이 글은 한빛미디어 출판사의 '혼자 공부하는 컴퓨터 구조+운영체제(강민철 저)'를 정리한 내용입니다.
CPU는 프로그램 실행 과정에서 메모리에 빈번하게 접근하게 된다. 하지만 CPU가 메모리에 접근하는 시간은 CPU의 연산 속도보다 느리다. 이를 극복하기 위한 저장 장치가 바로 캐시 메모리이다.
캐시 메모리를 이해하려면 먼저 저장 장치 계층 구조를 알아야 한다.
저장 장치 계층 구조(Memory hierachy)
저장 장치는 일반적으로
- CPU와 가까운 저장 장치는 빠르고, 멀리 있는 저장 장치는 느리다
- 속도가 빠른 저장 장치는 저장 용량이 작고, 가격이 비싸다
위의 명제를 따른다. 따라서 속도가 빠르고, 저장 용량이 큰 저장 장치는 양립하기 어렵다.
예를 들어 CPU의 내의 레지스터는 CPU와 가장 가깝지만 용량이 메모리보다 작고, 가격이 비싸다. 반대로 USB 메모리는 메모리에 비해 CPU와 멀지만 용량이 크다.
컴퓨터가 사용하는 저장 장치는 CPU에 얼마나 가까운가를 계층적으로 나타낼 수 있다. 이를 저장 장치 계층 구조라고 한다.
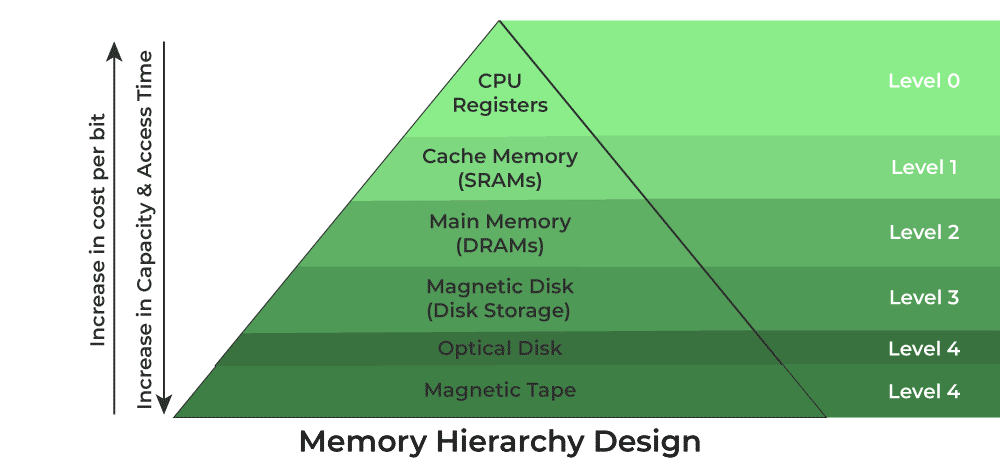
그림 출처 - https://www.geeksforgeeks.org/memory-hierarchy-design-and-its-characteristics/
CPU에 가까울수록 빠르고, 용량이 작고, 비싸다.
아래 계층으로 내려갈 수록 느리고, 용량이 크고, 저렴하다.
캐시 메모리
CPU와 메모리 사이에 위치하고, 레지스터보다 용량이 크고 메모리보다 빠른 SRAM 기반의 저장 장치이다.
CPU의 연산 속도와 메모리 접근 속도의 차이를 조금이나마 줄이기 위해 탄생. CPU가 사용할 일부 데이터를 미리 캐시 메모리로 가지고 와서 활용하는 것.
비유하자면 캐시 메모리는 집과 가까운 편의점, 메모리는 멀리 있는 대형 마트이다. 편의점에 필요한 물건이 있다면 대형 마트까지 갈 필요가 없다.
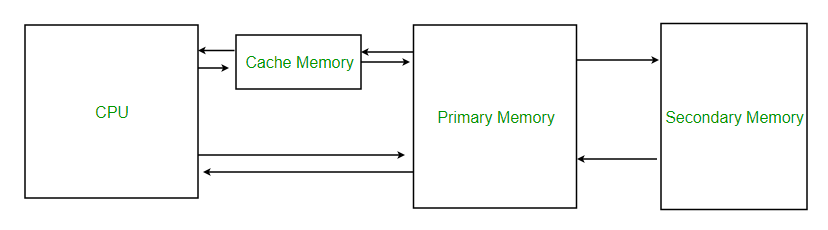
그림 출처 - https://www.geeksforgeeks.org/cache-memory-in-computer-organization/
컴퓨터 내부에는 여러 개의 캐시 메모리가 있다. 이 캐시 메모리들은 CPU와 가까운 순서대로 L1 캐시, L2 캐시, L3 캐시라고 부른다. CPU와 가장 가까운 캐시 메모리를 L1 캐시, 그 다음 가까운 캐시 메모리는 L2 캐시, 그 다음 가까운 캐시 메모리는 L3 캐시이다.
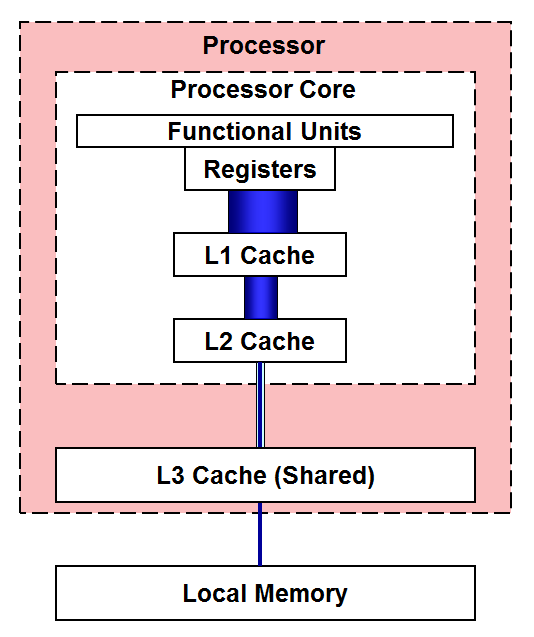
메모리 계층 구조대로 캐시 메모리의 용량은 L3가 제일 크고, 속도는 L1이 제일 빠르다. CPU가 메모리 내 데이터가 필요하다고 판단하면 우선 L1 캐시부터 살펴보고 없다면 L2, L3 순으로 검색한다.
멀티 코어 프로세서의 경우 L1 캐시, L2 캐시는 코어마다 고유한 캐시 메모리로 할당되고, L3 캐시는 여러 코어가 공유하는 형태로 사용한다.
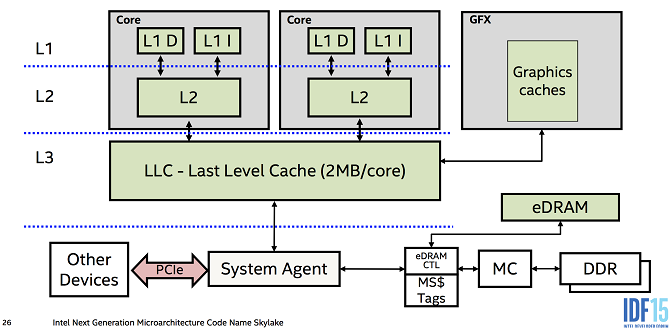
그림 출처 - https://quasarzone.com/bbs/qn_hardware/views/818208
분리형 캐시
코어와 가장 가까운 L1 캐시는 조금이라도 접근 속도를 빠르게 하기 위해 명령어만을 저장하는 L1l 캐시와 데이터만을 저장하는 L1D 캐시로 분리하는 경우도 있다.
참조 지역성 원리
캐시 메모리는 메모리보다 용량이 작기 때문에 메모리의 일부를 복사하여 저장한다. 그렇다면 캐시 메모리는 어떤 데이터를 복사해 저장해야 하는 것일까요?
캐시 메모리는 CPU가 사용할 법한 대상을 예측하여 저장한다. 이 때 예측한 데이터가 실제로 CPU에서 활용될 경우를 캐시 히트(cache hit)라고 한다.
반대로 예측이 틀린 경우는 캐시 미스(cache miss)라고 한다. 캐시 미스가 발생하면 CPU가 필요한 데이터를 메모리에서 직접 가져와야 하기 때문에 캐시 메모리의 이점을 활용할 수 없다. 캐시 미스가 자주 발생하면 성능이 떨어지게 된다.
참고로 캐시 적중률은 다음과 같이 계산한다.
(캐시 히트 횟수) / (캐시 히트 횟수 + 캐시 미스 횟수)그렇다면 CPU가 사용할 법한 데이터는 어떻게 알 수 있을까?
캐시 메모리는 참조 지역성의 원리에 따라 메모리에서 가져올 데이터를 결정한다.
참조 지역성의 원리
- CPU는 최근에 접근했던 메모리 공간에 다시 접근하려는 경향이 있다
- CPU는 접근한 메모리 공간 근처를 접근하려는 경향이 있다
1) 최근에 접근했던 메모리 공간에 다시 접근하려는 경향?
== CPU는 변수가 저장된 메모리 공간을 언제든 다시 참조할 수 있다.
변수에 값을 할당하고 나면 이 변수에 언제든 다시 접근할 수 있고, 일반적으로 프로그램이 실행되는 동안 여러번 사용된다.
이처럼 '최근에 접근했던 메모리 공간에 다시 접근하려는 경향'을 시간 지역성(temporary locality)라고 한다.
2) 접근한 메모리 공간 근처를 접근하려는 경향?
프로그램은 서로 관련 있는 데이터끼리 모여서 저장된다. 워드 프로세서 프로그램은 워드 프로세서 관련 데이터들이 모여 저장이 되는 것처럼.
그리고 하나의 프로그램 내에서도 관련 있는 데이터들은 모여서 저장이 된다. 워드 프로세서 프로그램에서 자동 기능은 이 기능과 관련한 데이터가 모여 저장되는 것처럼.
CPU가 워드 프로그램을 실행할 때에는 이 프로그램이 모여 있는 공간 근처를 집중적으로 접근할 것이다. 이렇게 '접근한 메모리 공간 근처를 접근하려는 경향'을 공간 지역성(spatial locality)라고 한다.
캐시 메모리는 이런 원리를 바탕으로 CPU가 사용할 법한 데이터를 예측한다.
내용 출처 - '혼자 공부하는 컴퓨터 구조+운영체제(강민철 저, 한빛미디어)
