Recent trends
- transformer, self-attention은 기계번역 외의 분야에서도 쓰이고 있다!
- transformer 논문에서 제시된 것처럼 6개의 transformer를 쌓지 않고 12개, 24개 혹은 그 이상으로 쌓는 것만으로도 성능 향상이 있는 것이 실험적으로 밝혀졌다. 특별한 기본 모델의 구조 변경 또한 없다! 이러한 모델을 위한 대용량 데이터를 학습하기 위해 Self-supervised learning framework를 사용한다.
e.g., BERT, GPT-3, XLNet, ALBERT, RoBERTa, Reformer, T5, ELECTRA - 위에 언급된 방식대로 학습 후, 여러 domain과 task에 맞게 transfer leraning하는 것만으로도 해당 분야에 특화된 모델보다 훨씬 좋은 성능은 낸다!
- 활용분야: Recommender system, drug discovery, computer vision...
- 한계점: Greedy decoding에서 벗어나지 못하고 있다. = 왼쪽에서 오른쪽으로 decoding 해가며 해당 step에서 최선의 선택을 하는 형태
GPT-1
NLP의 여러 task를 통합했다.
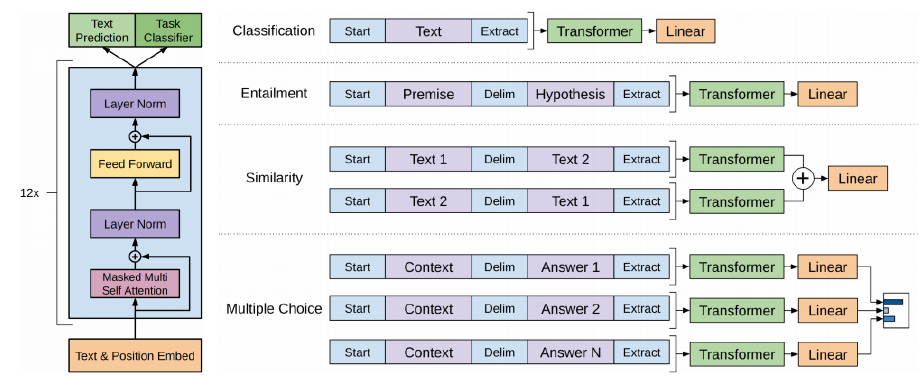
transformer를 12개 쌓았다.
일반적인 Seq2Seq
일반적인 seqeunce의 학습 과정은 이전 포스팅에서 다룬 기본적인 transformer와 동일하다. 'I go home'을 출력하기 위해서는 입력으로 '[SOS]'를 받으며 'I'를, 'I'를 받으면 'go'를 출력하도록 한다.
Classification

Seq2Seq를 수행하면서 Text의 앞뒤에 start, extract token을 넣어서 구현한다.
- transformer 학습이 수행되면 input과 동일한 형식의 encoding vector가 형설된다.
- encoding vector에서 extract token에 위치한 값을 활용해 classification을 한다.
e.g., 문장의 긍/부정 - Seq2Seq는 extract token을 제외한 나머지 encoding vector의 값들을 활용해 지속할 수 있다.
Entailment

함의라는 뜻이다. Premise(전제)와 Hypothesis(가설)이 논리적 내포 관계인지, 모순관계인지 판단하는 task다.
GPT-1에서는 위 도식과 같이 Premise와 hypothesis를 하나의 sequence로 만들어서 task를 해결한다. Extract token이 transformer 상에서 query로 사용되어, 적절한 정보들을 sequence 상의 다른 정보들로부터 추출한다.
- 두 문장 사이는 Delim이라는 delimiter를, sequence의 끝에는 Extract 토큰을 넣어준다.
- Encoding vector의 extract token을 ouput layer에 통과시켜, 논리적 관계를 판단한다.
Transfer learning
특정 task에 적합하게 학습된 GPT-1 모델을 다른 task에서도 사용할 수 있다.
가령, 긍/부정을 판단하는 task를 수행하는 모델을 활용해 주제 분류를 하고자 한다고 해보자.
기존의 Output layer는 긍/부정을 판별하기 위한 linear neural network이다. 따라서 해당 layer를 삭제하고, 주제 분류를 위한 linear nueral network를 transformer 뒤에 붙인다.
마치 CNN에서 기존의 모델에서 마지막 classification layer의 수만을 바꿔줘서 임의의 classification task를 수행하는 것과 마찬가지이다. Pre-trained 전체 네트워크는 유지하고 ouput layer를 initialize해서 학습을 진행한다.
Self-supervised learning
GPT는 Pre-trained 모델을 학습할 때 별도의 라벨링이 되지 않은 데이터를 사용해서 Seq2Seq task를 수행하도록 한다. 다음 단어를 예측하는 task이기 때문에 라벨링이 필요하지 않은 것이다. 이 때 self supervised learning이 사용된다고 한다.
하지만 주제 분류 task는 라벨링이 된 데이터가 필요하다. 보통 라벨링된 데이터는 라벨링 되지 않은 데이터에 비해 매우 소량이기 때문에 모델 학습에 불리하다.
self-supervised learning으로 pre-trained된 모델이 있기 때문에 대용량 데이터로 대부분의 parameter들이 의미있게 초기화돼있다. 따라서 소량의 라벨링 데이터를 사용해 transfer learning을 하는 것만으로도 유의미한 성능의 모델을 만들 수 있다.
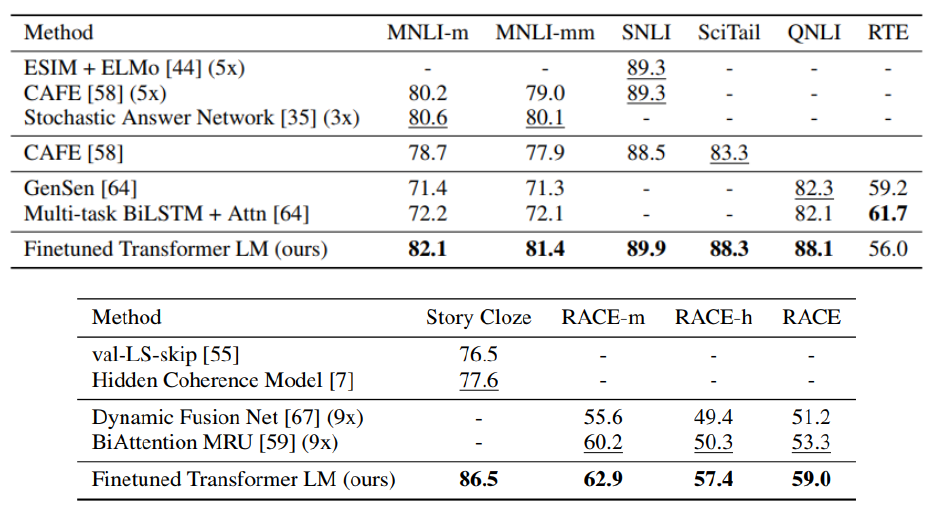
위 표는 특정 task만을 위해 고안된 모델과 데이터의 결합을 GPT와 비교한 것이다. 미리 대용량 데이터로 학습 한 후, transfer learning을 한 것이 더 좋은 성능을 보여준다.
BERT
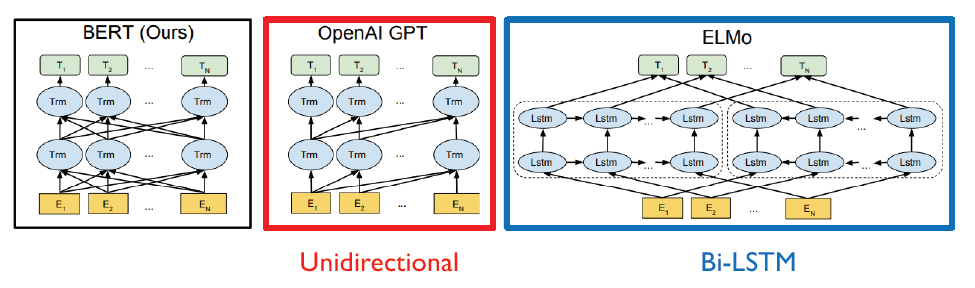
Bidirectinoal Transformers for Language Understading이라고 한다. 이전에도 LSTM을 활용해 대용량의 데이터를 self-supervised learning을 하도록 시도했지만, BERT가 훨씬 성능이 좋다.
Motivation
RNN 계열은 한 가지 방향으로만 정보를 취득한다. 전체 맥락을 이해하고 독해를 해야하는 task에서 매우 취약한 방법론이다. 따라서 이를 해결하기 위해 Bi-Directional하게 정보를 취득하고자 하는 것이 BERT의 Maksed language model이다.
Maksed Language Model(MLM)
입력 sequence의 단어들을 랜덤하게 mask로 치환한다. 그리고 mask된 단어르 유추하도록 학습을 진행한다.
hyperparameter : 어느 수준의 확률로 단어들을 mask로 변경할지
- 가 너무 높을 때: 정보가 너무 많이 가려져서 mask 데이터를 유추하기 어렵다.
- 가 너무 낮을 때: 학습에 걸리는 시간이 너무 오래 걸리거나, 학습 효율이 떨어진다.
보통 를 쓴다.
부작용
15%의 단어들을 mask token으로 치환하고자 했다할지라도 15%에 해당하는 데이터를 모두 mask toekn으로 치환하는 것은 부작용이 발생한다!!
Pre-trained model은 15%의 데이터가 mask token인 것에 익숙하지만, 실제 test data는 그렇지 않을 가능성이 다분하다. 이러한 양상이 transfer learning에서 큰 방해가 된다.
해결 방법
에 해당하는 데이터를 다음과 같이 분류한다.
- 80%의 데이터는 mask token으로 치환한다.
- 10%의 데이터는 random word로 치환한다. 이상한 단어가 입력으로 들어오더라도 제대로 처리하기 위함이라고 한다.
- 10%의 데이터는 원본을 유지한다. 소신있게 원본이 옳다고 말할 수 있기 위함이라고 한다.
Next Sentence Prediction
GPT에서의 task처럼 문장 단위의 task를 처리하기 위해 BERT에서 제안한 방법론이다.

마치 GPT에서의 extract, delimiter token과 마찬가지로 CLS, SEP token을 사용했다.
- SEP: 문장과 문장 사이를 구분해주는 token
- CLS: classification 정보가 담기는 token. 문장의 맨 앞에 온다.
- MASK: Mask language model에서 쓰인 mask.
위 그림에서 나온 task는 두 문장이 인접한 것이 옳은가를 판별하는 것이다. 즉, CLS token은 binary 데이터를 담게 된다. transformer에는 그림의 모든 정보가 한꺼번에 입력되어 네트워크가 알아서 CLS token에 예측 결과를 출력한다.
BERT 구조
Model Architecture
- L: Layer
- H: Attention encoding vector의 dimension
- A: Attention head per Layer
- BERT Base: L=12, A=12, H=768
- BERT Base: L=24, A=16, H=1024
Input Representation
- WordPiece embedding: Word 단위의 Embedding이 아니라 Subword 단위로 Embedding(30,000 WordPiece)
- Learned positional embedding
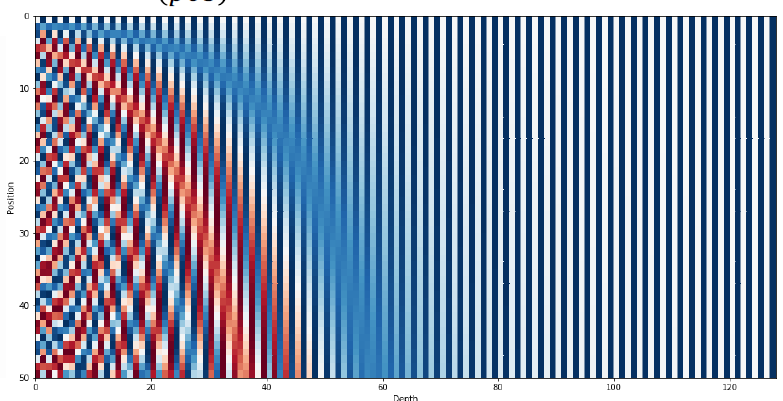
Transformer에서 sin, cos에 미리 정해진 offset을 사용하여 positional embedding에서 사용할 matrix를 계산했다.
BERT에서는 이러한 matrix조차도 end-to-end로 학습한다. 마치 Word2Vec에서 embedding vector를 만들기 위해 network를 학습하듯이! - Segment Embedding
Segment Embedding
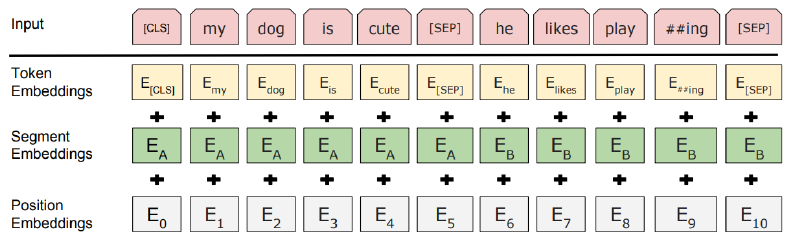
Positional embedding에 의해서 순서성이 부여되지만, 문장 간의 결합을 인지하지는 못한다.
Next sentence prediction 같은 경우 SEP token을 기준으로 'he'는 첫번째 단어라고 처리를 해야하지만 sequence 단위로는 첫번째가 아니기 때문에 발생하는 문제점이다. 따라서 Segement embedding을 도입한다.
SEP 단위로 앞 뒤 문장이 다름은 Segment embedding을 통해 계산 후 단순히 더해주기만 하면 된다.
Bidirectional
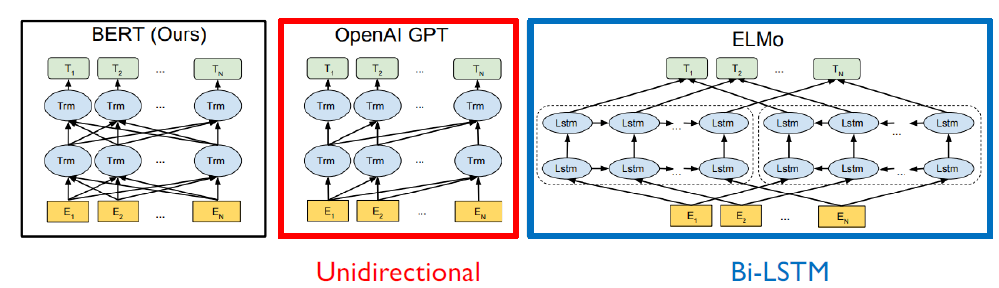
GPT는 Masked self-attention 사용해서 다음의 정보를 참고자하지 못하도록 했다. 다음 단어를 예측해야 하는데 다음 단어를 보면 안되기 때문이다.
BERT는 seuquence가 mask로 처리돼있기 때문에 전체 sequence를 본다. 왜냐하면 전체 맥락을 보고 mask를 예측해야하기 때문이다. 그래서 BERT는 일반적인 transformer의 self-attention을 사용한다.
Transfer learning
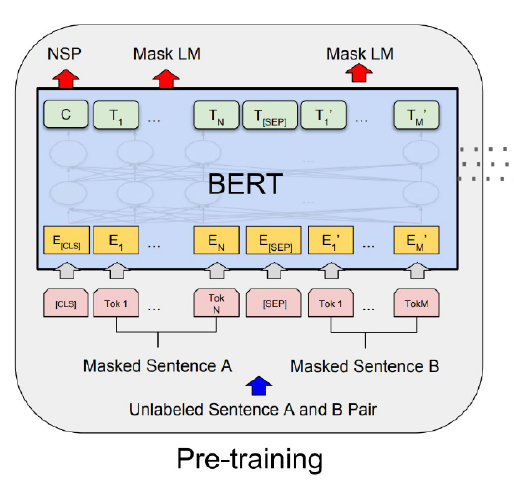
Self-supervised learning으로 만든 Pre-trained BERT가 있다고 해보자. 이를 활용해서 가능한 task는 아래와 같다. GPT와 유사하다!
Sentence pair classification
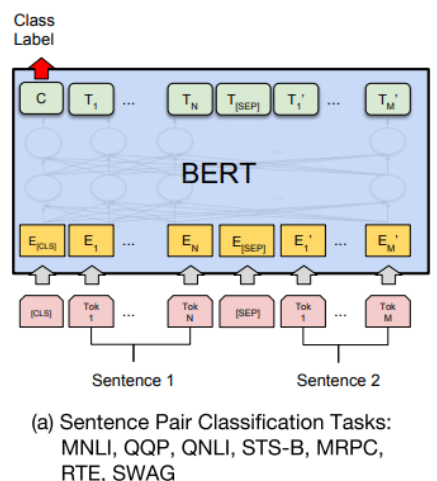
- 두 문장을 SEP token 단위로 묶는다.
- 첫번째 인덱스에는 CLS token을 넣어서 BERT를 통과시킨다.
- Encoding vector의 첫번재 인덱스는 CLS token인데, 이것을 output layer에 넣어서 class label을 얻는다.
Single sentence classification
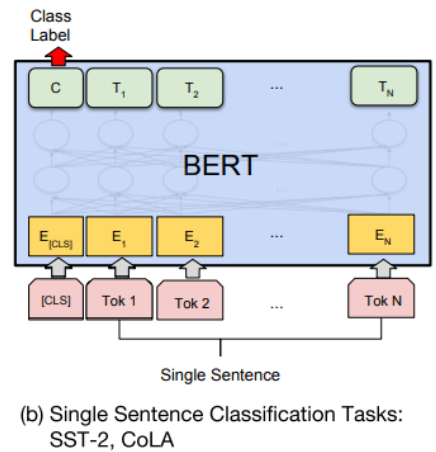
Sentence pair classification과 동일하다. 한 문장이기 때문에 CLS token만 있다.
Single Sentence Tagging
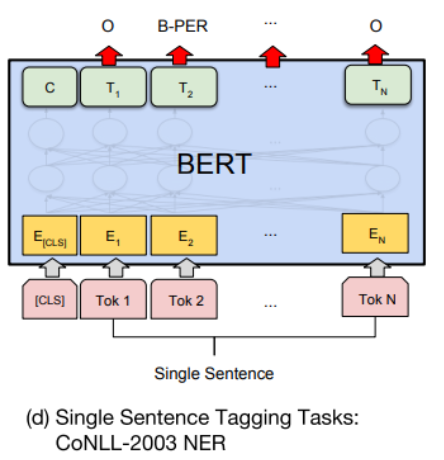
word 별로 Encoding vector가 존재할 것인데, 이것들 각각을 output layer에 통과시켜서 품사, 형태소 등의 정보를 판별하도록 한다.
BERT vs GPT-1
- Training size
- GPT: BookCorpus(800M words)
- BERT: BookCorpus, Wikipedia(2,500M words)
- BERT: SEP, CLS token이 있다. Segment embedding을 통해 문장들을 구분한다.
- Batch size
- BERT: 128,000 words
- GPT: 32,000 words
- 일반적으로 batch size가 크면 학습이 더 안정되고 잘 된다고 한다.
gradient descent에서 여러번의 학습을 통해 얻어진 gradient의 평균을 사용하는 것보다, 한번에 계산된 gradient를 사용하는 것이 더 좋다!
- Task specific fine-tuning
- GPT: 여러 task에서도 5e-5의 learning rate를 썻다.
- BERT: task-specific하게 learning rate를 fine tuning했다.
MRC(Machine Reading Comprehension), Question Answering
문장을 독해해서 답을 하는 것.

위와 같이 Document에 대해서 주체와 행동에 대한 독해가 제대로 이루어져야지 답을 할 수 있다.
SQuAD 1.1
MRC를 활용한 QA model의 성능을 테스트하기 위한 Standford QuA Dataset. 지금은 2.0도 있다고 한다. 테스트셋에 대한 스코어 리더보드도 있다.
SquAD 1.1 해결 과정

보통 질문의 답은 지문의 특정 위치에 위치하는데, 이 위치를 찾도록 한다.
1. 데이터셋의 질문과 질문을 위한 지문을 SEP token을 활용해 concatenate한다.
2. 1번의 데이터에 대한 Encoding vector를 얻는다.
3. 답의 start point을 찾기 위해서 Encoding vector를 scalar로 만들기 위한 fully connected layer를 추가하고, softmax를 수행한다.
4. 답의 end point을 찾기 위해서 Encoding vector를 scalar로 만들기 위한 fully connected layer를 추가하고, softmax를 수행한다.
5. 한 번의 encoding vector에 두 개의 fully connected layer를 사용해서 답의 start, end point를 구한다.
SquAD 2.0 해결 과정
1.1은 항상 질문에 대한 답이 있지만, 2.0은 질문에 대한 답이 지문에 없는 경우도 포함됐다.
따라서 답이 있는지 찾는 task가 선행된다. 답이 있다면 SquAD 1.1 해결 과정을 수행하면 된다.
- 질문과 지문을 concatenate하고 CLS token을 추가한다.
- CLS token의 값을 활용해 binary classification을 하는 fully connected layer를 추가한다.
- Cross entropy를 활용해 분류한다.
SWAG
주어진 문장에 대해서, 다음에 나타날법한 문장을 고르는 task.

- Permise 문장과 과 보기에 해당하는 문장들을 각각 concatenate한다.
e.g., Permise + 보기1, Permise + 보기2, ... - 각각의 concatenate 결과에 대해서 encoding vector를 구한다.
- 각각의 encoding vector를 output layer에 통과시켜서 scalar를 얻는다. 동일한 output layer를 사요한다.
- scalar 결과들에 대해 softmax를 취해 가장 높은 확률의 보기를 고른다.
BERT: Ablation study
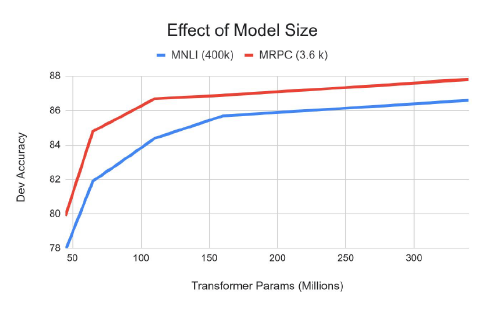
BERT는 parameter를 많이 쓸수록 성능이 올랐다.
