Question Anwering

BERT, GPT와 같은 self-supervised learning의 가장 큰 수혜자라고 할 수 있는 영역이다.
- Question과 context가 주어진다.
- context는 문맥이라고 이해하면 되는데 사용되는 분야마다 의미가 조금씩 달라진다고 한다.
- Multiple-choice: Question에 대한 답의 후보군을 여러 개 주고, 그 중 답을 고르게 한다.
- Span-based: Question에 대한 답을 지문에서 발췌.
e.g., 10번째에서 30번째 index에 해당하는 부분이 답을 포함하고 있다. - Yes/No: Question에 대한 질의
- Generation-based: GPT와 같이 답 자체 또한 language generation task로 보고 수행.
Open-Domain Question Answering
External Knowledge인 Knowledgebase, knowledge graph와 같은 구조화된 형태의 DB에서 정보를 발췌하여 QA를 진행.
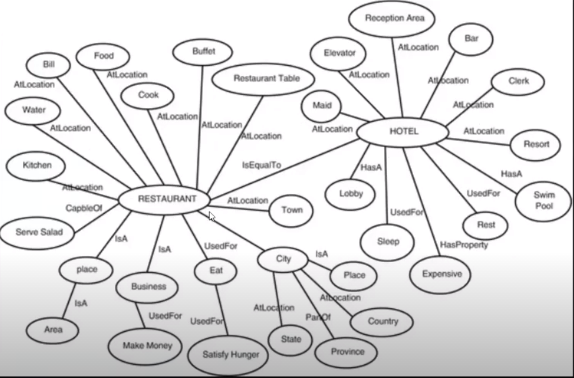
- Knowledge tuple: [Hotel], [HasA], [Lobby]와 같이 정보를 가진 node들이 쌍.
- Knowledge graph: knowledge tuple의 구성체
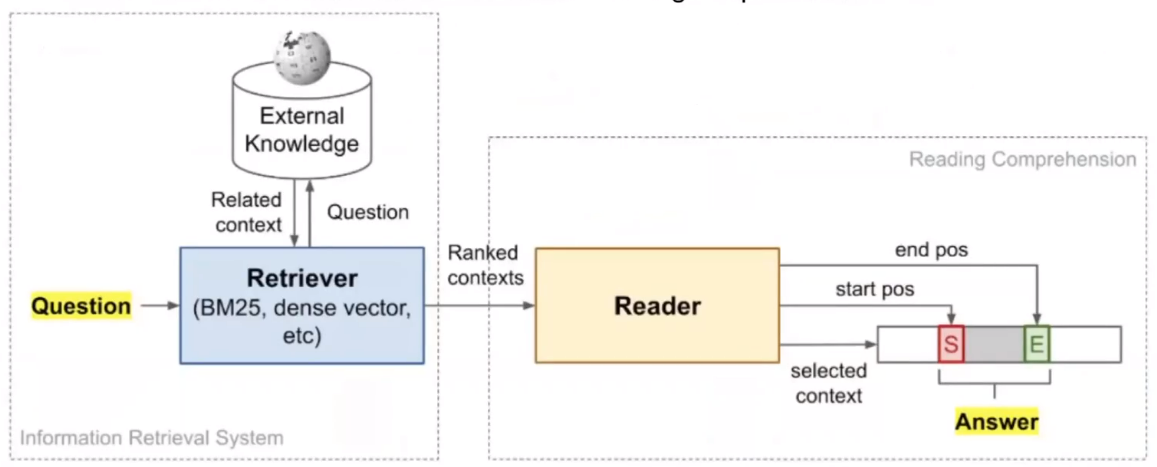
Open-Domain Questino answering은 external knowledge에서 정보를 검색한다. 대부분의 NLP task들은 자연어 형태의 sequence data를 기반으로 정보를 얻고 학습을 진행한다. 이러한 모델들을 fine-tuning 할 때, knowledgebase와 같은 구조화된 data를 사용하고자 하는 시도가 최근 trend다.
Open-Domain Question answering은 knowledgebase든 Wikipedia같은 자연어 데이터든 External Knowledge를 Retriever가 발췌해서 MRC를 진행하는 것이다.
Retrieval-augmented Language Model pre-training/fine-tuning
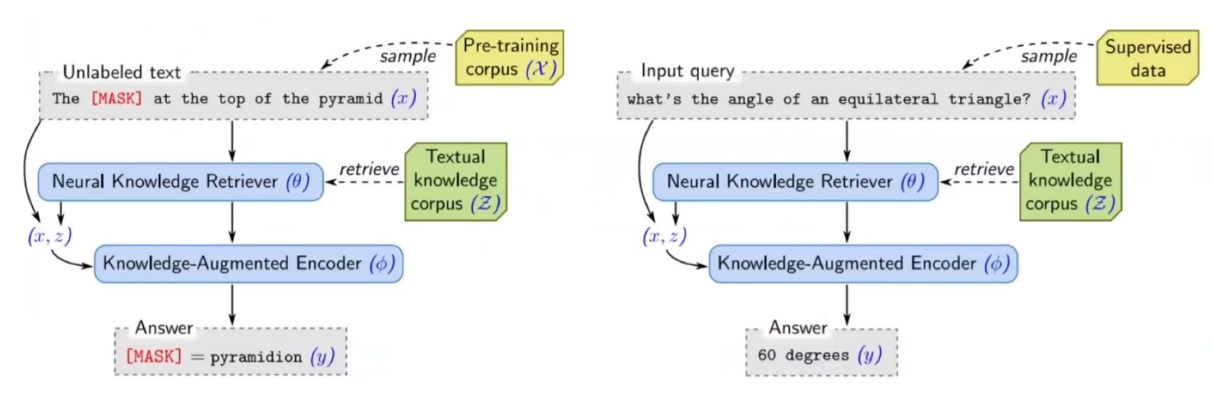
지문에서 답을 찾는 것이 아니라, Pre-training model이 가지고 있는 정보와 external knowldeg만을 활용해 답을 찾는다. 일종의 zero-shot learning이다.
Open-domain Chatbot
아직까지 chatbot을 위한 정형화된 답은 없다. 보통은 Seq2Seq로 구성한다.
- Open-domain chatbot: 비정형화된 주제라도 대화가 가능하다.
- closed-domain에 비해서 매우 어려운 task다.
- Closed-domain chatbot: 특정 주제와 목적만을 위한 chatbot. 사람이 직접 디자인한 모델을 통해 진행되는 경우가 많다.
- 높은 자유도가 아니다.
- 보통 classification 위주다.
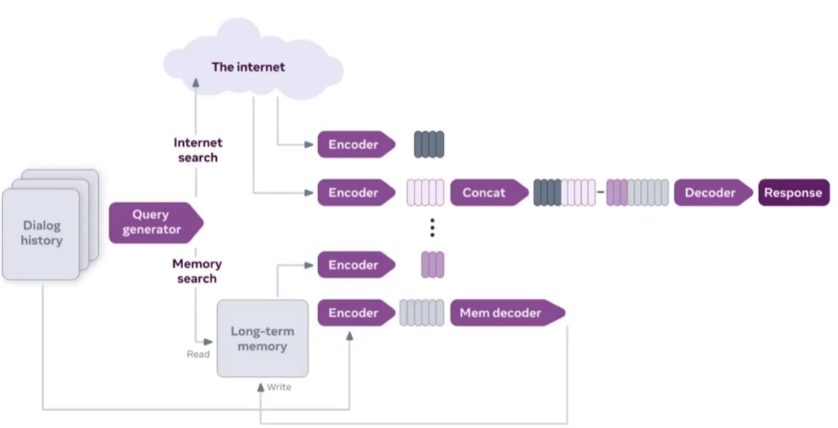
Facebook에서 공개한 Blender Bot 2.0의 구조이다. 모델이 미리 알고 있는 정보와 인터넷의 정보를 결합해서 질의를 하고자 한다.
Unsupervised Neural Machine Translation
보통의 번역 task는 라벨링된 데이터를 활용한다. 이러한 task를 라벨링 되지 않은 데이터에 대해서 활용을 하고자 하는 분야다.
Back-translation
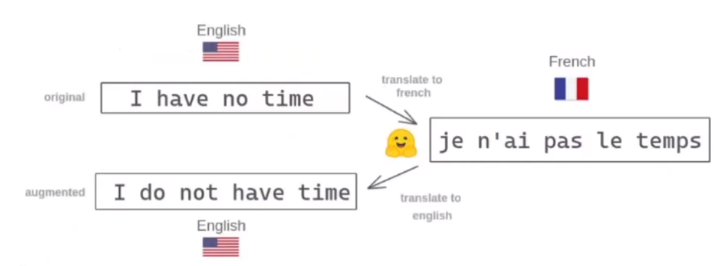
CycleGAN, StarGAN 등에서도 활용되는 기법과 동일하다.
- Parallel corpus: 말 그대로 평행한 문서 집합. 가령, (영어, 한국어)의 조합으로 이루어진 corpus.
Back-translation의 요지는 가령 영어를 프랑스어로, 다시 프랑스어를 영어로 번역했을 때 원본 문장이 생성되는지를 확인하는 것이다. 모델을 이애 대한 차이를 좁히도록 노력한다. 입력과 출력을 비슷하게 생성한다는 점에서 AutoEncoder와 비슷하지만, AutoEncoder처럼 latent vector에 어떤 것이 발생하는지 신경을 끄지 않는다.
중간 생성물인 프랑스어의 결과가 제대로 나오도록 노력하는 것이 핵심이다.
물론 중간생성물이 엉망임에도 입력과 출력 문장이 동일할 수 있다. 이러한 모순을 해결하기 위해 Denoising autoencoder를 사용하거나, decoder 결과물의 결과를 체크하는 등의 테크닉을 활용할 수 있다.
Text Style transfer
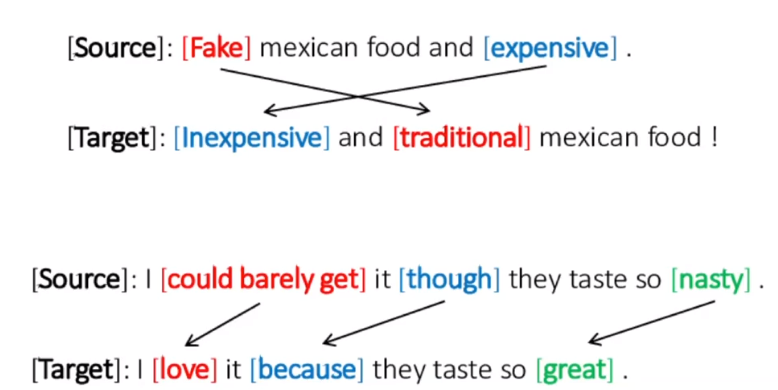
source 문장을 원하는 스타일로 바꾸는 task다. 가령, 문장의 어순을 바꾸거나 캐쥬얼한 문장을 바꾸거나 formal한 문장으로 바꾸는 것과 같은 task다.

encoder, decoder 사이에 style 정보를 넣어주거나 transformer에 x와 style에 대한 정보를 같이 주는 형태로 구현된다. conditional model, conditional generator라고 부르기도 하는 형태의 모델이다.
- (a) Disentanglement: context(z)와 style(s)을 구분한다.
- (b) Entanglement: context와 style을 구분하지 않는다.
Quality Esitmation
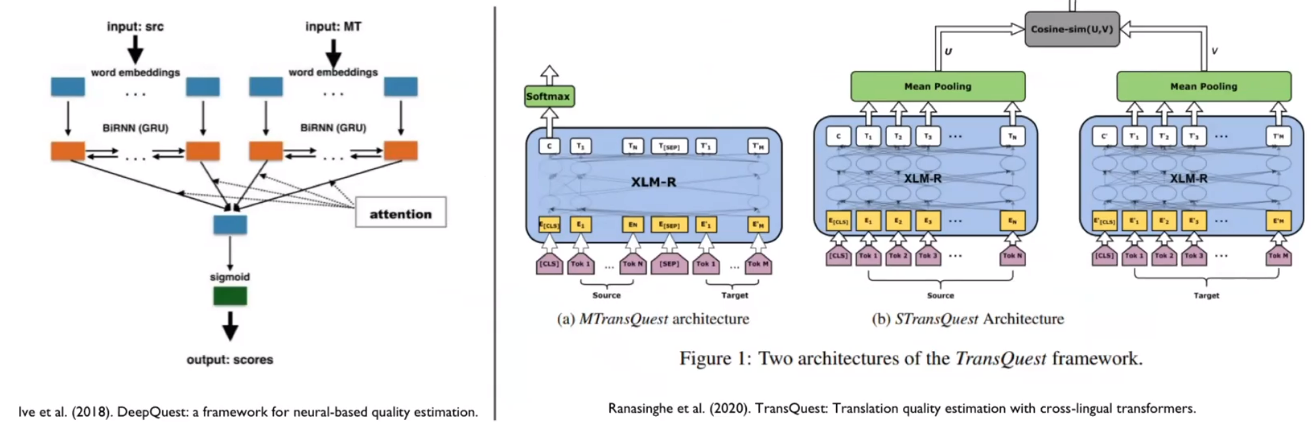
NLG(Natural language generation)의 지표로 BLEU score가 있다. 하지만 이는 사람이 직접 디자인한 점수일 뿐이고 모델에 대한 복합적인 지표가 아니다. 가령 BLEU score가 50도 되지 않지만 상용 모델로는 과분한 경우도 분명 존재한다. domain에서의 task를 얼만큼 잘 수행했는가에 대한 점수를 직접 디자인하기란 매우 어렵기 때문에 발생하는 문제다.
따라서 Quality Estimation에서는 정형화되지 않고 문장에 대한 다양한 요소들을 고려한 평가하고자 한다. 출력 문장이 좋은지에 대한 평가가 어렵기 때문에 어려운 분야라고 한다.
BERTScore
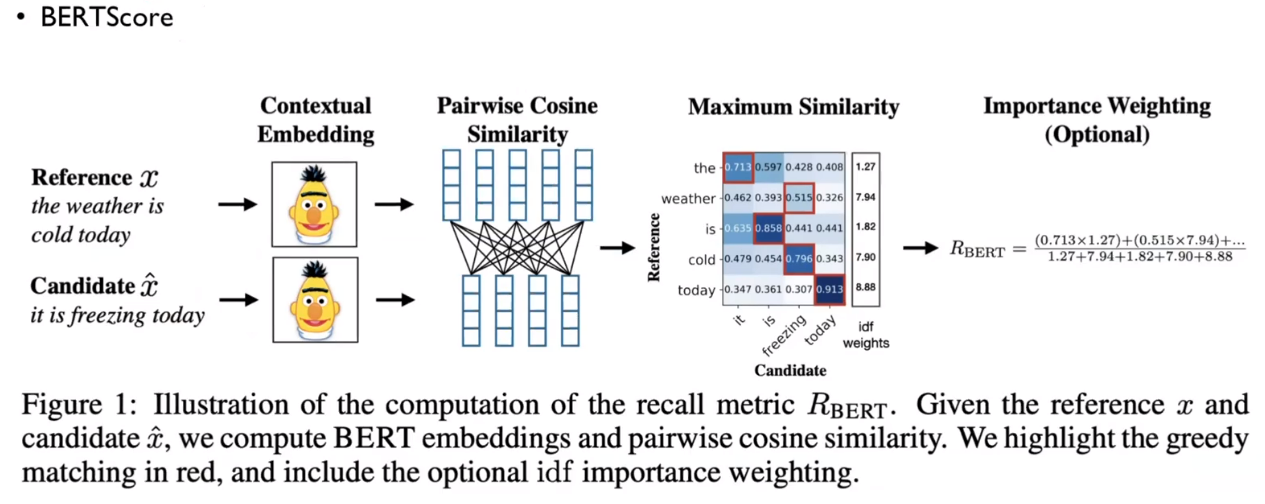
BERT encoding을 사용해서 평가를 수행한다. ground truth와 평가하고자하느 문장을 유사도를 통해 평가한다.
In-Context Learning
모든 NLP task를 자연어 생성 task만으로 처리하고자 하는 분야. GPT가 대표적이다.

CNN의 Few-shot과는 약간 다르다고 생각한다. 말 그대로 모든 task를 자연어 생성 task로 처리하기 때문에 task description, examples, prompt 조차도 자연어이다.
물론 번역과 관련된 데이터는 전혀 학습하지 않은 상태이기 때문에 Few-shot인 것은 CNN과 동일하다.
Prompt Tuning
위 도식에서 task description, examples, prompt를 어떻게 썻을 때 원하는 task를 가장 잘 수행하는가를 알아내는 task다.
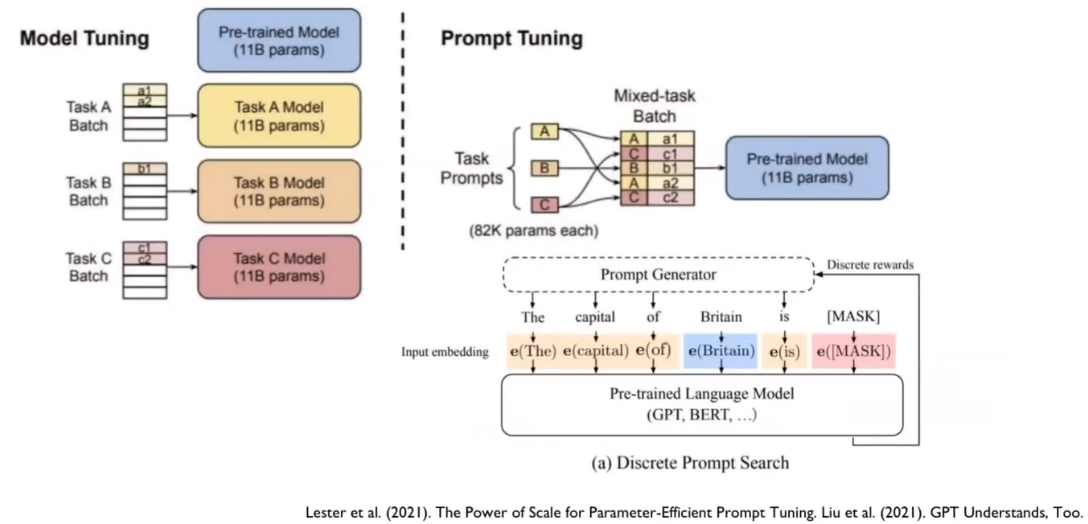
즉, 답을 얻고자 하는 질의에 사용되는 모든 문장을 optimize하는 task다. Prompt tuning을 위한 별도의 모델을 구성하지만 본래 모델(GPT)는 전혀 Fine-tuning하지 않는다.
Language Models Trained on Code
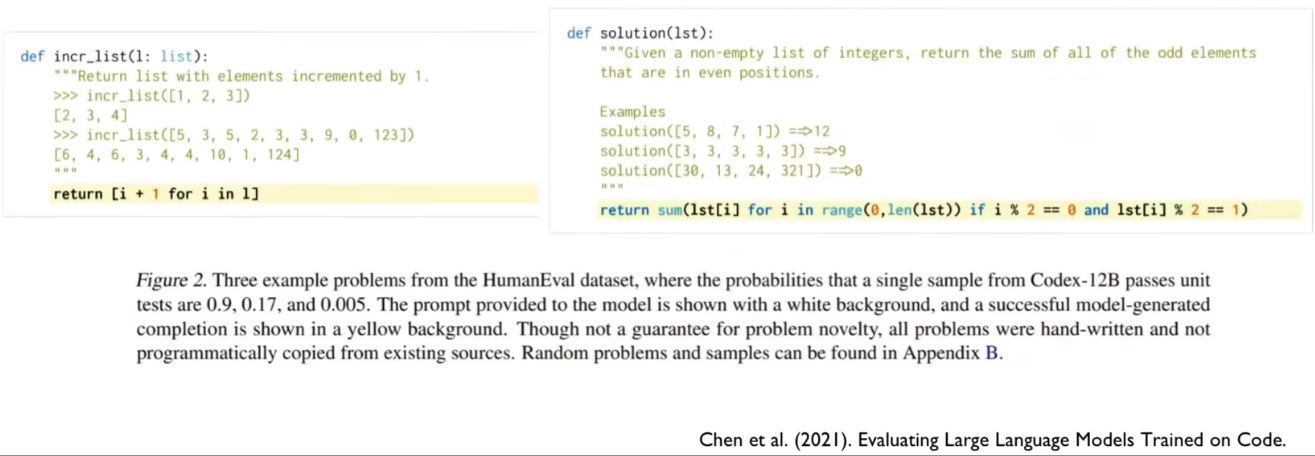
Codex: a language model fine-tuning on publicy available python code from Github.
In-Context Learning, Prompt Tuning을 code에도 적용하니 코딩을 잘하더라.
Multi-Modal Models
다양한 형태의 정보를 혼용하는 모델.
Dall-E

Generating images from text descriptions. Conditional generator다.
이미지를 n개의 patch 단위로 쪼갠 후 patch들을 Embedding vector처럼 취급한다. Dall-E에서는 n개의 patch를 모아서 하나의 sequence처럼 처리하여 생성한다. transformer 기반으로 생성한다.
CLIP
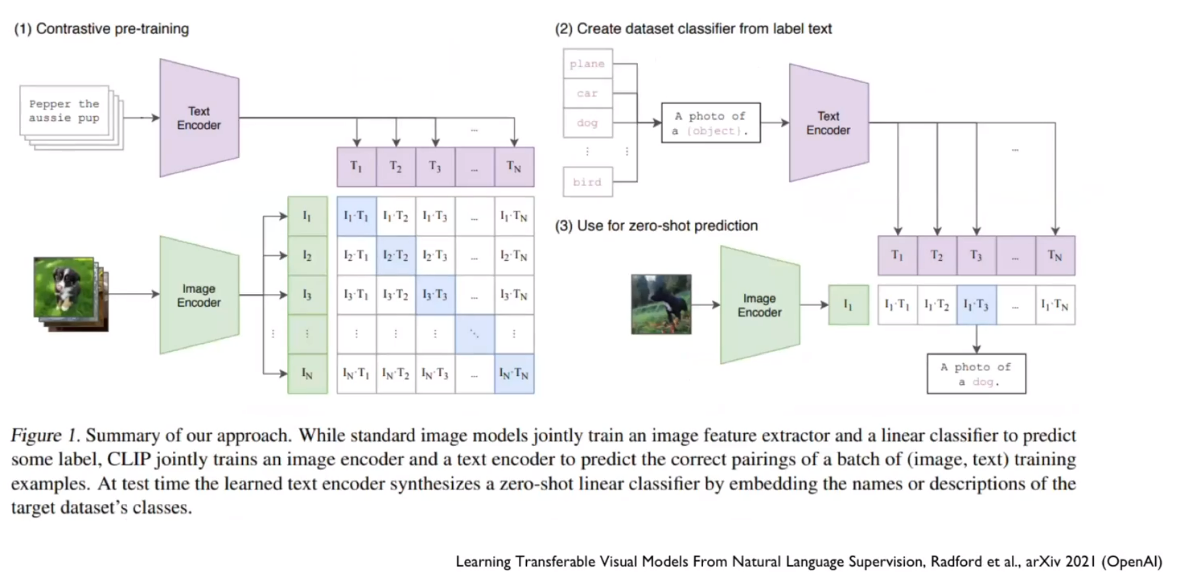
Text와 Image가 Semantic하게 유사하다면 Embedding space에서 비슷한 위치에 있어야 한다는 논리로 생성된 모델.
학습 데이터는 이미지와 캡션으로 구성된다. 다른 종류의 이미지에서 나온 캡션은 Embedding space에서 거리를 멀게 하고, 같은 종류의 이미지에서 나온 캡션은 거리를 가깝게 하는 방식으로 학습을 진행한다. 이것또한 transformer 기반이다.
Pre-trained model로써 굉장히 많이 사용한다!
CV, NLP 두 분야에서 모두 사용 가능한 굉장히 범용적인 Pre-trained model이다. 텍스트든 이미지든 뭐든지 encoding 가능하다.
NeRF라고 3D 이미지 생성 모델이 있는데 이게 CLIP을 transfer leraning한 것이라고 한다.
질의응답
- RNN, LSTM, GRU 등의 기존 RNN 계열의 모델들은 모두 transformer로 대체됐는가?
- 아니다. 미래 정보 예측의 경우 여전히 RNN을 사용하는 분야가 많다고 한다.
- Pattern signal을 중점적으로 봐야되는 분야들이 대표적으로 RNN 계열을 사용한다.
- Transformer는 paramter가 많은 것은 아니지만 보통 많은 layer를 쌓아서 구성하고 중간 생성물인 Q, K, V에 대한 연산들이 많은 메모리를 요구한다. 가 에 비례하게 메모리를 요구하기 때문이다.
- 따라서 경량화를 해야할 때 RNN 계열을 사용한다.
- Word2Vec, GloVe RNN, LSTM은 점점 사용하지 않는 것 같다. 최근 기술에 집중해서 공부하는 것이 맞을까?
- 최근에는 Pre-trained model에 별도의 까다로운 embedding을 거치지 않은 데이터를 넣어도 잘 작동하는 경우가 많다. 하지만 어찌보면 Word2Vec, GloVe 또한 Embedding layer에 해당한다고 할 수 있다. 동작 원리를 잘 파악하는 것은 도움이 된다.
- 모델이 모든 정보를 가지고 있으면 되지 않을까?
- 예상치 못한 정보에 대한 처리를 위해서 그러한 형태로 모델을 구성하지 않는다. 또한 현실적으로 세상의 모든 정보를 한 모델이 알고 있기란 불가능하다.
