 제공하는 것
- 데이터 추상화 (Insulation of program and data)
- secondary storage에서 데이터베이스 생성하고 관리
- 데이터베이스 검색/업데이트를 위한 질의어
- 다양한 사용자들 사이에 데이터 공유
- 거래 제어: 동시 처리
- 권한 없는 데이터로의 접근 제한
- 시스템 실패로부터 회복
- 효율적 질의 처리를 위한 질의 최적화
- 다른 class의 사용자들에 다양한 인터페이스
데이터베이스 저장
- heap : random
- sequential : sorted
- indexing(b+ tree)
- hasing
용어
Database = Schema + Instance
Schema(Intension) : DB의 구조와 제약, DB 설계할 때 명시, 거의 안 바뀜
Instance(Extension) : DB의 내용, 동적으로 변함
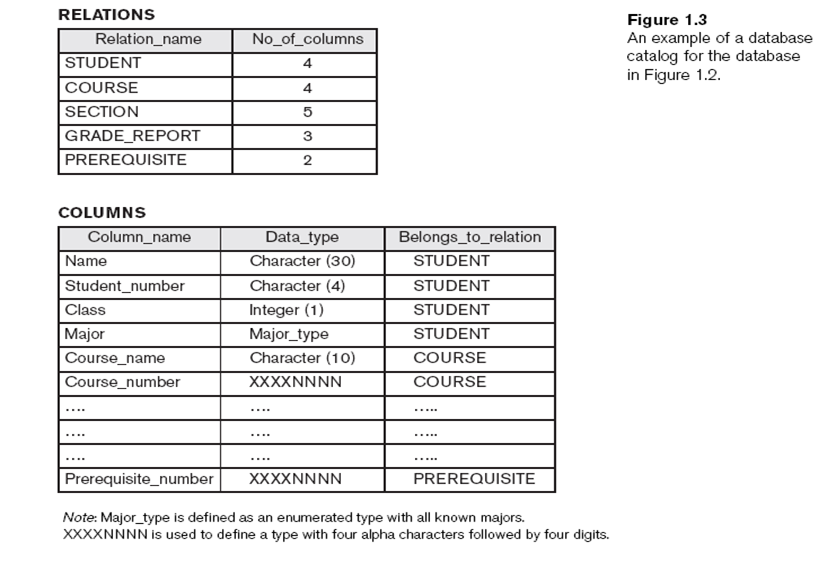
DBMS Catalog(Metadata, Data dictionary) : DB에 대한 설명, DBMS와 DB구조에 대한 정보가 필요한 DB 사용자들에 의해 참조됨
데이터베이스 질의어 SQL
-
DDL(Data Definition Language) : schema, table, views 정의
ex) CREATE, DROP, ALTER -
DML(Data Manipulation Language) : Retrieve and modify database instances
ex) SELECT, INSERT, DELETE, UPDATE
ANSI : 3-Schema Architecture
ANSI:미국 표준
DBMS의 데이터는 3레벨의 schema로 설명
-
Physical Schema
데이터베이스의 내부 저장 구조 설명(How data is stored physically?) -
Conceptual schema
사용자 그룹을 위한 데이터베이스의 개념 구조 설명(What is meaning of (whole) data?) -
External schemas (= Views)
특정 사용자의 필요에 따라 데이터베이스의 일부 설명(What is use of (partial) data?)
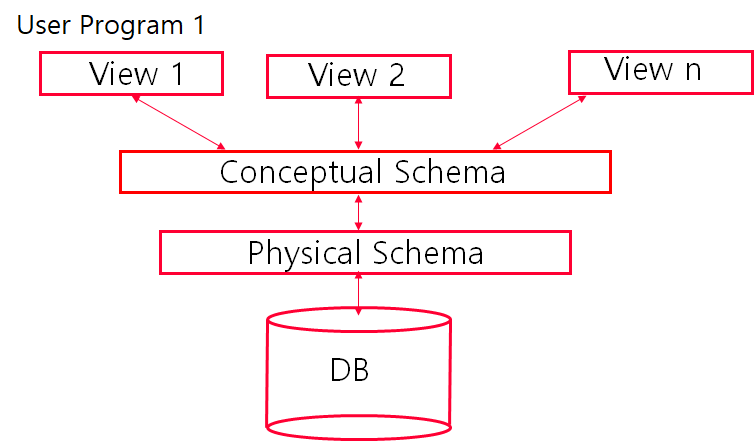
- 응용 프로그램과 물리적 데이터베이스를 분리
- 다중 사용자 view를 지원
- 높은 schema는 낮은 schema를 은폐
- 사용자의 요청과 데이터를 바꾸기 위해 schema level 간 맵핑 필요
데이터 독립성
- 논리적 독립성: external schema 안 바꾸고 conceptual schema 수정
- 물리적 독립성: conceptual schema 안 바꾸고 physical schema 수정
Class of Database Users
Database Administrator (DBA)
Database Designer
Application Programmer
Casual end user
Naïve end user