관계형 대수 : Relation database에 대한 질의(query) 처리 연산자의 모임
- Query는 relation에서 원하는 정보를 검색(retrieve)하는 조건을 명시하는 명령문 - (1 개 혹은 여러 개의) 입력 relation에 대해 질의 연산의 결과인 (1 개의) 출력 relation 생성
- 기본적으로 8 개의 검색 연산자들로 구성됨.
- 이 연산자들은 Query language인 SQL의 검색 연산 과정을 실현하는데 매우 중요함.
Relational algebra의 표현 방식
(1) 연산들을 nesting하여 한꺼번에 표현.
(2) 한번에 하나씩 연산들을 표현하면서 단계별로 표현.
(단, 이 경우 중간 결과를 저장하기 위한 relation 이름 지정 필요)
Basic Operations
SELECT σ: 단일 관계에서 주어진 조건을 만족하는 튜플들만 선택하여 출력, 수평 분할, 교환법칙
PROJECT π: 단일 관계에서 원하는 속성만 출력, 수직 분할, 중복 제거
만약 원하는 속성에 key가 포함된다면 결과값은 입력값과 길이 같음
UNION ∪: 합집합, 중복 제거
DIFFERENCE -: 차집합, 중복제거
INTERSECTION ∩: 교집합, 중복제거
위의 세 연산자 사용하려면 대상 관계들의 속성의 개수가 같아야 함
같은 위치에 대응하는 속서으이 도메인(자료형)이 같아야 함
속성의 이름은 서로 달라도 상관 없음, 이름이 다르면 첫 번재 관계의 이름 취함
CARTESIAN PRODUCT ×: 결과집합의 크기는 각 관계의 개수의 곱(mn)
결과집합의 속성의 개수는 (m+n)개
결과집합은 각 관계에 속한 튜플들을 모두 연결해 합침
-> join 설명하기 위해 존재함
JOIN ⋈: 결과집합의 속성의 개수는 (m+n)개
결과집합은 각 관계에 속한 튜플 중 조건식을 만족하는 것들만 연결해 합침
join condition은 A op B로 표현하는데,
A와 B는 각각의 관계에 속하고, 서로 같은 도메인을 가짐
join attribute가 null이거나 join condition이 false로 평가된 튜플들은 결과값에 표시 안 함
Equi-Join:
condition에 = 포함한 join
관계들 사이에 관계를 구현하는 등(Pk/FK 참조) 아주 널리 사용됨
결과값에 같은 값을 가진 튜플 쌍을 가지므로 둘 중에 하나 제거해야 함
이 경우 Natural Join(*) 이 생성되어 결과값에서 두 번째 속성 제거함
Natural Join에서 이름이 다른 경우 첫 번째 관계 속성의 이름 채택
Self-Join
Condition(Theta)-Join: condition에 = 말고 다른 연산자 포함한 join
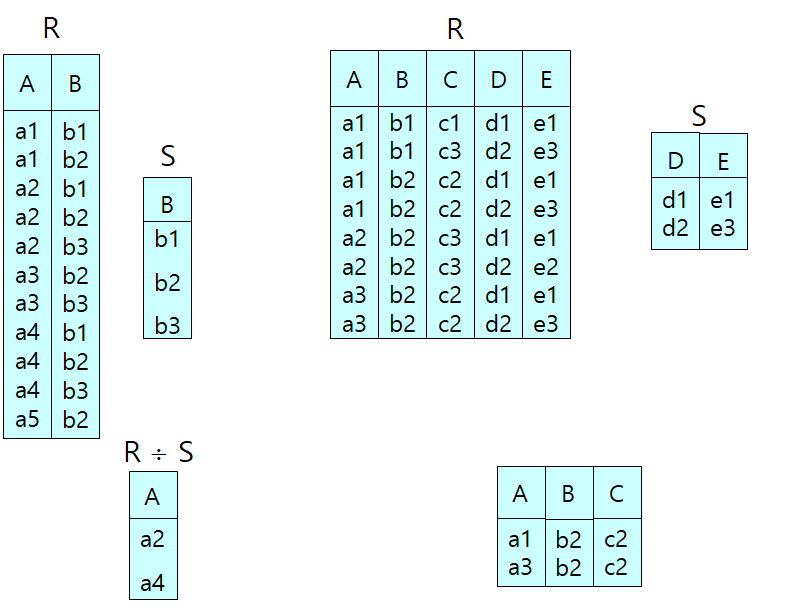
DIVISION ÷: 공통으로 있는 속성을 제외한 속성들에 대해 나누는 관계의 속성값을 모두 포함하는 값만 출력
"모든"이라는 말이 들어갈 때만 사용되는 특별한 연산자

Additional Operations
OUTER JOIN ⟕ : join할 때, 조건식에 맞지 않거나 null인 튜플들은 유실된다. 이 튜플들을 유지하기 위한 것이 outer join
- left outer join : 왼쪽 관계의 모든 튜플 유지, 조건에 만족하는 S의 튜플이 없으면 S의 튜플들은 결과값에 null로 채워짐
- right outer join : 오른쪽 관계의 모든 튜플 유지
- full outer join : 모든 튜플 유지
OUTER UNION ∪ : 두 개의 관계가 호환되지 않을 때(구조가 다를 때) 사용된다. 즉 부분적으로 호환되는 의 합집합을 취한다. 어느 관계에도 매칭되지 않는 튜플들은 null 값으로 채워진다.
Aggregate Functions 집계 함수
-
COUNT : count the number of values
-
SUM : total sum of values
-
AVG : average of values
-
MAX : maximum of values
-
MIN : minimum of values
-
GROUPING : 특정 속성값을 기반으로 튜플들을 그룹핑
ℱ (R) where is a list of ()
Recursive Query
: 같은 관계의 튜플들 간의 재귀적 관계에 사용됨
The SQL3 standard includes syntax for recursive closure.
