LSTM
Long short-term memory.
RNN이 가진 Long term dependency를 해결한 모델. 먼 time step의 정보를 잘 전달하기 위해 만들어졌다.
hidden state를 마치 단기 기억 소자처럼 보고, 단기 기억 소자가 보다 긴 시간 동안 생존할 수 있도록 고안했기 때문에 붙여진 이름이라고 한다.
기존 RNN
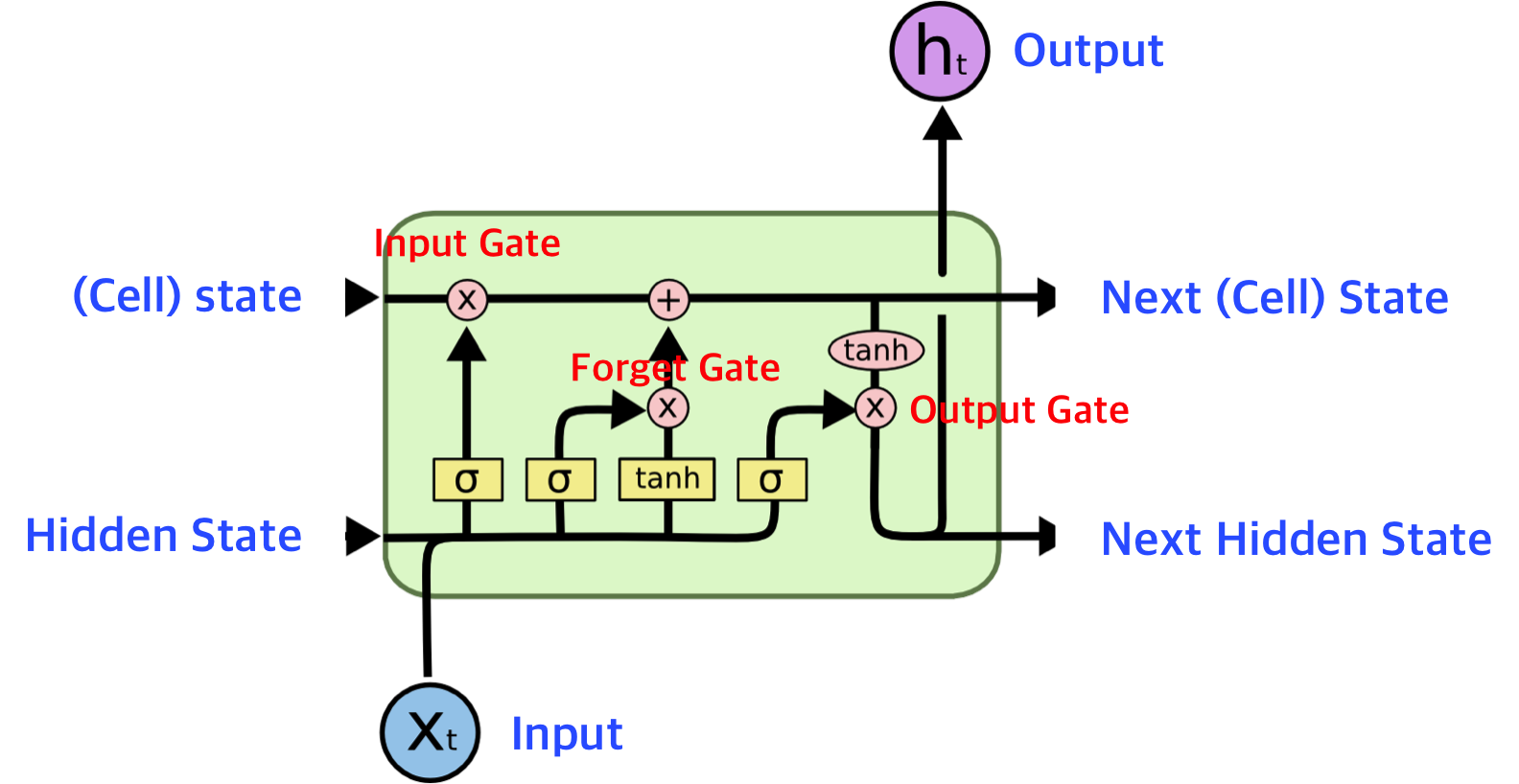
LSTM
cell state(): 이전의 모든 정보들이 담겨 있는 state.
hidden state(): 해당 step에서만 표출해야 되는 정보가 담겨 있는 state.
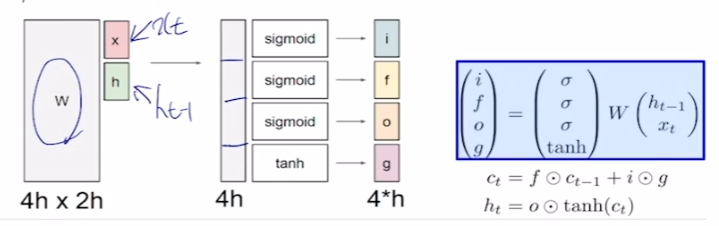
와 을 선형변환한 결과에 각각의 activation function에 통과시켜서 input gate, forget gate, output gate, gate gate(?)로 쓴다.
h를 와 hidden state의 dimension이라고 할 때, W는 (4h, 2h)이다. 왜냐하면 x와 hidden state를 선형변환하기 위해서 column은 2h여야 한다. 또한 i, f, o, g로 바로 쓸 수 있도록 row를 4h로 구성한다.
sigmoid를 통과시켜서 얻은 확률들은 hidden state에 element wise하게 곱해져서 마치 weight를 부여하는 역할을 한다.
Forget gate
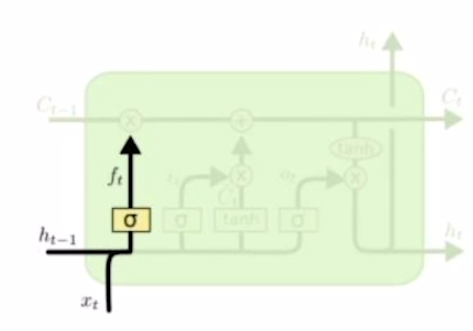
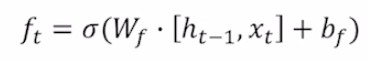
과 을 결합하고 이를 W와 선형결합해서 얻은 결과에 sigmoid를 씌웠다. 이를 cell state와 곱해서 cell state의 값들을 얼만큼 보존할지 결정한다. 다시 말하면 얼만큼 정보를 잊을지 결정한다.
Gate gate

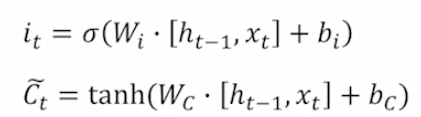
가 gate gate다. 새로운 정보를 만들어내는 게이트다.
는 input gate이다. forget gate와 동일한 형태로 sigmoid를 통과한 값을 가진다. 를 얼만큼 에 적용할지 결정해준다.
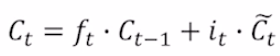
cell state를 새롭게 갱신한다. 앞쪽에 있는 항은 앞서 봤던 forget gate와 이전 cell state를 곱한 matrix다. 여기에 input gate와 gate gate 곱을 더해준다.
굳이 input gate를 생성해서 gate gate에 곱하는 이유는 한번의 선형변환만으로 원하는 결과를 만들기 어렵기 때문이라고 한다. 즉, input gate와 gate gate를 통해 더하고자 하는 정보에 대한 조작을 더 용이하게 하고자 하기 위함이다.
Output gate
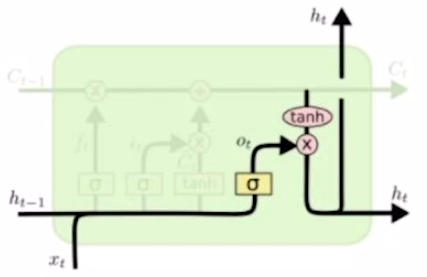
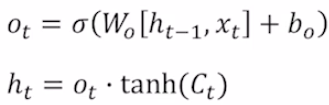
를 생성하기 위해 output gate를 먼저 구한다. cell state의 각 dimension을 적절한 비율만큼 줄이기 위해서 output gate를 사용한다고 한다.
LSTM에서의 는 현재 시점의 output에 직접적으로 사용되는 값이다. 즉, 가 가지고 있는 많은 정보들 중에서 현재 시점 t에 대한 정보만을 필터링한 정보를 가지고 있다고 생각하면 된다.
가령, hello를 학습데이터로 하는 모델이 있고 학습이 끝난 후 inference를 한다고 해보자. h를 모델에 넣으면 에 를 선형결합한 결과가 e가 되고 이것이 다음 step에서의 input이 된다.
Backpropagation
RNN과 달리 LSTM은 아래와 같이 덧셈의 형태로 정보를 결합한다.
즉, seuquence data가 길어져도 거듭제곱의 형태로 인해서 gradient vanishing/exploding이 발생하지 않는다.
GRU(Gated Recurrent Unit)
LSTM보다 적은 메모리만을 사용하기 위한 네트워크. LSTM과 성능이 비슷하거나 오히려 좋은 경우도 있어서 많이 사용된다.

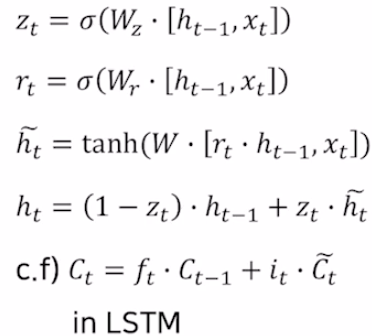
LSTM에서 forget gate와 input gate를 통해 정보 삭제량, 정보 생성량을 조절했다. GRU에서는 를 한번만 계산해 를 마치 forget gate처럼, 를 input gate처럼 사용한다.
또한 LSTM의 cell state와 hidden state을 하나의 hidden state만으로 구현한다. 즉, GRU의 hidden state는 이전의 모든 정보들을 가지고 있으면서 현재 step의 ouput에 직접적으로 관여하는 값이 된다.
