Trading
- trading: 단기적
- 1초 ~ 3일내에 재거래한다.
- Investment: 장기적
Quant trading
말 그대로 Quantative(계량적)인 trading이다. 느낌대로 사는게 아니라 수학, 모델을 활용해 trading을 하는 것.
= Automated / system / algorithmic trading
- 과거: 파생상품의 가격이 수학적 성질을 가진다고 보고, 수학적 조작을 통해 가격을 이끌어냈다.
- 과거의 데이터 사용 안 함
- 최근: 과거 데이터에 접근이 용이하고 편리해졌다. 통계, 머신러닝을 활용한 데이터 기반의 가격 접근법이 매우 성공적으로 활용되고 있다.
Strategy of Quant trading
수많은 전략들이 존재하는데, 널리 알려진 방식들은 다음과 같다.
- Position을 얼마나 유지하는가?
- 1초 미만, ~3분, ~1시간, ~하루, ~3일 등 매우 다양하다.
- 어떤 상품군을 거래하는가?
- 주식, 선물, 옵션, 채권, 외환, 암호화폐 등..
- e.g., 종목 거래량을 보면 선물은 많아봐야 10 ~ 100개 이하지만, 주식은 매우 많은 수를 거래한다. 가령 5000개.
- Automation 여부
- Blackbox: 100% 자동화
- Greybox: trader의 주관이 개입
- Trade execution(주문 집행) vs 자체 수익
- 종목 자체에서 발생하는 수익을 극대화하는 것인가
- 종목의 커다란 주문에 대한 처리에 대한 전략인가
- 어디에서 Edge가 오는가? What is trading edge?
- 시장의 특성 파악
- 훌륭한 모델을 통한 수익 발생
Arbitrage
차익거래. 싼 곳에서 사서 비싼 곳에서 파는 행위를 통해 수익을 발생시키는 전략이다.
보통 여러 거래소가 존재하는데 거래소마다의 시세를 감안하여 거래한다.
Arbitrage는 같은 상품의 가격을 맞춰주는 역할을 한다. 소비자가 어느 거래소에 가더라도 비슷한 가격에 물건을 사고 팔 수 있음을 알려준다.
Arbitrage가 깨지는 것은 거래소마다의 가격 예측이 안 되는 것이다. 대표적인 예시가 한국의 암호화폐가 다른 나라에 비해 비쌋던 현상을 나타내는 '김치 프리미엄'이다.
직관적이고 쉬운 방법론이기 때문에 속도 경쟁이 치열하다. Arbitrage 기회가 발생하면 시장과 거래소에 따라 다르지만 짧게는 수μs에서 수ms 사이에 거래가 이루어진다.
거래 성공의 요소를 비율로 따지자면 90%의 속도와 10%의 알파로 이루어진다. 알파는 얼마나 전략이 똑똑한지를 의미한다. 따라서 가장 좋은 모델이 독식하는 전략이라고 한다.
Market Making
시장 조성. Market maker(시장 조성자)가 자본 시장의 특성을 활용해 수익 창출.
e.g., 은행은 외화 거래를 통해 수익을 발생시킨다.
유동성을 공급한다 = 누구나 거래하고 싶을 때, 안정적으로 쉽게 사고 팔 수 있다.
- Market maker는 시장을 조성해서 유동성을 공급해 차익을 발생시킨다.
- Market maker는 자본시장을 안정시켜준다.
Market maker가 없다면 사람들은 P2P로 거래를 해야하고 사람에 따라서 거래액수도 차이가 나며 자본 시장이 불안정해진다.
Market에서 모든 사람들이 일제히 한 방향으로 거래할 때, 가격이 움직이면서 Market maker는 손해를 볼 수도 있다. 따라서 전략을 잘 세워 이러한 움직임을 파악해 주문을 취소하는 것이 중요하다.
50%의 속도, 50%의 알파다.
Statistical arbitrage
이름만 이렇고 arbitrage와는 별 관계가 없다고 한다. 미래 가격의 변화를 예측하는 모든 방법론들을 통칭한다고 한다.
- 최근 호가 움직임을 이용한 가격 예측
- 종목 간의 상관관계를 이용한 가격 예측(cross section)
- 종목 간의 가격 차이 예측(basis trading)
funmamental(ref), 기술적 지표 등 정보의 출처에 상관없이 모든 정보 활용.
데이터 기반 접근이 필수적이다!
10%의 속도, 90%의 알파다.
Funmanetal trading players
- Quant hedge fund(ref), robo-adviser(wiki)
- 규모가 큰 고객의 자본(수천억~수십조)을 운영
- 운용자금과 이익의 일부를 보수로 얻는다
- 종목의 보유 기간이 상대적으로 길다. Quant trading보다는 Quant investment에 가깝다고 한다.
- Propriety trading(자기 자본 거래, ref)
- Hedge fund와 다르게 회사 자신 혹은 회사 파트너들의 자본(수십~수백억)을 거래
- Hedge fund에 비해 상대적으로 규모는 작다.
- HFT, market making을 통해 높으 수익률을 추구. 성공적인 팀들은 연간 100% 이상의 수익률을 낸다.
- 금융위기 이후 규제 변경으로 인해 Prop trading을 안하고, quant trading service를 제공하는 쪽에 힘을 쓴다고 한다.
- e.g., 주문집행서비스: 일반적인 시스템으로 감당하지 못하는 대용량 매도를 quant trading을 통해 집행
Stat Arb strategy
Statistical Arbitragy strategy를 딥러닝으로 생각한다면 이상적으로는 아래와 같이 생각할 수 있다.

end-to-end의 멋지고 간단한 구조다. 하지만 현실적으로는 모든 요소에 대해서 end-to-end를 적용하지 않고 아래와 같이 구성한다.
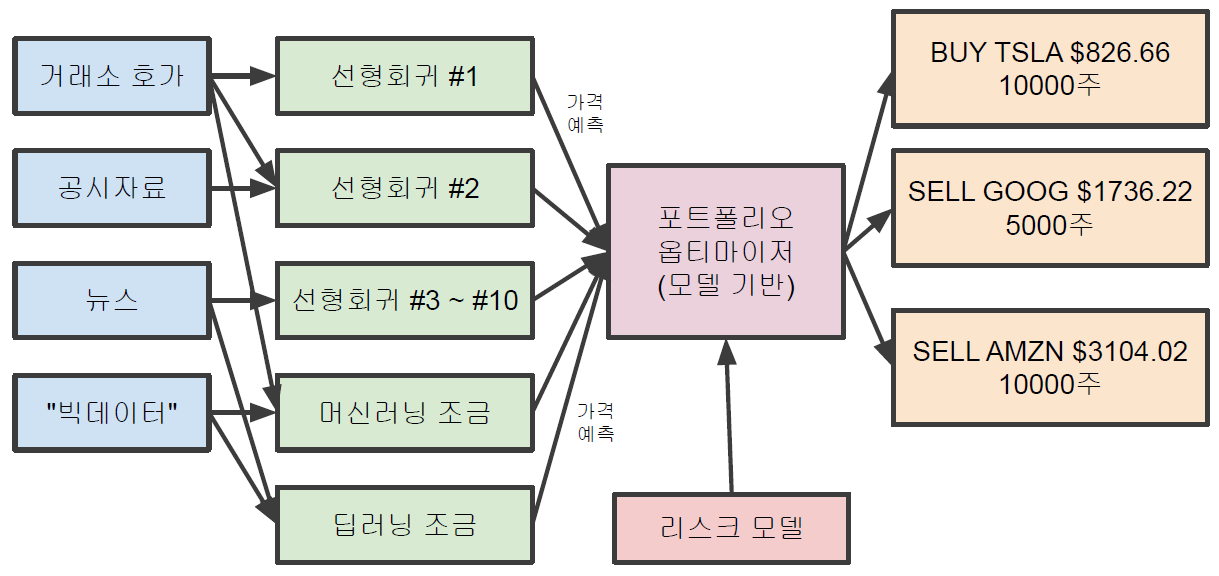
- 대부분의 가격 예측은 선형회귀를 통해서 이루어진다. 물론 머신러닝과 딥러닝 모델을 통해서도 예측한다.
- portfolio optimizer: 종목 간의 상관 관계성, 종목의 가격이 얼마나 움직이는지 등을 고려할 때 어떤 포지션이 가장 안정적인 수익을 창출할 수 있는지 판단하는 모델
- 데이터 기반 접근법보다는 모델 기반 접근
- 실제로 수행할 주문들을 여기서 뽑는다.
Quant trading이라는게 가능한가?
초과수익을 얻을 수 있는 시장에서 수익을 발생시킬 수 있는 것은 사기꾼이 아닌지 궁금할 수 있다. 즉, quant trading 자체의 효용성에 대한 의문이다. 왜냐하면 이러한 접근법으로 수익을 창출하는게 불가능하다는 가설, 썰들이 많기 때문이다.
효용설 시장 가설(Eugne Fama)
"가격은 상품에 대한 모든 정보를 포함하고 있기 때문에 장기적으로 초과수익을 얻을 수 없다."
가격은 미래와 현재의 모든 정보들이 선반영돼있기 때문에 일정 수준 이상의 수익을 창출할 수 없다는 가설이다. 노벨경제학상을 타신 분의 가설이라고 한다.
이를 뒷받침하는 이야기들은 아래와 같다.
- 액티브 펀드 매니저(펀드 매니저 개인의 판단 하에 매수/매도)와 시장 인덱스(시장의 모든 종목들을 시가총액 비율로 매수)를 비교하면 시장 인덱스가 더 좋다.
- Long Term Capital Management라는 회사가 1997년 아시아 금융위기 때 정말 거하게 말아먹은 전례가 있다.
예측 가능한 이유들
거래를 통한 정보 반영
예측 범위(horizon)에 따라 다르지만 미래 예측이 가능한 경우들과 그에 대한 이유들이 분명 존재한다.
상품에 대한 새로운 정보가 가격에 포함되기 위해서는 누군가 거래를 해야 한다.
효용성 시장 가설에서 가격에 정보가 선반영된다고 했지만, 결국 정보 반영은 거래를 통해 이루어진다. 따라서 거래 관측을 통해 미래 정보를 일정 수준으로 예측 가능하다!
- 포지션이 큰 참가자들은 움직이는데 오랜 시간이 걸린다.
- 하나의 종목에 대한 대용량 매도는 오랜 시간이 걸린다. 따라서 이러한 움직임을 파악해 가격 예측을 할 수도 있다.
- 큰 가격 변화에는 군중심리가 나타난다.
- 가격이 상승할 때, 피크를 찍고 적정 수준으로 조정된다.
- 전문가들은 리스크를 줄이는 합리적인 행동을 하고 실제로 의미가 있다.
- 옵션을 사고파는 market maker들은 많은 양을 매도할 때 리스크를 줄이기 위해 현물 시장에서 거래할 수 밖에 없다. 따라서 옵션 시장의 거래량을 통해 짧은 미래(수ms)를 예측할 수 있다.
- 새로운 정보(뉴스, 공시 정보, 매출, 펀더멘털 등)가 시장에 반영되는데 시간이 걸린다.
- 해당 정보가 시장에 반영되는 추이를 모델링해서 수익을 창출할 수 있다.
- 기술적인 문제들: 거래소/종목의 특성, 특정 규칙에 따라 움직이는 참가자들
- 해당 종목과 이용자들에 대해서는 특성과 규칙을 고려해 미래를 예측할 수 있다.
- 거래량이 많은 상품이나 거래소가 가격 발견 과정을 선도
- Arbitrage들은 거래량의 차이가 큰 거래소 사이의 가격을 맞춰주는데, 거래량이 큰 거래소를 기준으로 맞춰줄 수 밖에 없다.
- 거래량이 큰 쪽에 market maker가 있고 물량도 많기 때문에 거래량이 적은 쪽의 물량이 먼저 소진된다.
직관과 다른 성공 기준
미래 예측의 성공을 평가하는 지수로 (wiki)가 있다. 간단하게 미래 가격 예측에 대해 얼만큼 맞췄는지를 알려주는 지표라고 이해할 수 있다. 음수의 경우 예측을 안하는게 더 나은 경우고, 양수의 경우 0 ~ 100% 사이의 지표를 표현한다.
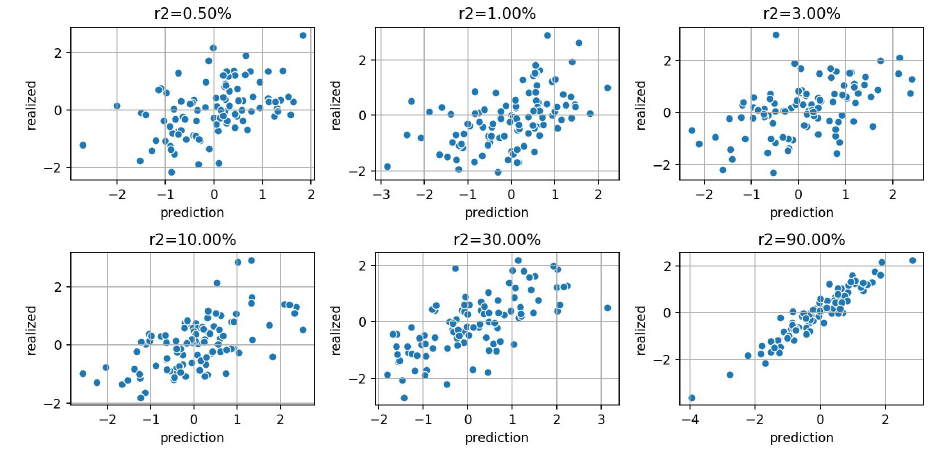
6개의 forecast(예측)을 보자.
높은 의 forecast가 돈을 버는데 유용할 것이라고 생각할 수 있다. 하지만 가 0.05%, 1.00%, 3.00%인 forecast가 실제로 실현 가능하고 돈을 벌 수 있는 forecast라고 한다.
오히려 가 15% 이상으로 나올 경우 문제가 있다고 생각할 수 있다. pipeline에 버그가 있거나, 를 잘못 측정하고 있거나, data snooping(ref) 문제때문에 인위적으로 가 높게 나오는 것을 의심한다.
**즉, 안 좋은 예측으로도 돈을 벌 수 있기 때문에 우리의 직관과 실제 quant trading에서 성공의 기준이 달라진다.
안 좋은 예측이 유효한 이유
- 엄청나게 작고 많은 예측
- 수천개의 종목에 하루에 수만번의 배팅을 한다.
- 베팅 성공 확률이 51%라면, 대수의 법칙에 따라 결국 이론값(51%)에 성공 확률이 수렴
- 많은 forecast 알고리즘 사용
- HFT(high frequency trading) 전략의 평균 수익은 거래량의 약 0.01% (1 basis point)
- 실제 수익률은 모두 다르지만, 전체 평균을 내면 아주 조금의 이익이 발생
- HFT를 통해 연수익 100% 이상을 기록하기 위해서는 매우 많은 거래가 필요
Quant trading에서 딥러닝의 사용
선형회귀를 많이 사용하고 ML, DL은 조금만 사용해서 가격 예측을 한다. 왜냐하면 시장을 예측하는 문제 자체가 정의하기도 어렵고 해결도 어렵기 때문이다.
시장 예측이 어려운 이유는 아래와 같다.
- 시장에 영향을 미치는 요소들 중 관측 가능한 요소들은 극히 일부에 불과
- 다른 참가자들의 포지션, 뷰, 코로나, 암호화폐 규제, 정치, 경제, 외교, 스캔들 등등..
- 정보를 볼 수 있는 시점은 정보 발생보다 늦을 수 밖에 없다.
- 시장의 특성은 계속 변한다.
- 참가자들은 접근 방법을 계속 고도화한다.
- 참가자들이 계속 바뀐다.
- 규제 조건이 계속 달라진다.
- 새로운 시장 / 상품군의 출현
문제와 환경의 정의
딥러닝이 효과적으로 해결하는 문제들은 다음과 같다.
- 이미지 인식: 이미지의 객체들은 변하지 않는다. 고양이, 강아지들의 특성은 수백만년이 지나지 않는 한 바뀌지 않는다.
- 바둑 AI: 어떠한 형태의 기보라도 바둑판 전체를 관측할 수 있다.
- NLP: 언어의 형태와 특성은 바뀌지만, 언어의 요체는 매우 오랜 기간 변하지 않는다.
즉, 문제 난이도와 별개로 문제 자체가 변화하지 않는 것들을 효과적으로 예측한다. 이러한 문제들은 시장 예측에 비유하면 아래와 같다.
- 털 한가닥을 관측해 어떠한 동물인지 파악
- 동물들이 분류를 피하기 위해 털 모양을 변화
- 동물들의 기준을 정부가 바꿈
문제가 어렵다는 것은?
- 오버피팅의 위험이 크다
- insample error를 줄이는 것은 쉽다. ML, DL이든 아주 쉽다.
- 하지만 낮은 error를 찾는 것은 오퍼피팅이 될 여지가 아주 크다.
- 오버피팅을 막았다할지라도, 미래에도 오버피팅이 되지 않을 가능성은 없다.
- 시장에서 변화하는 속성과 변화하지 않는 속성으 구분해야 한다.
- 이를 제대로 분류할 수 있다면 선형회귀만으로도 가치 있는 모델을 얻을 수 있다.
즉, 문제의 정의가 어렵고 문제 자체가 계속 변화하며 가치 있는 정보에 대해서도 오버피팅의 위험이 크기 때문에 딥러닝을 잘 활용하지 않는다고 정리할 수 있다.
Research
Hypothesis
대부분의 시장에 대한 research는 가설에서 출발한다.
- 여름에 홍수가 나고 날씨가 작물에 악영향을 끼친다면 곡물 선물 가격은 상승할 것이다.
- 같은 크기의 매수 주문이 반복된다면 가격이 상승할 것이다.
모델을 대략적으로 설계하고 데이터를 투입해서 결과를 얻는 데이터 기반 접근법을 실패하기 쉽다. 왜냐하면 설득력 있는 가설 없이는 모델 수정, 방향 수정, 데이터 조정 등의 작업이 어렵기 때문이다. 설득력 있는 가설이 있을 때도 프로덕션까지 생성되는 일은 거의 없는데, 가설조차 없다면 더욱 힘들다.
항상 Waterfall 형태의 연구만 이루어지는 것은 아니다. 개발된 모델의 형태나 결과만을 보고모델과 파이프라인을 수정해 좋은 결과를 얻는 과정도 필수적이다.
Data
Quant trading 회사들은 굉장히 다양한 데이터를 구입해 사용한다.
- 거래 시세, 공지사료
- 뉴스, 트위터, 웹 크롤링 결과, 애널리스트 리포트
- 루머로는 인공위성 사진(주차장의 차량 개수에 따른 경기 예측), 날씨정보(흉작 여부 에측), 신용카드 사용 정보 등을 활용하기도 한다.
데이터에서 엑기스만 걸러내는 작업들은 익히 알고 있는 ML/DL 작업들이 포함된다.
- filtering, noise 제거, clipping, outlier 감지, normalization, regression regularization, NLP ...
Algorithm
- 가설을 잘 표현할 수 있는지?
- 최적화 대상인 목적함수가 제대로 설계된 것인지? (e.g., L1, L2 norm에서 어떤 것을 사용하는 것이 맞을까?)
- 기존 코드를 재활용
- 엔지니어링적 관점: 분산화가 안된 코드라면 코드 수정
- 모델링적 관점: 모델 경량화
Monetiazation
이익창출. 알고리즘의 결과를 활용해 돈을 벌어야 한다.
- 거래소 선정
- 주문 타입 선정
- 어떤 포트폴리오가 출렁임 없이 꾸준한 성능을 내는지 파악
- 내 알파와 포지션을 노출하지 않고 거래하기
- 내 거래가 시장에 영향을 끼치지 않게 하기
- 시뮬레이터와 현실의 차이를 어떻게 고려할지
주의점
- Production system과 Backtest system의 간극
- Backtest system: 평가를 위한 system
- e.g., production은 c++로, backtest는 python으로 구현된 경우가 많았는데 간극이 존재했다.
- Market impact(가격 충격): 나의 거래로 인해 발생하는 시장 영향력
- Data snooping: 리서치에서는 보지 못했던 데이터들을 고려하지 않게 되는 실수
- 최근 거래량이 많은 주식 위주로 백테스트:
- 이후에 어떤 주식의 거래량이 많아질지 모르기 때문에 위험하다.
- 거래 당일에 공개되지 않는 정보들을 활용한 백테스트
- 어제까지의 정보만을 활용해야되는데 실수로 오늘까지의 정보를 데이터에 넣어서 좋은 테스트 결과를 얻는 실수
- 최근 거래량이 많은 주식 위주로 백테스트:
Reseach pipeline
ML과 마찬가지로 리서치는 개발과 다르게 결과가 안나오는 경우가 허다하다. 개발은 어떻게든 requriements들을 충족시키다보면 개발 완료를 선언할 수 있지만 리서치는 아무리 좋은 방법들을 고안해도 결과가 나오지 않는다면 무의미한 작업의 연속일 뿐이다.
따라서 가설 검증을 효율적으로 반복할 수 있는 플랫폼이 매우 중요하다.
- 회사 단위의 투자
- 자체적인 노트북 리서치 플랫폼, 자체 클라우드, 자체 DSL
- 팀 단위의 투자
- 쉽게 재현 가능한 리서치 스크립트, 리서치 효율성에 대한 투자
업계
국내에도 트레이딩 스타트업, 전통적 증권사의 프랍 데스크, robo-adviser, 핀테크 스타트업 등 여러 종류의 quant trading 기업들이 생기고 있다.
일할 곳은 플랫폼과 프로세스에 대한 투자를 열심히 하고, 내부적으로 연구 결과와 자료를 많이 공개하는 분위기의 회사가 좋다.

좋은 내용 감사합니다 멋지네요! 저도 퀀트 공부하는 중인데, https://quantpro.co.kr/ 해당 사이트 퀀트 내용 어떤지 의견주시면 감사하겠습니다!