
5.1 Basic Concepts
-
To maximize CPU utilization, we need multiprogramming.
-
다중 프로그래밍의 목적은 CPU 이용률을 최대화하기 위해 항상 실행 중인 프로세스를 가지게 하는데 있다.
-
CPU 이용률을 최대화 하는 것은 다중 프로세서 운영체제 설계의 핵심
어떤 프로세스가 대기해야 할 경우, 운영체제는 CPU를 그 프로세스로부터 회수해 다른 프로세스에 할당한다.
(+) 멀티 프로그래밍 : (CPU 효율성 극대화)
- 멀티 프로그래밍은 하나의 프로세서가 하나의 프로세스를 수행하는 동안 다른 프로세스에 접근할 수 있도록 하는 방법을 의미한다.
- 초기 컴퓨터는 하나의 프로세서가 하나의 프로세스만 처리할 수 있도록 설계되었다. 하지만 하나의 프로세스를 처리하는 과정에서 프로세서의 처리 속도와 입출력 속도 간의 차이로 인해 입출력 처 리가 완료될 때까지 기다리는 비효율적인 상황이 발생하게 된다.
- 멀티 프로그래밍은 입출력이 완료될 때까지 기다리는 시간을 버리지 말고 다른 프로세스를 처리할 수 있도록 해주는 것이다.
-
But, with a single CPU core, only one process can run at a time.
-
그러나 하나의 CPU 코어로 한 번에 하나의 프로세스만 실행할 수 있습니다.
-
This requires CPU scheduling.
-
이 경우 CPU 스케줄링이 필요
-
어떤 자원을 누가 언제 어떤 방식으로 사용할지를 결정해주는 것 -> 자원의 효율적인 관리
CPU - I/O 버스트 사이클 (CPU - I/O Burst Cycle)
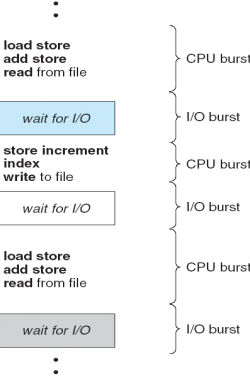
-
(+) 프로세스의 실행은 CPU Burst로 시작된다. 뒤이어 I/O Burst가 발생하고, 그 뒤를 이어 또 다른 CPU Burst가 발생하며, 이어 또 다른 I/O Burst 등등으로 진행된다. 결국 아래의 그림처럼 마지막 CPU Burst는 실행을 종료하기 위한 시스템 요청과 함께 끝난다
-
(+) CPU burst
-
CPU 버스트는 사용자 프로그램이 CPU를 직접 가지고 빠른 명령을 수행하는 단계이다. 이 단계에서 사용자 프로그램은 CPU 내에서 일어나는 명령 (ex. Add)이나 메모리(ex. Store, Load)에 접근하는 일반 명령을 사용할 수 있다.
-
(+) I/O burst
-
I/O 버스트는 커널에 의해 입출력 작업을 진행하는 비교적 느린 단계이다. 이 단계에서는 모든 입출력 명령을 특권 명령으로 규정하여 사용자 프로그램이 직접 수행할 수 없도록 하고, 대신 운영체제를 통해 서비스를 대행하도록 한다.
-
(+) 이처럼 사용자 프로그램이 수행되는 과정은 CPU 작업과 I/O 작업의 반복으로 구성된다.
- Process execution consists of a cycle of CPU execution and I/O wait (CPU-I/O burst cycle) and alternates this cycle.
- 프로세스 실행은 CPU 실행 및 I/O 대기(CPU-I/O 버스트 주기) 사이클로 구성
- 이 사이클을 번갈아 수행합니다.
- CPU burst distribution is generally characterized as exponential, with many short CPU bursts, and a few long CPU bursts.
- CPU 버스트 분포는 일반적으로 expensential로 특징지어지며, CPU 버스트가 짧고 CPU 버스트가 길기도 합니다.
< Histogram of CPU-burst Times >
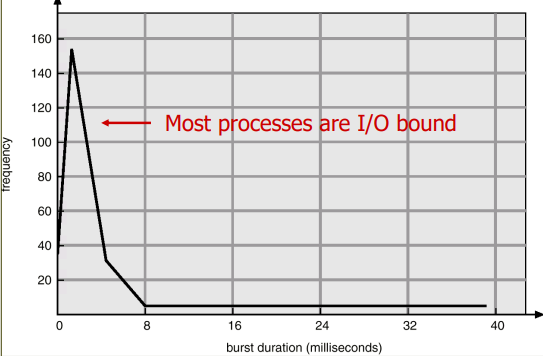
- I/O bound process typically has many short CPU bursts, while a CPU bound process has a few long CPU bursts.
- 입출력 바운드 프로세스 : 일반적으로 짧은 CPU 버스트를 많이 발생
- CPU 바운드 프로세스 : 긴 CPU 버스트를 조금 발생시킨다.
=> 프로그램이 수행되는 구조를 보면 I/O 바운드 프로세스는 짧은 CPU 버스트를 많이 가지고 있는 반면, CPU 바운드 프로세스는 소수의 긴 CPU 버스트로 구성된다는 것을 알 수 있다.
-
(+) CPU bound process와 I/O bound process
각 프로그램마다 CPU 버스트와 I/O 버스트가 차지하는 비율이 균일하지 않다. 어떤 프로세스는 I/O 버스트가 빈번해 CPU 버스트가 매우 짧은 반면, 어떤 프로세스는 I/O를 거의 하지 않아 CPU 버스트가 매우 길게 나타난다. 이와 같은 기준에서 프로세스를 크게 I/O 바운드 프로세스와 CPU 바운드 프로세스로 나눌 수 있다. -
(+) I/O 바운드 프로세스
I/O 요청이 빈번해 CPU 버스트가 짧게 나타나는 프로세스를 말한다. 주로 사용자로부터 인터랙션을 계속 받아가며 프로그램을 수행하는 대화형 프로그램이 해당된다. -
(+) CPU 바운드 프로세스
I/O 작업을 거의 수행하지 않아 CPU 버스트가 길게 나타나는 프로세스를 말한다. 주로 프로세스 수행의 상당 시간을 입출력 작업 없이 CPU 작업에 소모하는 계산 위주의 프로그램이 해당된다.
CPU 스케줄러(CPU Scheduler)
(+)
- CPU가 유휴 상태가 될 때마다, 운영체제는 Ready Queue에 있는 프로세스 중에서 하나를 선택해 실행해야 한다.
- 선택 절차는 CPU 스케줄러(CPU Scheduler)에 의해 수행
(+)
- 프로세스의 CPU 버스트를 분석해보면 대부분의 경우 짧은 CPU 버스트를 가지며, 극히 일부분만 긴 CPU 버스트를 갖는다.
=> 이는 다시 말해서 CPU를 한 번에 오래 사용하기보다는 잠깐 사용하고 I/O 작업을 수행하는 프로세스가 많다는 것이다. - 즉 대화형 작업을 많이 수행해야 하는데, 사용자에 대한 빠른 응답을 위해서는 해당 프로세스에게 우선적으로 CPU를 할당하는 것이 바람직하다.
- 만약 CPU 바운드 프로세스에게 먼저 CPU를 할당한다면 그 프로세스가 CPU를 다 사용할 때까지 수많은 I/O 바운드 프로세스는 기다려야할 것이다. 이러한 이유로 CPU 스케줄링이 필요해진 것 !
- (1) selects a process to run among the processes in memory that are ready to execute
- 실행할 준비가 된 메모리의 프로세스 중에서 실행할 프로세스를 제외
- (2) allocates the CPU to one of them.
- CPU를 둘 중 하나에 할당
=> CPU 스케줄러는 실행 준비가 되어 있는 메모리 내의 프로세스 중에서 선택해, 이들 중 하나에게 CPU를 할당
선점 및 비선점 스케줄링 (Preemptive and Nonpreemptive Scheduling)
-
CPU scheduling decisions may take place when a process
-
CPU 스케줄링의 결정은 다음의 네 가지 상황에서 발생할 수 있다.
-
- Switches from running to waiting state (i.e., when an I/O is initiated).
: 한 프로세스가 실행 상태에서 대기 상태로 전환될 때 (I/O 발생)
- Switches from running to waiting state (i.e., when an I/O is initiated).
-
- Switches from running to ready state (i.e., when an interrupt occurs).
: 프로세스가 실행 상태에서 준비 완료 상태로 전환될 때 (인터럽트 발생)
- Switches from running to ready state (i.e., when an interrupt occurs).
-
- Switches from waiting to ready (i.e., when an I/O completes).
: 프로세스가 대기 상태에서 준비 완료 상태로 전환될 때 (I/O 종료)
- Switches from waiting to ready (i.e., when an I/O completes).
-
- Terminates. 프로세스가 종료할 때
-
When scheduling takes place only under 1 and 4, we say that the scheduling scheme is non-preemptive or cooperative.
-
스케줄링이 1 및 4에서만 수행되는 경우 스케줄링 체계가 비선제적 또는 협력적이라구 함
-
비선점 스케줄링(nonpreemptive)하에서는, 일단 CPU가 한 프로세스에 할당되면 프로세스가 종료하든지, 또는 대기 상태로 전환해 CPU를 방출할 때까지 점유한다. (1, 4번)
- All other scheduling is preemptive. -> affect OS design !
- Access to shared data, preemption while in kernel mode, etc.
- Virtually all modern Oss use preemptive scheduling algorithms.
- 선점 스케줄링(preemptive)은 시분할 시스템에서 타임 슬라이스가 소진되었거나, 인터럽트나 시스템 호출 종료시에 더 높은 우선 순위 프로세스가 발생 되었음을 알았을 때, 현 실행 프로세스로부터 강제로 CPU를 회수하는 것을 말한다. (2, 3번)
디스패처 (Dispatcher)
- CPU를 누구한테 누구한테 줄 지 결정했으면 해당 프로세스에게 넘겨야 하는데, 디스패처가 이 역할을 수행
- 디스패처(Dispatcher)는 CPU 코어의 제어를 CPU 스케줄러가 선택한 프로세스에 전해주는 모듈
- Dispatcher gives control of the CPU to the process selected by the scheduler
< 디스패처의 수행 작업 >
- ① - switching context
- 한 프로세스에서 다른 프로세스로 문맥을 교환하는 일
- ② - switching to user mode
- 사용자 모드로 전환하는 일
- ③ - jumping to the proper location in the user program to restart that program
- 사용자 프로그램의 적절한 위치로 이동하여 해당 프로그램을 다시 시작
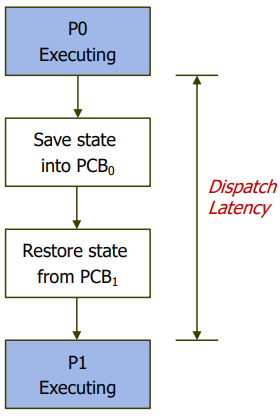
- Dispatch latency
: time it takes for the dispatcher to stop one process and start another running.
: 디스패처가 하나의 프로세스를 정지하고 다른 프로세스의 수행을 시작하는데까지 소요되는 시간- Should be as fast as possible !
5.2 스케줄링 기준 (Scheduling Criteria)
1. CPU utilization CPU 이용률(Utilization)
: keep the CPU as busy as possible.
어느 기간 동안 또는 특정 SNAPSHOT에서의 CPU의 이용률
2. Throughput : 처리량(Throughput)
:# of processes that complete their execution per time unit.
- 단위 시간당 완료된 프로세스의 개수
3. Turnaround time 총처리 시간
- amount of time to execute a particular process (from submission to completion).
This is the sum of the periods spent waiting in the ready queue, executing on the CPU, and doing I/O.
특정 프로세스를 실행하는 데 걸리는 시간입니다(제출에서 완료까지).
준비 대기열에서 대기하고 CPU에서 실행하고 I/O를 수행하는 데 소요된 시간의 합계입니다.
4. Waiting time 대기 시간
- amount of time a process has been waiting in the ready queue.
대기 시간 프로세스가 준비 대기열에서 대기하는 시간.
5. Response time : 응답 시간
- amount of time it takes from when a request was submitted until the first response is produced, not output (for time-sharing environment).
응답 시간 (시간 공유 환경의 경우)이 아니라 요청이 제출된 시점부터 첫 번째 응답이 생성될 때까지 걸리는 시간
Optimization Criteria
< average values are optimized >
- CPU Utilization, Throughput을 최대화
- Turaround Time, Waiting Time, Response Time을 최소화
-
However, under some circumstances, optimizing the minimum and maximum values is preferred.
-
그러나 일부 상황에서는 최소값과 최대값을 최적화하는 것이 선호
-
For interactive systems, it is more important to minimize the variance in the response time than to minimize the average response time.
-
대화형 시스템의 경우 평균 반응 시간을 최소화하는 것보다 반응 시간의 분산을 최소화하는 것이 더 중요
5.3 스케줄링 알고리즘 (Scheduling Algorithms)
① First-Come, First-Served (FCFS) Scheduling 선입 선처리
② Shortest-Job-First (SJF) Scheduling 최단 작업 우선
③ Priority Scheduling 우선순위
④ Round-Robin (RR) Scheduling
⑤ Multilevel Queue Scheduling 다단계 큐
⑥ Multilevel Feedback Queue Scheduling 다단계 피드백 큐
① First-Come, First-Served (FCFS) Scheduling
-
The process that requests the CPU first is allocated the CPU first.
CPU를 먼저 요청하는 프로세스가 CPU를 먼저 할당합니다. -
Non-preemptive Scheduling. 비선점
-
Simple to write and understand.
-
The implementation can be easily managed with a FIFO queue.
구현은 FIFO queue을 통해 쉽게 관리할 수 있습니다. -
Average waiting time is often quite long.
평균 대기 시간은 종종 꽤 깁니다. (대화형 시스템에 적절하지 않다.)
Particularly troublesome for time-sharing systems.
특히 시간 공유 시스템에 문제가 있습니다.
(+)
-
프로세스가 준비 큐에 진입하면, 이 프로세스의 프로세스 제어 블록(PCB)을 큐의 끝에 연결한다.
-
CPU가 가용 상태가 되면, 준비 큐의 앞부분에 있는 프로세스에 할당된다. 이 실행 상태의 프로세스는 이어 준비 큐에서 제거된다.
-
FCFS의 부정적인 측면으로는 선입 선처리 정책하에서 평균대기 시간은 종종 대단히 길 수 있다는 점을 갖고 있다.
-
선입 선처리 스케줄링 알고리즘은 비선점형 알고리즘이다.
-
일단 CPU가 한 프로세스에 할당되면, 그 프로세스가 종료하는지 또는 I/O 처리를 요구하든지 하여 CPU를 방출할 때까지 CPU를 점유한다
< Example of FCFS Scheduling >

대기시간 구하는 문제
< CONVOY EFFECT >
: 긴 프로세스 하나 때문에 짧은 프로세스 여러개가 기다리는 현상

② Shortest-Job-First (SJF) Scheduling
- 최단 작업 우선(Shortest Job First, SJF) 알고리즘은 CPU 버스트 길이가 가장 작은 프로세스부터 순서적으로 CPU 코어를 할당
- 평균 대기 시간을 가장 짧게
< Two schemes >
②-(1) SJF : Non-preemptive
- once CPU given to the process it cannot be preempted until completes its CPU burst.
- 프로세스에 제공된 CPU는 CPU 버스트를 완료할 때까지 우선할 수 없습니다.
(+)
일단 CPU를 잡으면 더 짧은 프로세스가 들어와도 CPU 버스트가 완료될 때까지 CPU를 선점당하지 않음
②-(2) SJF : Preemptive [ SRTF ]
- if a new process arrives with CPU burst length less than remaining time of current executing process, preempt. This scheme is know as the Shortest Remaining Time First (SRTF).
- CPU 버스트 길이가 현재 실행 프로세스의 남은 시간보다 짧은 새 프로세스가 도착하면 다음을 수행합니다. 이 체계를 SRTF(최단 남은 시간 우선)라고 합니다.
(+)
CPU를 잡았다 하더라도 더 짧은 프로세스가 들어오면 CPU를 뺴앗김.
< 문제점 >
- (1) Starvation (기아): 짧은 프로세스로 인해 긴 프로세스가 영원히 CPU를 잡지 못할 수 있음
- SJF is optimal in that it gives minimum average waiting time for a given set of processes.
- SJF는 주어진 공정 집합에 대한 최소 평균 대기 시간을 제공한다는 점에서 최적입니다.
- Moving a short process before a long one decreases the waiting time of the short processes more than it increases the waiting time of the long process.
- (2) CPU 버스트 시간을 미리 알 수 없음: 과거 CPU 사용 시간을 통해 추정만 가능
- The difficulty is knowing the length of the next CPU request
-> can ask the user or estimate !
- The difficulty is knowing the length of the next CPU request
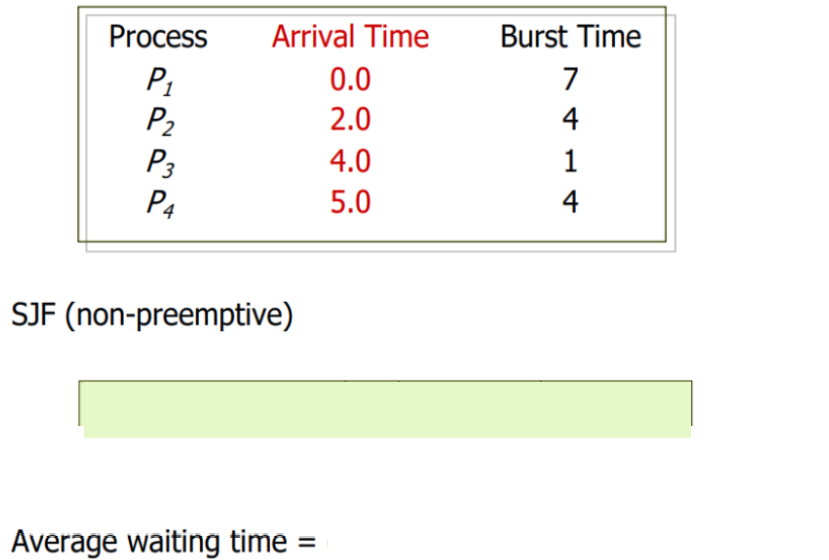
< Example of Non-Preemptive SJF >
(연습용)
< Example of Preemptive SJF >

(연습용)

< Determining Next CPU Burst Length >
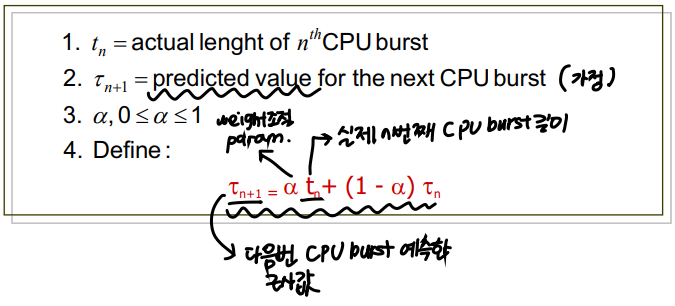
- Can only estimate the length.
- Can be done by using the length of previous CPU bursts, using exponential averaging.
③ Priority Scheduling
-
A priority number (integer) is associated with each process.
우선 순위 번호(정수)는 각 프로세스와 연결됩니다. -
The CPU is allocated to the process with the highest priority (smallest integer = highest priority).
CPU는 가장 높은 우선순위(숫자 정수 = 가장 높은 우선순위)로 프로세스에 할당
③-(1) Preemptive
③-(2) Non-preemptive
< 문제 >
- 무한 봉쇄(indefinite blocking) / 기아 상태(starvation)이다.
- 실행 준비는 되어 있으나 CPU를 사용하지 못하는 프로세스는 CPU를 기다리면서 봉쇄 된 것으로 간주할 수 있다. (Blocking)
- 부하가 과중한 컴퓨터 시스템에서는 높은 우선순위의 프로세스들이 꾸준히 들어와서 낮은 우선순위의 프로세스들이 CPU를 얻지 못하게 될 수 도 있다. (Starvation)
< 해결 방안 > : Aging
- 노화(aging)이다. 노화는 오랫동안 시스템에서 대기하는 프로세스들의 우선순위를 점진적으로 증가시킨다.
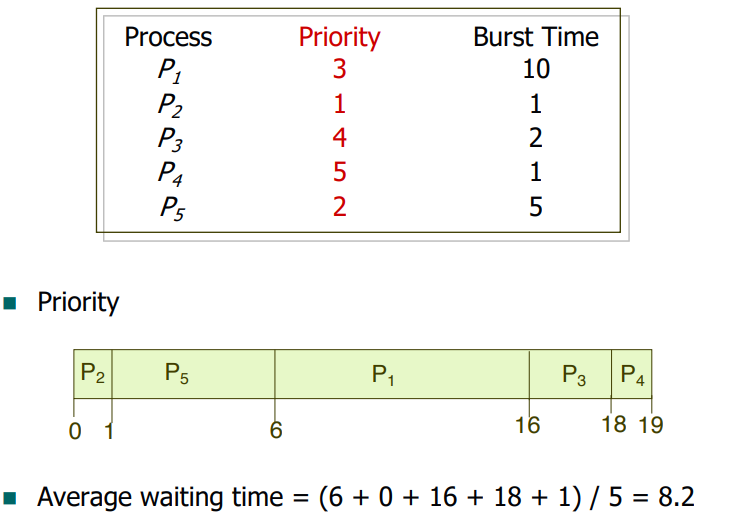
< Example of Priority Scheduling >
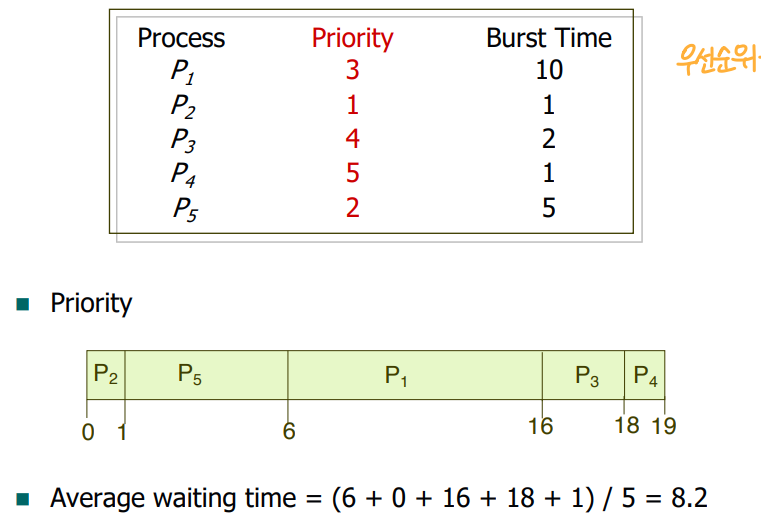
(연습용)
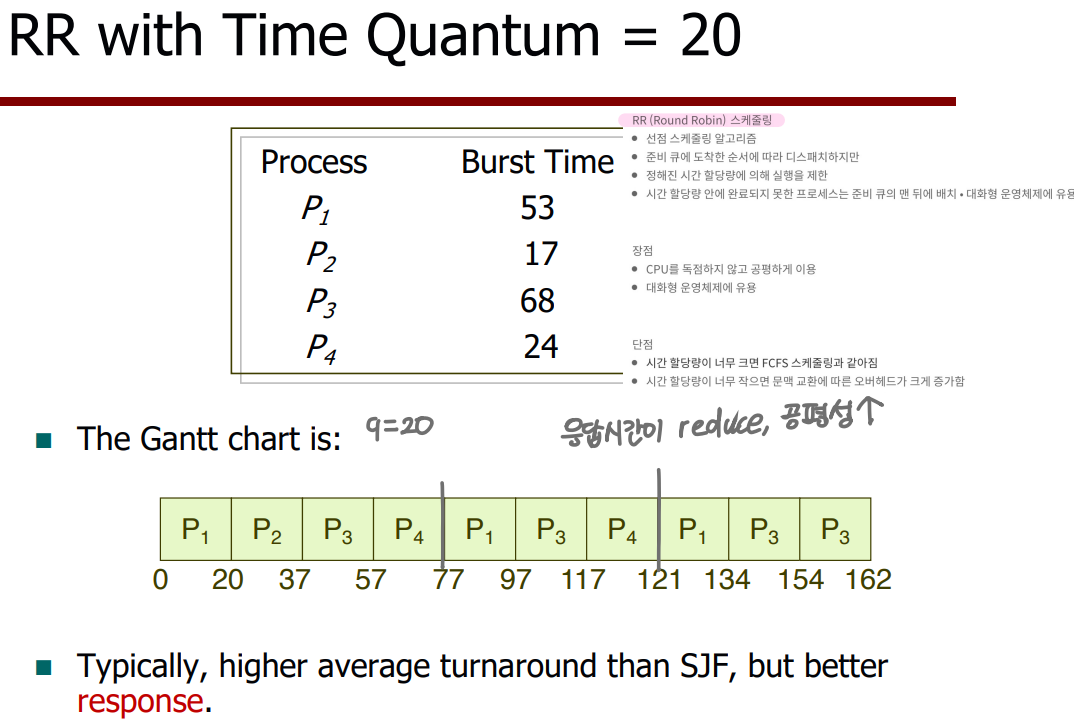
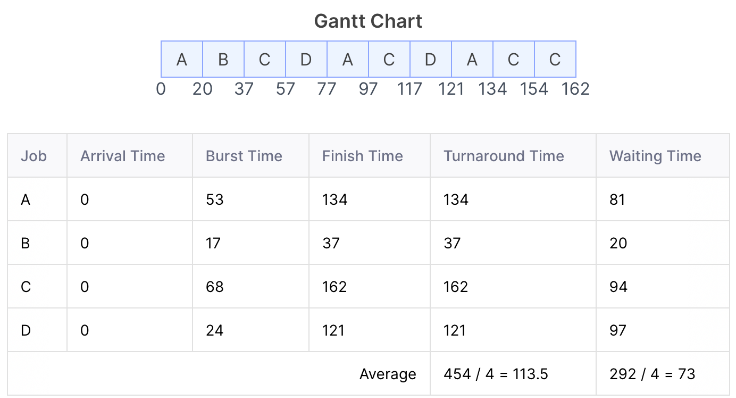
④ Round-Robin (RR) Scheduling
-
Each process gets a small unit of CPU time (time quantum), usually 10-100 milliseconds.
각 프로세스는 동일한 크기의 할당 시간인 time quantum 을 가짐 -
After this time has elapsed, the process is preempted and added to the end of the ready queue.
할당 시간이 지나면 프로세스는 CPU를 빼앗기고 Ready Queue 맨 뒤에 가서 줄을 서게 됨
짧은 응답 시간을 보장함
조금씩 CPU를 줬다 뺏었다를 반복하기 때문에 CPU를 최초로 얻기까지 걸리는 시간이 짧음
- if there are n processes in the ready queue and the time quantum is q, then each process gets 1/n of the CPU time in chunks of at most q time units at once.
- No process waits more than (n-1)q time units.
- n개의 프로세스가 Ready Queue에 있고, 할당 시간이 q time unit인 경우, 각 프로세스는 CPU 시간의 1/n을 최대 q 시간 단위로 한 번에 가져옵니다.
- 어떤 프로세스도 (n - 1) q time unit 이상 기다리지 않음
=> 즉 `(n - 1) q` 가 최대 대기 시간
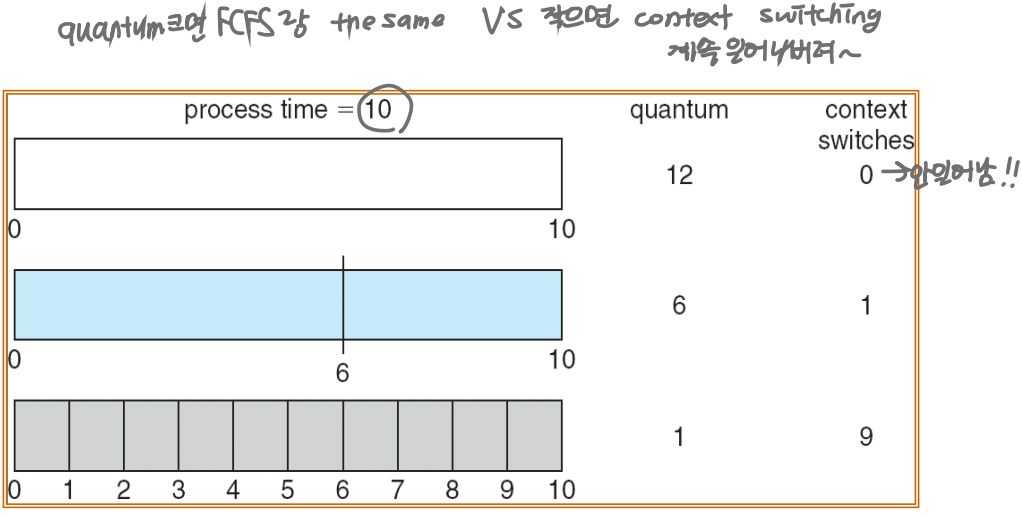
< Performance >
- q large -> FCFS
q가 커질 수록 FCFS에 가까워짐 - q small -> q must be large with respect to context switch.
q가 작을 수록 (시간 할당량)이 매우 적다면 RR 정책은 매우 많은 문맥 교환을 야기- If q is extremely small, it is called processor sharing – each of n processes has its own processor running at 1/n the speed of the real processor.
- q가 매우 작으면 프로세서 공유라고 합니다. 각 n개의 프로세스에는 실제 프로세서의 1/n 속도로 실행되는 자체 프로세서가 있습니다.
< RR with Time Quantum = 20 >
( 연습용 )

< Time Quantum vs Context Switch Time >
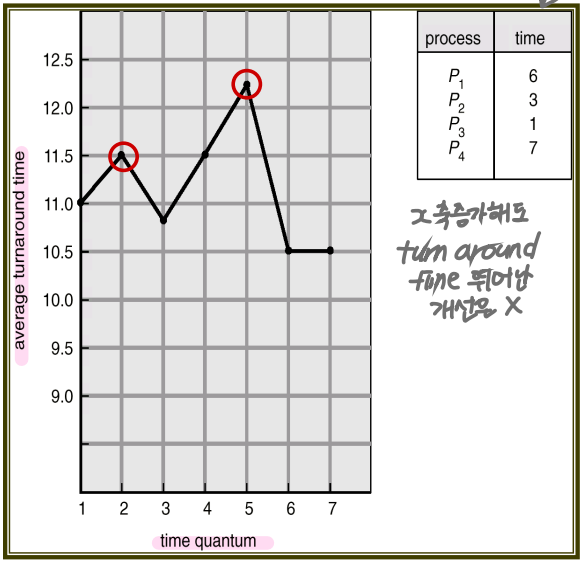
- Average turnaround time does not necessarily improve as the time quantum size increases.
- X축인 TIME QUANTUM이 증가한다고 해서 뛰어난 개선이 있는것은 아니다.
- If time quantum is too large, RR scheduling becomes FCFS policy.
- 80 percent of the CPU bursts should be shorter than the time quantum.
- CPU burst 의 80%는 time quantum 보다 작아야 한다.
⑤ Multilevel Queue Scheduling
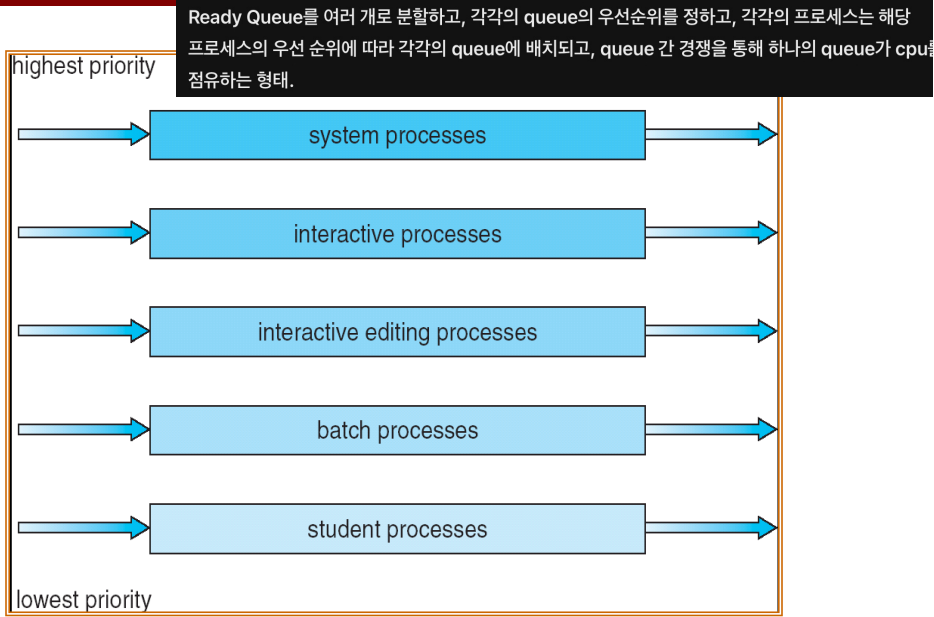
- (+) 프로세스들은 자신의 우선순위 값에 해당하는 큐에 들어가게 되며, 우선순위가 낮은 하위 단계 큐의 작업은 실행 중이더라도 상위 단계 큐에 프로세스가 도착하면 CPU를 뺏기는 선점 방식이다.
-
Ready queue is partitioned into separate queues.
-
준비 큐를 아래와 같이 분리한 것
- Foreground (interactive) - 대화형 , cpu burst 주로 짧은 애들
- Background (batch) - 계산 위주의 batch
-
Process resides permanently in a given queue.
-
Each queue has its own scheduling algorithm.
- (1) ⑤.1.1 Foreground - Round Robin
- 사용자에게 높은 응답속도를 제공해야 한다. - 따라서, 응답속도 위주인 Round Robin을 사용- (2) ⑤.1.2 Background - FCFS
- 처리량을 중점으로 두기 때문에, FCFS를 사용 -
Scheduling must be done between the queues.
큐 간의 스케줄링, 프로세스 스케줄링이 아닌, 어떤 큐를 사용할 것인지에 대한 스케줄링을 할 수 있다<스케줄링 방법>
-
프로세스 스케줄링이 아닌, 어떤 큐를 사용할 것인지에 대한 스케줄링을 할 수 있다.
‘Foreground Queue’ vs ‘Background Queue’- (1) ⑤.2.1 Fixed priority scheduling 고정 우선순위 스케줄링
-
(i.e., serve all from foreground then from background). Possibility of starvation.
-
Foreground Queue의 Task 들이 완료될 때까지, Background Queue의 Task들이 기다린다.
-
즉, 우선순위가 낮은 Task들은 평생 기다려야할 수 있다.
-
왜냐하면 고정 우선순위이기 때문이다. (Aging을 사용하면 극복할 수 있는 문제이다.)
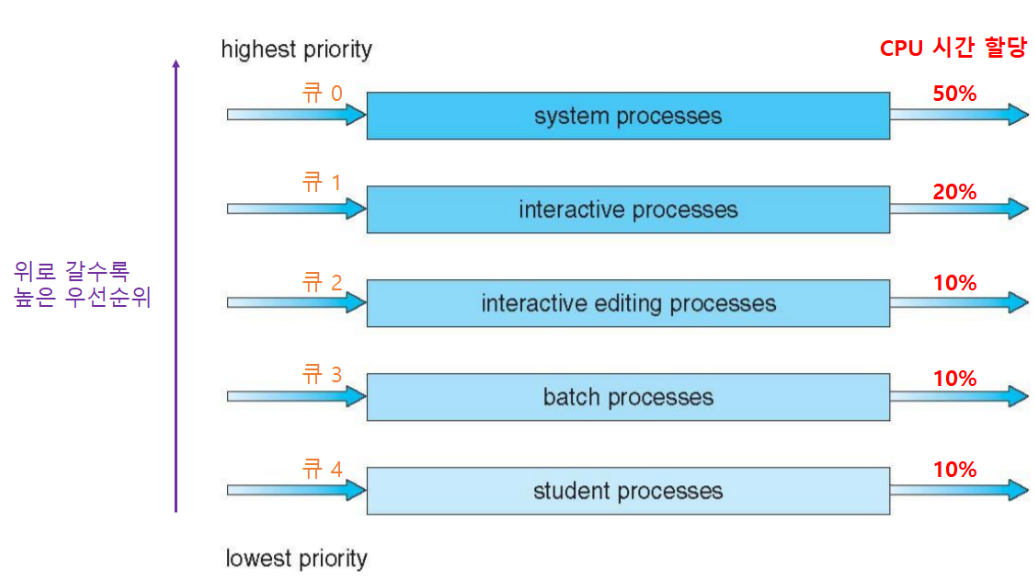
- (2) ⑤.2.2 Time slice 시분할
– each queue gets a certain amount of CPU time which it can schedule amongst its processes;
-
i.e., 80% to foreground in RR and 20% to background in FCFS.
-
각 큐마다 사용할 수 있는 CPU 시간을 분배하는 방법
-
예시) Foreground Queue = 80% CPU 시간 할당, Background Queue = 20% CPU 시간 할당
-
(+)
-
- (+) 우선순위를 가진 큐 별로 CPU를 선점할 수도 있고, 큐들 사이에 CPU의 시간을 나누어서 사용할 수도 있으니, 본인이 사용하는 문맥에 따라서 알고리즘을 적절히 활용하자.
- (+) 프로세스들은 자신의 우선순위 값에 해당하는 큐에 들어가게 되며, 우선순위가 낮은 하위 단계 큐의 작업은 실행 중이더라도 상위 단계 큐에 프로세스가 도착하면 CPU를 뺏기는 선점 방식이다.
- (+) 정적 우선순위이므로 큐들 간에 프로세스의 이동이 불가능
- (+) 장점 : 각각 프로세스의 중요도에 따라 큐로 나누고 각 큐에서 다른 알고리즘을 적용해 효율을 높이기 가능
- (+) 단점 : 반면에 한 번 해당 큐에 들어가면 프로세스는 다른 큐로 이동되거나 변경되는 것이 거의 불가능 즉 스케줄링 오버헤드가 낮은 대신에 inflexible 유연적이지 못합니다.
- (+) 큐에 영구적 할당
- (+) 일반적으로 성격이 다른 프로세스들을 별도로 관리하고 프로세스의 성격에 맞는 스케줄링을 적용하기 위해 별도의 큐를 두게 된다
- 내가 이해한 멀티레벨큐와 멀티레벨피드백 큐 차이점
- 멀티레벨큐는 자신의 큐 안에서 다 수행될 때까지 못 움직여
- 그러나 피드백 큐는 자기가 수행되고 있는 큐에서 다 수행이 안된다? 싶으면 다음 큐로 내려보낼 수 있는 것 => 프로세스가 큐들 사이를 이동하는 것을 허용
⑥ Multilevel Feedback Queue Scheduling
-
다단계 피드백 큐 스케줄링 알고리즘은 Aging과 Starvation 예방
-
다단계 큐 스케줄링 알고리즘에서는 일반적으로 프로세스들이 시스템 진입 시에 영구적으로 하나의 큐에 할당
-
A process can move between the various queues; aging can be
implemented this way -
이와 반대로 다단계 피드백 큐 스케줄링 알고리즘에서는 프로세스가 큐들 사이를 이동하는 것을 허용
-
(+) 여러 개의 큐, 각 큐마다 스케줄링 알고리즘을 적용할 수 있는 것까지 동일
-
Multilevel-feedback-queue scheduler defined by the following
parameters:- number of queues
- scheduling algorithms for each queue
- method used to determine when to upgrade a process
» 작업을 보다 높은 우선순위의 큐로 격상시키는 시기 결정 알고리즘 - method used to determine when to demote a process
» 작업을 보다 낮은 우선순위의 큐로 격하시키는 시기 결정 알고리즘 - method used to determine which queue a process will enter when that process needs service
» 프로세스들이 어느 큐에 들어갈 것인가를 결정하는 알고리즘
-
(+) 동적 우선순위를 기반으로 하는 선점 방식으로 운영된다.
-
(+) 여러 단계(우선순위 개수만큼)의 큐가 있으며 각 단계마다 서로 다른 CPU 시간 할당량
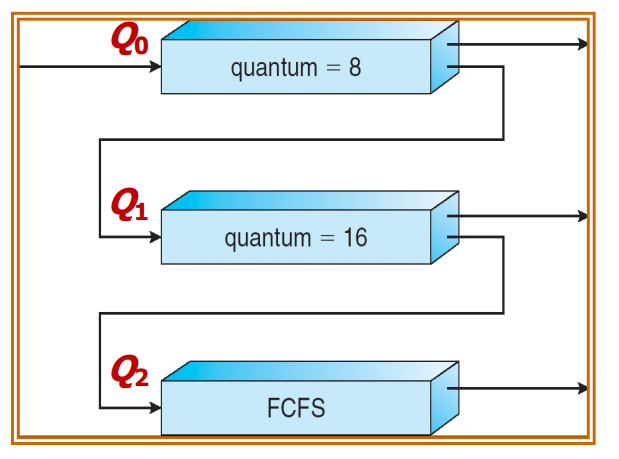

-
제일 위에 있는 queue는 RR으로 스케줄링을 하는데 time-quantum을 8로 스케줄링을 해요,
-
자신의 time quantum을 다 채우지 못한 process는 냅두고 time quantum을 다 채운 프로세스는 그 밑의 레벨에 있는 큐로 들어가게 됩니다.
=> 특징은, 밑에 있는 큐는 타임퀀텀의 크기를 첫 번째 있는 큐의 두 배로 돌려요! -
(+) 처음 들어오는 프로세서는 우선순위가 가장 높은 큐에 넣는다. 그리고 라운드 로빈 시간을 아주 조금 준다. 그리고 만약 처리가 그 큐에서 안끝났다면 아래 큐로 보내고 아래 큐로 갈수록 라운드 로빈 할당 시간을 조금씩 늘린다. 그리고 아래로 갈 수록 fcfs로 스케쥴링을 한다
-
마지막 큐는 백그라운드 프로세스가 보통 그랬듯이 대게 FCFS로 처리
< 문제점 >
-
우선순위가 높은 프로세스(INTERACTIVE) 가 들어오면 큐만 주구장창 수행되고 낮은 우선순위 애들은 밀리는 starvation문제가 발생
-
이럴 경우 우선순위 스케줄링에서 언급했던 aging 방식을 도압해서 해결할 수 있습니다.
-
a process that waits too long in a lower-priority queue may be moved to a higher priority queue.
-
낮은 우선순위 큐에서 너무 오래 기다리는 프로세스들을 높은 우선순위 큐에 다시 갖다놓는거
(+) 멀티레벨피드백 큐 우선순위 명쾌 정리글 :
- 게임 다운로드처럼 CPU를 계속 써야하는, CPU burst가 큰 프로세스를 우선순위가 낮다고 판별하는 겁니다.
- 그리고 나와 상호작용할 가능성이 높은 프로세스, 내 입출력을 필요로 하는(마우스 클릭이라던지 키보드 타이핑이라던지) 이런 애들은 CPU처리가 I/O작업이랑 번갈아가며 일어나므로 CPU burst가 작다는 특징을 기져요 그리고 이를 우선순위가 높구나! 이런 특징을 활용한 것이 멀티레벨피드백 큐인겁니다
- time quantum을 다채웠다는것은 CPU burst process일 가능성이 높죠 그래서 한번 더 밑으로 내려보는겁니다.
- 16으로 했더니 그걸 또 다 채웠어!! 그럼 이거는 CPU bound process구나!
- 그러니까 아예 밑으로 내려가서 CPU bound process들은 사용자하고 대화형으로 동작하는 것이 아니니까 context switching을 안하고 그냥 개를 쭉 수행시켜주는 것이 유리하겠죠? 그러니까 FCFS로 그냥 하는겁니다.
=> 즉 다음 단계로 넘어갈 수록 CPU burst가 크다는 거니까 우선순위가 점점 낮아진다! 이런 룰이 되는거예요 - That is, I/O bound process들은 사용자하고 대화형으로 동작 !!
- 그러니까 개네들을 먼저 수행시켜줘야지 CPU bound process는 사용자들을 기다리지도 않잖아 !!
- interactive process는 계속 대화형으로 해야하니까 이 멀티레벨피드백 방식은 대화형 프로세스의 우선순위를 높이는 스케줄링의 방법이겠죠.
Algorithm Evaluation
① 결정론적 모델링 (Deterministic Modeling)
– takes a particular predetermined (static) workload and defines the performance of each algorithm for that
workload (e.g. Gantt chart)
- < 장점 >
- Simple and fast
- < 단점 >
- Requires exact number for input,정확한 숫자를 요구
- its answers apply only to those cases 응답도 단지 이들의 경우에만 적용
- (+) 사전에 정의된 특정한 작업 부하를 받아들여 그 작업 부하에 대한 각 알고리즘의 성능을 정의
② Queueing models
- Queueing-network analysis
- Little’s formula: n = λ * W
- n: average queue length
- λ: average arrival rate for new processes
- W: average waiting time in the queue
- (+) 많은 시스템에서 실행되는 프로세스들은 날마다 변화하기 떄문에, 결정론적 모델링을 사용할 수 있는 프로세스들(그리고 시간)의 정적인 집합이 없다. 그러나 결정할 수 있는 것은 CPU와 I/O 버스트의 분포이다. 이들의 분포는 측정할 수 있으며 그런 후에 근삿값을 계산하거나 단순하게 추정 가능
- Queueing-network analysis
③ 모의실험 (Simulation)
- Programming a model of the computer system.
- Trace tape: monitor the system and record the sequence of events.
- sequence recoed 적어놓은 것
- (+) 스케줄링 알고리즘을 완벽히 정확하게 평가하는 유일한 방법은 실제 코드로 작성해 운영체제에 넣고 실행해 보는 것
④ 구현 (Implementation)
- Completely accurate way to evaluate a scheduling algorithm.
- Puts a scheduling algorithm in the real system under real operating conditions (e.g., using Linux kernel or Pintos).
- (+) 스케줄링 알고리즘을 완벽히 정확하게 평가하는 유일한 방법은 실제 코드로 작성해 운영체제에 넣고 실행해 보는 것
