2025.03.04
배열
배열(Array)
- 동일한 자료(Data Type)의 묶음
- 연속된 메모리 공간에 값을 저장 및 사용
- heap 영역에 new 연산자를 통해 할당
- 배열의 길이는 최초 선언한 값으로 고정
- 인덱스를 통해 데이터에 접근
1차원 배열 선언 및 초기화
int arr[] = new int [5];
int[] arr1;
int arr2[];
int[] arr3;
arr3 = new int[5];
int[] arr4 = {0, 1, 2, 3};
int[] arr5 = new int[] {0, 1, 2, 3};
- 배열의 이름과 주소 값은 stack에 설정, 배열의 크기만큼은 heap 영역에 할당
- 선언은 stack에 배열의 주소를 보관할 수 있는 공간을 만드는 것
- new 연산자는 heap 영역에 공간을 할당하고 발생한 주소값을 반환하는 연산자
- 발생한 주소를 레퍼런스 변수(참조형 변수)에 저장하고 이것을 참조하여 사용하기 때문에 참조자료형(reference type)이라고 함
- 한번 할당된 배열은 지울 수 없지만, 레퍼런스 변수를 null로 변경하여 더 이상 주소를 참조할 수 없게된 배열은 일정 시간이 지난 후 heap의 old 영역으로 이동하여 GC(가비지컬렉터)가 삭제시킨다.
다차원 배열 선언 및 초기화
int arr[][] = new int [3][4];
int[][] arr1;
int[] arr2[];
iarr1 = new int[3][]; //배열의 크기를 지정해줘야하는 최소 조건
- 서로 같은 길이의 여러 개 배열을 하나로 묶어 관리하는 2차원 배열을 정변배열
- 서로 길이가 같지 않은 여러 개의 배열을 하나로 묶어 관리하는 2차원 배열을 가변배열
배열 선언 시 값의 형태 별 기본값
- 정수 : 0
- 실수 : 0.0
- 논리 : false
- 문자 : \u0000
- 참조 : null
배열의 복사
- 얕은 복사(shallow copy) : stack의 주소값만 복사
- 깊은 복사(deep copy) : heap의 배열에 저장된 값을 복사
얕은 복사
- stack의 주소값만 복사
- 레퍼런스 변수 안에 담긴 주솟값을 새로운 레퍼런스 변수에 복사하는 것
- 두 개의 레퍼런스 변수는 동일한 배열의 주소값
- 내용 수정/변경 시 다른 배열의 값도 변경된 값이 반영된다.
ex) int[] copyArr = originArr;
깊은 복사
- heap의 배열에 저장된 값을 복사
- 새롭게 할당한 힙 영역에 기존 배열의 값을 복사한 후 새롭게 생성된 배열의 주솟값을 넘겨주는 것
- 서로 같은 값을 가지고 있지만, 두 배열은 서로 다른 배열이기에 하나의 배열에 변경을 하더라도 다른 배열에는 영향을 주지 않는다.
깊은 복사를 하는 방법 4가지
int[] originArr = new int[] {1,2,3,4,5};- for문을 이용한 동일한 인덱스의 값 복사
int[] copyArr1 = new int[10];
for (int i = 0; i < originArr.length; i++) {
copyArr1[i] = originArr[i];
}- Object의 clone()을 이용한 복사 : 이전 배열과 같은 배열밖에 만들 수 없다는 특징
int[] copyArr2 = originArr.clone();- System의 arraycopy()를 이용한 복사 : 순수 배열의 복사, 가장 높은 성능
int[] copyArr3 = new int[10];
/* 원본배열, 원본배열에서 복사를 시작할 인덱스, 복사본 배열, 복사본 배열에서 복사가 시작될 위치 인덱스, 복사할 길이 의미를 가진다. */
System.arraycopy(originArr, 0, copyArr3, 3, originArr.length);- Arrays의 copyOf()를 이용한 복사 : 좀 더 유연한 방식, 가장 많이 사용되는 방식
import java.util.Arrays;
/* 시작인덱스부터 원하는 길이만큼만 복사해서 사용 가능 */
int[] copyArr4 = Arrays.copyOf(originArr, 7);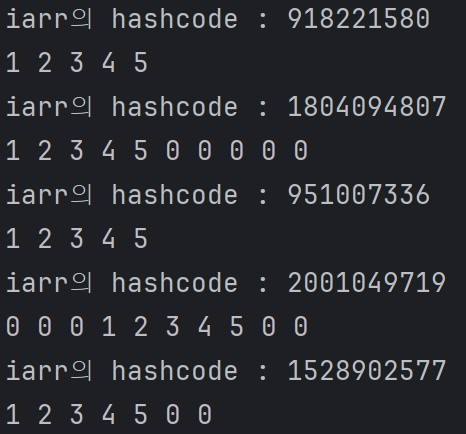
배열의 정렬
순차 정렬 알고리즘
배열의 처음과 끝을 탐색하면서 차순대로 정렬하는 가장 기초적인 정렬 알고리즘
- 가장 간단하고 기본이 되는 알고리즘
선택 정렬 알고리즘
배열을 전부 탐색하여 최솟값을 고르고 왼쪽부터 채워나가는 방식의 정렬
- 데이터 양이 적을 때 좋은 성능
- 100개 이상의 자료에서 급격히 속도 저하
버블 정렬
인접한 두 개의 원소를 검사하여 정렬하는 방법
- 구현이 쉽고, 이미 정렬된 데이터를 정렬할 때 가장 빠름
- 다른 정렬에 비해 속도는 느리고, 역순으로 정렬할 때 가장 느린 속도를 가진다.
삽입 정렬
배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열과 비교하여 자신의 위치에 삽입하여 정렬한다.
- 배열의 두 번째 데이터부터 연산을 시작
- 버블 정렬의 비교 횟수가 많은 단점을 개선
추가
- hashcode() : 일반적으로 객체의 주소값을 10진수로 변환하여 생성한 객체의 고유한 정수값을 반환한다. 동일객체인지 비교할 때 사용할 목적
- equals() : 문자열이 같은지를 비교하는 기능을 제공. 문자열은 == 비교가 불가능.
- length() : String 클래스의 메소드로 문자열의 길이를 int형으로 반환.

잔디 속 새싹 하나