0. 공부 배경
LLM을 구동하기 위해 엔진을 찾아보니 생각보다 많은 종류가 있다
대충 둘러본 내용은 아래와 같은데..
이 외에도 TensorRT-LLM 등 다양한 엔진이 있는 듯 하다
모든 기술을 다 이해할 필요는 없지만, 자신에게 필요한 지식은 공부할 필요가 있다고 생각한다
예를 들어 내가 여러 사용자가 물리는 서비스에 LLM을 서빙해야한다면, 병렬처리가 장점인 vLLM을 고려해볼 것이다.
다양한 엔진에서 Paged Attention이니 Flash Attention이니 다양한 기법들이 적용되어가고 있는데
원리를 이해하고 있어야 시스템에서 효과적일지 알 수 있을 것 같아서 차근차근 공부하고자 한다
1. Attention
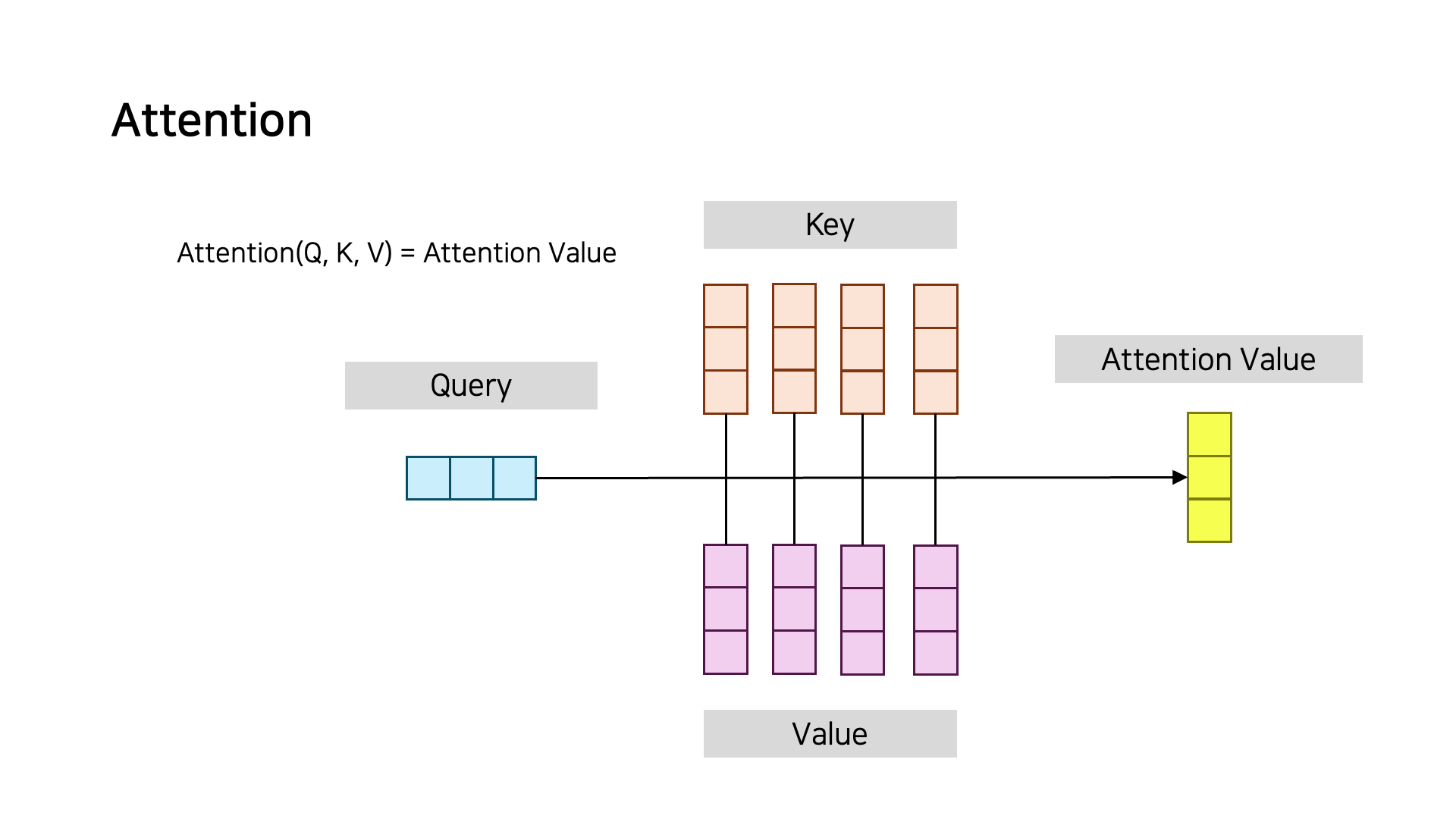 Attention 메커니즘은 기본적으로 Q, K, V로 Attention Value를 구하게 된다
Attention 메커니즘은 기본적으로 Q, K, V로 Attention Value를 구하게 된다
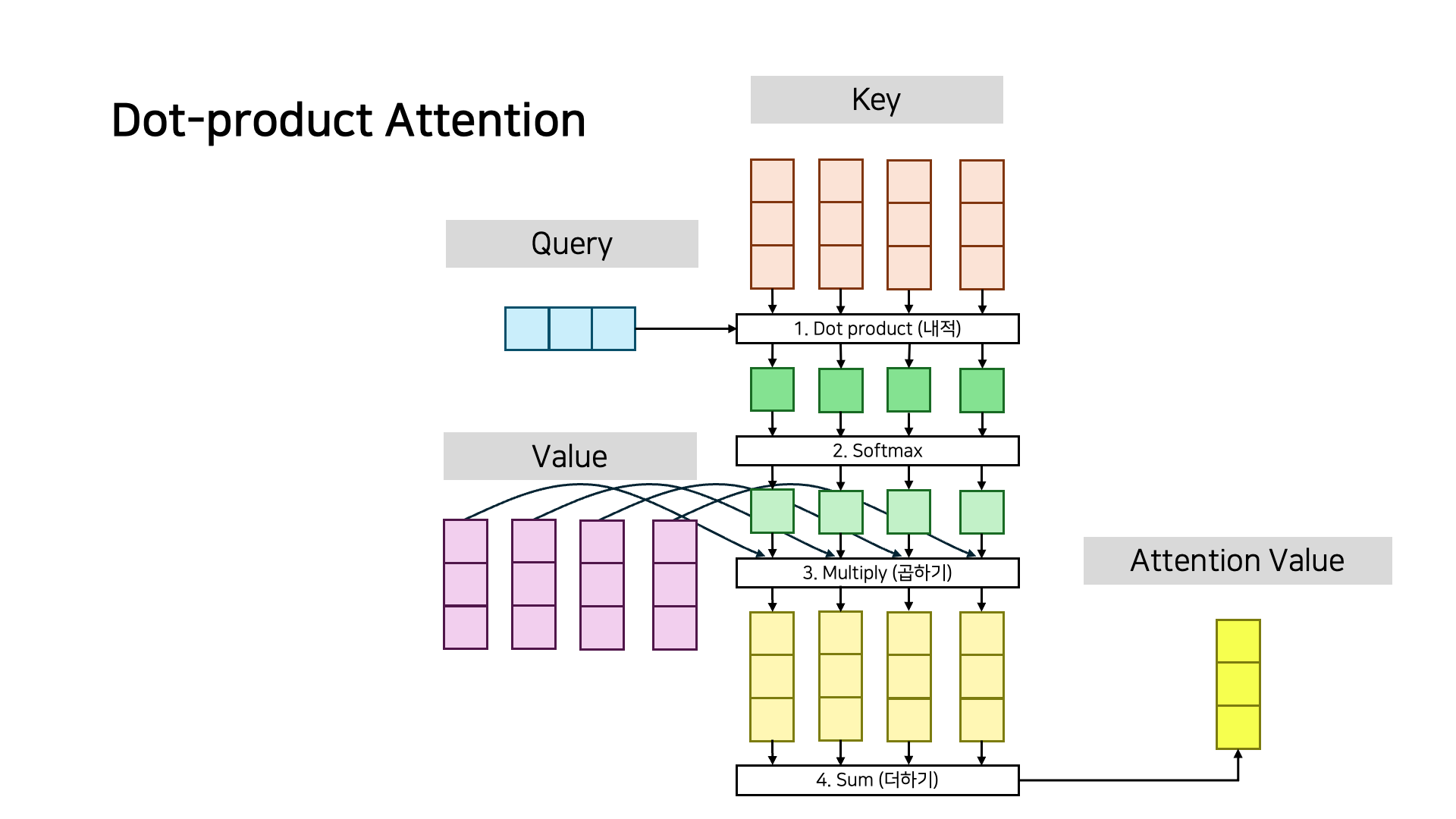 예를 들어 Dot-product Attention은 위와 같이 연산되는데
예를 들어 Dot-product Attention은 위와 같이 연산되는데
실제로는 쿼리가 여러개이므로 행렬 연산이 이루어진다
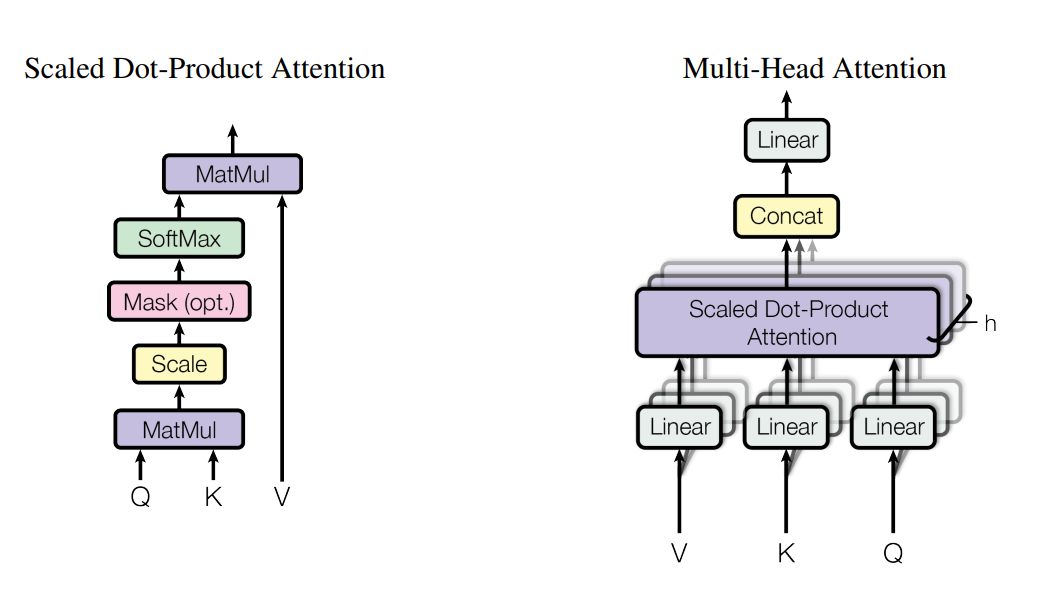 Transformer 모델에서는 Scale 과정이 추가된 Scaled Dot-Product Attention을
Transformer 모델에서는 Scale 과정이 추가된 Scaled Dot-Product Attention을
여러개 겹쳐놓은 Multi-Head Attention을 사용한다고 한다
아무튼 Attention(Q, K, V) 함수는 Q, K, V로 열심히 행렬 연산을 수행하는 것이다.
Attention 메커니즘 이해에 도움이 될만한 자료들
2. Flash Attention
- We propose FlashAttention, a new attention algorithm that computes exact attention with far fewer memory accesses.
- 우리는 FlashAttention이라는 새로운 Attention 알고리즘을 제안합니다.
- 이 알고리즘은 훨씬 적은 메모리 접근으로 정확한 Attention을 계산합니다.
- Even with the increased FLOPs due to recomputation, our algorithm both runs faster and uses less memory than standard attention, thanks to the massively reduced amount of HBM access
- 재계산으로 인해 FLOP(부동소수점 연산 수)가 증가했음에도 불구하고, 우리의 알고리즘은 Standard Attention보다 빠르게 실행되고 메모리를 적게 사용합니다.
- 이는 HBM 접근을 크게 줄였기 때문입니다.
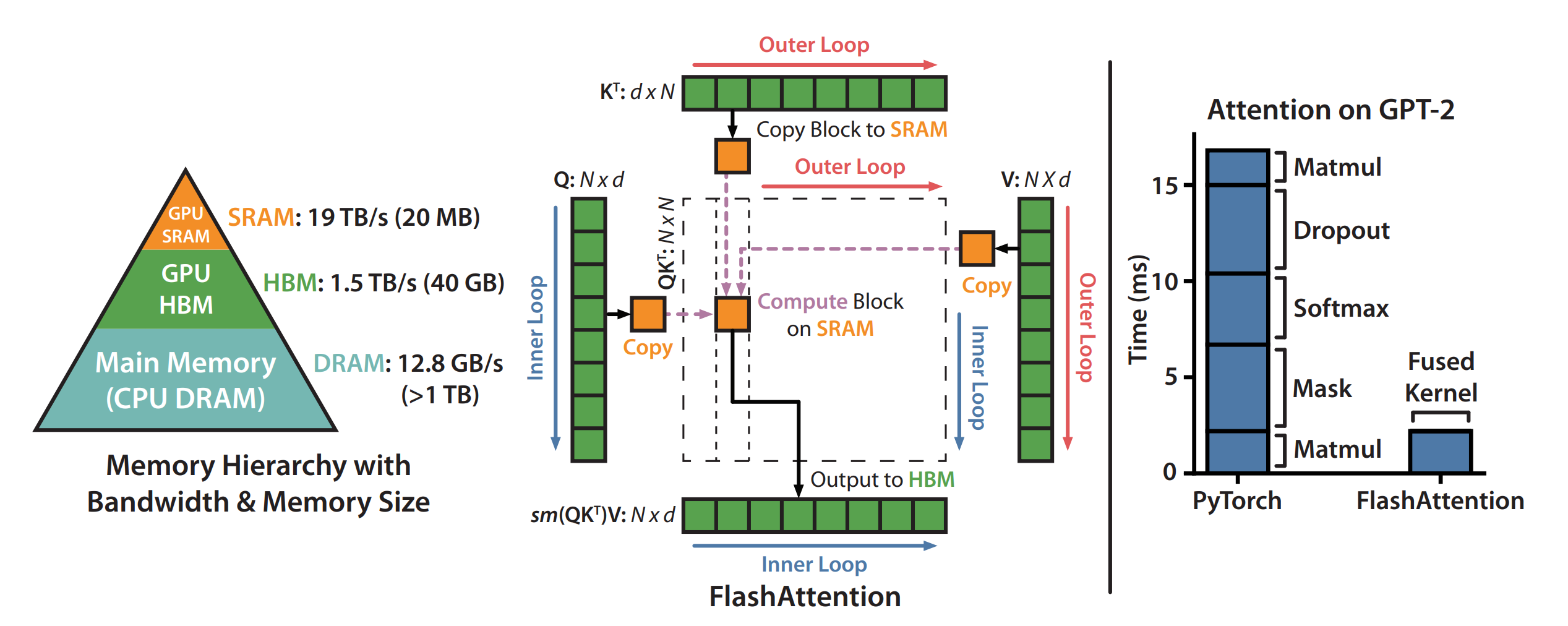
논문에 따르면 HBM 접근 빈도를 줄여서, 연산 횟수는 늘었음에도 빠르게 만들었다고 한다.
의사코드
Require: Matrices Q,K,V∈RN×d in HBM, on-chip SRAM of size M.
N:입력 토큰 수, d:임베딩 차원 수
1. 블록 크기를 SRAM이 허용하는 범위에서 정의 : Bc=⌈4dM⌉,Br=min(⌈4dM⌉,d).
만약 SRAM이 허용해서, Br=d이 된다면 Bc:한번에 처리가능한 토큰 수
2. Output배열 초기화 O=(0)N×d∈RN×d,ℓ=(0)N∈RN,m=(−∞)N∈RN in HBM.
3. Q를 Tr=⌈BrN⌉개의 블록 Q1,…,QTr로 나누고, K와 V를 Tc=⌈BcN⌉개의 블록 K1,…,KTc 및 V1,…,VTc,로 나눔. 각 블록 크기 Bc×d.
4. O를 Tr개의 블록 Oi,…,OTr로 나누고, ℓ를 Tr개의 블록 ℓi,…,ℓTr로 나누고, m을 Tr개의 블록 m1,…,mTr로 나눔.
5. for 1≤j≤Tc do
6. HBM→SRAM:Kj,Vj를 로드.
7. for 1≤i≤Tr do
8. HBM→SRAM:Qi,Oi,ℓi,mi를 로드.
9. SRAM에서 Sij=QiKjT∈RBr×Bc 계산.
10. SRAM에서 m~ij=rowmax(Sij)∈RBr,P~ij=exp(Sij−m~ij)∈RBr×Bc (포인트별),ℓ~ij=rowsum(P~ij)∈RBr 계산.
11. SRAM에서 mnewi=max(mi,m~ij)∈RBr,ℓnewi=exp(mi−mnewi)ℓi+exp(m~ij−mnewi)ℓ~ij∈RBr 계산.
12. HBM에 Oi←diag(ℓnewi)−1(diag(ℓi)exp(mi−mnewi)Oi+exp(m~ij−mnewi)P~ijVj) 쓰기.
13. HBM에 ℓi←ℓnewi,mi←mnewi 쓰기.
14. end for
15. end for
16. O 반환.
정리하면, 블록 사이즈를 잘 정의해서 블록 개수(Tr)만큼 HBM에 접근이 일어나게 했는데
- HBM→SRAM:Qi,Oi,ℓi,mi를 Load
- HBM←SRAM:Oi,ℓnewi,mnewi를 Write
이는 Θ(MN2d2)으로 기존 Attention 메커니즘의 Θ(Nd+N2)보다 크게 줄었다고 한다
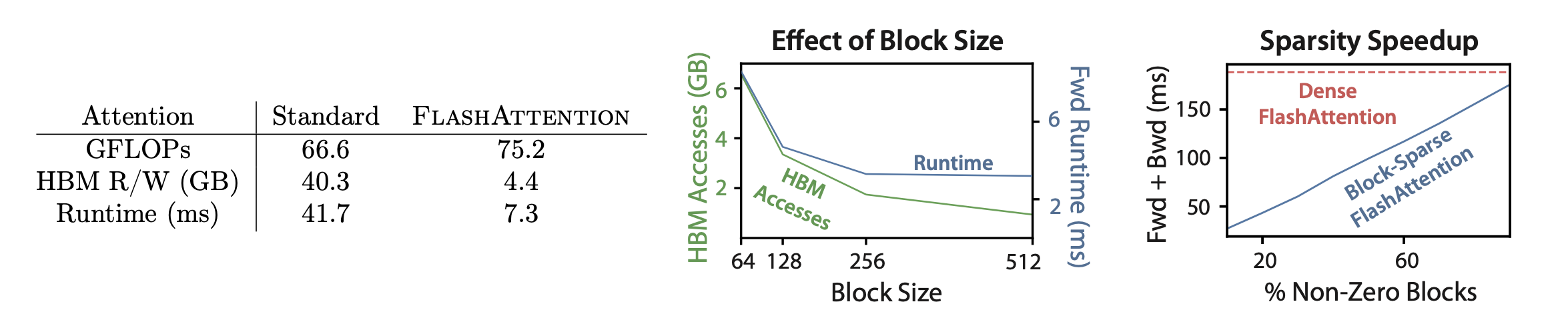
For typical values of d (64-128) and M (around 100KB), d2 is many times smaller than M, and thus FlashAttention requires many times fewer HBM accesses than standard implementation. This leads to both faster execution and lower memory footprint, which we validate in Section 4.3.
일반적인 d 값(64-128)과 M 값(약 100KB)에 대해 d2는 M보다 훨씬 작습니다. 따라서 FlashAttention은 표준 구현에 비해 HBM 접근 횟수가 훨씬 적습니다. 이는 더 빠른 실행과 더 적은 메모리 사용을 초래하며, 이를 4.3절에서 검증합니다.
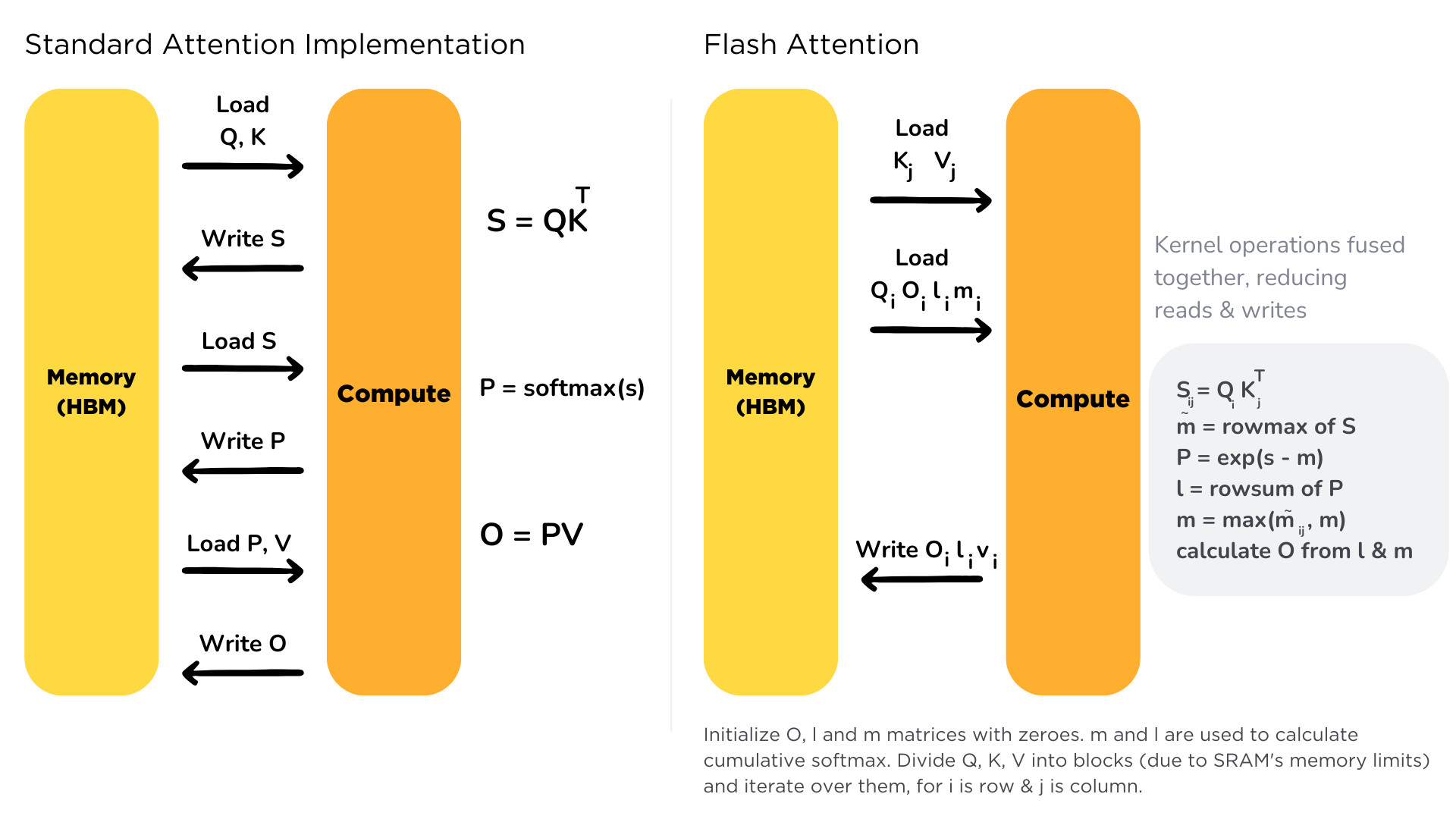
출처 : HuggingFace
그림으로 보면 더 이해하기 쉬운데, 연산량이 늘더라도
HBM의 접근을 최대한 줄여서 시간을 줄였음을 이해할 수 있다.
하드웨어에 따라 성능 변화가 다를 듯하다 (SRAM 크기, 연산 성능 등)
