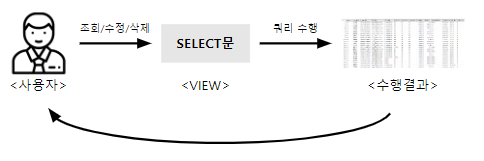
🔍 VIEW
-
논리적 가상 테이블
-> 테이블 모양을 하고는 있지만, 실제로 값을 저장하고 있진 않음. -
SELECT문의 실행 결과(RESULT SET)를 저장하는 객체
VIEW 사용 목적
1) 복잡한 SELECT문을 쉽게 재사용하기 위해.
2) 테이블의 진짜 모습을 감출 수 있어 보안상 유리.
VIEW 사용 시 주의 사항
-
1) 가상의 테이블(실체 X)이기 때문에 ALTER 구문 사용 불가.
-
2) VIEW를 이용한 DML(INSERT,UPDATE,DELETE)이 가능한 경우도 있지만
-
제약이 많이 따르기 때문에 조회(SELECT) 용도로 대부분 사용.
VIEW 옵션
1) OR REPLACE 옵션 :
기존에 동일한 이름의 VIEW가 존재하면 이를 변경
없으면 새로 생성
2) FORCE | NOFORCE 옵션 :
FORCE : 서브쿼리에 사용된 테이블이 존재하지 않아도 뷰 생성
NOFORCE(기본값): 서브쿼리에 사용된 테이블이 존재해야만 뷰 생성
3) 컬럼 별칭 옵션 : 조회되는 VIEW의 컬럼명을 지정
4) WITH CHECK OPTION 옵션 :
옵션을 지정한 컬럼의 값을 수정 불가능하게 함.
5) WITH READ OLNY 옵션 :
뷰에 대해 SELECT만 가능하도록 지정.
VIEW 작성법
CREATE [OR REPLACE][FORCE | NOFORCE] VIEW 뷰이름 [컬럼 별칭]
AS 서브쿼리(SELECT문)
[WITH CHECK OPTION][WITH READ OLNY];
⭐️ VIEW를 생성하기 위해서는 권한이 필요하다
🔍 SEQUENCE
순차적으로 정수 값을 자동으로 생성하는 객체로 자동 번호 발생기 역할을 함
SEQUENCE 왜 사용할까??
PRIMARY KEY(기본키) : 테이블 내 각 행을 구별하는 식별자 역할
NOT NULL + UNIQUE의 의미를 가짐
⭐️ PK가 지정된 컬럼에 삽입될 값을 생성할 때 SEQUENCE를 이용하면 좋다!
[작성법]
CREATE SEQUENCE 시퀀스이름
- [STRAT WITH 숫자] -- 처음 발생시킬 시작값 지정, 생략하면 자동 1이 기본
- [INCREMENT BY 숫자] -- 다음 값에 대한 증가치, 생략하면 자동 1이 기본
- [MAXVALUE 숫자 | NOMAXVALUE] -- 발생시킬 최대값 지정 (10의 27승 -1)
- [MINVALUE 숫자 | NOMINVALUE] -- 최소값 지정 (-10의 26승)
- [CYCLE | NOCYCLE] -- 값 순환 여부 지정
[CACHE 바이트크기 | NOCACHE] -- 캐쉬메모리 기본값은 20바이트, 최소값은 2바이트
시퀀스의 캐시 메모리는 할당된 크기만큼 미리 다음 값들을 생성해 저장해둠
--> 시퀀스 호출 시 미리 저장되어진 값들을 가져와 반환하므로
매번 시퀀스를 생성해서 반환하는 것보다 DB속도가 향상됨.
사용법
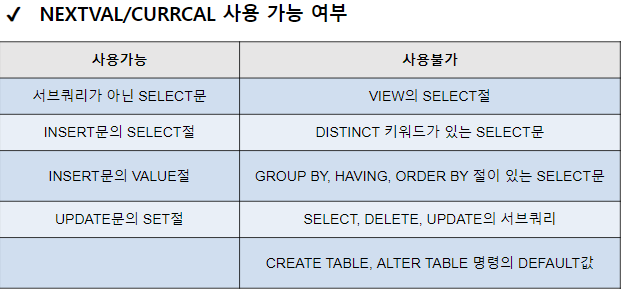
1) 시퀀스명.NEXTVAL : 다음 시퀀스 번호를 얻어옴.
(INCREMENT BY 만큼 증가된 수)
단, 생성 후 처음 호출된 시퀀스인 경우
START WITH에 작성된 값이 반환됨.
2) 시퀀스명.CURRVAL : 현재 시퀀스 번호를 얻어옴.
단, 시퀀스가 생성 되자마자 호출할 경우 오류 발생.
== 마지막으로 호출한 NEXTVAL 값을 반환
⭐️시퀀스 수정 시 CREATE에 사용한 옵션을 변경 가능
단 START WITH 값 변경은 불가하기 때문에 변경하려면 삭제 후 다시 생성해야 함
🔍 INDEX
- SQL 구문 중 SELECT 처리 속도를 향상 시키기 위해
컬럼에 대하여 생성하는 객체 - 인덱스 내부 구조는 B* 트리 형식으로 되어있음.
INDEX의 장점
- 이진 트리 형식으로 구성되어 자동 정렬 및 검색 속도 증가
- 조회 시 테이블의 전체 내용을 확인하며 조회하는 것이 아닌
인덱스가 지정된 컬럼만을 이용해서 조회하기 때문에
시스템의 부하가 낮아짐.
INDEX의 단점
- 데이터 변경(INSERT,UPDATE,DELETE) 작업 시
이진 트리 구조에 변형이 일어남
-> DML 작업이 빈번한 경우 시스템 부하가 늘어 성능이 저하됨.- 인덱스도 하나의 객체이다 보니 별도 저장공간이 필요(메모리 소비)
- 인덱스 생성 시간이 필요함.
INDEX 종류
-
고유 인덱스(UNIQUE INDEX)
중복 값이 포함될 수 없음
PRIMARY KEY 제약조건을 생성하면 자동으로 생성됨 -
비고유 인덱스(NONUNIQUE INDEX)
빈번하게 사용되는 일반 컬럼을 대상으로 생성
주로 성능 향상을 위한 목적으로 생성 -
단일 인덱스(SINGLE INDEX)
한 개의 컬럼으로 구성한 인덱스 -
결합 인덱스(COMPOSITE INDEX)
두 개 이상의 컬럼으로 구성한 인덱스 -
함수 기반 인덱스(FUNCTION-BASED INDEX)
SELECT절이나 WHERE절에 산술 계산식이나 함수식이 사용된 경우
계산식은 인덱스의 적용을 받지 않음
[작성법]
CREATE [UNIQUE] INDEX 인덱스명
ON 테이블명 (컬럼명[, 컬럼명 | 함수명]);
DROP INDEX 인덱스명;
인덱스가 자동 생성되는 경우
-> PK 또는 UNIQUE 제약조건이 설정된 컬럼에 대해
UNIQUE INDEX가 자동 생성된다.
