Preprocessing
bounding box
필요 이상의 정보를 거르자. 문제는 보통 그냥 이미지만 덜렁 주어진다는 것이다. 개발자가 알아서 적절한 방법을 찾아야한다.
수업 때 배웠던 YOLO를 써도되고, 대부분 이미지 중앙에 마스크 사진이 있으니 중앙crop만 해도 되고... 이것저것 해봐야겠다.
Resize
원본 크기로 계산하면 좋겠지만 이미지의 w, h, channel을 고려하면 정보의 양은 매우 크다. 즉, 정보의 손실과 계산의 효율성 사이에서 적절하게 균형을 찾아야한다. 오히려 계산량을 조금 줄여서 여러번 학습하는게 효율적일 수도 있다.
도메인 지식 활용
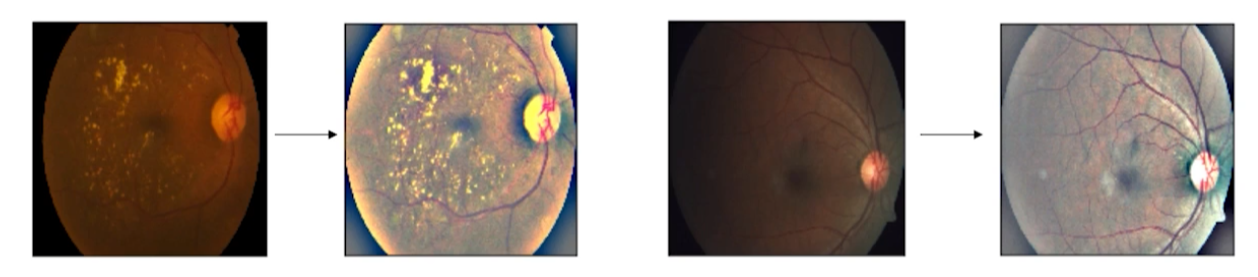
Kaggle에서 안구 관련 데이터 이미지를 가져왔다. 원본 이미지를 그대로 사용하지 않고 약간의 전처리를 거친 것이다. 밝기를 올리고 채도를 살짝 낮춘 것 같다. 이런식으로 도메인에서 활용이 적절하다고 생각되면 바로 활용해보자.
Data Augmentation
Bias, Variance
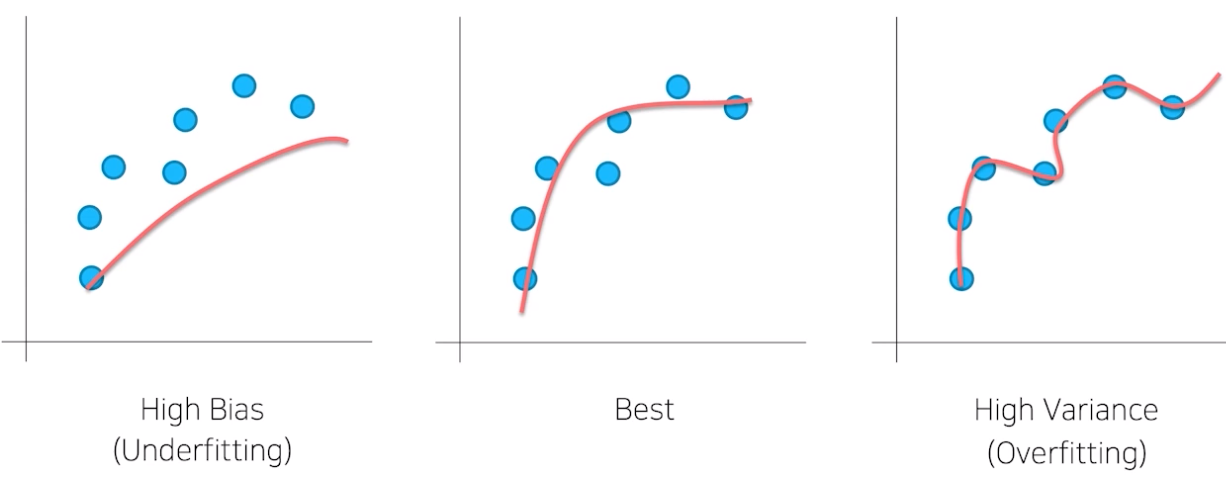
벌써 2년 사이에 4번이나 배우는 내용이다. 하지만 관점이 약간 다르다. 그 동안은 generalization이 잘 되는 모델을 공부하기 위해 위의 내용들을 봤다.
하지만 지금은 데이터의 노이즈 관점에서 생각할 수 있다. 즉, 우리가 원하는 아주 이상적인 데이터만 존재하는 것은 불가능하고 현실 세계의 문제 또한 노이즈가 매우 많다. 따라서 해당 노이즈에 대해서도 잘 처리할 수 있는 모델을 학습하기 위해, 노이즈에 대한 전처리, augemntation(증대)가 필요하다.
Train, validation
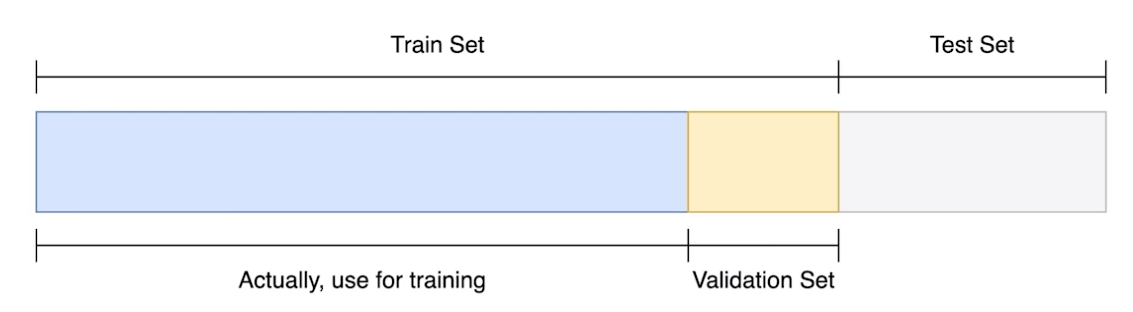
작년에 pytorch를 처음보고 굉장히 궁금했던 내용인데, 나는 validation set의 결과가 train 결과에 피드백이 되서 weight가 조절되는 줄 알았다. 하지만 막상 pytorch 코드를 보니 그냥 validation의 결과만 보고 학습이 끝나길래 뭔가 싶었다.'
이렇게 validation set을 굳이 나누는 이유는 학습에 활용되지 않은 데이터 분포가 필요하기 때문이다. 즉, 그냥 학습을 다 돌려버리면 test set에 model을 돌려보지 않는 이상 학습이 잘 됐는지 알 수 없다. 내 코드는 그저 train set에 fitting된 모델일 뿐이니까 당연하다.
따라서 굳이 train set에서 validation set을 만들어주는 것이다. 내가 진행한 학습이 제대로 되고 있는지 사람이 확인할 수도 있고, hyper parameter tuning을 위한 지표로도 사용 가능하다.
Test set은 절대 건드리지 않는다!! 보는 것은 cheating일 뿐더러 generalization도 잘 안된다.
Data Augmentation
데이터를 일반화하는 과정.
주어진 데이터가 가질 수 있는 case(경우), state(상태)를 다양하게 변경하여 일반화하는 것이다.

가령, 자동차 사진이 있다고 하자. 지금까지처럼 이 사진만으로도 학습을 할 수 있지만, 이미지의 상태와 경우는 매우 다양하다. 사진과 같이 밝지 않은 상태를 가정할 수도 있고, 비가 오는 상황을 가정할 수도 있다.
그리고 실제로 이러한 다양한 상황에서도 모델이 동작하는 것이 목적이다. 따라서, 데이터에 이러한 노이즈를 추가해서 데이터의 variance를 늘려서 robust한 model을 만들 수 있다.
torchvision.transforms

https://www.cse.iitb.ac.in/~vkaushal/talk/auto-augment/
그림처럼 사진을 다양하게 변형시켜서 variance를 늘리는 방법이다. 다만, 중요한 것은 실제로 현실세계에 있을법한 variance를 고려해야한다.
가령, 이번 이미지 대회는 마스크 사진 검출이다. 따라서 매장 앞에서 손님들을 찍은 사진에 대한 검출이 목적이다. 손님이 천장에 매달리지 않는 이상 상하반전 사진은 기대할 수 없다는 뜻이다. 굳이 transform에서 상하반전을 할 필요는 없을 것이다.
이런 식으로 도메인 지식을 적극적으로 활용하자.
Albumentations
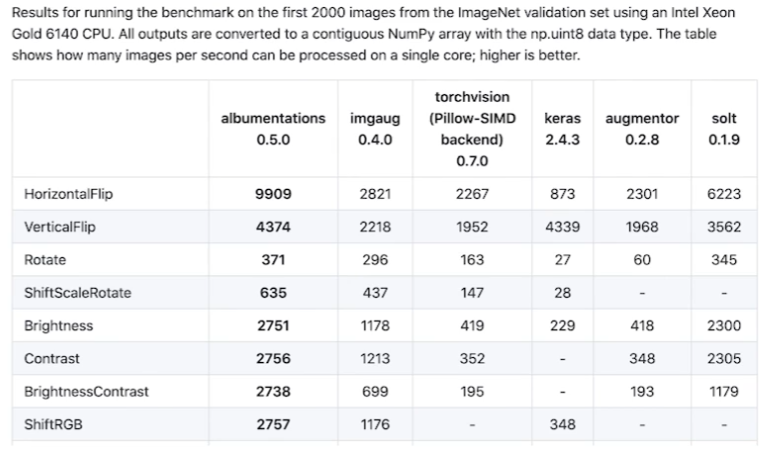
pytorch의 transforms보다 빠르고 다양하다고 한다. 사용해보자.
정리
무조건 해야되고, 무조건 좋은 method는 결코 없다. 가정과 실험을 통해 검증하면서 사용하자.

YOLO 는 you only live once 아닌가요?