
시간 검색어 크롤링
Crawler : 크롤러는 데이터를 모아주는 역할
- web crawler : 데이터를 모아주는 소프트웨어
0. 파이썬 실행법
=> 명령어 실행 : shell에 python 파일명.py 입력
1. 외부 모듈 requests 필요
pip install requestsimport requests- 함수 : 자주 쓰이는 아이들을 미리 만들어 놓은 것
- 모듈 : 파이썬에서 자주 쓰이는 함수들을 모아둔 파일
2. requests 함수 탐구
requests 모듈에서
get 함수를 꺼내어
요청을 보내줘
import requests
print(requests)=> requests가 설치된 경로를 알려준다
print(requests.get)-
requests는 GET 이라는 요청을 보내는 기능
REQUESTS
클라이언트는 서버에게 특정 웹주소의 정보를 요청, 그럼 서버는 받아온 요청을 찾아 결과값을 찾은 후 이를 클라이언트에게 전달 -
서버는 응답을 하는 역할, 클라이언트는 요청 & 응답값을 받는 역할

사진출처
requests.get(url)
간장계란장조리키트.계란삶기키트(계란)
return 값 : 간장계란장 는 아래와 같다
requests라는 모듈안의 get 함수를 이용해 parameter을 요리하는 것
parameter 란? argument 와의 간단 차이 설명
parameter is what is declared in the function,
while an argument is what is passed through when calling the function
(ex) 참고한 스택오버플로우def add(a, b): return a+b add(5, 4)
- 위의 예시에서 a,b가 parameter, 5,4 가 인자
requests.get(url)
return 값 : requests.response3. requests 함수 직접 실행
import requests
requests.get('http://www.naver.com')=> 아무 응답도 뜨지 않음, 하지만 이는 url 자리에 온 인자에게 요청을 보내는 중인 것은 사실
이를 확인 위해서는 print
import requests
print(requests.get('http://www.naver.com'))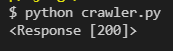
=> 하지만 이는 상태값만 보여준다 (requests.get(url))의 상태값)
=> 우리는 이 안의 결과물을 보고싶은 것이므로
import requests
response = requests.get('http://www.naver.com')
print(response)
print(response.text)이때 그냥 response만 프린트하면 상태값이
response.text 를 하면 response에 담겨온 아이를 text 형식으로 출력해주는 것
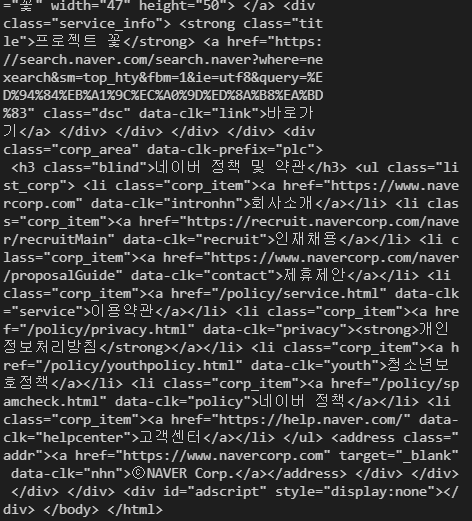
=> url의 html을 요소를 받아와서 출력해오는 것
text 방식 말고 다른 요소들
print(response.url)
print(response.content)
print(response.encoding)
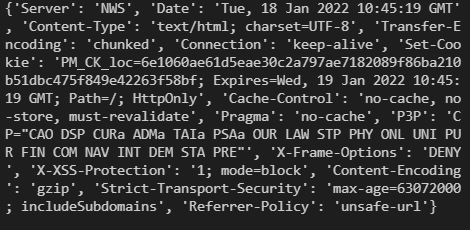
print(response.headers)
print(response.json)
print(response.links)
print(response.ok)
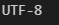
print(response.status_code)
-> 200



4. BeautifulSoup
1) 모듈 설치
pip install beautifulsoup42) 호출
import requests
from bs4 import BeautifulSoup
3) 코드 작성
import requests
from bs4 import BeautifulSoup
response = requests.get('http://www.naver.com')
print(type(response.text))
print(type(BeautifulSoup(response.text,features="html.parser")))=> beautiful soup는 내가 가져온 정보를 의미있는 정보로 변환 도움
=> type을 씌워서 type을 알아보면 아래와 같이 둘이 다른 type임을 알 수 있음

강의랑 사소하게 다른 점print(type(BeautifulSoup(response.text,features="html.parser")))
- beautiful soup는 string(문자열)을 어떤 beautiful soup 안에 차곡차곡 정리해주는 것
4) beautiful soup의 용도
BeautifulSoup(데이터, 파싱방법)
=> 데이터는 html,css 를 받아오는 부분
=> parsing 응답을 의미있는 데이터로 변경하는 것 , parsing을 도와주는 아이를 parser이라고 한다.
response 값의 처음 499 글자만 데려와본다면
print(response.text[:500])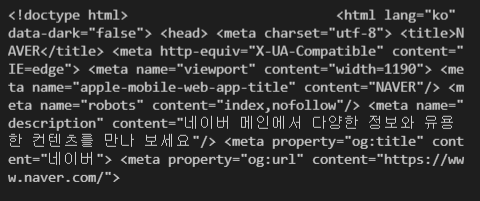
위의 사진과 같이 출력됨
slice
>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90] >> a[0:4] # 인덱스 0부터 3까지 잘라서 새 리스트를 만듦 [0, 10, 20, 30] => [:500]이라면 인덱스 0부터 499까지만 잘라오라는 말임
import requests
from bs4 import BeautifulSoup
response = requests.get('http://www.naver.com')
#print(type(response.text))
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.title)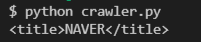
=> title html 태그가 담긴 아이만 데려온다는 것을 파악 가능
soup는 그냥 데이터를 통으로 저장하는 게 아니라 적절하게 분류해서 데리고 있음
따라서 soup로 정제해 준 데이터에서 원하는 칸에 담긴 아이만 데려올 수 있는 것
(ex) soup.title은 soup의 여러가지 칸 중에서 title 에 담긴 칸을 데려오고 싶어하는 것, soup.span 은 span 에 담긴 칸의 아이 중 가장 상단의 아이만 데려오고 싶어하는 것
(soup.span 결과는 아래와 같음)

- 상단의 아이 하나만 아니라 모두 추출해오고 싶다면
(ex) 모든 span과 관련된 아이 추출 원한다면
print(soup.findAll('span'))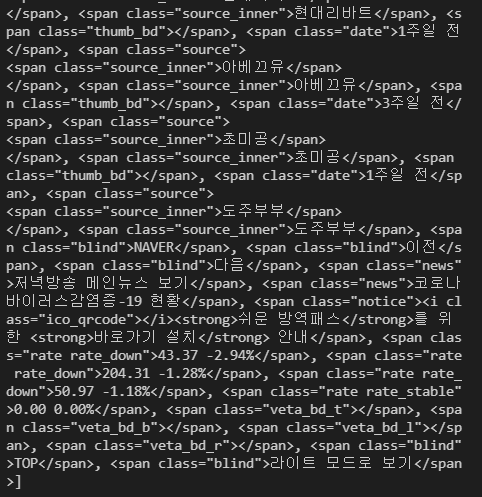
5) 내가 원하는 데이터만 데려오는 방법은!?
5-1 ) 우선 데이터를 담아서 데려올 파일 생성하기
import requests
from bs4 import BeautifulSoup
response = requests.get('http://www.naver.com')
file = open("naver.html","w")
file.write(response.text)
file.close()- 위처럼 file open 시 아래와 같은 에러 발생
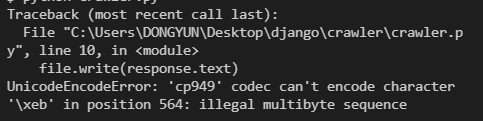
UnicodeEncodeError: 'cp949' codec can't encode character
'\U0001f64c' in position 86972: illegal multibyte sequence
=> so 파일 오픈 시 인코딩 방법 (encoding="utf-8") 추가
(한글깨짐 방지 ENCODING UTF-8 추가, 만약 csv 라면 encoding="UTF-8-sig" 추가해줘야 함)
file = open("naver.html","w", encoding = "utf-8")
file.write(response.text)
file.close()
위와 같이 파일 생성됨
file 관련한 python 명령어
def open(file, mode='r'):
1. 첫번째 인자 file
- 파일 경로를 집어 넣습니다.
2. 두번째 인자 mode
- 파일이 열리는 옵션, 모드 입니다. 이 모드에 따라 읽기 용인지 파일을 생성하고 쓸것인지 등이 정해집니다.
- 'r' : 기본값으로 정해져 있으며 파일을 읽기 위한 옵션 입니다.
- 'w' : 쓰기모드이며 파일에 내용을 쓸 때 사용하는 옵션 입니다. 만약 이미 파일이 존재하면 커서를 맨 앞으로 돌리면서 뒤에 내용을 다 잘라내기 때문에 내용이 사라질 수 있습니다. 파일이 존재하지 않는다면 새롭게 파일을 생성합니다.
- 'a' : 쓰기모드이며 파일에 내용을 쓸 때 사용하는 옵션입니다. w 옵션과는 달리 이미 파일이 존재하면 그 파일의 끝에 커서가 존재하고, 그 뒤에 이어쓰기가 가능합니다.
즉, 파일 내용을 잘라내지 않고 이어서 쓸 수 있습니다.
- 'x' : 파일이 없으면 파일을 생성하고 쓰기모드로 열립니다. 만약 파일이 있으면 에러를 발생시킵니다.
- 'b' : 바이너리 모드 입니다.
- 't' : 텍스트 모드 입니다. (기본값)
두번째 인자는 'r', 'w', 'a', 'x' 와 같이 't'나 'b'를 따로 쓰지 않으면 기본적으로 텍스트 모드인 't'로 열리게 됩니다. 즉, 읽기위해 'r'을 넣는다는것은 'rt'를 넣는것과 동일한 뜻 입니다.
=> 만약 파일을 읽기모드인데 바이너리 모드로 열고싶다면 'rb' 이런식으로 집어 넣으면 됩니다.
따로 표기하지 않으면 기본 텍스트 모드인 't'로 열림
=> 오픈한 파일을 닫으려면 파일 닫기 함수인 close()함수를 이용
출처: https://blockdmask.tistory.com/454 [개발자 지망생]
=> 미리 해본 결과 daum 은 제대로 안 불러와진다
=> 실시간 검색어 있눈 사이트 중에선 네이트로 하는게 더 나을 듯
daum.net 보단 nate.come 추천
from bs4 import BeautifulSoup
import requests
url = "https://www.nate.com/."
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
file = open("nate.html","w", encoding="utf-8")
file.write(response.text)
file.close()
print(soup.title)
print(soup.title.string)
print(soup.span)
print(soup.findAll('span'))=> nate.html 에서 실시간 검색어로 활용하면 됨
5-2) 태그, 클래스에 속하는 애들만 데려오는 방법

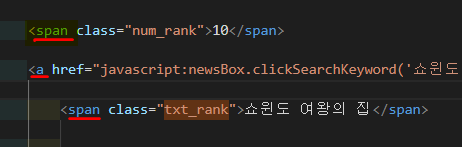
=> 실시간 검색어가 txt_rank 라는 클래스로 감싸져 있음
- Beautiful soup를 통해서 태그를 불러오는 방법
(soup.findAll("태그"))
태그란?
- 밑줄 친 아이들을 가리키는 것
- 일반적인 의미에서는 식별, 구별 또는 인식을 위해 짧은 크기로 붙여 놓은 것
- 프로그래밍에서 태그란 표현이나 어떤 기능의 수행을 지시하는 짧은 낱말을 가리킴
출처 : html 태그란
url = "http://www.daum.net/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
(soup.findAll("a"))- 태그 + 그 태그 안의 클래스도 불러오려면
(soup.findAll("태그", "클래스")) 로 불러와야 함
현재 네이트 사이트의 검색어는 span 태그 안의 txt_rank 클래스 안에 담겨져있음, 따라서 이를 불러오기 위해선 아래와 같이 코드 작성
print(soup.find_all('span','txt_rank'))
프린트한 결과는 아래와 같습니다.
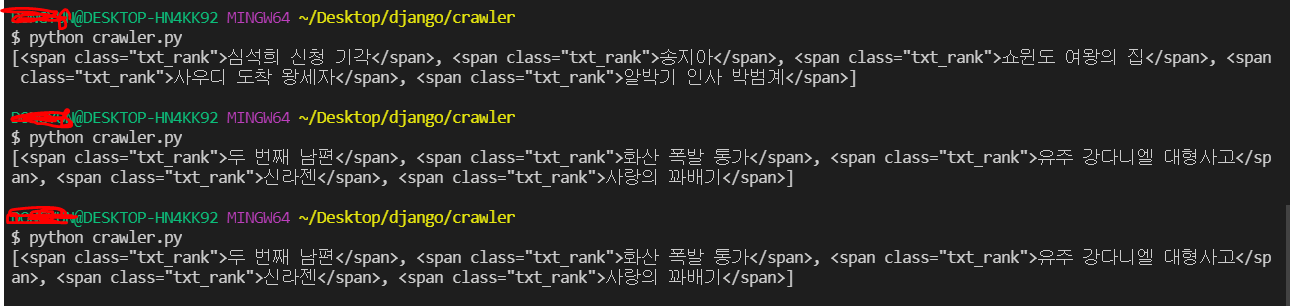
=> 근데 여기서 프린트 될 때 아래처럼 앞의 태그, 클래스명도 함께 출력됨, 검색어만 보려면 우짜지?? 그럼 ~ 이를 제거해보자

5-3) 데려온 아이들 자체만 예쁘게 담아오는 방법
from bs4 import BeautifulSoup
import requests
url = "https://www.nate.com/."
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
results = (soup.find_all('span','txt_rank'))
- 데려올 아이들을 results 라는 주머니에 넣어주기, 이 주머니엔
< span class ='txt_rank'>라는 아이 만날 때마다 주머니에 넣어주는 것
이 results 주머니에 들어온 아이들(result 라고 변수 설정)을 우선 하나하나 따로따로 구경하고 싶다면 아래와 같이 for 문을 활용해서 아이들을 따로따로 출력해주면 됨
for result in results :
print(str(result) + "\n")만약 아이들을 baby란 이름으로 불러오고 싶다면
for baby in results : print(str(baby) + "\n")이런 식으로써주면 된다
(+) 개행문자 , str(출력값)
\n는 개행문자로 한 아이를 꺼내올 때마다 개행처리를 해주어서 각 아이들 사이에 빈줄이 만들어지게해줌- str()로 출력값을 씌워주면 문자열 처리 되어서 결과값이 나온다.
결과는 아래와 같이 아이들이 따로따로 나오는구나 파악 가능
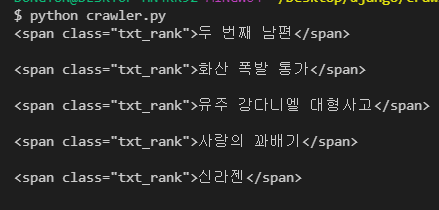
근데 여전히 text 이외에도 태그와 클래스를 나타내주는 친구가 나옴
따라서 우리는 주머니속에 든 각각의 result의 아이 안에 담긴
text 만 뽑아낼 것이라는 의미에서
그저 result 가 아닌
result.text로 뽑아와준다
from bs4 import BeautifulSoup
import requests
url = "https://www.nate.com/."
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
results = (soup.find_all('span','txt_rank'))
for result in results :
print(str(result.text) + "\n")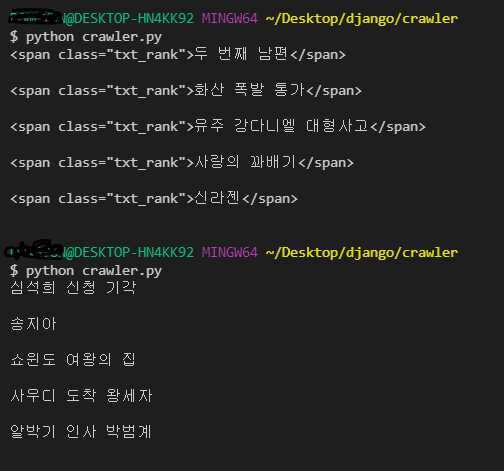
(+) from datetime import datetime 으로 현재 시각 출력하기
from datetime import datetime
print(datetime.today())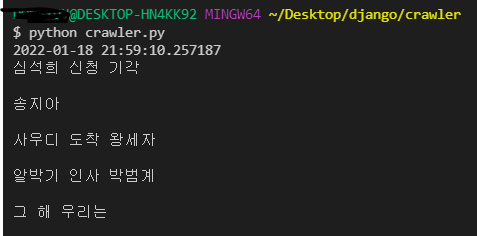
- 사진의 맨 첫줄과 같이 날짜, 시각 출력
=> 이를 문장에 담아 출력하고 싶다면
print(datetime.today().strftime("%Y년 %m월 %d일 %H시 %M분의 실시간 검색어 순위입니다.\n"))
로 작성해주면 년,월,일,시,분 순서대로 출력된다.
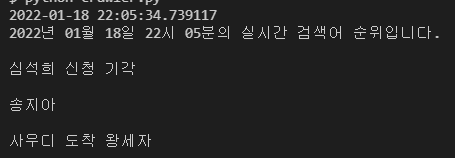
- 코드 윗 줄은 그냥 DATETIME 으로 출력, 밑 줄은 STRFTIME()메서드로 DATETIME을 변환해서 출력
STRFTIME 명령어
- datetime 오브젝트, date 오브젝트의 strftime() 메서드를 사용해 날짜 형식을 변환
◆ %d : 0을 채운 10진수 표기로 날짜를 표시
◆ %m : 0을 채운 10진수 표기로 월을 표시
◆ %y : 0을 채운 10진수 표기로 2자리 년도
◆ %Y : 0을 채운 10진수 표기로 4자리 년도
◆ %H : 0을 채운 10진수 표기로 시간 (24시간 표기)
◆ %I : 0을 채운 10진수 표기로 시간 (12시간 표기)
◆ %M : 0을 채운 10진수 표기로 분
◆ %S : 0을 채운 10진수 표기로 초
◆ %f : 0을 채운 10진수 표기로 마이크로 초 (6자리)
◆ %A : locale 요일
◆ %a : locale 요일 (단축 표기)
◆ %B : locale 월
◆ %b : locale 월 (단축 표기)
◆ %j : 0을 채운 10진수 표기로 년중 몇 번째 일인지 표시
◆ %U : 0을 채운 10진수 표기로 년중 몇 번째 주인지 표시 (일요일 시작 기준)
◆ %W : 0을 채운 10진수 표기로 년중 몇 번째 주인지 표시 (월요일 시작 기준)
6) 원하는 값을 파일로 저장하기
open("파일명", 모드)
모드 - r(read), w(write), a (append) - 기존에 추가
- 모드에 따라서 파일이 어떤 모드로 열릴 지 결정이 되는 것
file = open("nate_실시간검색어.html","w", encoding="utf-8")
for result in results :
file.write(str(result.text) + "\n")
file.close() #파일을 열고 작성 완료했으면 꼭 닫아주어야 한다.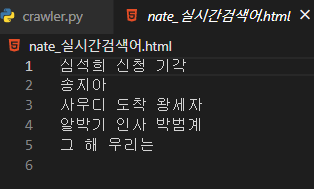
이때 새로 갱신된 검색어도 파일에 추가하고 싶으면 mode를 append 로 변경해주면 된다
file = open("nate_실시간검색어.html","a", encoding="utf-8")
for result in results :
file.write(str(result.text) + "\n")
file.close() #파일을 열고 작성 완료했으면 꼭 닫아주어야 한다.7) 사이트 접근 금지된 정보 데려오기
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
url = "https://datalab.naver.com/keyword/realtimeList.naver?age=20s"
response = requests.get(url,headers=headers)=> headers 에는 우리가 로봇 기계가 아니라는 정보를 담고 , 우리가 정보를 가져오길 바라는 url로 보내서 header을 서버에 전송, 그럼 서버는 헤더보고 우리 안전하다~ 판단하고 해당 url에 담긴 정보를 반환 ㅇ
