의존 구문 분석
- 지배소: 의미의 중심
- 의존소: 지배소가 갖는 의미를 보완(수식)
- 어순과 생략이 자유로운 한국어같은 언어에서 주로 연구
규칙
- 지배소는 후위언어
- 지배소는 항상 의존소보다 뒤에 위치
- 각 의존소와 지배소는 한 개씩 존재한다.
- 교차 의존 구조는 없다.
- 중첩은 된다. 즉, A가 누군가의 지배소라면 동시에 다른 단어의 의존소도 될 수 있다.
분류 방법
Sequence labeling을 통해 분류.
활용
- 복잡한 자연어 형태를 그래프로 구조화해서 표현 가능해진다.
- 각 대상(Entity)에 대한 정보를 추출할 수 있다.
단일 문장 분류 task
주어진 문장이 어떤 분류에 속하는지 구분한다.
- Sentiment Analysis(감정 분석)
- 문장의 긍정/부정/중립 등 성향을 분류
- 험오 발언 분류
- 기업 모니터링
- Topic labeling(주제 분류)
- 문장을 category로 분류
- 대용량 문서 분류
- VoC(Voice of Customer): 고객의 피드백을 분류
- Language Detection(언어 감지)
- 문장이 어떤 나라의 언어인지 파악
- 번역기
- 데이터 필터링
- Intent Classification
- 문장이 가진 의도를 분류
- 챗봇: 문장의 의도를 파악해 적절한 답변 생성
한국어 문장 분류를 위한 데이터
- Kor_hate
- 혐오 표현에 관한 데이터
- 욕설 말고 bias 표현 모음
- Kor_sarcasm
- 비꼬는 표현 데이터
- Kor_sae
- 질문의 유형에 관한 데이터
- e.g.,
- yes / no로 답변 가능한 질문
- 대안 선택을 묻는 질문
- 금지, 요구 명령
- Kor_3i4k
- 의도와 관련된 데이터
문장 분류 모델 구조도
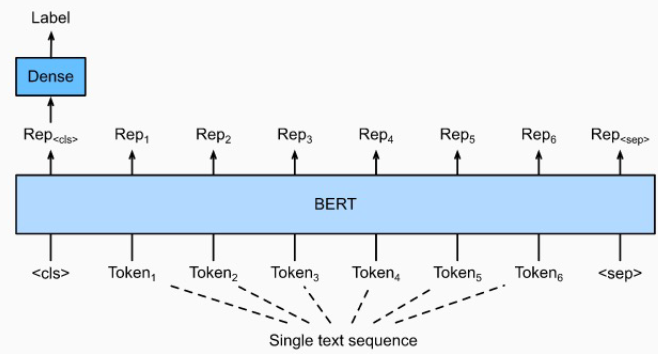
BERT를 기본으로 하고, CLS token에 classifier를 붙여서 문장 분류를 한다.
사용될 parameters는 다음과 같다. 일반적으로 BERT에서 정해지는 설정 값들이다.
• input_ids : sequence token을 입력
• attention_mask : [0,1]로 구성된 마스크이며 패딩 토큰을 구분
• token_type_ids : [0,1]로 구성되었으며 입력의 첫 문장과 두번째 문장 구분
• position_ids : 각 입력 시퀀스의 임베딩 인덱스
• inputs_embeds : input_ids대신 직접 임베딩 표현을 할당
• labels : loss 계산을 위한 레이블
• Next_sentence_label : 다음 문장 예측 loss 계산을 위한 레이블
학습 과정
- Dataset 준비
- Dataset 전처리, 토큰화
- Dataloader 설계
- Train, Test Dataset 준비
- TrainingArguments 설정
- Pretrained Model import
- Trainer 설정
- Model 학습
- Predict 구현, 평가

https://github.com/naem1023