2025.03.06 ~ 03.07
제네릭스, 컬렉션, 예외처리
제네릭스(Generics)
제네릭스
데이터의 타입을 일반화 -> 타입을 매개변수로 사용할 수 있도록 하는 기능
제네릭 클래스는 제네릭 타입(T, E, K, V)을 활용하여 하나의 클래스로 해당 제네릭 타입에 변화를 줘서 제네릭 클래스의 인스턴스(객체)를 다양한 타입을 지닌 인스턴스(객체)로 활용
-
제네릭 타입(T, E, K, V) == 자료형으로 보고 사용
-
T : Type(자료형)
-
E : Element(컬렉션에서 요소를 다룰 때)
-
K, V : Key, Value(맵 자료구조)
-
N : Number(숫자 관련)
접근제한자 class 제네릭스명<제네릭타입>{
private 제네릭타입 변수;
public 제네릭타입 getValue(){
return ;
}
public void setValue(T 변수){
this.변수 = 변수;
}
}제네릭스 인스턴스 생성 > 제네릭스명<> 변수 = new 제네릭스명<생략가능>();
<> 안에 들어갈 수 있는 것
- 클래스 타입
- 래퍼 클래스
- 사용자 정의 클래스
- 인터페이스
- 배열
- 중접 제네틱
- 와일드카드
- 불가능한 타입
- 기본 자료형(int, double, char 등) - 제네릭은 참조형만 허용- Integer.valueOf(10) - valueOF으로 형변환 하여 사용
제네릭스를 사용하는 이유
- 하나의 클래스만 작성해도 여러 타입의 필드 값을 가진 클래스로 변형해서 다룰 수 있어서 구현의 편리함이 있다. -> 컬렉션 같은 자료구조는 기본적으로 Object 타입을 저장하므로 데이터를 꺼낼 때 타입 캐스팅(형변환)이 필요하다.
- 해당 제네릭 클래스의 필드 타입이나 메소드의 매개변수나 반환형을 알고 사용하기 때문에 자료형의 안정성이 높다. -> 특정 타입만 저장 가능 하고 컴파일에서 잘못된 타입 저장을 방지한다.
와일드카드(Wildcard)
메소드의 매개변수로 받을 시 타입을 원하는 만큼으로 제한하는 것
제네릭 클래스 타입을 불특정하게 표현하고 싶을 때 사용함
- : 모든 타입을 허용하는 와일드 카드
- : T 타입 / T의 하위 타입을 허용하는 와일드 카드
- : T 타입 / T의 상위 타입을 허용하는 와일드 카드
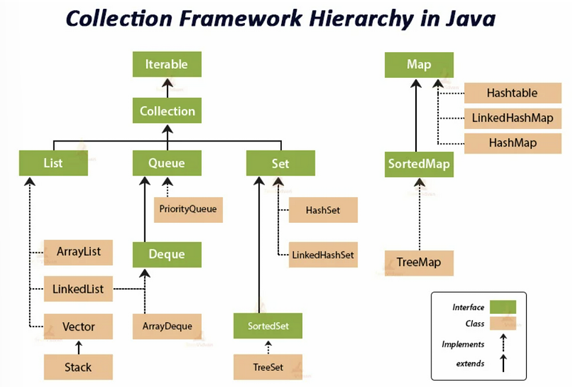
컬렉션(Collection)
컬렉션
많은 데이터들을 효과적으로 처리할 수 있는 방법을 제공하는 클래스들의 집합
컬렉션을 사용하는 이유
- 일관된 API : 컬렉션에서 제공하는 규격화된 메소드를 사용함으로 일관된 사용과 유지보수가 가능
- 프로그래밍 비용 감소 : 이미 제공된 자료구조를 활용하는 것으로 low-level의 알고리즘을 고민할 시간과 노력을 아낄 수 있다.
- 프로그래밍 속도 및 품질 향상
컬렉션의 주요 인터페이스
- List : 순서가 있는 데이터 집합, 데이터의 중복을 허용
- ArrayList, LinkedList, Stack, Queue, Vector - Set : 순서가 없는 데이터 집합, 데이터 중복 허용하지 않음(null도 하나의 null만 저장)
- HashSet, TreeSet, LinkedHashSet - Map<K,V> : 키와 값이 쌍을 이루어 구성되는 데이터 집합, 순서가 없다. 키 중복은 허용하지 않음, 값 중복은 허용
- HashMap, TreeMap, HashTable, Properties
List
-
ArrayList(배열리스트) : 기본 배열보다 느리지만 동적 배열이 구현, 가장 많이 사용되는 컬렉션 클래스
- Object 클래스의 하위 타입 인스턴스를 모두 저장할 수 있다.
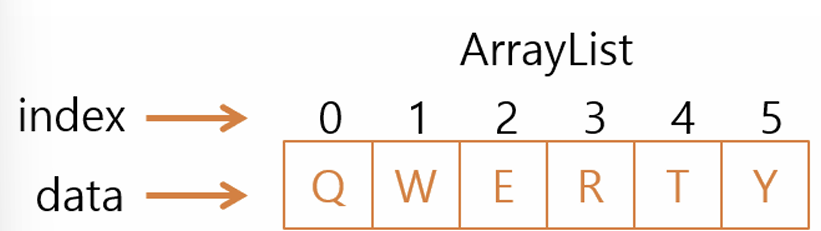
-
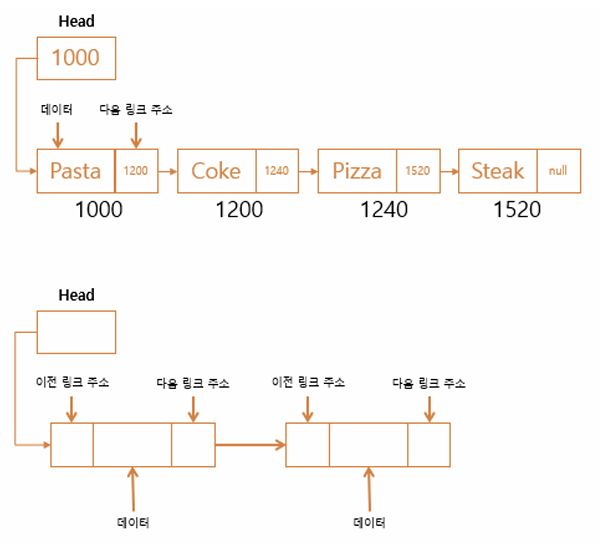
LinkedList(이중 연결리스트) : 연결 리스트를 이용해 데이터 저장, 배열리스트의 단점 보완
-
Stack : 리스트 계열 클래스인 Vector 클래스를 상속받아 구현된 자료구조, LIFO(Last In First Out)
- 스택은 제일 상단(가장 마지막에 들어간게) 상단인덱스 1번이다.
- push()메소드 : stack애 값을 넣을 때
- search(찾을 값) : 스택에서 요소를 찾을 때 순번 출력, 인덱스가 아닌 위에서부터 순번을 의미, 가장 상단의 위치는 0이 아닌 1
- peek() : 해당 스택의 가장 마지막에 있는(상단에 있는) 요소 반환
- pop() : 해당 스택의 가장 마지막에 있는(상단에 있는) 요소 반환 후 제거 -
Queue : 사전적 의미는 줄, FIFO(선입선출), 큐 인터페이스를 상속받는 하위 인터페이스들은 다양하지만 대부분의 큐는 LinkedList를 이용
- Deque, BlockingQueue, BlockingDeque, TransferQueue 등Queue 변수 = new Queue<>(); // 에러
Queue 변수 = new LinkedList<>();- .offer(값) : 큐에 데이터를 넣을 때 - peek() : 해당 큐의 가장 앞에 있는 요소(먼저 들어온 오쇼)를 반환 - poll() : 해당 큐의 가장 앞에 있는 요소(먼저 들어온 요소)를 반환하고 제거 -
Vector
Set
- HashSet : HashMap을 이용하여 만들어짐, 키 값을 이용하여 데이터에 저장/접근, 삽입 삭제가 빈번한 경우 사용, 순서를 관리하지 않음
- 순서 상관없이 들어가 있음
- .contains(값) : 해시 안에 값이 포함되어있는지 확인 - true/false 반환
- iterator()로 목록 만들어 연속 처리 - LinkedHashSet : HashSet과 동일한 구조를 가지지만 HashSet과는 다르게 데이터를 삽입한 순서대로 출력
- 만들어진 LinkedHashSet을 가지고 TreeSet으로 객체를 생성하면 같은 타입의 객체를 자동으로 비교하여 오름차순으로 정렬 - TreeSet : 중복 데이터 저장하지 않고 저장 순서를 유지하지 않는다.
- 데이터가 정렬된 상태로 저장되는 이진 컴색 트리의 형태로 요소를 저장한다.
- 데이터를 추가하거나 제거하는 등의 기본 동작 시간이 매우 빠르다.
- Set 인터페이스가 가지는 특징을 그대로 가지지만 정렬된 상태를 유지하는 것이 다른 점
List와 Set의 공통인 Collection 인터페이스 주요 메소드
- add(인덱스, "값") : 인덱스 위치에 추가, 인덱스를 안 적으면 순서대로 뒤에 추가 된다.
- clear() : 리스트 비우기
- contains()
- equals()
- isEmpty() : 리스트가 다 비워져있나? - true/false
- iterator() : 반복자
- remove(인덱스) : 삭제할 인덱스
- size() : 배열의 크기가 아닌 요소의 갯수 반환
- toArray()
Map<K,V>
실제 데이터를 찾기 위한 역할
- HashMap : Map 인터페이스를 구현하고 있는 클래스 중에서 가장 자주 쓰이는 클래스
- 저장은 느리지만 Hashing이라는 해시 함수를 이용하여 테이블에 저장하기 때문에 검색 측면에서 뛰어나다.
- 중복된 키 값에 값을 저장하면 기존의 값에 새로운 값이 덮어 씌어진다.(override)
- 해시맵변수.put(키,값) : 처음 저장
- .get(키값) : 키 값 객체의 내용을 가져올 때
- .remove(키값) : 키 값을 가지고 삭제 처리할 때
- .size() : 저장된 객체 수 확인
- .keySet() : keySet()을 이용해서 키만 따로 set으로 만들고, iterator()로 키에 대한 목록 만듦
- .values() : 저장된 value객체들만 values()로 Collection으로 만듦 -> Iterator()로 목록, 배열로 만들어서 처리
- entrySet() : Map의 내부클래스인 EntrySet을 이용
- Entry : 키 객체와 값 객체를 쌍으로 묶은 것 - Properties : Hashtable 을 상속 받아 구현한 것
- (Object, Object) 의 형태로 저장하는 해시 테이블과 달리 (String, String) 형태로 저장 -> 문자열만 사용 가능
- 주로 환경 설정과 관련된 속성을 저장하는데 사용
- .store() : 파일 생성해서 다른곳에 내보내기
- .load() : 다른 곳에서 파일 가져오기
- getProperty(키값) : Properties 클래스에서 특정 키에 대한 값을 가져오는 메서드
Iterator(반복자)
Collection 인터페이스의 iterator() 메소드를 이용해서 인스턴스를 생성할 수 있다.
- 반복문을 이용해서 목록을 하나씩 꺼내는 방식으로 사용하기 위함(주로 while)
- 컬렉션에서 값을 읽어오는 방식을 통일된 방식으로 제공하기 위해
- 인덱스로 관리되는 컬렉션이 아닌 경우에는 반복문을 사용해서 요소에 하나씩 접근할 수 없기 때문에 인덱스를 사용하지 않고도 반복문을 사용하기 위한 목록을 만들어주는 역할이라고 보면 된다.
- hasNext() : 다음 요소를 가지고 있는 경우 true, 더 이상 요소가 없는 경우 false를 반환 -> iterator()와 hasNext()를 같이 쓰는 경우 한번 꺼내면 다시 쓸 수 없다.
- next() : 다음 요소를 반환
예외처리
예외(Exception)
- 오류(Error) : 시스템 상에서 프로그램에 심각한 문제가 발생하여 실행중인 프로그램이 종료되는 것, 개발자가 미리 예측하거나 코드로 처리하는 것이 불가능 한 경우
- 예외: 오류와 마찬가지로 실행중인 프로그램을 종료시키는 것이 일반적이지만 발생할 수 있는 상황을 개발자가 미리 예측하고 처리할 수 있는 미약한 오류
예외 클래스의 종류
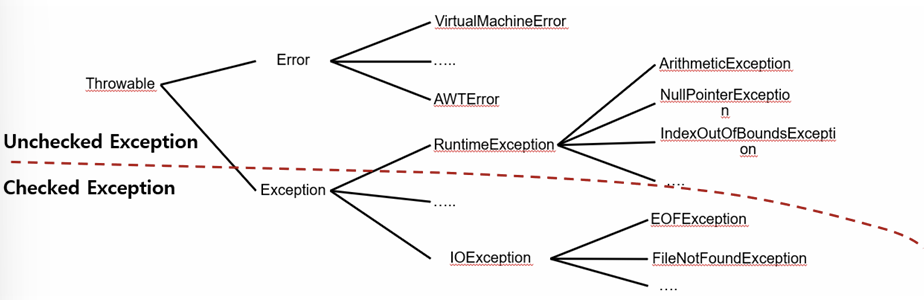
- 오류와 예외는 모두 Throwable을 상속 받음
- 예외의 최상위 클래스는 Exception 클래스
- Unchecked Exception 계열은 기본적 이미 처리되어 있고 실행 중인 프로그램이 종료되게 작성
- Chekced Exception 계열은 반드시 예외 처리를 해야 하고 하지 않으면 컴파일 에러 발생
- RuntimeException타입의 예외들은 런타임 시점에 해당 예외 클래스 타입의 Exception이 발생
RuntimeExcpetion 후손 클래스 몇 가지
- ArithmeticException : 0으로 나누는 경우 발생
- ArrayIndexOutOfBoundsException : 배열의 index범위를 넘어서 참조하는 경우 발생
- NullPointerException : 인스턴스가 참조되지 않은 상태(Null)로 인스턴스에 접근하는 경우 발생
- ClassCastException : 형변환(Cast연산자 사용) 시 자료형에 문제가 있을 때 발생
예외 처리 방법
-
throws로 위임 : Exception이 발생하는 메소드(또는 생성자)를 호출한 상위 메소드에게 처리를 위임하는 방식
throw new 예외클래스명();
-
try_catch_finally 사용 시 위에서 부터 아래 순서로 적용 되므로 상위(부모) 예외가 위에 오면 안된다.
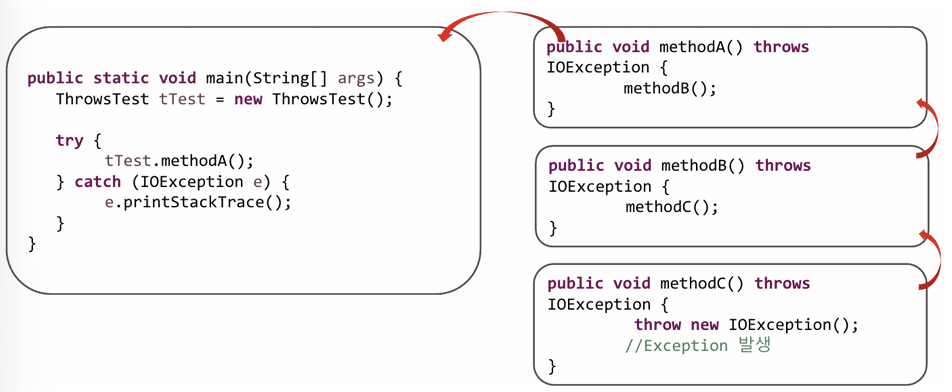
- try-catch(또는 try-catch-finally)로 처리 : 발생한 Exception을 직접 처리하는 방식

- .getClass() : 발생한 예외클래스의 이름을 알 수 있다.
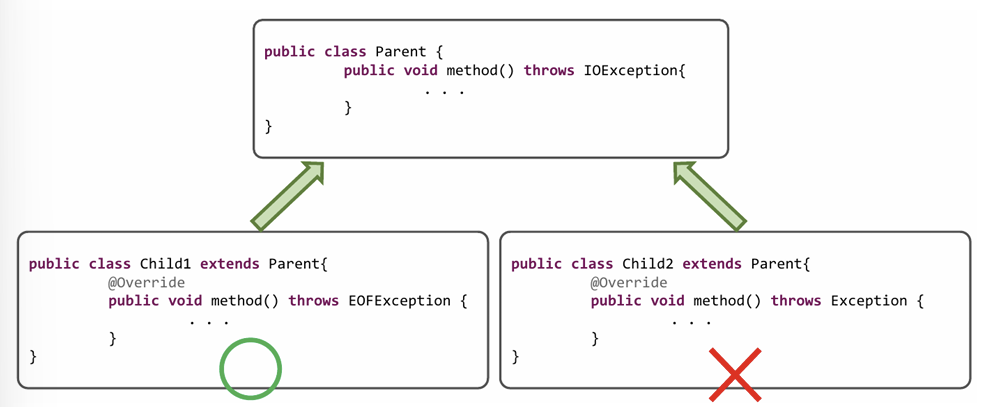
오버라이딩 시 예외 발생 가능 범위
상속 시 오버라이딩하는 메소드는 부모 클래스의 원본 메소드보다 더 상위 타입의 예외를 발생 시키면 안된다
사용자 정의의 예외클래스
extends Exception으로 예외처리 클래스를 상속받아 더 구체적인 예외 이름을 정의하는 것
참고
sort()메소드 : list가 오름차순 정렬 처리 된 후 정렬 상태가 유지
