
읽기 전
독자님의 시간을 아끼기 위해 결과를 먼저 작성합니다.
문제 정의 단계의 오류로 성공하지 못한 실험 이야기입니다.
그럼에도 나름의 가설 수립 과정, 실험 설계, 오류에서 배운 점을 담았으니 참고 부탁드립니다 🙇♀️
배경
기능 설명
⏰ 사용자가 N(5 ≤ N ≤ 30, N은 5의 배수)분 후에 특정 로직 실행 예약
현재, 예약 요청이 들어오면 그 즉시 TaskScheduler에 등록하는 방식이다.
그런데 여기서 문제가 예약된 작업 수를 제한할 수 없다는 문제가 있다.
Spring TaskScheduler는 기본적으로 ThreadPoolTaskScheduler를 사용하는데, 이는 Java의 ScheduledThreadPoolExecutor을 기반으로 동작한다.
⛔ ThreadPoolTaskScheduler를 사용하면 Core Pool Size는 조절할 수 있지만 Queue Capacity는 조절할 수 없다.
- 스케줄링의 본질은 "정해진 시각에 실행하는 것"
- 큐가 거부하면 시간 맞춰 실행 불가 → 기본은 무제한 우선순위 큐 + 예외 없음 설정이 디폴트
ScheduledThreadPoolExecutor

그래서, ThreadPoolTaskScheduler를 사용한 예약 작업은 무제한 큐를 사용하기 때문에 불필요한 메모리 사용을 방지하고자 '1분 이내 작업 스케줄링' 방식과 메모리 사용량을 비교해보고자 한다.
- 1분 이내 작업 스케줄링: 매 분 DB에서 1분 이내 실행될 작업만 조회해 스케줄러에 등록
가설
먼저 heap 메모리에 등장하는 Eden Space, Survivor Space, Old Gen도 알아보고 넘어가자 🤔
| 영역 | 설명 |
|---|---|
| Eden Space | 새 객체 할당 |
| Survivor Space | Minor GC 후 생존 객체 보관 |
| Old Gen | 장수 객체 보관 (Major GC 대상) |
힙 영역은 Young Generation, Old Generation으로 구분된다.
Old Gen는 이름 그대로 Old Generation에 속하고, 이 중에서 Eden Space와 Survivor Space을 합쳐 Young Generation이라고 한다. Young Generation에서 발생하는 GC를 Minor GC, Old Generation에서 발생하는 GC를 Major GC라고 부른다.
GC에 대해서는 잘 모르지만, Minor GC보다 Major GC의 비용이 더 크기 때문에 가능한 Minor GC로 heap을 유지하는 게 좋다고 한다.
Major GC는 Heap 메모리가 모두 찼을 때 발동되기 때문에, Major GC는 최대한 발동되지 않고 Minor GC가 많이 발동되도록 하는 것이 순리상 맞다. 즉 생명 주기가 짧은 젊은 객체는 Old Generation으로 올라가기 전에 Young Generation에서 제거 되게끔 하고 오래된 객체의 경우 Old Generation에 상주시켜 상대적으로 아주 저렴한 Minor Garbage Collection 만으로 heap의 유지가 가능하게 유도하는 것이 좋다.
Weekly Java: 트래픽이 많이 몰리는 이벤트가 예정되어 있을 때, Young Gen과 Old Gen의 비율 고민하기
위 내용을 바탕으로, 그리고 뇌피셜을 바탕으로 아래 가설을 세웠다.
1번 방식(기존 스케줄링): 실행까지 오래 남은 작업들을 모두 스케줄러에 등록
2번 방식(1분 미만 스케줄링): 실행까지 얼마 남지 않은 작업들만 스케줄러에 등록
- 1번 방식보다 2번 방식이 메모리 사용량이 낮을 것이다.
- 1번 방식은 더 많은 작업이 메모리에 올라가기 때문에 메모리 사용량이 더 높을 것이다.
- 1번 방식보다 2번 방식이 Old Gen 사용량이 낮을 것이다.
- 2번 방식은 메모리에 올리고 얼마 뒤에 소멸할 것이기 때문에 짧은 생명주기를 가질 것이다.
테스트 환경
- Spring Boot 3.1
- Java 17
- JMeter: HTTP 동시 요청
- 4,000명의 사용자가 3번씩 요청 ⇒ 12,000개
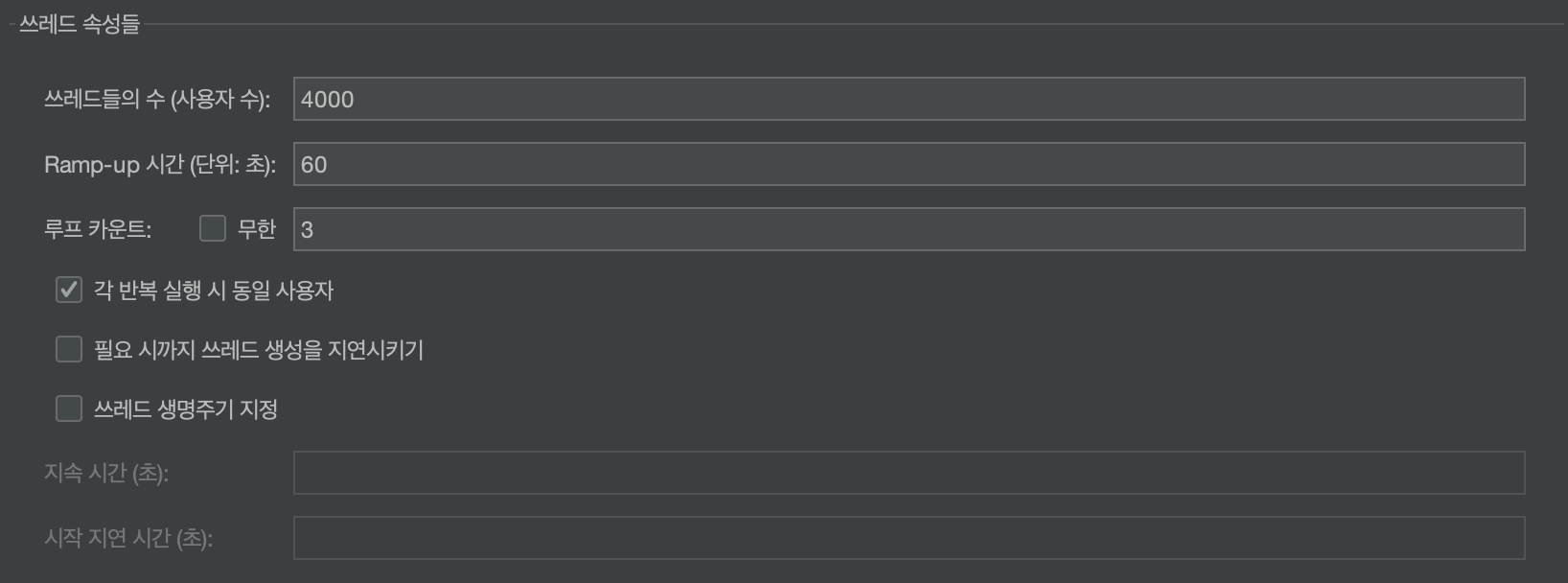
- 4,000명의 사용자가 3번씩 요청 ⇒ 12,000개
- Prometheus: 메모리 사용량 확인
- 스케줄링 스레드풀 : 10
비교
1. 메모리 사용량 (total heap)
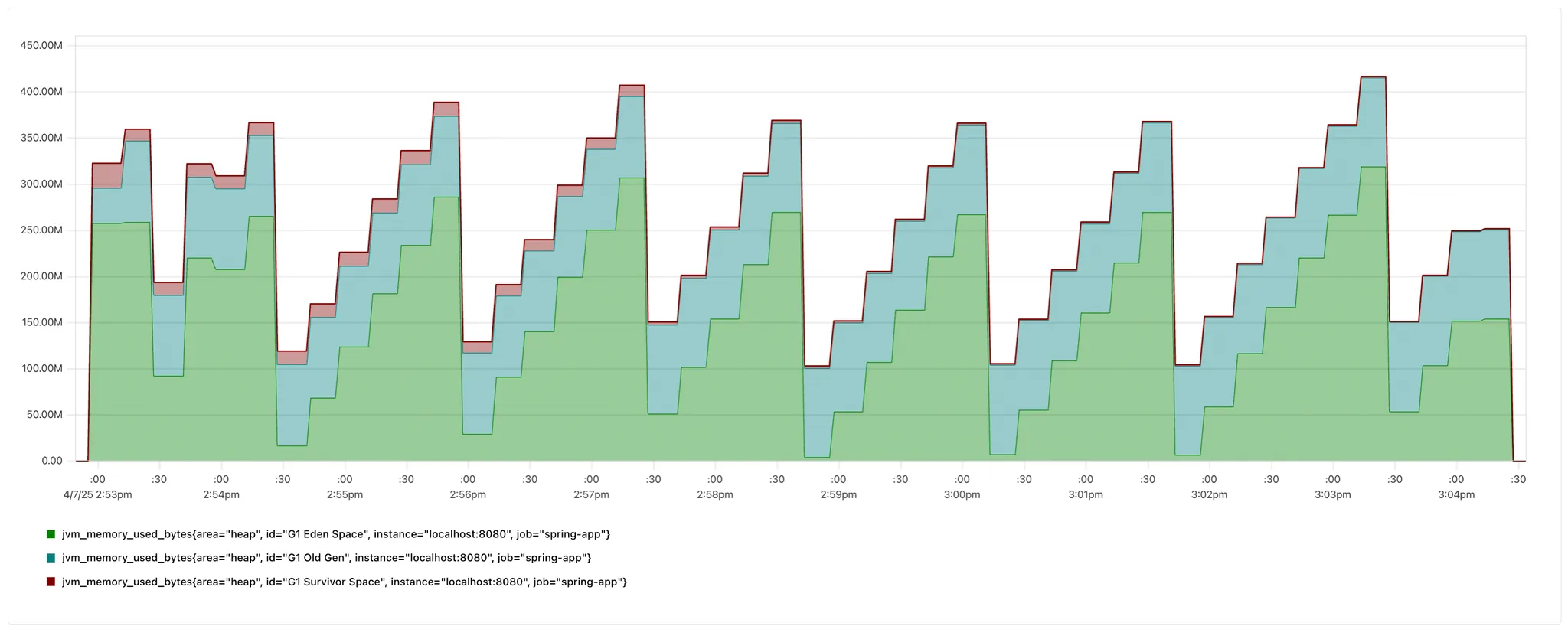
- 기존 스케줄링
- 1분 미만 스케줄링
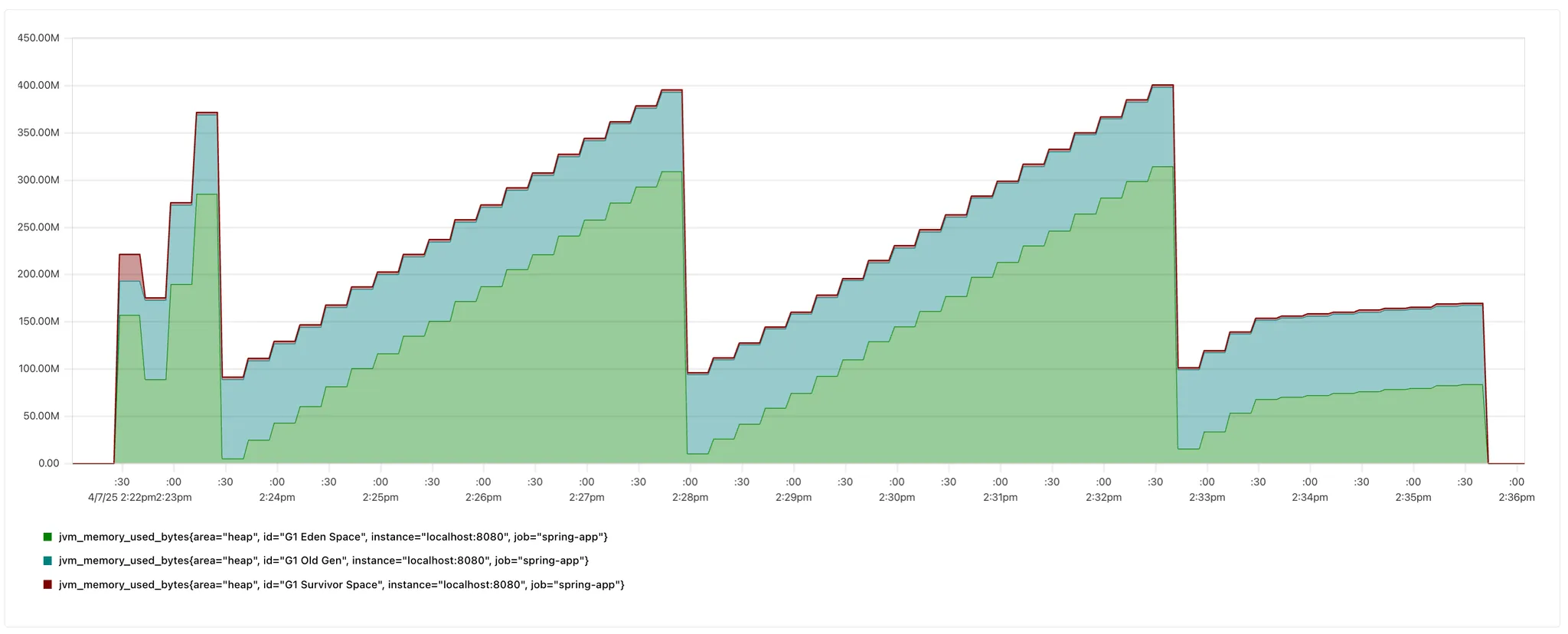
| 구분 | 기존 스케줄링(상) | 1분 미만 스케줄링(하) |
|---|---|---|
| 피크 메모리 | ~420 MB | ~400 MB |
| GC 후 최소 메모리 | ~100–150 MB | ~100 MB |
| 회복 속도 | ~1.5분 | ~4.5분 |
지표를 비교해보자
포인트는 2가지이다.
- GC 이후 메모리 사용량
중간 중간 메모리 사용량이 급감하는 구간이 있는데, 이는 GC의 흔적이다.
두 그래프를 비교해보면 개선 전(100MB-150MB)보다 개선 후 GC 이후(100MB) 메모리 사용량이 더 적어진 것을 확인할 수 있다.
이는 Survivor Space에 넘어가는 객체가 줄어들었다는 의미이다.
- 메모리 사용량 느리게 회복
GC 발생 이후 기존 스케줄링은 짧은 시간 내에 메모리를 빠르게 회복시키는 반면, 1분 미만 스케줄링은 회복 시간이 길어 상대적으로 완만한 회복 곡선을 보인다.
여기서 빠른 회복이라는 의미는 필요한 메모리 요청에 즉각적으로 응답할 수 있도록 회수된 메모리가 신속하게 재할당한다는 것으로 이해하면 되겠다.
개인적인 분석은 아래와 같다.
일반 스케줄링은 단순히 당장 필요한 작업뿐만 아니라 미래에 예약된 작업까지 메모리 할당을 빠르게 진행하기에 빠른 회복 동향을 보이며,
1분 미만 스케줄링은 즉각적인 작업만 메모리에 할당하여 메모리 회복이 점진적으로 이루어지며 피크 수치도 상대적으로 낮게 유지된다.
2. 메모리 사용량 (Young Gen)
- 기존 스케줄링
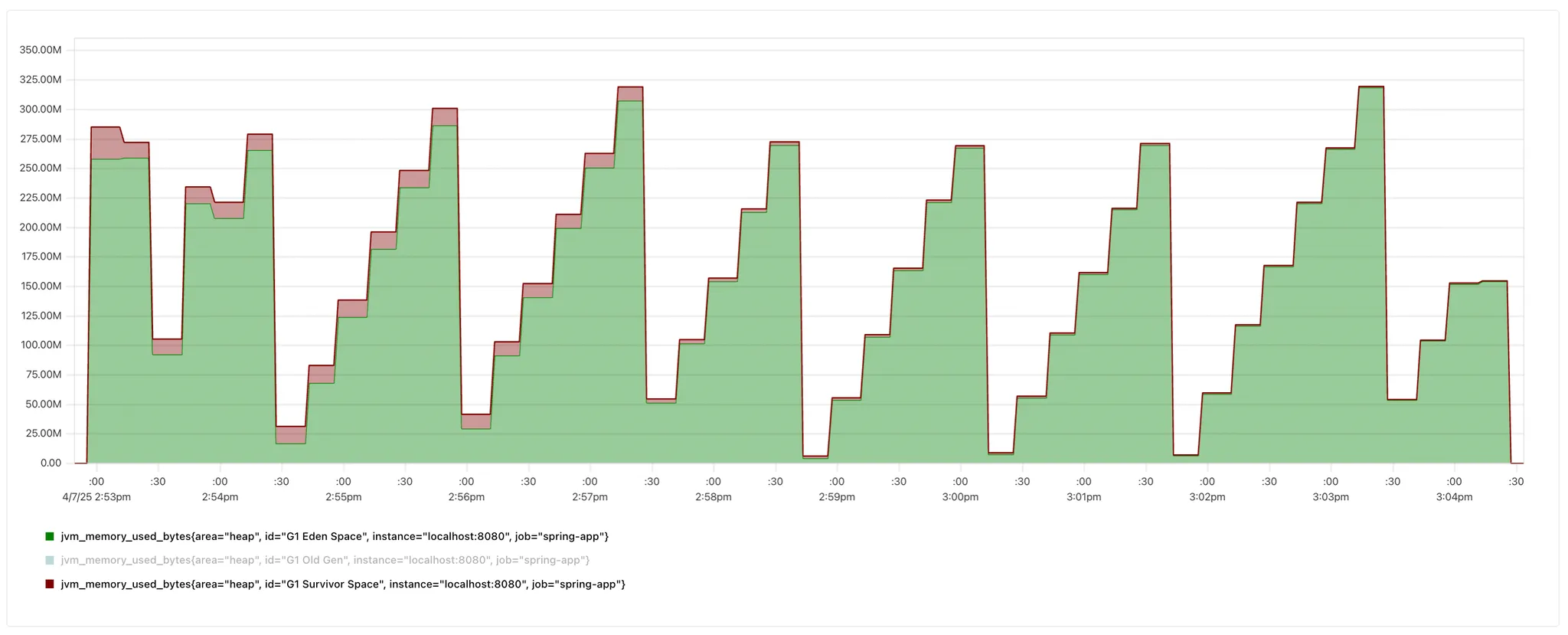
- 1분 미만 스케줄링
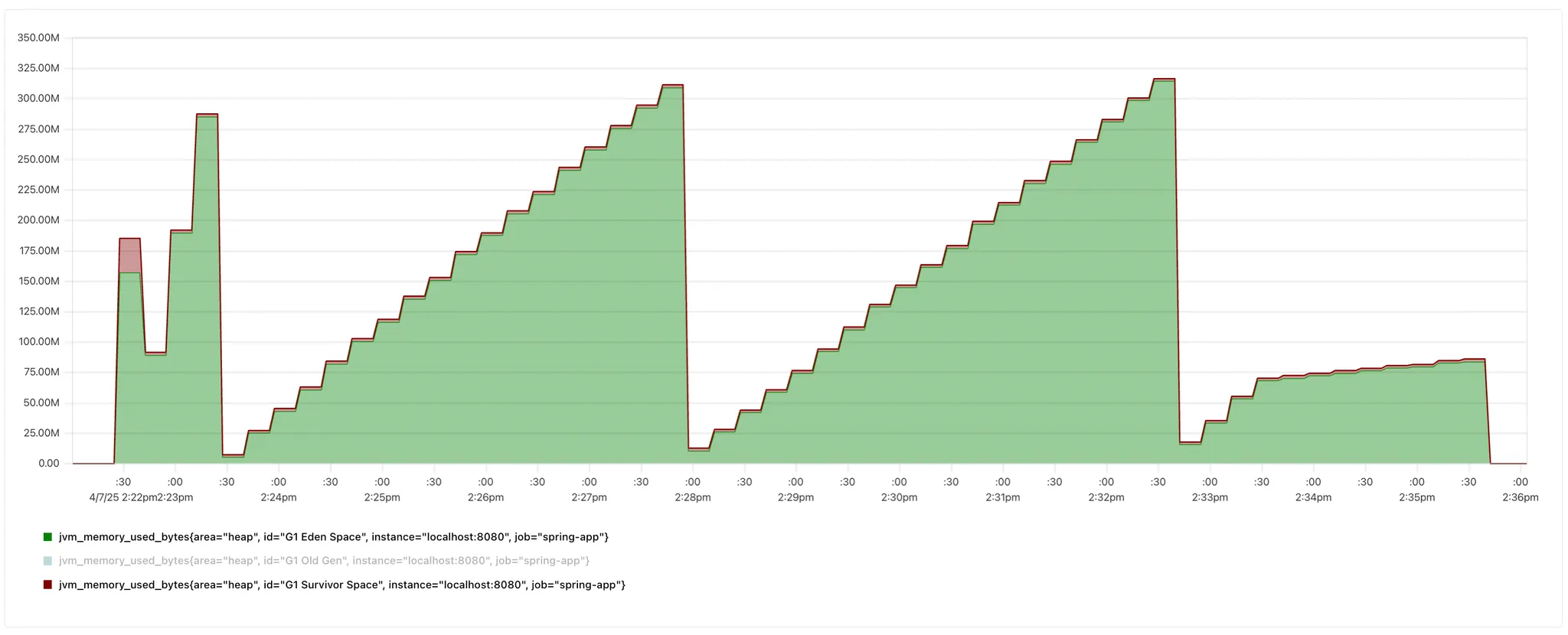
Survivor Space 감소
빨간색 지표가 Survivor Space이다. 기존 스케줄링의 경우 survivor space는 약 30MB이며 이후 감소 추세를 보인다. 1분 미만 스케줄링 또한 초반에는 30MB정도의 survivor space를 사용하지만 그 이후 해당 면적이 눈에 띄게 작아진 것을 확인할 수 있다.
이는 새로운 객체가 저장되는 Eden Space에서 Survivor Space로 넘어가는 객체가 줄었다는 것을 의미한다.
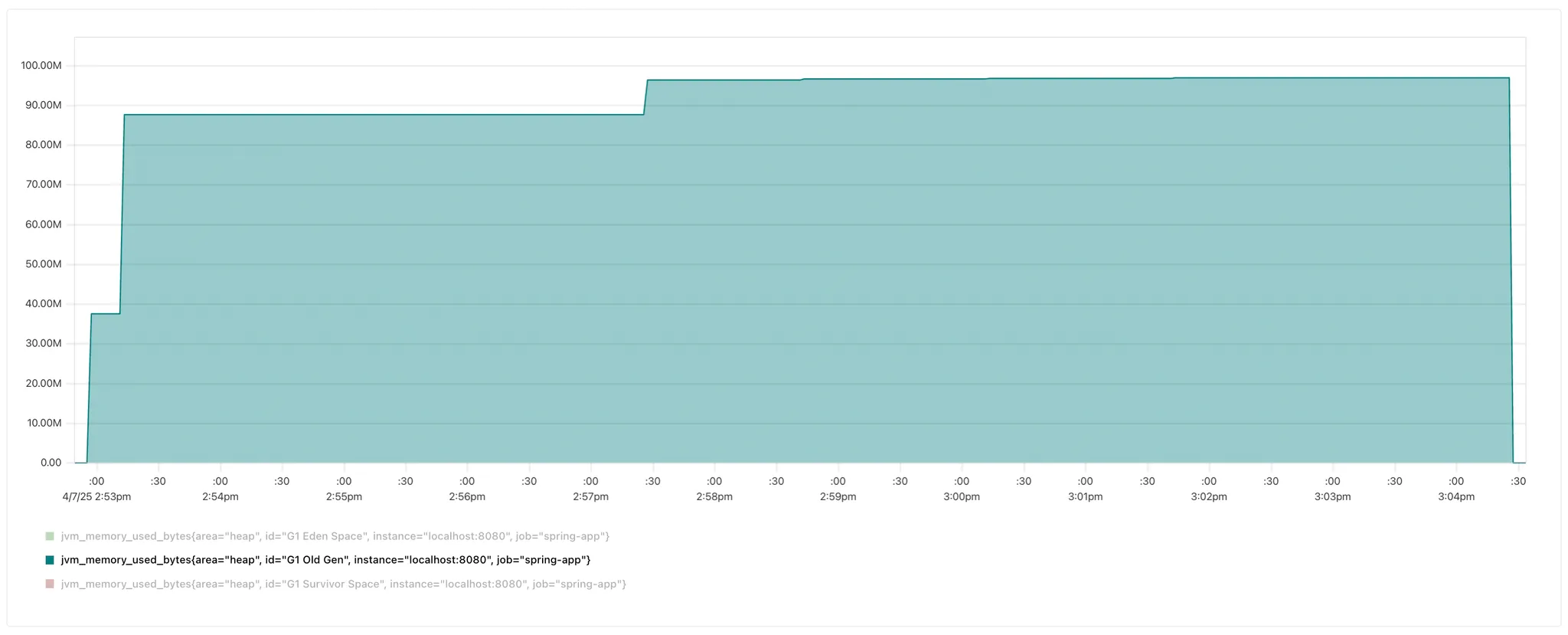
3. 메모리 사용량 (Old Gen)
가설에서 Old Gen이 감소했을 것이라 생각했으니 이번엔 Old Gen 사용량만 따로 확인해보자.
- 기존 스케줄링
- 1분 미만 스케줄링
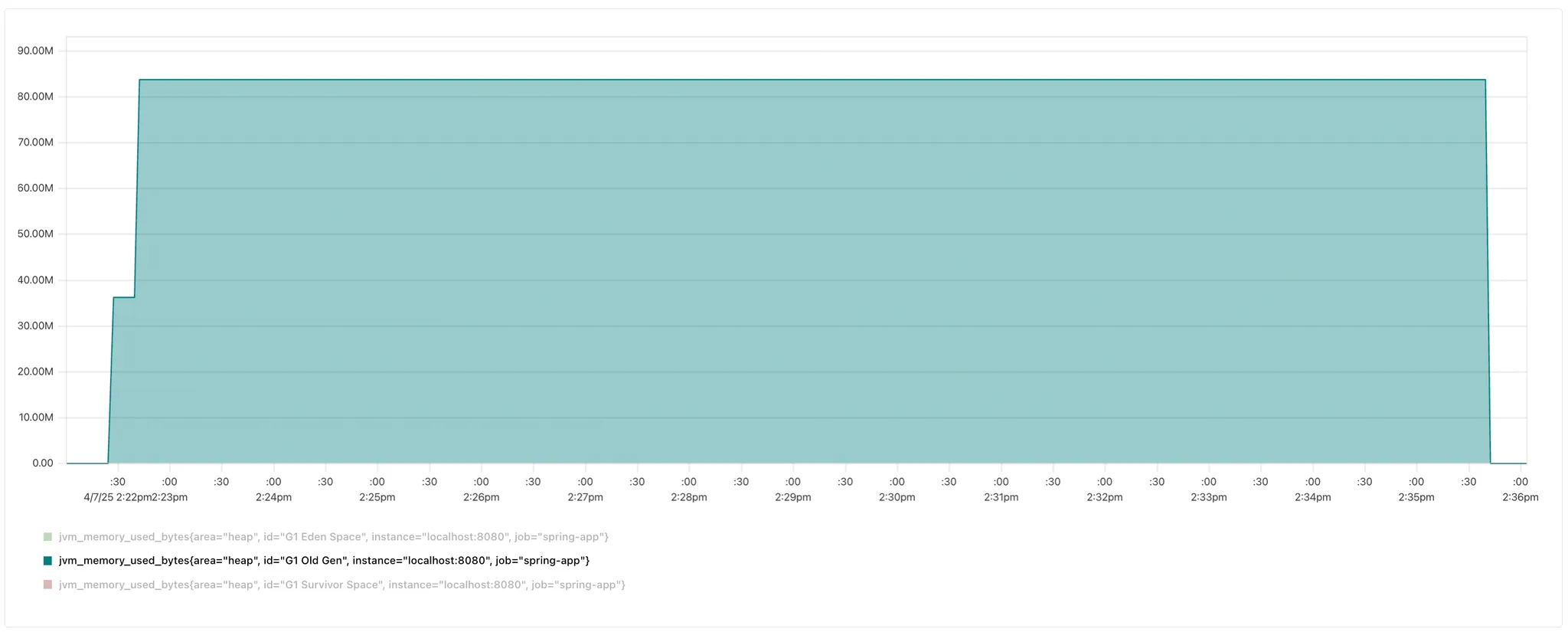
Old Gen 감소
가설대로(?) Old Gen이 아주 조금 감소했다. (세로축.. 잘 보이시나요🥲 ?)
기존 스케줄링의 경우 95MB 이상 유지하는 것을 확인할 수 있지만, 1분 미만 스케줄링의 경우 약 83MB를 유지한다.
4. GC 누적 정지 시간
- 기존 스케줄링
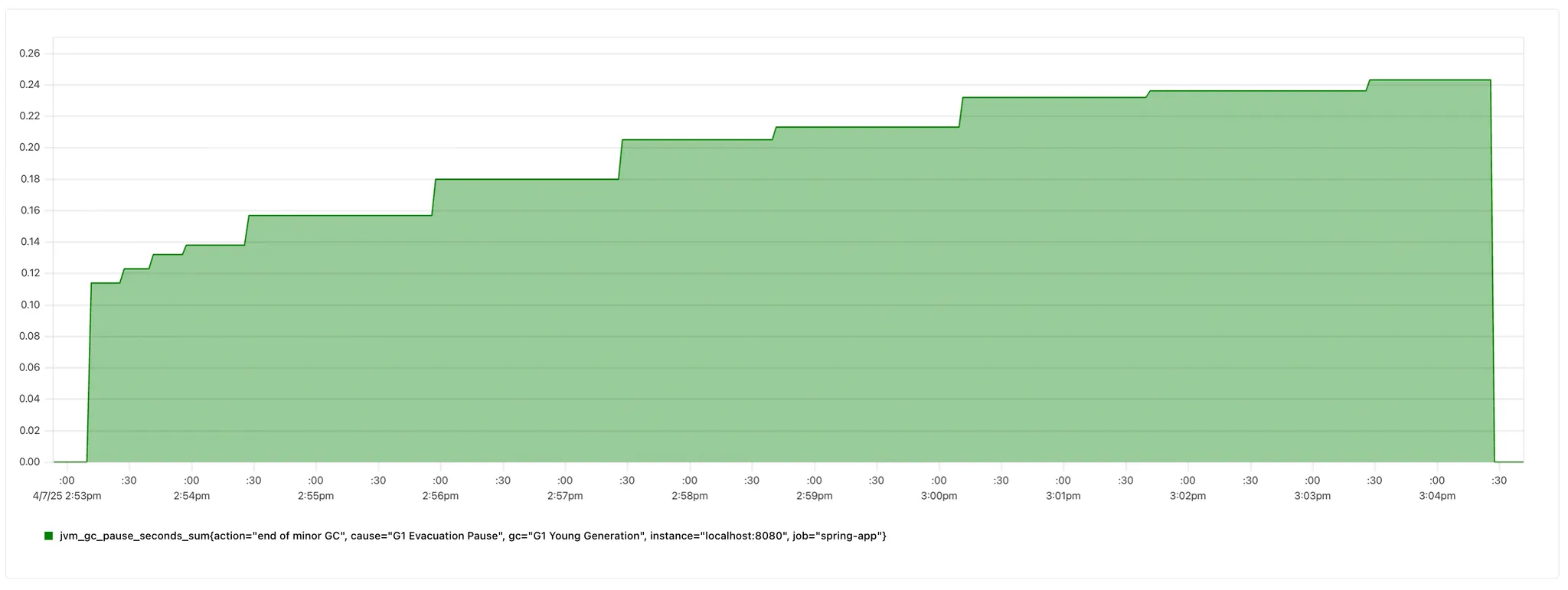
- 1분 미만 스케줄링
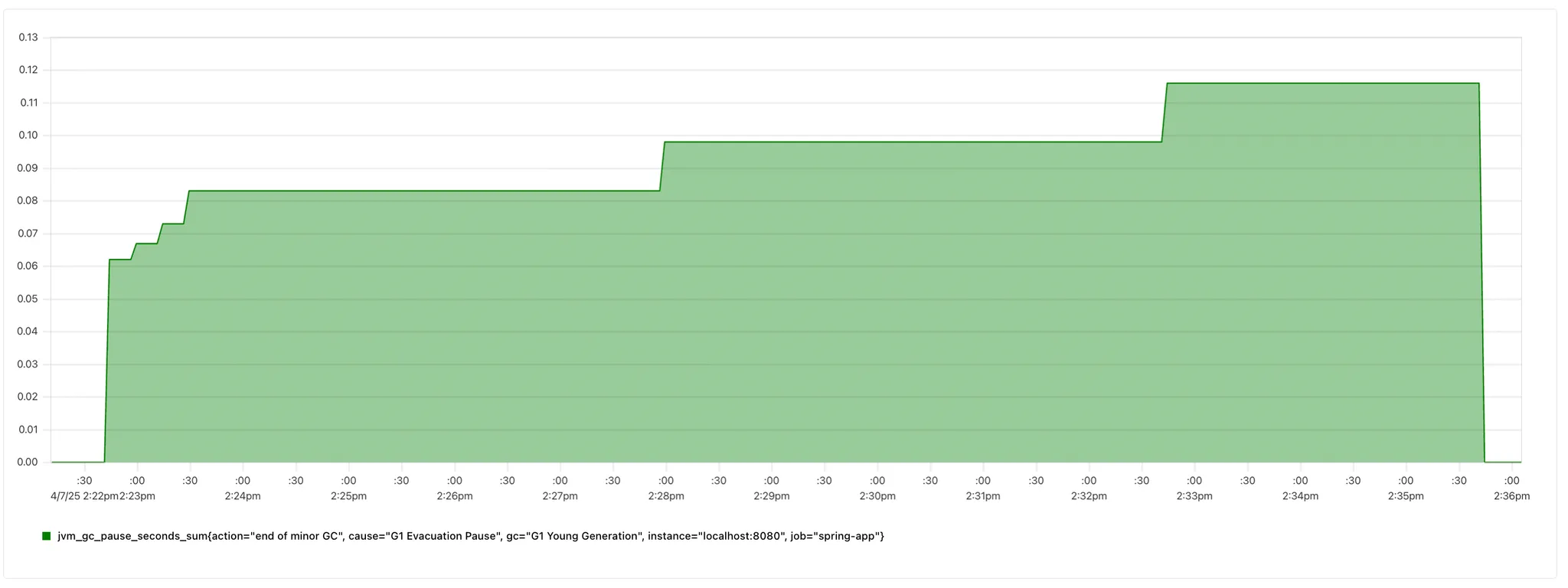
| 항목 | 기존 스케줄링 (상) | 1분 미만 스케줄링 (하) |
|---|---|---|
| 초기 정지 시간 | 약 0.18초 | 약 0.06초 |
| 10분 후 누적 정지 시간 | 약 0.24초 | 약 0.1초 |
| GC 발생 횟수(상승 지점) | 11회 | 6회 |
GC 관련 지표는 생각보다 차이가 있었다.
1번 방법에 비해 더 짧은 시간 정지하며, GC 발생 횟수도 약 1/2회로 줄었다.
결론
테스트 결과를 바탕으로 가설을 검증해보자
1번 방식보다 2번 방식이 메모리 사용량이 낮을 것이다. 🔺
사실 이번 테스트에서 메모리 사용량이 낮아졌다는 결과를 도출하기는 어려웠다. Survivor Space와 Old Gen이 감소하긴 했지만, 미래 작업까지 모두 메모리에 올라감으로써 몇 배는 높은 메모리를 사용할 것이라 예측한 것에 비해서는 미세한 차이다.
1번 방식보다 2번 방식이 Old Gen 사용량이 낮을 것이다. ⭕️
위 가설에 부합하는 결과를 확인할 수 있었다.
Young Gen 메모리 사용량은 두 스케줄링 방식에서 비슷하여 단기 객체 처리 성능에는 큰 차이가 없으나, Old Gen에서는 1분 미만 스케줄링이 미세하게 사용량이 적은 것으로 판단했다.
추가적으로
GC의 정지 시간까지 비교해본 결과, 1분 미만 스케줄링 방식이 일반 스케줄링 방식에 비해 GC 발생 횟수가 절반으로 감소했으며 누적 정지 시간도 더 낮음을 확인했다.
그럼에도 해당 수치가 서비스에 영향을 미치는 정도는 아니라는 생각이 들었다.
추후 알아본 내용으로는, 스케줄링에 등록하는 작업이 실행 코드 참조만 가지는 Runnable 객체로 상당히 가볍기 때문에 작업 개수가 많아도 메모리 사용량이 크게 변하지 않는다고 한다.
사실상 이미 최적화된 스케줄러였기 때문에 이번 실험은 성공적이지 못하다고 보면 되겠다

끝맺음
먼저 이번 실험을 통해 문제를 명확하게 정의하는 것이 중요하다는 것을 느꼈다.
문제 '예방'에 초점을 두고 '정말 문제인가'를 간과했던 것 같다.
무제한 큐에 모든 작업을 저장하는 방식이 정말 해결해야 하는 문제인지 고민하지 못했다.
작업 당 어느 정도의 메모리를 사용하고 몇 개의 작업이 얼마나 오래 유지되어야 문제가 되는지 생각했어야 한다. 그리고 가설을 세우기 전, 어떤 데이터가 어떤 형태로 스케줄러에 적재되는지 이해했어야 한다.
다음에는 문제를 예방하든, 문제를 해결하든 '무엇이 문제인가', '왜 문제인가', '정말 문제인가'를 새기고 들어가야겠다.
그럼에도 heap 메모리의 구조와 GC 종류에 대해서도 알아가는 기회가 되었다.
그리고 이런 실험이 처음인지라, 테스트 환경과 관련해서 GPT에게 의존적인 부분이 많았다. 처음에 1,000건으로 테스트를 진행했을 때는 일관된 결과가 나오지 않았으며 육안으로 확인하기 어려운 수치였다. 이후 10,000건 이상을 테스트하면서 육안으로 확인할 수 있는 수치가 나왔는데, 사실 요청 수 외에도 조절해야 하는 변수들이 있지 않을까 생각한다.
가설을 검증하기 위해 어떤 변수들을 통제해야 하는지, 그리고 측정 기간은 얼마나 잡아야 하는지 계속 탐구해보겠다.
혹시 테스트 과정이나 해석에서 오류가 있다면 알려주시면 감사하겠습니다 :)

새로운 걸 많이 배워가요!
기능 설명에서 궁금한게 있어요!
1. DB 기반 스케줄링. 매분 0초마다 DB에서 현재 실행해야하는 데이터 조회 후 실행
2.TaskScheduler 도입
3. DB 기반 1분 내 실행 작업 스케줄링
위 3가지 방법으로 시도를 하셨는데, 제가 이해한 바로는
1번 : @Scheduled, 2번 : TaskScheduler, 3번 : @Scheduled + DB 예약 데이터 비교
이렇게 진행하신게 맞을까요?? 아님 DB의 스케줄러를 사용하신건지 궁금해요 ㅎㅎ